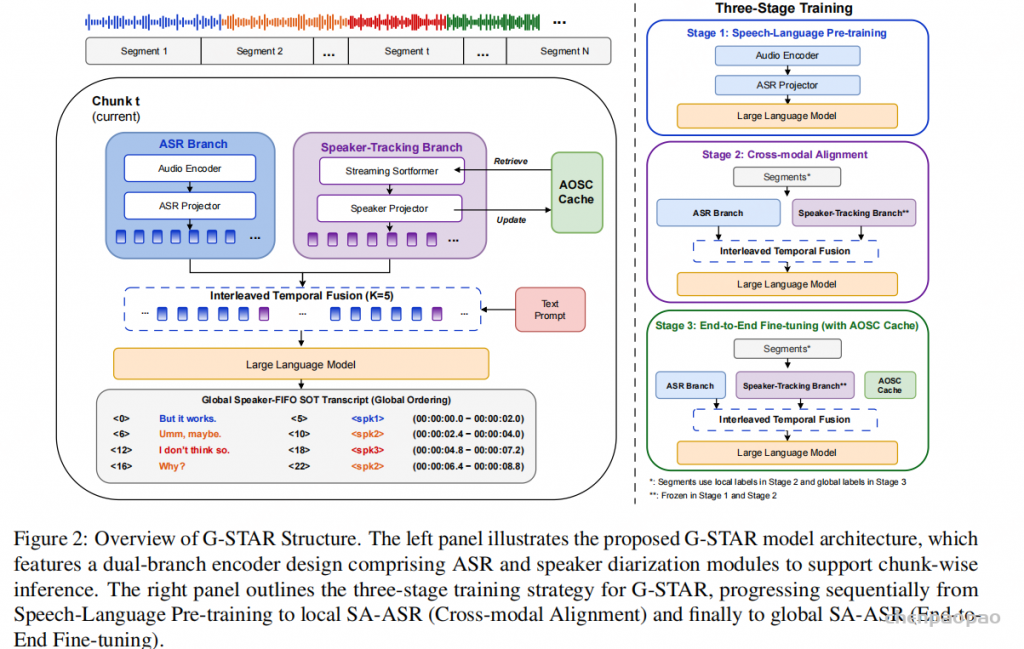
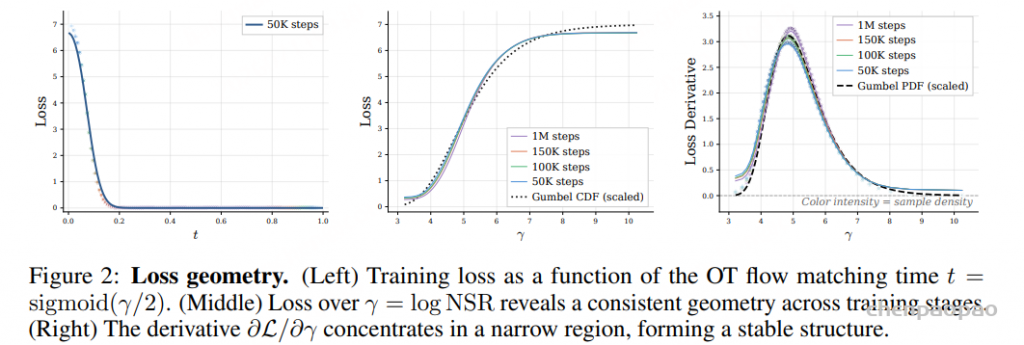
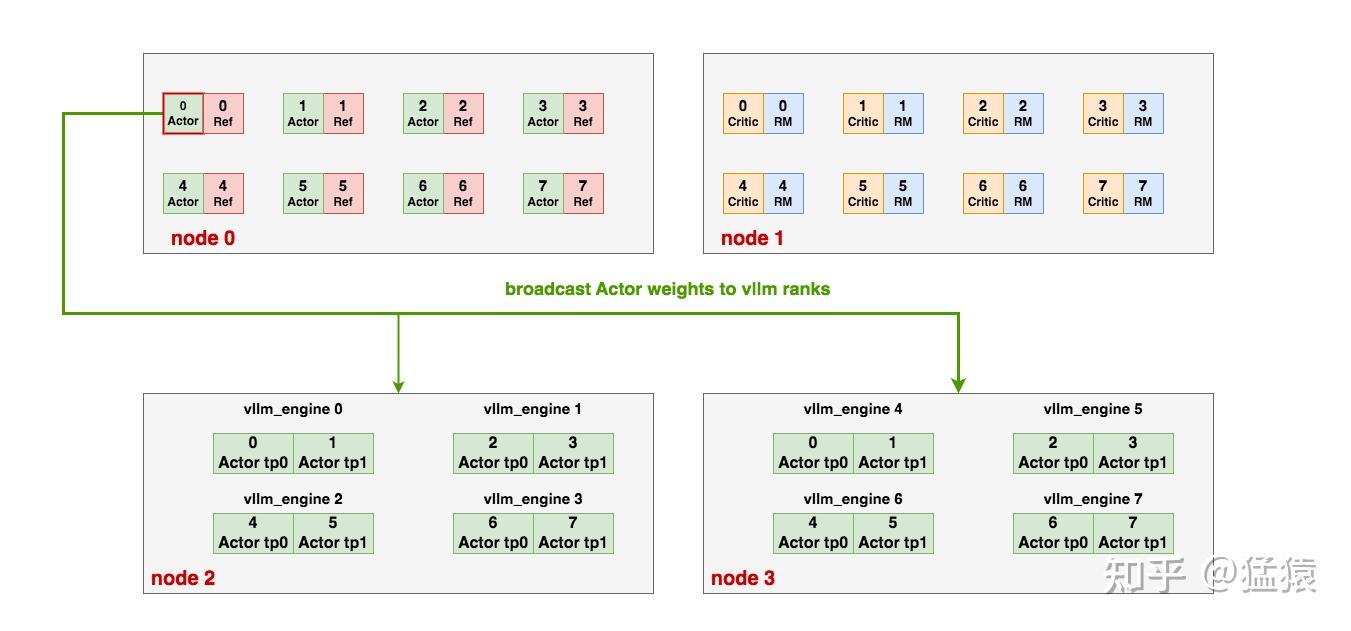
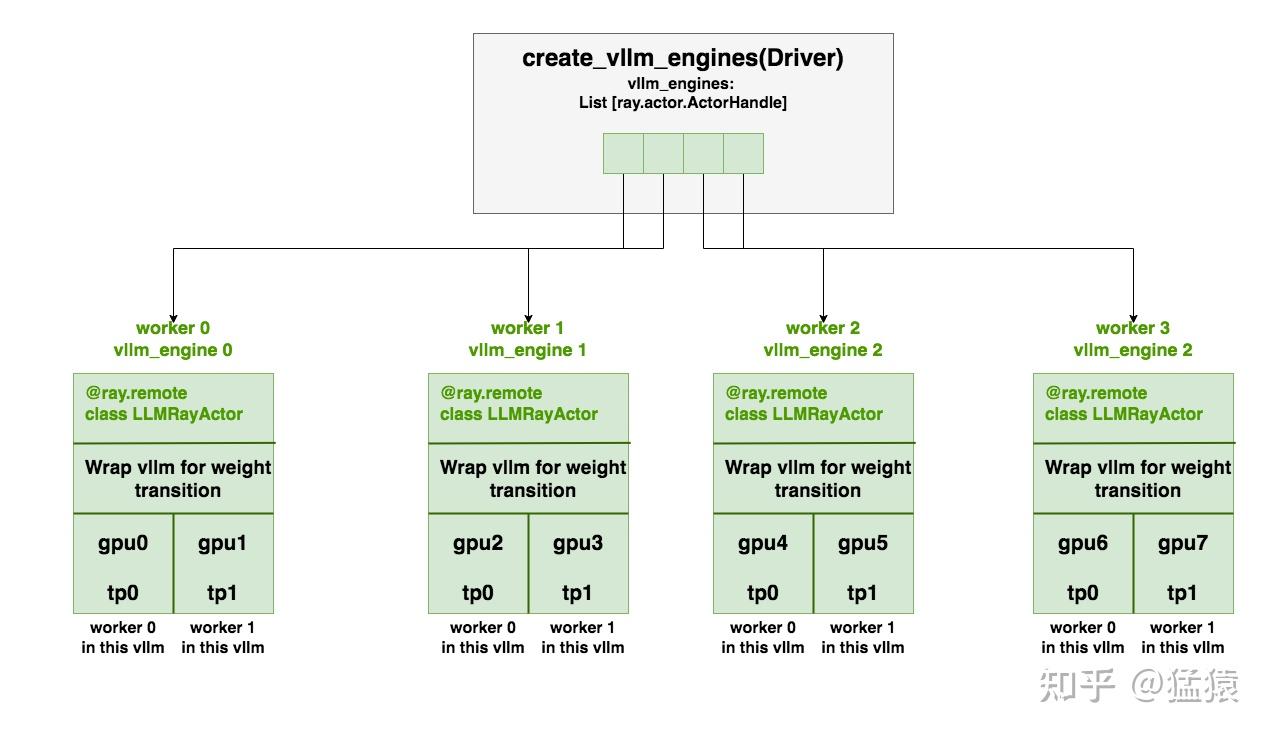
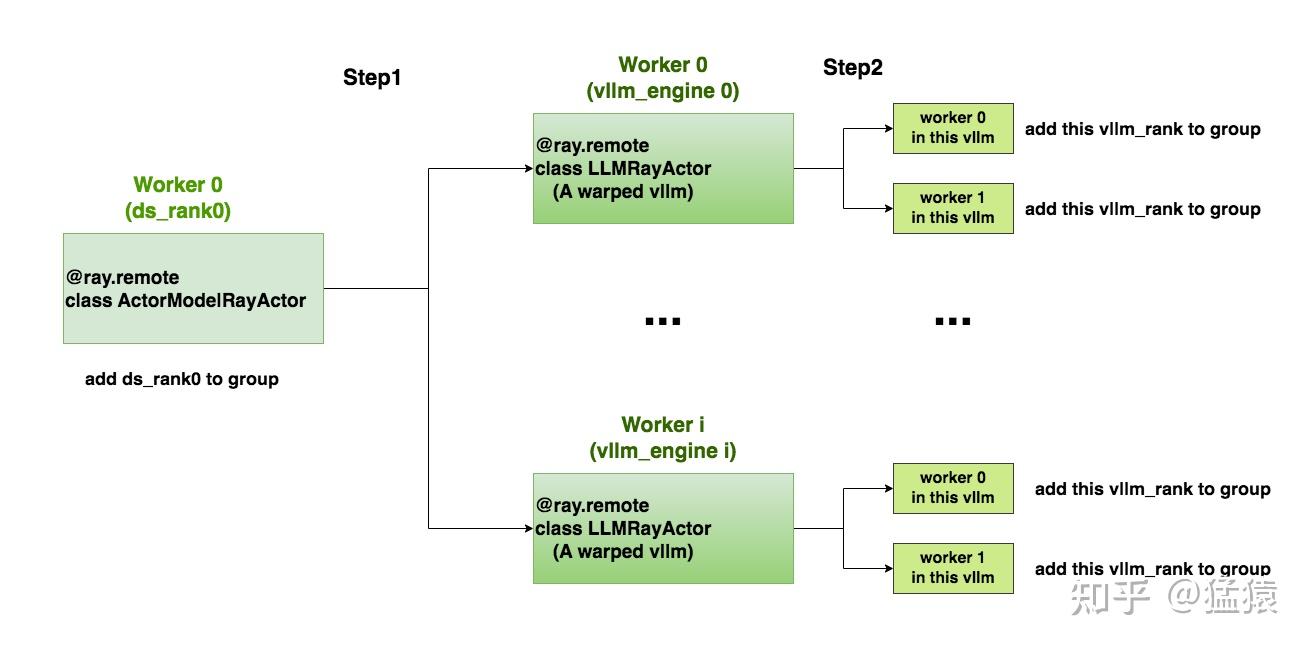
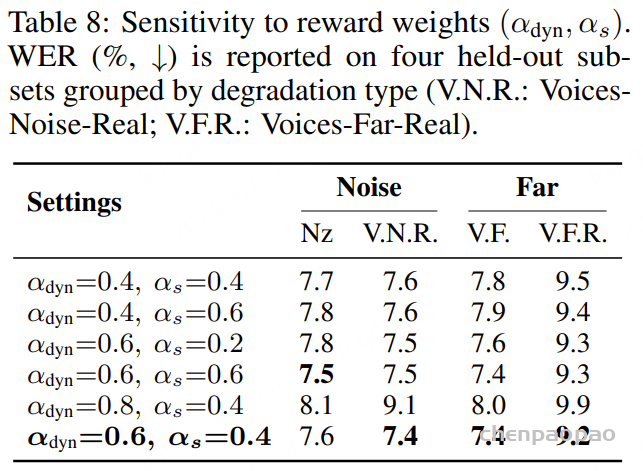
这篇论文 Mixture-of-Expert Conformer for Streaming Multilingual ASR 讨论的是一个更偏工业部署的问题:如何让一个流式端到端 ASR 模型同时支持多种语言,又不把推理成本推到端侧设备难以承受的程度。作者选择的路线是把 Mixture-of-Experts 放进 Conformer,把模型总容量做大,但每次推理只激活一小部分参数。
摘要:容量变大,激活参数不线性变大
论文提出的模型是在流式多语种 Conformer 中加入 MoE 层。MoE 层由多个 FFN 专家和一个 softmax gate 组成,每个输入帧只选择权重最高的两个专家参与计算。这样,专家总数可以增加,模型总容量也可以增加,但推理时激活的专家数固定,因此计算和激活参数不会随专家数量线性增长。
论文中的 gate 先对第 l 层输入 x 做线性映射,再通过 softmax 得到专家权重:
\(
g_l=\mathrm{Softmax}(W_l\cdot x)
\)
随后只取 top-2 expert,并把两个 expert 的输出按 gate 权重加权求和:
\(
y=\sum_{i=1}^{2}g_{l,i}\cdot e_{l,i}
\)
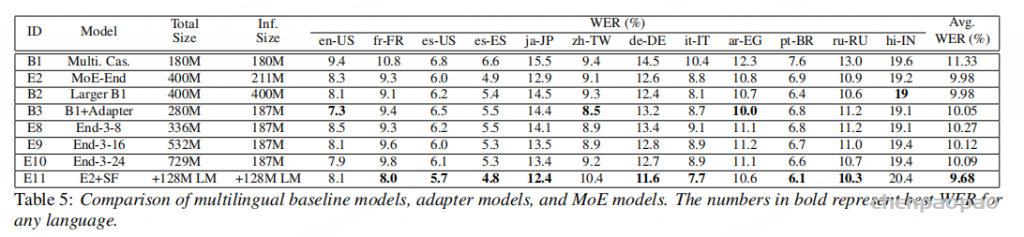
实验覆盖 12 个语言 locale。相对于 180M 参数的多语种 cascaded Conformer baseline,MoE-End 模型把平均 WER 从 11.33 降到 9.98,约 11.9% 相对改善。与同等总规模的 dense baseline 相比,MoE 达到类似 WER,但推理激活参数约为 211M,对比 dense 的 400M 更省。再结合多语种 neural LM 做 shallow fusion,平均 WER 还能进一步相对降低约 3%。
引言:多语种统一模型的容量问题
多语种端到端 ASR 的吸引力很直接:用一个模型识别多种语言,降低维护和部署复杂度。过去几年,CTC、LSTM、attention-based 模型以及流式 RNN-T 都在多语种 ASR 上取得了进展。尤其是端侧流式场景,模型既要有识别质量,又要满足低延迟和低计算。
经验上,模型容量越大,多语种 ASR 越容易受益。Whisper、USM 等大型模型也说明了大数据和大模型对语音识别质量的推动作用。但大模型的代价是训练和推理成本。对端侧应用来说,不能简单把模型扩大到数十亿参数。
已有一些效率方案依赖语言相关组件,比如按语言选择 adapter 或二阶段模型。但流式场景里,稳定预测语言信息本身就不容易,还可能引入错误传播。本文的 MoE 路线更直接:由输入表示动态选择专家,不需要显式语言标签,也不需要 ground-truth language information。
相关工作:专家模型与语言信息
论文把自己的方法放在几类工作之间比较。第一类是 ASR 中已有的 MoE 模型,但许多工作偏单语种,或者需要额外的共享 embedding 网络来做专家路由。第二类是 NLP 和视觉中的 MoE,比如 Switch Transformer 或 DeepMoE,不过这些结构在 ASR 尤其是流式多语种 ASR 中的直接效果并不确定。
