
github: https://github.com/leftthomas/ESPCN
2016年的文章。在此之前使用CNN进行SR的方法都是将LR图像先用一个single filter(通常是bicubic)upscale至HR的尺寸,再进行reconstruction的。所有SR的操作都再HR空间进行。 而本文提出在LR空间进行特征提取。并引入sub-pixel convolution layer用于学习一组upscaling filter,用这些针对特征图训练得到的更复杂的filter代替手工bicubic filter。可以降低计算成本,实现实时SR。直接将LR图像输入一个l层的CNN中,之后通过一层sub-pixel卷积层upscaleLR特征图生成对应的HR图像。

这篇论文提出了一种亚像素卷积的方法来对图像进行超分辨率重建,速度特别快。虽然论文里面称提出的方法为亚像素卷积(sub-pixel convolution),但是实际上并不涉及到卷积运算,是一种高效、快速、无参的像素重排列的上采样方式。由于很快,直接用在视频超分中也可以做到实时。其在Tensorflow中的实现称为depthtospace ,在Pytorch中的实现为PixelShuffle。
这种上采样的方式很多时候都成为了上采样的首选,经常用在图像重建领域,如后续有在降噪领域中的FFDNet。
论文的主要创新点为:
1. 只在模型末端进行上采样,可以使得在低分辨率空间保留更多的纹理区域,在视频超分中也可以做到实时。
2.模块末端直接使用亚像素卷积的方式来进行上采样,相比于显示的将LR插值到HR,这种上采样方式可以学习到更好、更为复杂的方式,可以获得更好的重建效果。
可以看到,相比于其他的一些超分算法,这里实际上只改动了最后的上采样方式。在模型倒数第二层学习对应的通道数( r2c )的卷积,其中c为最终的通道数,如输出是RGB图,则c为3,如输出是灰度图或者Y通道的图,则c为1;r为需要进行的上采样倍数,为正整数倍,不同的上采样倍数只需要调整这一层卷积的通道数即可。
由于带计算的操作都是在低分辨率空间中进行的,所以速度相对会快很多。
这里给出的示例为r=3,c=1,即单通道图的3倍上采样图。结合超像素的思想来看,以第一张特征图进行的3×3宫格的像素重排列,行优先地按顺序将不同深度的特征依次重排列到宫格上。
这里给出的示例图是简单场景,像素重排列的方式为:

从公式可以看出,对于多通道的图,以通道数作为一个整体,即将特征图通道数中连续的c个通道作为一个整体,再然后进行像素重排列,得到多通道的上采样图。
论文的核心创新点就在于这里的像素重排列的方式。
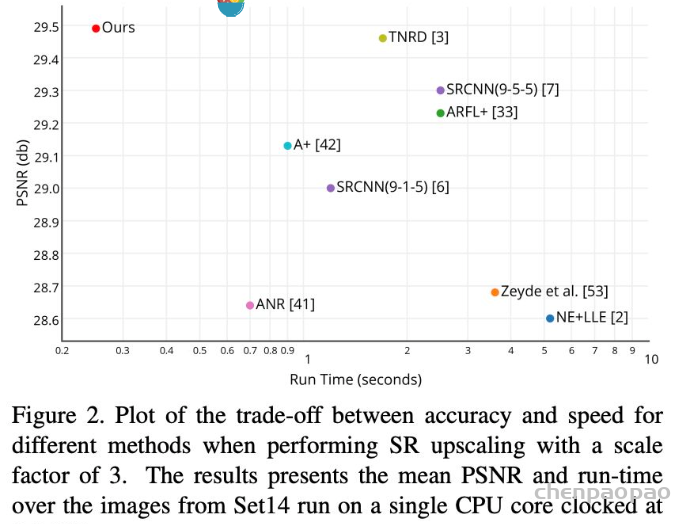
整体的效果上来说,也是非常的惊人。从模型的角度上而言,其主干模型可以采样其他SOTA的主干结构。由于上采样的差异,可以学习到更好、更复杂的上采样方式,所以最终的重建效果是要稍好于SOTA的模型的。并且由于上采样特别高效,速度非常的快。从PSNR的角度来看,ESPCN比TNRD(TNRD发表于TPAMI2015,是DnCNN的前身)稍好,但是速度却相差一个数量级左右。

结论
这篇论文提出了一种亚像素卷积层,在低分辨率空间中可以学习到更好、更复杂的上采样方式,对于不同的重建倍数,只需要对应地更改低分辨率空间中的卷积通道数,非常灵活。其最终的重建PSNR效果也是SOTA,速度上具有很巨大的优势,视频超分也能做到实时。这种上采样方式也广泛地应用于其他的重建领域中。