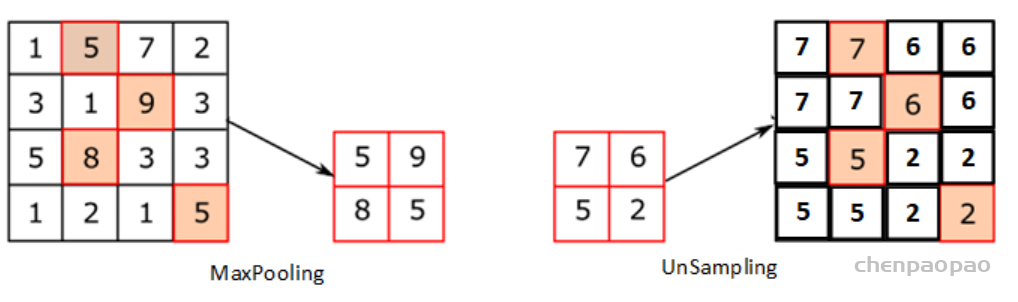
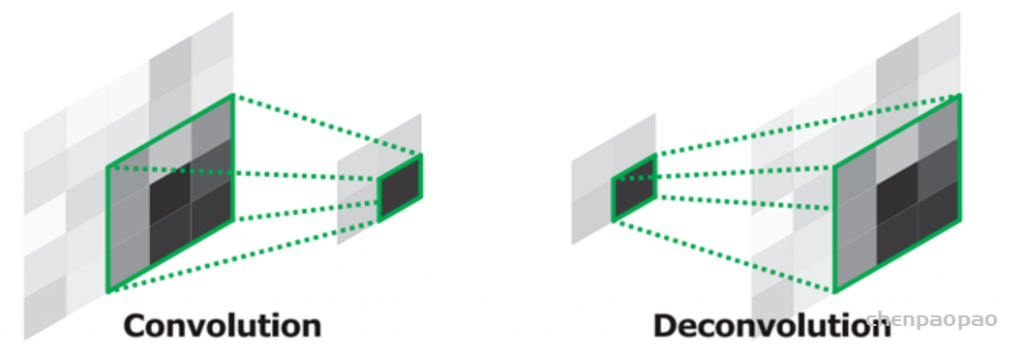
自2015年以来,UNET在医学图像细分中取得了重大突破,开放了深度学习时代。后来的研究人员在UNET的基础上做出了很多改进,以提高语义细分的性能。
摘自:https://github.com/ShawnBIT/UNet-family
如何查找代码:在 https://paperswithcode.com/ 查找论文即可
UNet-family
2015
- U-Net: Convolutional Networks for Biomedical Image Segmentation (MICCAI) [paper] [my-pytorch][keras]
2016
- V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation [paper] [caffe][pytorch]
- 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation [paper][pytorch]
2017
- H-DenseUNet: Hybrid Densely Connected UNet for Liver and Tumor Segmentation from CT Volumes (IEEE Transactions on Medical Imaging)[paper][keras]
- GP-Unet: Lesion Detection from Weak Labels with a 3D Regression Network (MICCAI) [paper]
2018
- UNet++: A Nested U-Net Architecture for Medical Image Segmentation (MICCAI) [paper][my-pytorch][keras]
- MDU-Net: Multi-scale Densely Connected U-Net for biomedical image segmentation [paper]
- DUNet: A deformable network for retinal vessel segmentation [paper]
- RA-UNet: A hybrid deep attention-aware network to extract liver and tumor in CT scans [paper]
- Dense Multi-path U-Net for Ischemic Stroke Lesion Segmentation in Multiple Image Modalities [paper]
- Stacked Dense U-Nets with Dual Transformers for Robust Face Alignment [paper]
- Prostate Segmentation using 2D Bridged U-net [paper]
- nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation [paper][pytorch]
- SUNet: a deep learning architecture for acute stroke lesion segmentation and outcome prediction in multimodal MRI [paper]
- IVD-Net: Intervertebral disc localization and segmentation in MRI with a multi-modal UNet [paper]
- LADDERNET: Multi-Path Networks Based on U-Net for Medical Image Segmentation [paper][pytorch]
- Glioma Segmentation with Cascaded Unet [paper]
- Attention U-Net: Learning Where to Look for the Pancreas [paper]
- Recurrent Residual Convolutional Neural Network based on U-Net (R2U-Net) for Medical Image Segmentation [paper]
- Concurrent Spatial and Channel ‘Squeeze & Excitation’ in Fully Convolutional Networks [paper]
- A Probabilistic U-Net for Segmentation of Ambiguous Images (NIPS) [paper] [tensorflow]
- AnatomyNet: Deep Learning for Fast and Fully Automated Whole-volume Segmentation of Head and Neck Anatomy [paper]
- 3D RoI-aware U-Net for Accurate and Efficient Colorectal Cancer Segmentation [paper][pytorch]
- Detection and Delineation of Acute Cerebral Infarct on DWI Using Weakly Supervised Machine Learning (Y-Net) (MICCAI) [paper](Page 82)
- Fully Dense UNet for 2D Sparse Photoacoustic Tomography Artifact Removal [paper]
2019
- MultiResUNet : Rethinking the U-Net Architecture for Multimodal Biomedical Image Segmentation [paper][keras]