第三类是 informed-expert:模型根据已知语言信息选择某个语言专家、adapter 或二阶段模块。这种做法在有可靠语言标签时很自然,但部署中会遇到两个麻烦:语言信息要么来自外部,要么需要模型先预测;一旦预测错了,后面的专家选择也会受影响。本文的 MoE 不显式使用语言信息,routing 由模型从声学表示中学出来。
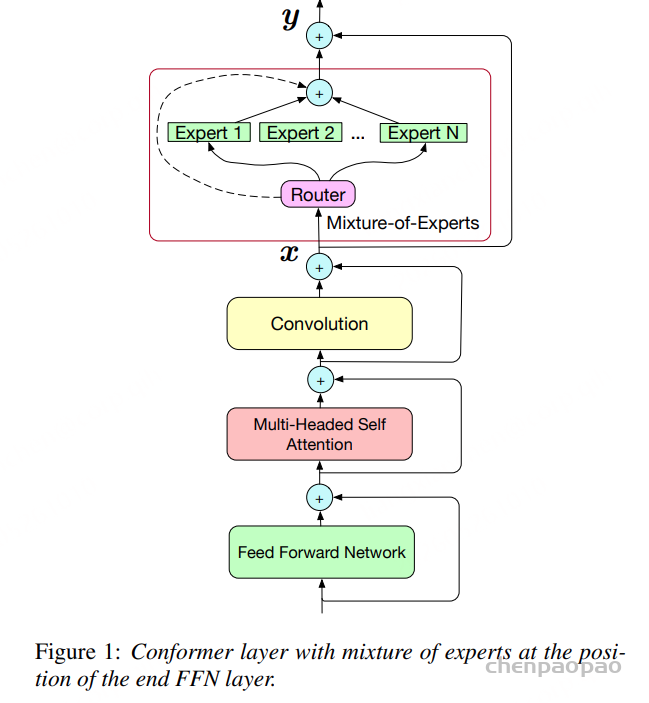
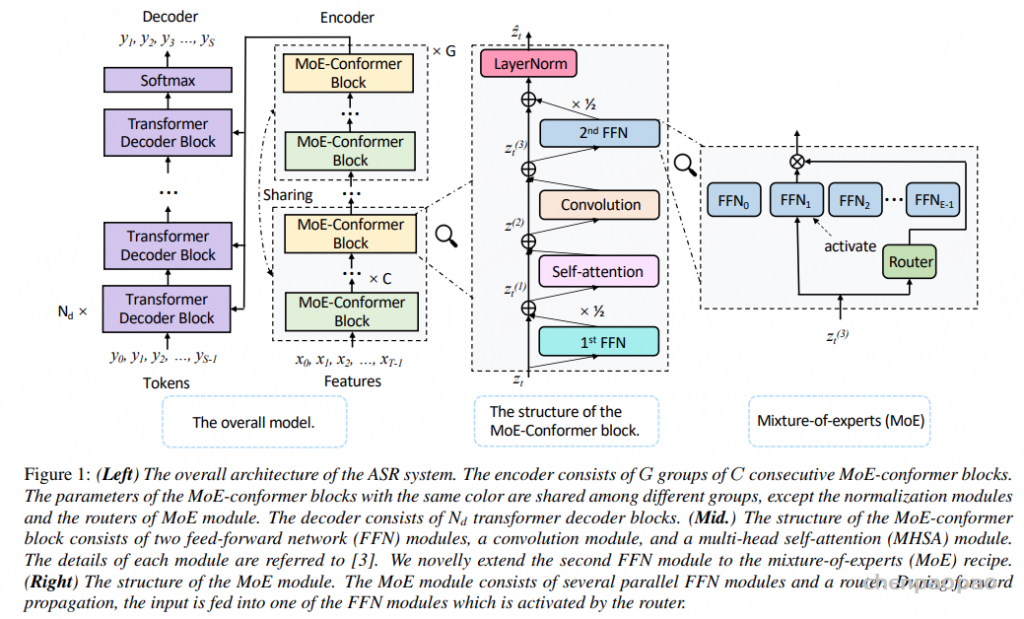
MoE Conformer:把专家放在 FFN 位置
基础模块是 Conformer。一个 Conformer layer 通常包含两个 FFN、中间的 self-attention 和 convolution。作者把 MoE 主要用于替换 Conformer 里的 FFN,尤其是 end FFN。每个 MoE 层包含多个 FFN 专家和一个 router。
对每一帧表示,router 通过 softmax 计算各专家权重,然后选出 top-2 专家。两个专家的输出按路由权重加权求和,得到该 MoE 层输出。训练和推理都使用 top-2。为了防止专家使用不均衡,论文加入辅助负载均衡损失,让不同专家都有机会被训练到。
这个设计的关键是稀疏激活。比如总共有 8 个、16 个或 24 个专家时,每帧仍只走两个专家。总参数代表模型潜在容量,激活参数代表推理成本;MoE 的优势就在于让这两者不再完全绑定。
实验设置
模型训练使用 RNN-T loss,并额外加入专家负载均衡项。论文中的 auxiliary loss 写成:
\(
l_{\mathrm{aux}}=\frac{1}{N}\sum_{i=1}^{N}c_i\cdot m_i
\)
其中 m_i 是第 i 个 expert 的平均 gate,c_i 是 top-2 路由中该 expert 被选择的计数。
数据
实验使用 12 个语言 locale:美式英语、中文、法语、德语、日语、美式西班牙语、西班牙西班牙语、阿拉伯语、意大利语、印地语、葡萄牙语和俄语。训练数据来自 Voice Search、YouTube 等多个域,总计约 139.4M 条人工转写匿名语音。不同语言数据量差异很大,从 0.5M 到 25.2M utterances 不等。
测试集来自 Voice Search 流量,每个语言大约 1.4K 到 10K 条 utterances,与训练集不重叠。评价指标是 WER;对中文等语言,论文按字符计算错误率。
模型细节
baseline 是一个语言无关的多语种 transducer 模型,包含 7 层 causal Conformer encoder 和 10 层 non-causal cascaded encoder。causal 部分保证流式,non-causal cascaded 部分提供约 0.9 秒右上下文。模型使用 separate decoders 分别服务 causal 和 non-causal encoder,以获得更好质量。baseline 总参数约 180M。
MoE 改造主要发生在 cascaded encoder。作者尝试替换 start FFN、end FFN 或两者都替换。最多使用 24 个专家,但每次训练和推理只选 top-2。输入特征为 128 维 log-Mel filterbank,经连续帧堆叠形成 512 维输入,并下采样到 30ms 帧率;训练中使用 SpecAug 增强鲁棒性。
结果与比较
消融实验
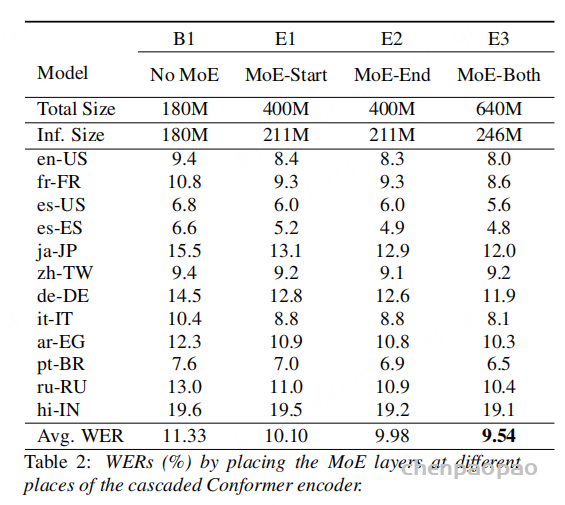
