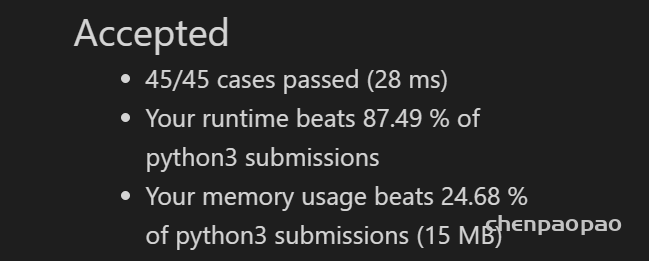
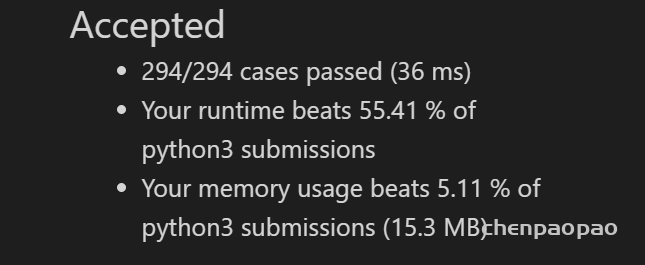
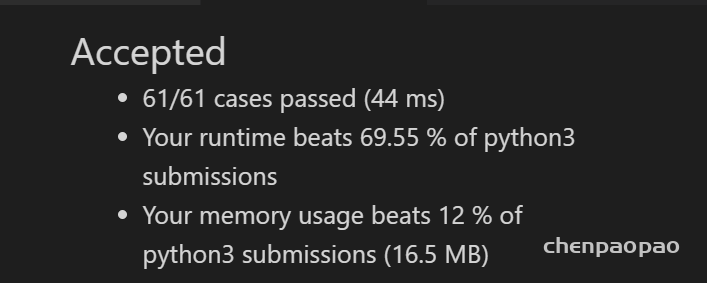
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
示例 1:
输入:n = 2 输出:2 解释:有两种方法可以爬到楼顶。 1. 1 阶 + 1 阶 2. 2 阶
示例 2:
输入:n = 3 输出:3 解释:有三种方法可以爬到楼顶。 1. 1 阶 + 1 阶 + 1 阶 2. 1 阶 + 2 阶 3. 2 阶 + 1 阶
动态规划 or 递归
# @lc app=leetcode.cn id=70 lang=python3
#
# [70] 爬楼梯
#
# @lc code=start
class Solution:
def climbStairs(self, n: int) -> int:
dp=[0 for i in range(n)]
for i in range(n):
if i == 0:
dp[0]=1
continue
if i == 1:
dp[1]=2
continue
dp[i]=dp[i-1]+dp[i-2]
return dp[n-1]