- U-NetPlus: A Modified Encoder-Decoder U-Net Architecture for Semantic and Instance Segmentation of Surgical Instrument [paper]
- Probability Map Guided Bi-directional Recurrent UNet for Pancreas Segmentation [paper]
- CE-Net: Context Encoder Network for 2D Medical Image Segmentation [paper][pytorch]
- Graph U-Net [paper]
- A Novel Focal Tversky Loss Function with Improved Attention U-Net for Lesion Segmentation (ISBI) [paper]
- ST-UNet: A Spatio-Temporal U-Network for Graph-structured Time Series Modeling [paper]
- Connection Sensitive Attention U-NET for Accurate Retinal Vessel Segmentation [paper]
- CIA-Net: Robust Nuclei Instance Segmentation with Contour-aware Information Aggregation [paper]
- W-Net: Reinforced U-Net for Density Map Estimation [paper]
- Automated Segmentation of Pulmonary Lobes using Coordination-guided Deep Neural Networks (ISBI oral) [paper]
- U2-Net: A Bayesian U-Net Model with Epistemic Uncertainty Feedback for Photoreceptor Layer Segmentation in Pathological OCT Scans [paper]
- ScleraSegNet: an Improved U-Net Model with Attention for Accurate Sclera Segmentation (ICB Honorable Mention Paper Award) [paper]
- AHCNet: An Application of Attention Mechanism and Hybrid Connection for Liver Tumor Segmentation in CT Volumes [paper]
- A Hierarchical Probabilistic U-Net for Modeling Multi-Scale Ambiguities [paper]
- Recurrent U-Net for Resource-Constrained Segmentation [paper]
- MFP-Unet: A Novel Deep Learning Based Approach for Left Ventricle Segmentation in Echocardiography [paper]
- A Partially Reversible U-Net for Memory-Efficient Volumetric Image Segmentation (MICCAI 2019) [paper][pytorch]
- ResUNet-a: a deep learning framework for semantic segmentation of remotely sensed data [paper]
- A multi-task U-net for segmentation with lazy labels [paper]
- RAUNet: Residual Attention U-Net for Semantic Segmentation of Cataract Surgical Instruments [paper]
- 3D U2-Net: A 3D Universal U-Net for Multi-Domain Medical Image Segmentation (MICCAI 2019) [paper] [pytorch]
- SegNAS3D: Network Architecture Search with Derivative-Free Global Optimization for 3D Image Segmentation (MICCAI 2019) [paper]
- 3D Dilated Multi-Fiber Network for Real-time Brain Tumor Segmentation in MRI [paper][pytorch] (MICCAI 2019)
- The Domain Shift Problem of Medical Image Segmentation and Vendor-Adaptation by Unet-GAN [paper]
- Recurrent U-Net for Resource-Constrained Segmentation [paper] (ICCV 2019)
- Siamese U-Net with Healthy Template for Accurate Segmentation of Intracranial Hemorrhage (MICCAI 2019)
2020
- U^2-Net: Going Deeper with Nested U-Structure for Salient Object Detection (Pattern Recognition 2020) [paper][pytorch]
- UNET 3+: A Full-Scale Connected UNet for Medical Image Segmentation (ICASSP 2020) [paper][pytorch]