首先看 MoE 放在哪里。baseline 平均 WER 为 11.33。把 MoE 放在 start FFN,平均 WER 为 10.10;放在 end FFN,平均 WER 为 9.98;两处都放,平均 WER 最好,为 9.54。不过两处都放会增加推理激活参数。作者最终更多采用 MoE-End,因为它在质量和效率之间更均衡。
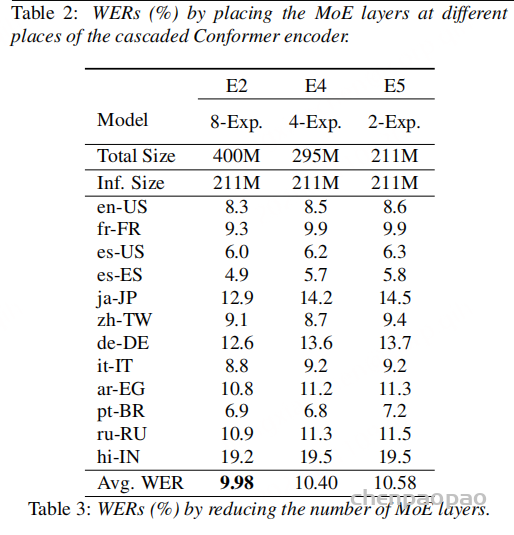
专家数量方面,8 experts 的 MoE-End 平均 WER 为 9.98;减少到 4 experts 后为 10.40;减少到 2 experts 后为 10.58。由于推理始终激活 top-2,专家总数减少主要影响总容量而不是激活参数。结果说明,额外专家确实被模型利用了。
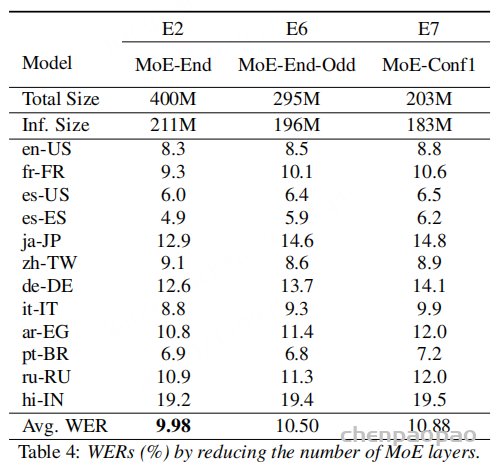
MoE 层数也很重要。只在隔层使用 MoE,平均 WER 退到 10.50;只在第一个 Conformer 层使用 MoE,为 10.88。即便只加一个 MoE 层也比 baseline 好,但完整地在 end FFN 位置加入 MoE 才能发挥主要效果。
与 dense baseline 和 adapter 比较
与 180M baseline 相比,MoE-End 模型总参数约 400M,推理激活约 211M,平均 WER 从 11.33 降到 9.98。为了排除“只是模型变大”的因素,作者构造了一个同为 400M 的大 dense baseline。这个 dense 模型平均 WER 也是 9.98,但推理需要激活 400M 参数;MoE 只激活 211M,约为 dense 的 53%。
与基于 ground-truth language information 的 adapter 模型相比,MoE 的意义更明显。Adapter 模型依赖真实语言信息选择对应模块;MoE 不需要语言标签,只根据输入动态路由。把 FFN multiplier 调小并增加专家数后,16 或 24 experts 的 MoE 在平均 WER 上接近 adapter,但部署上少了语言信息依赖。
Shallow Fusion 进一步提升
作者还训练了一个 128M 左右的多语种 neural LM,并在解码时做 shallow fusion。文本数据来自 12 种语言的监督训练文本和额外 text-only 数据。加入 LM 后,MoE 模型平均 WER 从 9.98 进一步降到 9.68,约 3% 相对改善。
不过改善并非所有语言都一致。法语收益最大,中文和印地语出现退化。作者推测,中文退化可能与 text-only 数据里混入粤语转写有关;印地语则可能因为 text-only 数据规模很大但与 Search 域不完全匹配,需要更好的过滤策略。
结论:MoE 的部署价值在于“不需要语言标签”
这篇论文展示了 MoE 在流式多语种 ASR 中的一个清晰用途:用更大的总容量提升多语种识别质量,同时通过 top-2 稀疏激活控制推理成本。最重要的是,模型不依赖语言标签完成专家选择,这比 adapter 或 per-language expert 在真实部署中更省心。
从结果看,MoE-End 相对于 baseline 有 11.9% 平均相对 WER 改善;与同规模 dense 模型相比,达到类似质量但只激活约 53% 参数;与语言标签 adapter 相比,质量接近但路由更自动。对端侧、流式、多语种这三个约束同时存在的场景,这种“动态容量”思路很值得继续跟进。
这篇论文 Parameter-Efficient Conformers via Sharing Sparsely-Gated Experts for End-to-End Speech Recognition 关注一个非常实际的问题:Conformer 在端到端语音识别里效果很好,但模型层数和参数量上来之后,训练、部署、端侧运行都会变重。作者的思路不是简单砍层,也不是只做普通的参数共享,而是把“共享 Conformer 块”和“稀疏门控专家”结合起来,让少量参数被重复使用,同时用 MoE 保住表示容量。
