
对于做人工智能来说,最主要的爬取目标是图片,需要在网上获取大量的图片数据用于模型训练。这里参考网上资料,自己写一个简单的爬虫程序。
1、爬取百度图片:
百度图片比较简单,通过一个ajax请求,来获取图片的url:
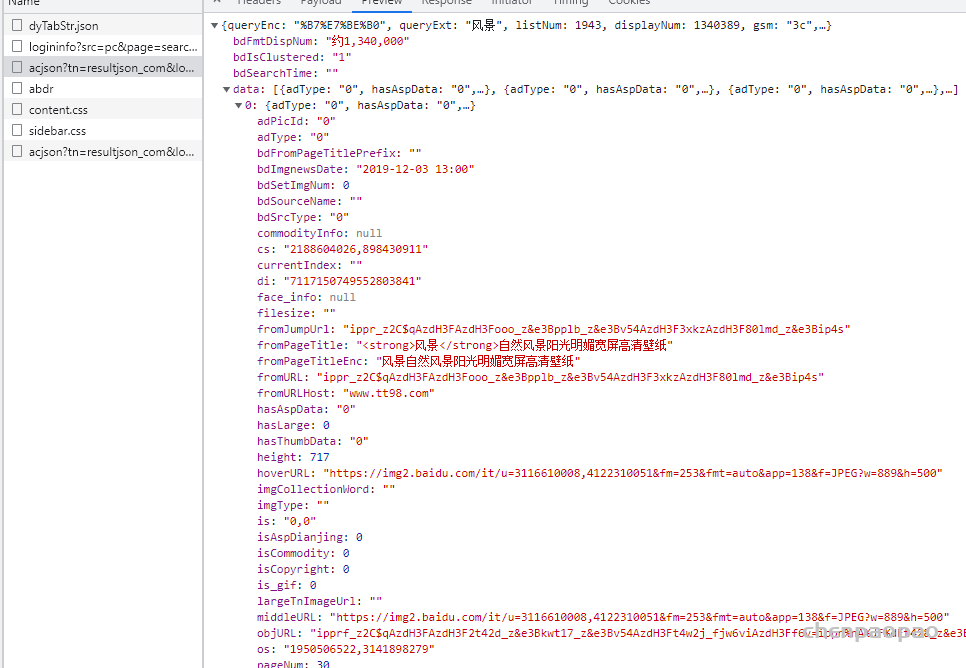
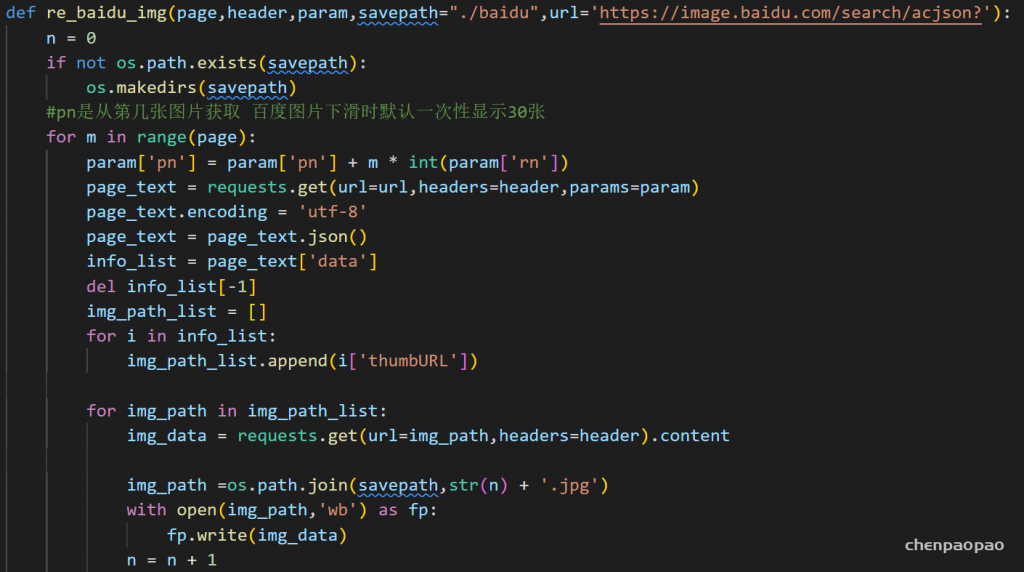
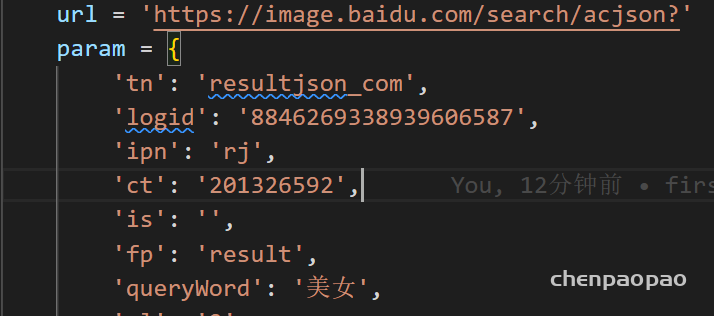
参数:

2、爬取 谷歌图片:
谷歌跟百度不同,需要使用 selenium
由于google图片界面是属于那种往下划会在本页面中加载出更多信息,但未刷新的机制,但是它又并未使用ajax。
所以这里我们使用selenium。selenium是一个能够模拟浏览器的工具,如果你没有安装,请pip install 一下。
然后是下载符合你的浏览器的驱动,我这里用的是Chrome,所以下载了ChromeDriver,将其放在D:\python\Scripts(你的python安装目录)。
用这两个来模拟用户的浏览器操作。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import time
import os
import urllib.request
import uuid
def download_pic(url, name, path):
if not os.path.exists(path):
os.makedirs(path)
res = urllib.request.urlopen(url, timeout=3).read()
with open(path + name +'.jpg', 'wb') as file:
file.write(res)
file.close()
def get_image_url(num, key_word):
box = driver.find_element_by_xpath('/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input')
box.send_keys(key_word)
box.send_keys(Keys.ENTER)
box = driver.find_element_by_xpath('//*[@id="hdtb-msb"]/div[1]/div/div[2]/a').click()
# 滚动页面
last_height = driver.execute_script('return document.body.scrollHeight')
while True:
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(2)
new_height = driver.execute_script('return document.body.scrollHeight')
try:
driver.find_elements_by_xpath('//*[@id="islmp"]/div/div/div/div/div[5]/input').click()
except:
pass
if new_height == last_height:
# 点击显示更多结果
try:
box = driver.find_element_by_xpath('//*[@id="islmp"]/div/div/div/div[1]/div[2]/div[2]/input').click()
except:
break
last_height = new_height
image_urls = []
for i in range(1, num):
try:
image = driver.find_element_by_xpath('//*[@id="islrg"]/div[1]/div[' + str(i) + ']/a[1]/div[1]/img')
# 此选项为下载缩略图
# image_src = image.get_attribute("src")
image.click() # 点开大图
time.sleep(4) # 因为谷歌页面是动态加载的,需要给予页面加载时间,否则无法获取原图url,如果你的网络状况一般请适当延长
# 获取原图的url
image_real = driver.find_element_by_xpath('//*[@id="Sva75c"]/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div[2]/div[1]/a/img')
image_url = image_real.get_attribute("src")
image_urls.append(image_url)
print(str(i) + ': ' + image_url)
except:
print(str(i) + ': error')
pass
return image_urls
if __name__ == '__main__':
# 创建一个参数对象,用来控制chrome是否以无界面模式打开
ch_op = Options()
# 设置谷歌浏览器的页面无可视化,如果需要可视化请注释这两行代码
ch_op.add_argument('--headless')
ch_op.add_argument('--disable-gpu')
url = "https://www.google.com/"
driver = webdriver.Chrome(r'D:\anconda3\chromedriver.exe', options=ch_op)
driver.get(url)
key_word = input('请输入关键词:')
num = int(input('请输入需要下载的图片数:'))
_path = input('请输入图片保存路径,例如G:\\\\google\\\\images\\\\ :')
# path = "G:\\google\\images_download\\" + key_word + "\\" # 图片保存路径改为自己的路径
path = _path + key_word + "\\"
print('正在获取图片url...')
image_urls = get_image_url(num, key_word)
for index, url in enumerate(image_urls):
try:
print('第' + str(index) + '张图片开始下载...')
download_pic(url, str(uuid.uuid1()), path)
except Exception as e:
print(e)
print('第' + str(index) + '张图片下载失败')
continue
driver.quit()