https://github.com/KMnP/vpt
https://github.com/hjbahng/visual_prompting
Visual Prompt Tuning

最近NLP领域提出了Prompt范新式,企图革新原先的Fine-tuning方法,而在CV领域中,Prompt其实可以理解为图像label的设计,从这个角度看,Prompt(预测文本中mask的字符,类似完形填空)其实是介于Image caption(迭代预测出每一个字符)和one-hot label(one-hot可以认为是prompt的特例,单字符通过text encoder成one-hot)之间的任务。最近在Visual-Language Model(缩写VLM)任务中,prompt开始展现出强大的能力.
Fine-tuning中:是预训练语言模型“迁就“各种下游任务。具体体现就是上面提到的通过引入各种辅助任务loss,将其添加到预训练模型中,然后继续pre-training,以便让其更加适配下游任务。总之,这个过程中,预训练语言模型做出了更多的牺牲。
Prompting中,是各种下游任务“迁就“预训练语言模型。具体体现也是上面介绍的,我们需要对不同任务进行重构,使得它达到适配预训练语言模型的效果。总之,这个过程中,是下游任务做出了更多的牺牲。
Abstract
目前调整预训练模型的方法是full fine-tuning,即完全微调。本文介绍Visual Prompt Tuning(VPT)作为一种有效的用于大规模Transformer的视觉微调。它只需要在输入空间引入少量(不到1%的模型参数)的可训练参数,同时冻结backbone。会发现在很多情况下,优于完全微调。