摘要:少参数,不想少能力
论文的核心目标是构造一个参数高效的 Conformer 编码器。传统跨层权重共享可以减少参数,但也会压缩模型容量,导致识别性能下降。作者提出的方案是在共享的 Conformer 块中加入 sparsely-gated MoE:第二个前馈网络不再是单一路径,而是一组专家,由路由器选择其中一个专家参与计算。这样总参数增加了一些,但每次前向只激活一个专家,计算量基本保持在非 MoE 模型的水平。
为了让共享块在不同深度位置仍能适配不同层级的表示,论文还让路由器和归一化层保持独立,而不是所有内容都共享。最后,作者用全参数模型作为 teacher,通过隐藏层表示的知识蒸馏进一步弥补共享模型的能力损失。实验显示,在 AISHELL-1 上,最终模型用约三分之一的编码器参数取得了接近全参数模型的 CER。
引言:Conformer 很强,但部署不轻
端到端 ASR 中,Transformer 和 Conformer 已经是很常见的编码器选择。Conformer 在 Transformer 的全局建模基础上加入卷积模块,更适合语音这种既有长程依赖、又有局部结构的序列。相对位置编码、Macaron 风格 FFN、卷积增强等设计,都让它在语音识别中表现稳定。
问题在于,这类模型往往参数冗余。直接堆很多层可以换来更强表达,但也带来显存、存储和推理成本。已有工作会通过跨层共享参数降低模型规模,类似让同一个 block 被重复调用多次。这个办法省参数,但副作用也明显:自由参数少了,模型容量下降,性能容易掉。
作者的切入点是:既然共享会损失容量,那就在共享块内部引入 MoE 来补容量;既然 MoE 可以稀疏激活,那就只让少数专家参与一次前向,避免计算量跟着总参数线性增长。这个组合特别适合“参数少、计算不能太贵”的场景。
背景:Conformer Seq2Seq ASR
论文使用的是 attention-based encoder-decoder 框架。编码器把声学特征序列变成高层表示,解码器按 token 逐步生成文本序列,训练时优化负对数似然,推理时用 beam search 找更可能的输出。
论文中先把 AED 的逐 token 预测概率写成下面这个形式,其中 y<s
\(
P(y_s \mid y_{<s}, x)=\mathrm{Trfm}(y_{<s},x)
\)
对应的最大似然训练目标,也就是负对数似然损失为:
\(
L_{\mathrm{nll}}(\theta)=-\frac{1}{S}\sum_{s=1}^{S}\log P(y_s\mid y_{<s},x)
\)
Conformer 块由两个 FFN、一个多头自注意力模块和一个卷积模块组成。两个 FFN 采用半步残差风格,注意力负责长程依赖,卷积负责局部模式。本文的 MoE 改造发生在第二个 FFN:作者把它替换成一个稀疏门控的专家集合,也就是 MoE-Conformer block。
论文把一个 MoE-Conformer block 的计算写成四步。最后一步中,第二个 FFN 被替换成 MoE 版本:
\(
\begin{aligned}
z_t^{(1)} &= z_t + \frac{1}{2}\mathrm{FFN}(z_t),\\
z_t^{(2)} &= z_t^{(1)} + \mathrm{MHSA}(z_t^{(1)}),\\
z_t^{(3)} &= z_t^{(2)} + \mathrm{Conv}(z_t^{(2)}),\\
\hat{z}_t &= \mathrm{LayerNorm}\left(z_t^{(3)}+\frac{1}{2}\mathrm{FFN}^{(\mathrm{MoE})}(z_t^{(3)})\right).
