编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入:strs = ["flower","flow","flight"]
输出:"fl"示例 2:
输入:strs = ["dog","racecar","car"]
输出:""
解释:输入不存在公共前缀。提示:
1 <= strs.length <= 2000 <= strs[i].length <= 200strs[i]仅由小写英文字母组成
第一次解法:(暴力)依次比较每个str的元素
# @lc code=start
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
lens=len(strs[0])
lenlist=len(strs)
j=0
if lenlist==1 or strs[0]=="":
return strs[0]
while j<lens:
for i in range(1,lenlist):
fist=strs[0][j]
if j>=len(strs[i]) or strs[i][j] != fist:
return strs[0][0:j]
j=j+1
return strs[0][0:j]

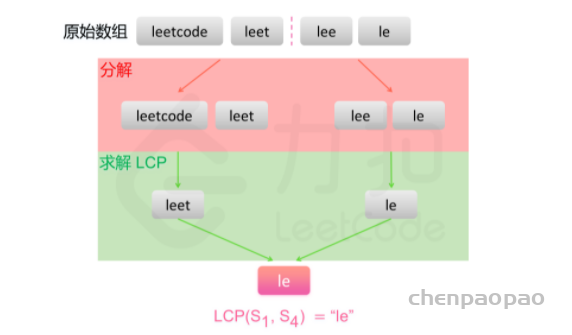
#递归函数
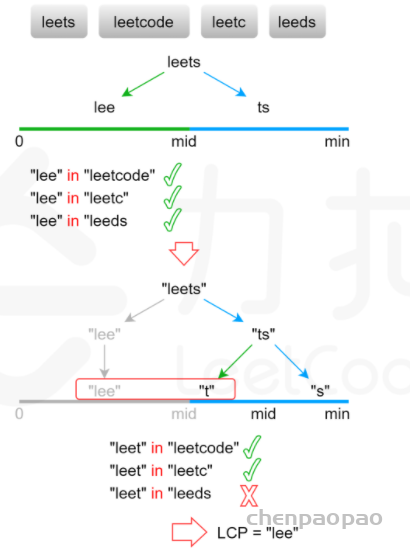
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
def lcp(start, end):
if start == end:
return strs[start]
mid = (start + end) // 2
lcpLeft, lcpRight = lcp(start, mid), lcp(mid + 1, end)
minLength = min(len(lcpLeft), len(lcpRight))
for i in range(minLength):
if lcpLeft[i] != lcpRight[i]:
return lcpLeft[:i]
return lcpLeft[:minLength]
return "" if not strs else lcp(0, len(strs) - 1)
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/longest-common-prefix/solution/zui-chang-gong-gong-qian-zhui-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
def isCommonPrefix(length):
str0, count = strs[0][:length], len(strs)
return all(strs[i][:length] == str0 for i in range(1, count))
if not strs:
return ""
minLength = min(len(s) for s in strs)
low, high = 0, minLength
while low < high:
mid = (high - low + 1) // 2 + low
if isCommonPrefix(mid):
low = mid
else:
high = mid - 1
return strs[0][:low]
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/longest-common-prefix/solution/zui-chang-gong-gong-qian-zhui-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。