Introduction
对于大规模模型适应下游任务时,通常的策略是进行端到端的全面微调,然而这种策略需要为每个人物存储部署单独的主干参数,代价比较高,毕竟现在的Transformer体系结构比较大。
一种简单的方法是使用已经完善的其他策略,如下图(a):仅微调参数的子集,如分类器头部或者偏差项。之前的研究还会试着向主干添加额外的残差结构或者adapter,可以对Transformer实施类似的策略。然而,这些策略会在准确度上执行完全微调。
作者试图探索一种不同的方法:并不通过改变或者微调预训练好的Transformer本身,而是修改其输入。如下图(b)所示:将少量特定任务的可学习参数引入输入空间,同时在下游训练期间冻结backbone。实践中,这些附加参数只是预先加入到Transformer每层输入序列中,并在微调时和线性头一起学习。
在预训练主干用ViT的24个跨域的下游任务中,VPT优于了其他迁移学习的baseline,有20个超过了完全微调,同时保持了为每个单独任务储存较少参数的优势。(NLP任务中,prompt tuning旨在某些情况下才匹配完全微调的性能)。如下图(c)所示,VPT在地数据区尤其有效,结果也进一步表明,VPT是适应不断增长的视觉主干的最有效方法之一。
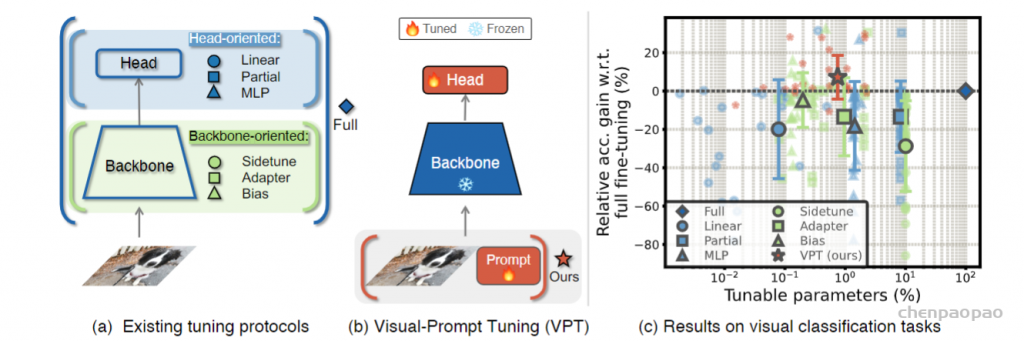
transfer learning protocols are grouped based on the tuning scope: Full fine-tuning,
Head-oriented, and Backbone-oriented approaches. (b) VPT instead adds extra pa-