\end{aligned}
\)
方法:共享稀疏门控专家
Conformer 参数共享
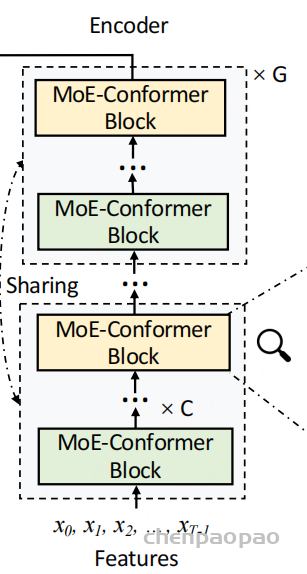
作者把连续的 C 个 Conformer 块看作一组,再堆叠 G 组。不同组中相同位置的块共享参数,相当于一组块被递归调用 G 次。这样做的好处很直接:如果想要 12 次变换,不一定真的保存 12 套编码器参数,可以用更少的块反复计算。
但是共享不是白来的。共享块在浅层和深层面对的表示分布不一样,如果完全用同一套参数、同一套路由、同一套归一化统计,模型会很难同时适配不同深度的表示。因此后面两个设计,也就是独立路由器和独立归一化,就变得很关键。
MoE 动态路由
MoE 模块由 E 个并行 FFN 专家和一个 router 组成。对每个时间步的表示,router 输出各专家的概率,论文采用 top-1 选择,只激活得分最高的专家。也就是说,虽然模型里存着多个专家参数,但每次计算只走其中一个 FFN。
top-1 MoE 的路由过程如下。router 先产生各 expert 的 gate 分数,再选择最大分数对应的 expert:
\(
\begin{aligned}
g &= [g_0,\cdots,g_{E-1}]=\mathrm{softmax}(\mathrm{router}(z_t^{(3)})),\\
i^* &= \arg\max_{0\le i\le E-1} g_i,\\
\mathrm{FFN}^{(\mathrm{MoE})}(z_t^{(3)}) &= g_{i^*}\mathrm{FFN}_{i^*}(z_t^{(3)}).
\end{aligned}
\)
这个设计把“容量”和“计算”部分解耦:总参数更多,潜在表达空间更大;但激活参数不增加太多,推理计算仍接近普通 FFN。为了避免所有样本都挤向同一个专家,作者加入 load balancing loss,同时在训练时给 router 加高斯噪声,让专家选择更分散。
负载均衡损失用于鼓励 expert 被更均匀地使用:
\(
L_{\mathrm{balance}}=E\sum_{i=0}^{E-1}f_i\bar{g}_i
\)
独立路由器与归一化
论文没有把所有 MoE router 都一起共享,而是让每个 MoE 模块拥有自己的 router。直觉上,同一个共享块在第 1 次、第 6 次、第 12 次递归调用时,输入表示已经处在不同层级;如果路由路径完全一致,就会限制专家选择的灵活性。
归一化层也类似。LayerNorm、BatchNorm 的统计和缩放偏移参数对表示分布很敏感。作者让归一化模块保持独立,使不同层级的表示能够维持各自合适的统计状态。论文还把归一化中的 scale 和 offset 看作一种轻量 adapter,用很少参数增强共享块的适配能力。
隐藏层知识蒸馏
共享模型再聪明,毕竟参数少。作者用全参数 Conformer 编码器作为 teacher,让共享模型的编码器输出尽量接近 teacher 的隐藏表示。这里不是只蒸馏最终预测分布,而是直接约束隐藏 embedding 的 L2 距离。这样做的目的,是让小模型学习 full model 的中间表征轨迹。
hidden embedding 蒸馏损失直接约束 student encoder 输出 h_t 与 teacher encoder 输出 h_t' 的距离:
\(
L_{\mathrm{kd}}=\frac{1}{T}\sum_{t=0}^{T-1}\lVert h_t-h_t’\rVert_2
\)
训练目标
最终损失由三部分组成:主任务的负对数似然、MoE 的负载均衡损失、隐藏层知识蒸馏损失。负载均衡项负责让专家不塌缩,蒸馏项负责让共享模型贴近全参数 teacher。论文还在实验中加入 CTC loss 来辅助对齐。
\(
L=L_{\mathrm{nll}}+\frac{\alpha}{C}\sum L_{\mathrm{balance}}+\beta L_{\mathrm{kd}}
\)
这里 C 是 MoE module 的数量,α 和 β 分别控制负载均衡损失与蒸馏损失的权重。
与已有工作的关系
MoE 常被用来扩大模型容量,尤其是在 NLP 大模型里,通过条件计算扩展到很大的参数规模。但这篇论文不是追求超大规模,而是把 MoE 当作参数高效工具:共享专家、重复使用专家,让少量模块发挥更大作用。
跨层权重共享也不是新想法,ALBERT、Universal Transformer 以及若干 ASR 工作都用过类似机制。本文的不同点在于,它没有只做朴素共享,而是在共享结构里加入稀疏专家,同时让 router 和 normalization 独立,从而减少共享带来的容量和分布适配问题。
实验:
实验设置
实验使用 AISHELL-1 普通话语音识别数据集:约 150 小时训练语音、18 小时开发集、10 小时测试集。输入特征为 80 维 FBANK,窗口 25ms、步长 10ms,并使用全局 CMVN、速度扰动、SpecAugmentation 和 time stretch 等增强手段。词表包含 4235 个中文字符以及起止符号。
模型前端是两层 CNN subsampling,把帧率降到 25Hz。编码器维度为 256,MHSA 使用 4 个头,卷积核大小 15,FFN 中间维度 1024。MoE-Conformer 的第二个 FFN 使用 4 个专家,解码器是 4 层 Transformer。训练 80 个 epoch,使用 PyTorch 和 FastMoE 实现。
