
论文地址: https://arxiv.org/abs/1609.05158
代码:https://github.com/leftthomas/ESPCN
Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
ESPCN 是在2016年在CVPR上发表的一片论文,中提出的一种实时的基于卷积神经网络的图像超分辨率方法。
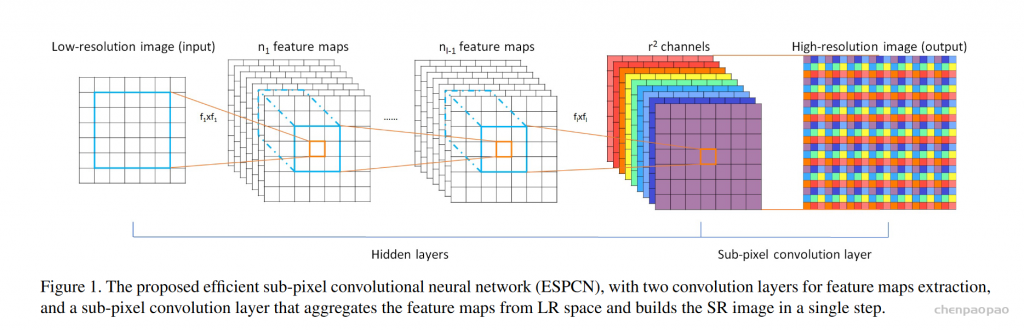
这篇论文主要就是提出了一种新的亚像素卷积层(sub-pixel convolutional layer),以往的方法,为了生成高分辨率的输出,一般是先对输入进行上采样扩大图像分辨率,得到与高分辨率图像同样的大小,再作为网络输入,意味着卷积操作在较高的分辨率上进行,相比于在低分辨率的图像上计算卷积,会降低效率。 ESPCN(Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network,CVPR 2016)提出一种在低分辨率图像上直接计算卷积得到高分辨率图像的高效率方法。
如果想最后的分辨率从 n 到 rn,ESPCN会生成r*r个通道,再进行sub-pixel convolutional,生成高分辨率的图片。假设是9通道 混合,这里的通道混合是将每个通道对应位置的元素重新排列成3*3的图像。这个变换虽然被称作sub-pixel convolution, 但实际上并没有卷积操作。
通过使用sub-pixel convolution, 图像从低分辨率到高分辨率放大的过程,插值函数被隐含地包含在前面的卷积层中,可以自动学习到。只在最后一层对图像大小做变换,前面的卷积运算由于在低分辨率图像上进行,因此效率会较高。
ESPCN激活函数采用tanh替代了ReLU。损失函数为均方误差。

pytorch中已经集成了 sub-pixel convolution :
nn.PixelShuffle(upscale_factor)
以四维输入(N,C,H,W)为例,Pixelshuffle会将为(∗,r 2 C r^2Cr2C,H,W)的Tensor给reshape成(∗,C,rH,rW)的Tensor
Upsample:
对给定多通道的1维(temporal)、2维(spatial)、3维(volumetric)数据进行上采样。
对volumetric输入(3维——点云数据),输入数据Tensor格式为5维:minibatch x channels x depth x height x width
对spatial输入(2维——jpg、png等数据),输入数据Tensor格式为4维:minibatch x channels x height x width
对temporal输入(1维——向量数据),输入数据Tensor格式为3维:minibatch x channels x width
此算法支持最近邻,线性插值,双线性插值,三次线性插值对3维、4维、5维的输入Tensor分别进行上采样(Upsample)。