rameters in the input space. (c) Performance of different methods on a wide range
of downstream classification tasks adapting a pre-trained ViT-B backbone, with mean
and standard deviation annotated. VPT outperforms Full fine-tuning 20 out of 24 cases
while using less than 1% of all model parameters
Related Work
迁移学习两种代表性方法:Adapter在每个Transformer层后插入一个额外的小模块。通常包含一个线性向下头像、线性向上投影及一个残差连接。BitFit是在微调网络时更新偏置项并冻结其余backbone参数。这些方法在NLP已经成熟运用。作者则进一步实验表明了VPT在视觉任务的Transformer的模型调整上性能更加良好。
Prompt最初指的是在输入文本中预编语言汁了,以便预训练好的LM(Language Model)能够“理解”任务。最近的工作则是将prompt视为任务特定的连续向量,并在微调过程中通过梯度直接优化,即Prompt Tuning。prompting依然局限于文本编码器的输入。作者是第一个解决(同样的方法能成功的应用到视觉主干)并研究视觉prompt的普遍性和可行性的工作。
Approach
整体框架图如下图所示:
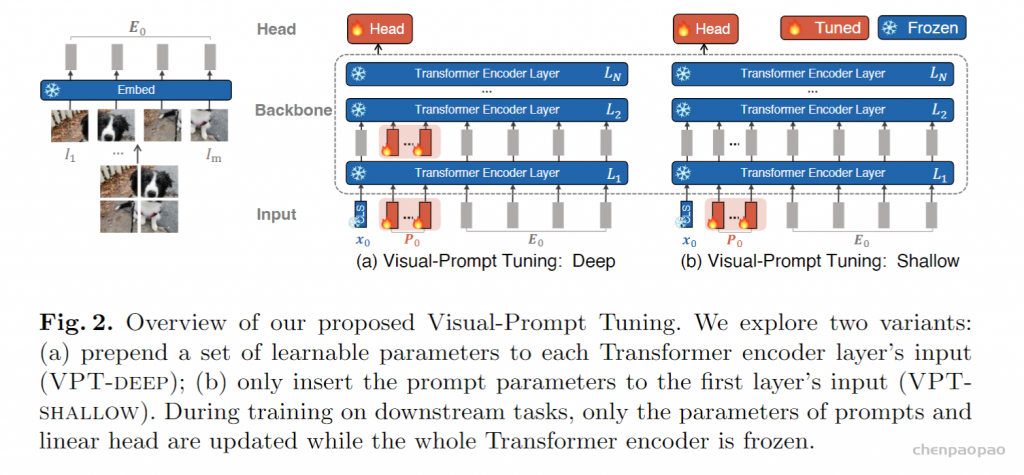
Visual-Prompt Tuning:
给定一个预先训练好的Transformer,在Embed层后的输入空间引入一组d维的p连续embedding。在微调过程中,只有prompt会被更新,主干将会冻结,根据加入prompt的层数量分为浅VPT和深VPT。
浅VPT :
Prompt仅插入第一层。每一个prompt token都是一个可学习的d维参数。集合和浅VPT表示如下:
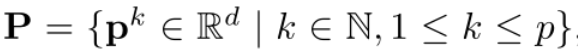
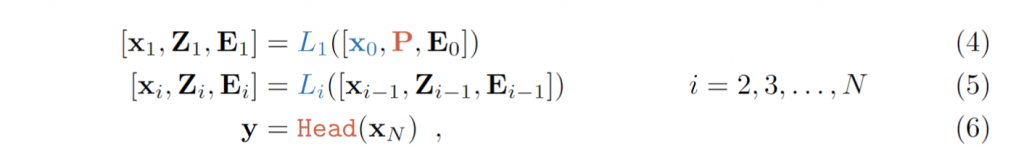
VPT-Deep: Prompt被插入每一层的输入控件。集合和深VPT表示如下:

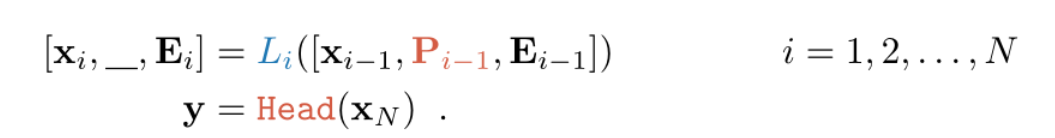
VPT对于多个下游任务都是有帮助的,只需要为每个任务存储学习到的prompt和分类头,重新使用预训练的Transformer,从而显着降低存储成本。
Experiments:
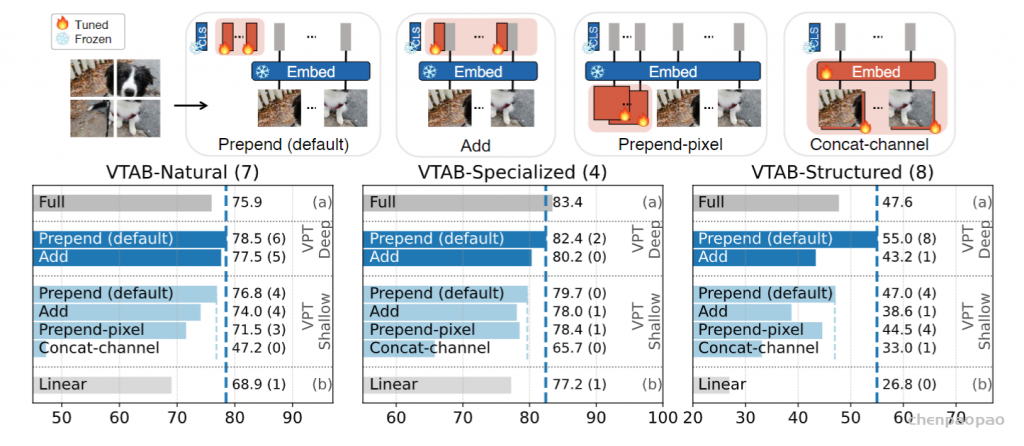
上图是关于prompt的位置,本文提出的是prepend,与直接在embedding上添加对比效果更好。除此之外,作为前置像素或者concat通道的效果也都在下降。
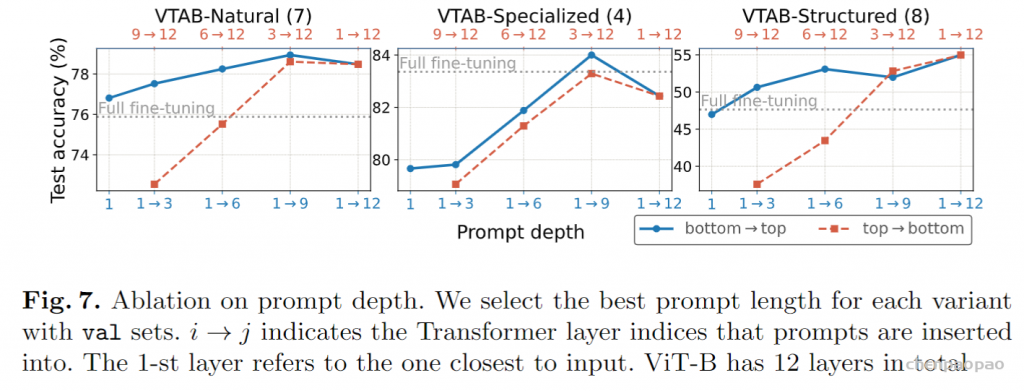
下图则是对prompt长度、深度的消融实验:
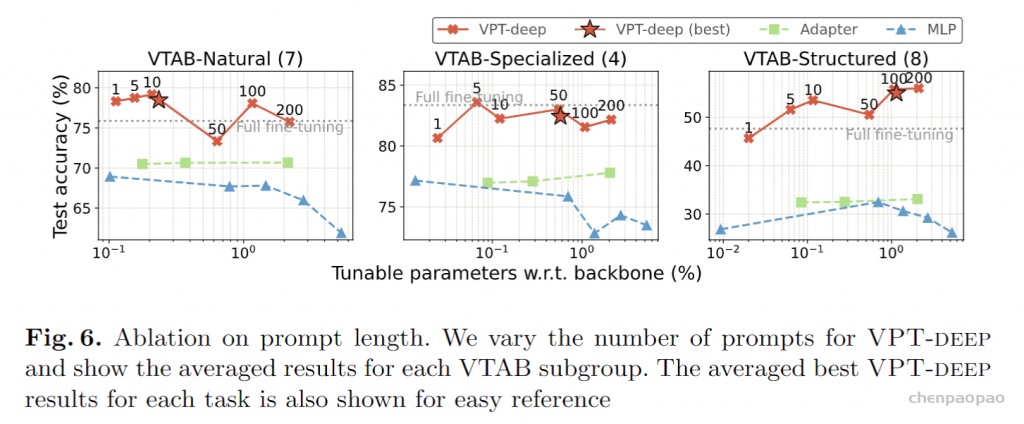
最佳提示长度因任务而异,即使只有一个prompt,深VPT的效果仍显着优于另外两种方法。