结果与分析
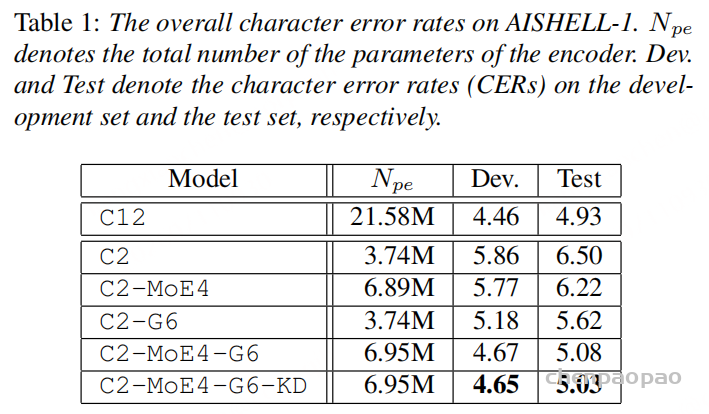
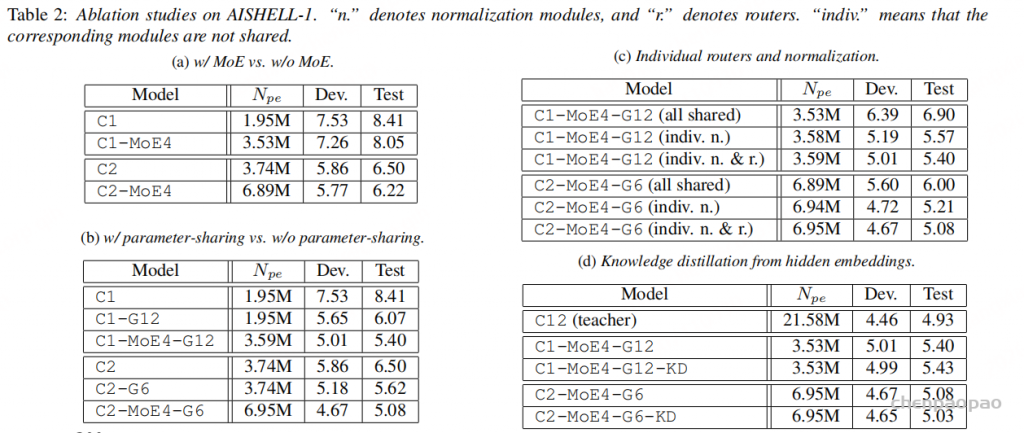
主表里,全参数 C12 编码器参数量为 21.58M,测试集 CER 为 4.93。最终的 C2-MoE4-G6-KD 只有 6.95M 编码器参数,测试集 CER 为 5.03。换句话说,它用大约三分之一的编码器参数,做到了非常接近 full-parameter 模型的结果。
消融实验显示,单独减少块数会明显损伤效果,例如 C2 的测试 CER 为 6.50;加入 MoE 后,C2-MoE4 降到 6.22,说明专家机制确实补了一部分容量。再加入跨层共享递归计算后,C2-G6 为 5.62,而 C2-MoE4-G6 达到 5.08,说明“共享 + MoE”的组合比任一单独机制更有价值。
独立路由器和归一化的作用也很明显。C2-MoE4-G6 如果全部共享,测试 CER 为 6.00;只让归一化独立,降到 5.21;归一化和 router 都独立后,进一步到 5.08。这说明共享模型最怕的不是参数少本身,而是不同深度表示被迫使用完全相同的适配路径。
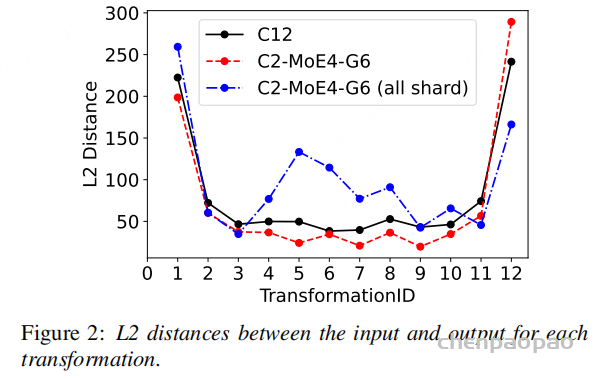
知识蒸馏带来的提升相对温和,但在 C2-MoE4-G6 上仍把测试 CER 从 5.08 推到 5.03。作者还通过输入输出 L2 距离观察模型内部变化:带独立 router 和 normalization 的共享模型更接近全参数 C12 的变化曲线,而全共享模型曲线更不稳定。
结论与未来方向
这篇论文的价值在于,它给出了一个较完整的参数高效 Conformer 方案:用跨层共享压缩参数,用稀疏 MoE 恢复容量,用独立路由器和归一化适配不同深度表示,再用隐藏层蒸馏补齐小模型表现。最终模型在 AISHELL-1 上以约三分之一编码器参数接近全参数模型。
它也留下了自然的后续问题:方法是否能在更大规模、多语种或更复杂的 ASR 数据集上保持优势?能否迁移到 RNN-T、CTC 或其他端到端 ASR 架构?从工程角度看,这类方案的吸引力很强,因为它不是单纯追求小模型,而是在“参数、计算、表达容量”之间做更细的拆分。
这篇论文 MoE Adapter for Large Audio Language Models: Sparsity, Disentanglement, and Gradient-Conflict-Free 的问题意识很明确:大语言模型要理解真实世界,不能只看文本,音频是很重要的输入模态。但音频并不是一种均匀信号。语音、音乐、环境声承载的信息结构不同,如果用一个 dense adapter 把所有音频都压进同一个文本 embedding 空间,很容易出现参数更新方向互相冲突。
摘要:用专家分工处理异质音频
论文提出 MoE-Adapter,用稀疏 Mixture-of-Experts 替代传统的 dense audio adapter。它不是让所有音频 token 都通过同一套 FFN,而是用动态门控把 token 路由到若干专门专家,同时保留一定共享能力来捕捉全局上下文。这样,语音、音乐、环境声等不同属性可以在不同专家子空间中被建模,从而减轻梯度冲突。
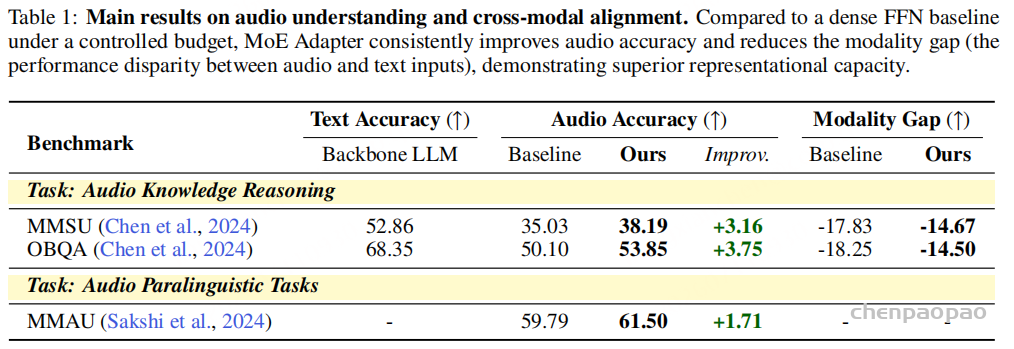
实验基于 Qwen3-1.7B 骨干,音频前端使用 Whisper-VQ tokenizer 和 Whisper Encoder。作者在相同参数预算下比较 dense adapter 和 MoE-Adapter:两者总参数约 94.4M,但 MoE 因稀疏激活,推理时只激活约 70.8M 参数。结果显示,MoE-Adapter 在 MMSU、OBQA、MMAU 等音频理解和推理任务上均优于 dense baseline,并减少音频输入与文本输入之间的 modality gap。
引言:音频不是一种单一分布
大语言模型在文本推理上已经非常强,但只处理文本会限制它们感知现实世界的能力。音频包含人类说话、环境声音、音乐和情绪韵律等信息,是多模态智能绕不开的一环。当前许多大音频语言模型的主流做法,是加一个 adapter,把声学特征投影到 LLM 的文本语义空间里。
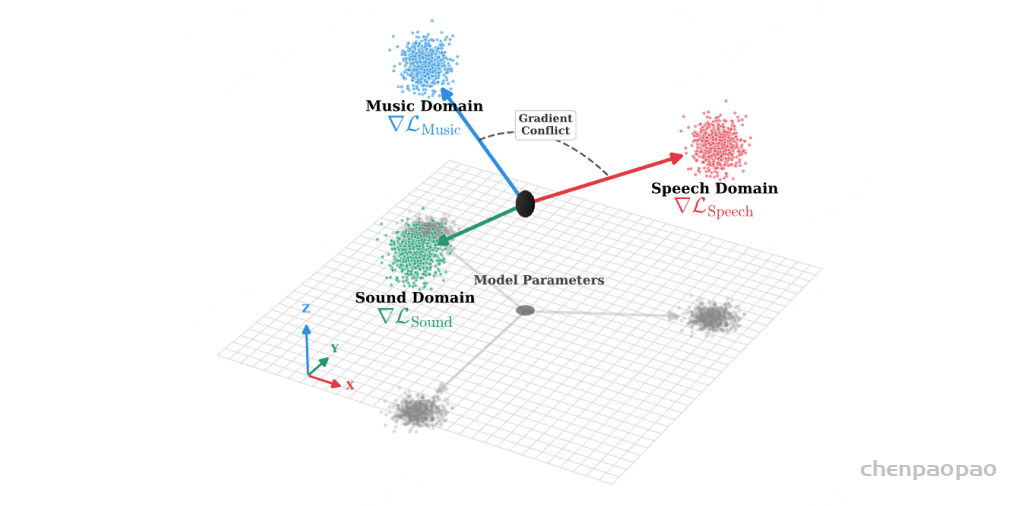
问题在于,很多 adapter 是 dense、参数共享的:所有音频都经过同一套投影层。这隐含一个假设,即不同音频类型可以被同一种映射均匀处理。作者认为这个假设过强。语音主要承载语义和语言结构,音乐更关注节奏、旋律和情感,环境声又有自己的声学模式。它们在表示空间中可能位于不同流形。
如果一个 dense adapter 同时学习这些相互差异很大的目标,不同数据类型的梯度可能朝相反方向更新同一组参数。这就是论文强调的 gradient conflict。MoE-Adapter 的贡献,就是用动态专家路由把这些冲突拆开:相似属性共享专家,冲突属性进入不同专家。
相关工作
大音频语言模型
早期音频问答或语音交互系统常采用级联管线:先 ASR 转文字,再交给 LLM。这样的系统容易受到识别错误传播影响,也会丢失语调、情绪、音乐和环境声等非文字信息。后来的端到端 LALM 通过可学习 adapter,把声学特征映射到文本空间,让 LLM 直接条件化在音频表示上。
现有 adapter 大致分为 Q-Former 类和 linear projector / MLP projector 类。后者结构简单、效率高,因此被许多最新模型采用。但这种全局共享投影层难以面对音频内部的分布差异。本文正是针对这个瓶颈,把稀疏 MoE 引入 audio-text alignment 阶段。
