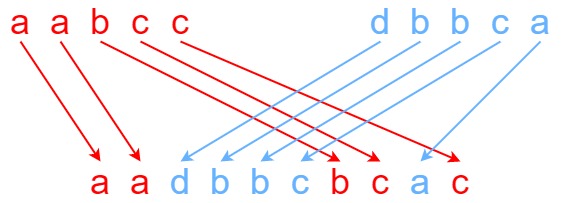
# [97] 交错字符串
#
# @lc code=start
class Solution:
def isInterleave(self, s1: str, s2: str, s3: str) -> bool:
len1=len(s1)
len2=len(s2)
len3=len(s3)
if(len1+len2!=len3):
return False
dp=[[False]*(len2+1) for i in range(len1+1)]
dp[0][0]=True
for i in range(1,len1+1):
dp[i][0]=(dp[i-1][0] and s1[i-1]==s3[i-1])
for i in range(1,len2+1):
dp[0][i]=(dp[0][i-1] and s2[i-1]==s3[i-1])
for i in range(1,len1+1):
for j in range(1,len2+1):
dp[i][j]=(dp[i][j-1] and s2[j-1]==s3[i+j-1]) or (dp[i-1][j] and s1[i-1]==s3[i+j-1])
return dp[-1][-1]
# @lc code=end
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
示例 1:
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
示例 2:
输入:head = [1,1,1,2,3]
输出:[2,3]
# [82] 删除排序链表中的重复元素 II
#
# @lc code=start
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def deleteDuplicates(self, head: ListNode) -> ListNode:
if not head:
return head
dummy = ListNode(0, head)
cur = dummy
while cur.next and cur.next.next:
if cur.next.val == cur.next.next.val:
x = cur.next.val
while cur.next and cur.next.val == x:
cur.next = cur.next.next
else:
cur = cur.next
return dummy.next
# @lc code=end
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
示例 1:
输入:root = [1,2,3,4,5,6,7]
输出:[1,#,2,3,#,4,5,6,7,#]
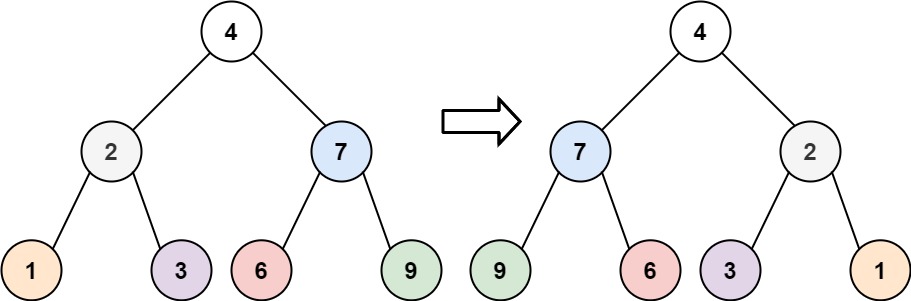
解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化的输出按层序遍历排列,同一层节点由 next 指针连接,'#' 标志着每一层的结束。
# @lc app=leetcode.cn id=116 lang=python3
#
# [116] 填充每个节点的下一个右侧节点指针
#
# @lc code=start
"""
# Definition for a Node.
class Node:
def __init__(self, val: int = 0, left: 'Node' = None, right: 'Node' = None, next: 'Node' = None):
self.val = val
self.left = left
self.right = right
self.next = next
"""
class Solution:
def connect(self, root: 'Optional[Node]') -> 'Optional[Node]':
if not root: return root #注意特殊情况:树为空返回[]
queue = [root]
import copy
while queue:
lens=len(queue)
for i in range(len(queue)):
a = queue.pop(0)#元素出队列
a.next=queue[0] if i<lens-1 else None
if a.left:
queue.append(a.left)
if a.right:
queue.append(a.right)
return root
# @lc code=end
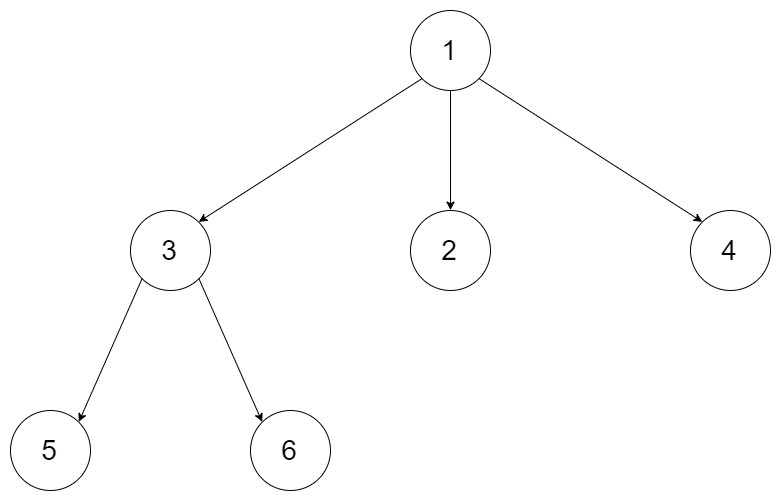
# [429] N 叉树的层序遍历
#
# @lc code=start
"""
# Definition for a Node.
class Node:
def __init__(self, val=None, children=None):
self.val = val
self.children = children
"""
class Solution:
def levelOrder(self, root: 'Node') -> List[List[int]]:
if not root: return [] #注意特殊情况:树为空返回[]
queue = [root]
list1 = []
while queue:
list2 = []
lens=len(queue)
for i in range(lens):
a = queue.pop(0)#元素出队列
for i in range(len(a.children)):
queue.append(a.children[i])
list2.append(a.val)
list1.append(list2)
return list1
# @lc code=end