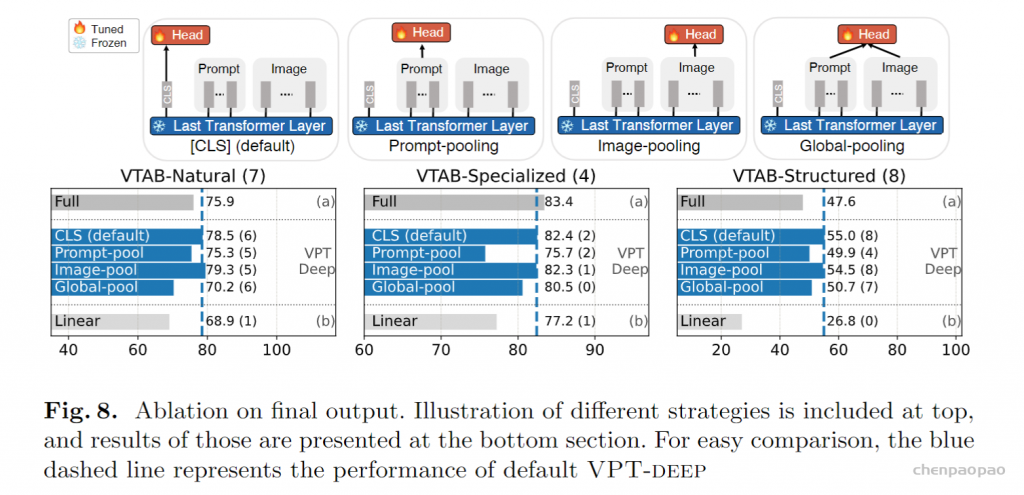
下图为最终输出的消融实验:
补充:
CoOp:
CoOp明显是受到了AutoPrompt的启发,并且CoOp发现CLIP实际上就是prompt在visual-language model中的一个应用,于是CoOp在CLIP的基础上进一步进行改进。

CoOp先在四个数据集上做实验,发现更合理的prompt能够大幅度的提升分类精度尤其是使用了本文提出的CoOp之后,最终的分类精度远超CLIP人为设计的prompt。
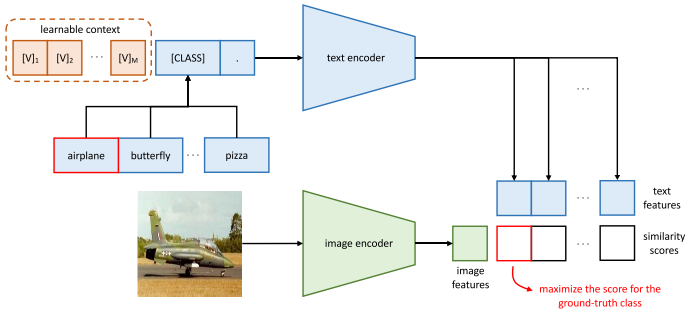
和CLIP的主要不同之处在于,CoOp在CLIP的第二个阶段中引入了context optimization。具体的,CoOp将prompt设计为:
t=[V]1[ V]2…[V]M[CLASS]
其中每个[V]M向量跟word embedding的维度相同,可以理解为可学习的context,并且所有类别对应的context共享参数。
Exploring Visual Prompts for Adapting Large-Scale Models
这篇文章参考了Ian Goodfellow等人(2018)对抗样本中的对抗重编程思想, 对抗重编程的目标是我使用一个任务A的网络(无需重新训练该网络)来做任务B。我们设一个经过训练的模型,其原本的任务是,给定输入x,会得到输出f(x)现在有一个攻击者,其对抗任务是对于给定的输入x~,会得到输出g(x~),这里x~和x不一定需要是同域的。这看起来是不可行的,但是攻击者通过学习对抗重编程函数hf(.;θ)和hg(.;θ)来实现这两个任务之间的映射。hf(.;θ)用于将输入从x~所在的域转换到x所在的域,也就是说,经过hf的处理后得到的hf(x~;θ)对于f而言是有效的输入;而hg则将f的输出f(h(x~;θ))映射会g(x~)的输出。