MoE 架构
MoE 的基本思想是让不同专家处理不同样本或不同 token,通过稀疏门控实现条件计算。它已经在语言模型、多模态模型、视觉语言模型等方向证明了对异质数据和任务冲突的缓解能力。音频领域也开始出现 MoE 相关工作,例如生成、医疗音频特征选择等。
不过,在通用 audio-text alignment 这个环节,主流 LALM 仍大量依赖静态、共享参数 adapter。本文的 MoE-Adapter 不只是借用 MoE 扩容量,而是把 MoE 作为一种“解耦工具”,专门处理音频属性之间的冲突。
方法
整体框架
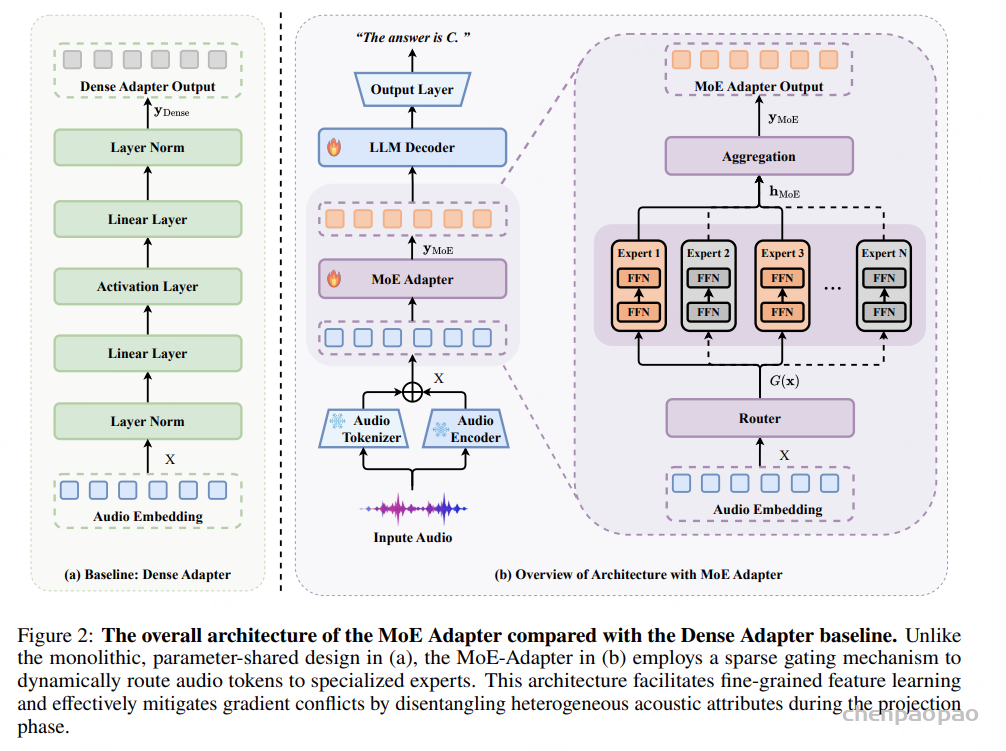
模型采用类似 Kimi-Audio 的 dual-stream 音频前端:一条路径用冻结 tokenizer 提取离散语义 token,另一条路径用 speech encoder 提取连续声学特征。两类表示经过投影和融合后,进入 adapter。
传统方案会用 dense adapter 把融合音频特征映射到 LLM embedding 空间。本文则用 MoE-Adapter 完成这一步。最终,adapted audio embeddings 与文本 token embeddings 拼接,作为 LLM 的输入,并用标准自回归 next-token prediction 训练。
稀疏 MoE Adapter
Dense adapter 可以看作一个单体 FFN:所有音频 token 都通过同一组权重。作者指出,这种设计强制同一组参数同时容纳异质音频,会形成不必要的优化干扰。
论文先把 dense adapter 写成单体 FFN 投影。给定音频 token x,输出 embedding 为:
\(
y=\mathcal{N}\left(W_{d2}\cdot\sigma\left(W_{d1}\cdot\mathcal{N}(x)\right)\right)
\)
MoE-Adapter 把单体 FFN 替换成专家集合。每个专家都是轻量 FFN,router 根据输入 token 计算各专家得分,并通过 Top-k 选择保留若干活跃专家。被选中的专家输出按门控权重聚合,形成中间表示。随后再经过输出投影和 LayerNorm,对齐到 LLM embedding 维度,用来替换输入序列中的音频占位 token。
每个 expert 本身也是一个轻量 FFN:
\(
E_i(x)=W_{e2}^{(i)}\cdot\phi\left(W_{e1}^{(i)}\cdot\mathcal{N}(x)\right)
\)
router 根据 logits s=xW_g 做 Top-k 稀疏选择,再 softmax 得到门控概率:
\(
G(x)=\mathrm{softmax}\left(T_k(s)\right),\quad s=xW_g
\)
被选中的 expert 输出按 gate 权重聚合,并经过最终投影对齐到 LLM embedding 空间:
\(
h_{\mathrm{MoE}}=\sum_{i\in I}G(x)_i\cdot E_i(x)
\)
\(
y_{\mathrm{MoE}}=\mathcal{N}\left(W_P\cdot h_{\mathrm{MoE}}\right)
\)
这套机制有两个效果:一是稀疏激活降低推理成本,二是专家分工让不同音频属性进入不同子空间。对于语音、音乐、环境声这种天然异质输入,第二点尤其重要。
训练目标
训练目标由 next-token prediction loss 和 auxiliary load-balancing loss 组成。前者让模型基于音频上下文预测后续文本 token,是主任务;后者用于避免 expert collapse,即所有 token 都涌向少数专家。
总训练目标为 next-token prediction 与负载均衡项的加权和:
\(
L=L_{\mathrm{NTP}}+\lambda L_{\mathrm{aux}}
\)
其中主任务 NTP loss 写成:
\(
L_{\mathrm{NTP}}=-\sum_{t=1}^{T}\log P(y_t\mid y_{<t},X;\theta)
\)
负载均衡损失会同时考虑专家的重要性和实际负载,让不同专家都被充分训练。这里有一个微妙的取舍:过强的均衡可能压制某些自然形成的专家偏好,但完全不均衡又会损害高层语义推理的泛化。论文后面的消融和分析专门讨论了这个矛盾。
论文将 expert importance 与 expert load 分别定义为:
\(
\bar{P}_e=\frac{1}{B}\sum_{b=1}^{B}p_{b,e}
\)
\(
\bar{f}_e=\frac{1}{B}\sum_{b=1}^{B}r_{b,e}
\)
最终 auxiliary loss 为:
\(
L_{\mathrm{aux}}=|\mathcal{E}_R|\sum_{e\in\mathcal{E}_R}\bar{P}_e\cdot\bar{f}_e
\)
实验
实验设置
LLM 骨干是 Qwen3-1.7B,音频前端使用 Whisper-VQ tokenizer 和 Whisper Encoder。训练语料规模为 40B token,优化器为 AdamW,学习率调度采用 Warmup-Stable-Decay。为了公平比较,dense adapter 与 MoE-Adapter 的总参数预算都限制在约 94.4M。
评测覆盖几类能力。MMAU 用于音频感知和副语言理解,覆盖 speech、sound、music 等场景;VoiceBench 中的 MMSU 和 OpenBookQA 子集用于世界知识和语义推理,它们是从文本推理基准改造来的音频版本。所有评测采用 greedy decoding,避免采样随机性干扰比较。
主结果
在知识推理任务上,MoE-Adapter 明显超过 dense baseline。MMSU 的 audio accuracy 从 35.03 提升到 38.19,OBQA 从 50.10 提升到 53.85。对比文本输入准确率,音频输入仍存在明显 gap,但 MoE 把这个差距分别缩小了约 3.16 和 3.75 个点。
在 MMAU 这类副语言和音频感知任务上,MoE-Adapter 也从 59.79 提升到 61.50。这个提升说明专家路由不仅对知识推理有用,也能帮助模型捕捉更复杂的声学线索。论文强调,MoE 的收益不是单纯参数变多,而是在相近总参数预算下更合理地分配表示能力。
消融实验
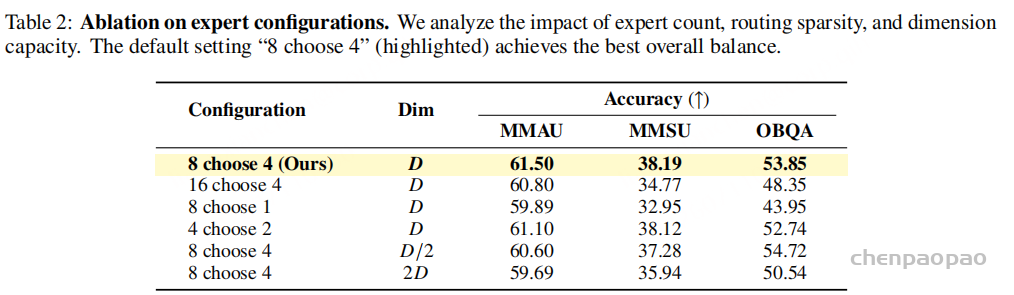
专家配置方面,默认的 “8 choose 4” 表现最均衡:MMAU 61.50、MMSU 38.19、OBQA 53.85。把专家数扩大到 “16 choose 4” 反而变差,说明专家总数不是越多越好。把路由变得过稀疏,例如 “8 choose 1”,也会显著伤害音频推理。论文的结论是,专家数量、激活数量和专家容量之间需要平衡,而不是盲目扩某一个维度。
负载均衡损失的消融更有意思。去掉 EBL 后,MMAU 从 61.50 升到 63.01,但 MMSU 和 OBQA 分别下降到 37.37 和 52.31。作者解释说,MMAU 很异质且含有大量低层声学感知样本,不加均衡时 router 会集中使用少数“强专家”,反而有利于这类感知任务;但这会减少专家多样性,损害需要世界知识和语义推理的任务
专家分工与优化动态分析
专家均衡如何影响路由
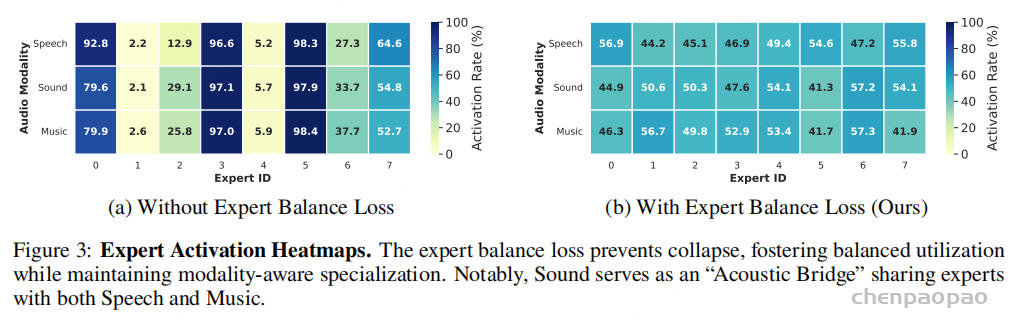
作者在 MMAU 上分析 speech、sound、music 三类样本的专家激活热力图。结果显示,模型确实学出了模态相关的专家分工:有些专家主要服务单一类别,有些专家在 sound 与 speech 或 sound 与 music 之间共享。值得注意的是,几乎没有专家同时专门服务 speech 和 music。
这个现象符合直觉:环境 sound 和 speech/music 都可能共享一些低层声学特征,因此可以作为“桥”;但 speech 和 music 在时间结构、语义组织上差异更大,不适合强行塞进同一个专家。EBL 并不会消灭这种分工,而是防止少数专家过度支配,保留一定均衡。
梯度冲突与缓解机制
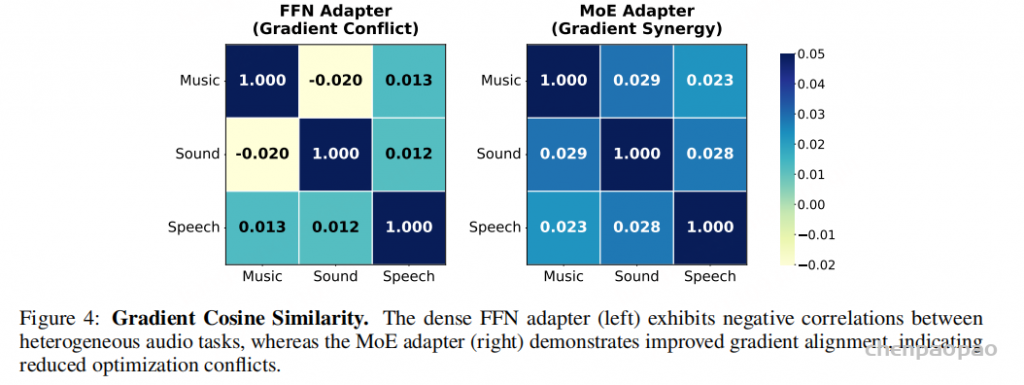
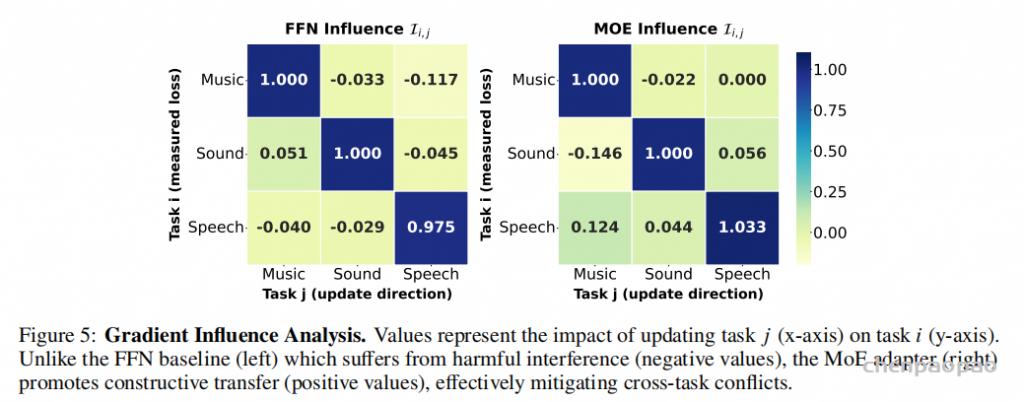
论文用两个指标分析优化过程。第一个是不同音频类别梯度之间的 cosine similarity。dense adapter 中,不同类别的梯度经常出现负相似度,意味着一个类别的更新方向可能伤害另一个类别。MoE-Adapter 则把这些相似度推向更正的方向,说明专家路由减少了破坏性干扰。
第二个是 gradient influence score,用来衡量基于某一任务梯度做更新后,对另一个任务损失是帮助还是伤害。dense adapter 中,speech 的更新会明显伤害 music 和 sound;MoE-Adapter 中,影响分数更多为正,说明它不是简单隔离任务,还能通过共享专家保留有益迁移。例如 speech 对 sound 的更新可以产生正向帮助,而 music 的冲突被更好地隔开。
结论
这篇论文把 MoE-Adapter 定位为解决 LALM 音频异质性的结构工具。相比 dense adapter,它用动态专家分工缓解语音、音乐、环境声之间的梯度冲突,在相近参数预算下提升音频知识推理、副语言理解和跨模态对齐表现。更重要的是,论文不仅给出指标提升,也通过路由热力图、梯度相似度和影响分数解释了为什么 MoE 有效。
局限性
作者也明确指出了几个限制。第一,实验目前只在 Qwen3-1.7B 骨干上验证,方法是否适用于其他 LLM 家族或更大规模模型,例如 70B,还需要实验。第二,论文没有系统研究稀疏路由随训练数据规模增长的 scaling law。第三,当前任务集中在音频理解与推理,没有扩展到生成式音频任务。
附录:超参数和工程含义
附录强调,dense baseline 与 MoE-Adapter 在总参数预算上被严格对齐,约为 94.4M。MoE-Adapter 的活跃参数约为 70.8M,大约是 dense baseline 的 75%。共同音频前端包含 speech encoder、audio hidden projection 和 feature fusion;MoE 端则包含专家集合、gate network 和 aggregation block。
从工程角度看,这个设置很关键。它把论文的结论从“MoE 参数更多所以更强”拉回到“在可比预算下,稀疏专家分工更适合异质音频”。如果未来大音频语言模型要同时处理语音问答、环境声推理、音乐理解和情绪韵律,adapter 层可能不该再是一个单体投影器,而应该具备更细粒度的路由和分工能力。