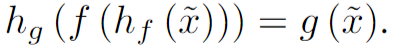
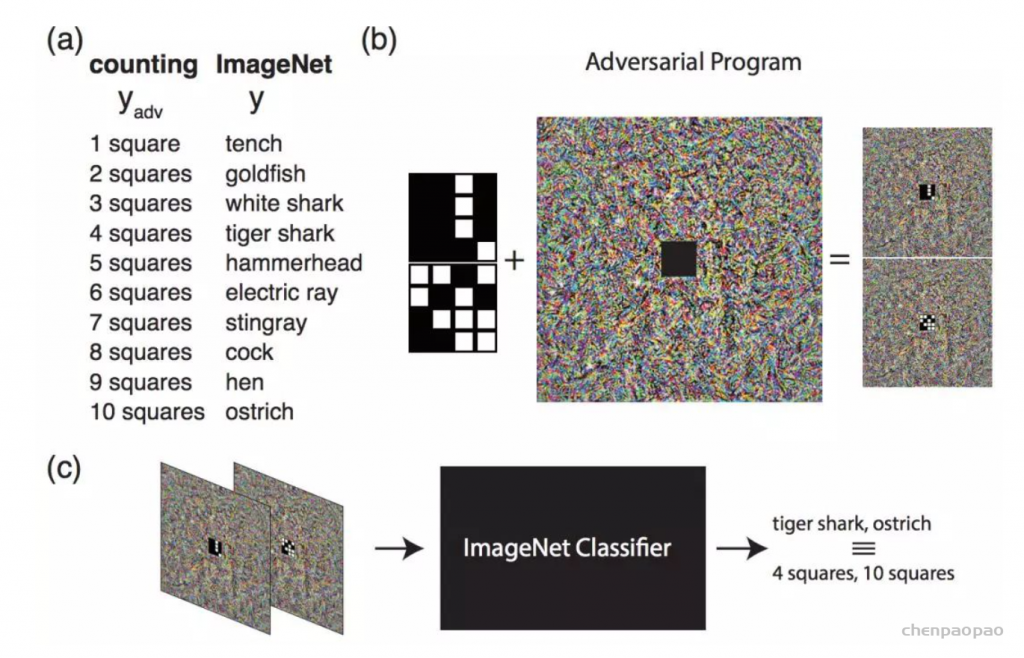
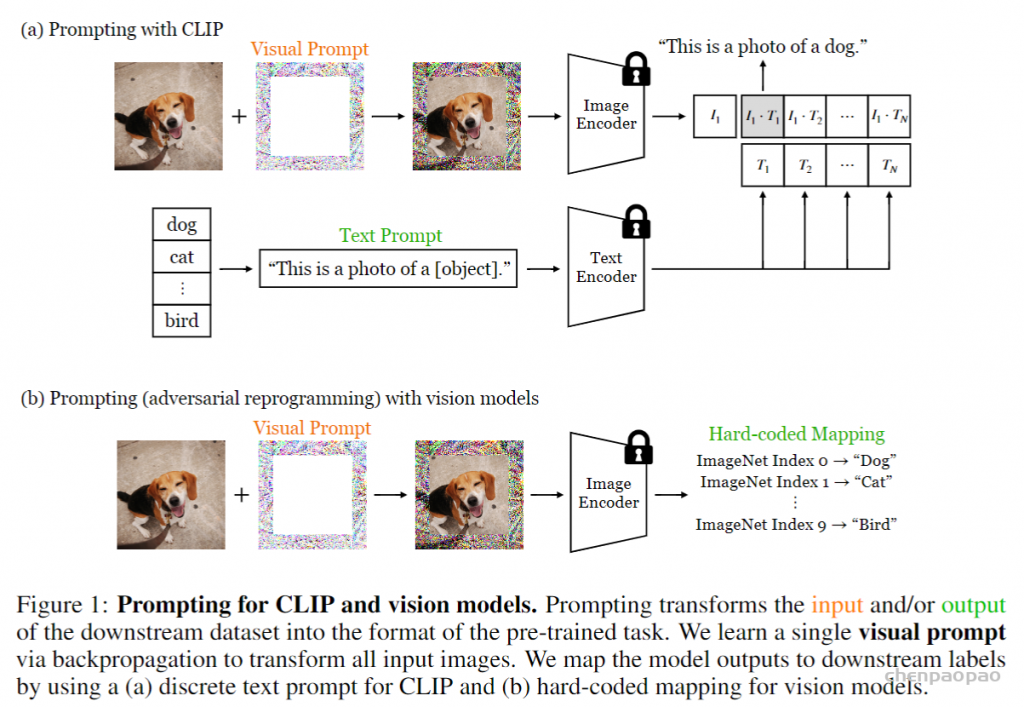
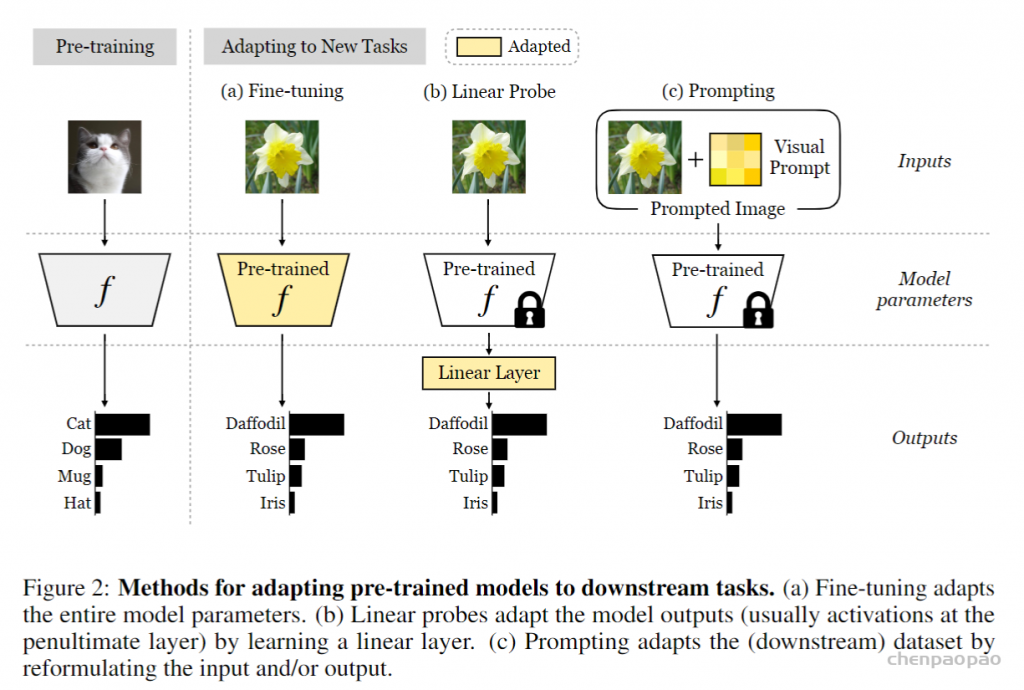
图2提供了适应预训练模型的不同方法的摘要。微调和线性探测的用法非常灵活:它们可用于使模型适应新的输入域或具有不同输出语义的新任务。但是,在线性探针的情况下,在微调和模型输出(通常在倒数第二层的激活)的情况下,他们还需要一定程度的访问模型:参数。域的适应性是模型适应的有趣替代方法,因为它仅使用图像到图像翻译等技术来修改模型的输入[50,19]。像域的适应性一样,视觉提示也将输入修改为模型。因此,一旦最终用户找到了视觉提示,就不需要在测试时间控制模型本身。这打开了独特的应用程序;例如,用户可以将适应域的图像馈送到只能通过输入来操纵的在线API。域的适应性重点是调整源域以看起来像目标域,同时需要源和目标数据集。另一方面,我们认为视觉提示可以以更任意的方式引导模型。例如,可以通过扰动输入像素来使用新的输出语义进行一个完全不同的分类任务来执行完全不同的分类任务。同样,尽管域适应方法通常是输入条件,但我们在本文中探索的视觉提示是固定的(即输入 – agnostic),如NLP,例如在NLP中,将相同的自然语言提示添加到所有模型查询中