

Dosovitskiy et al. An image is worth 16×16 words: transformers for image recognition at scale. In ICLR, 2021
step1 :分割图片

step2 向量化:从九个快变成九个向量
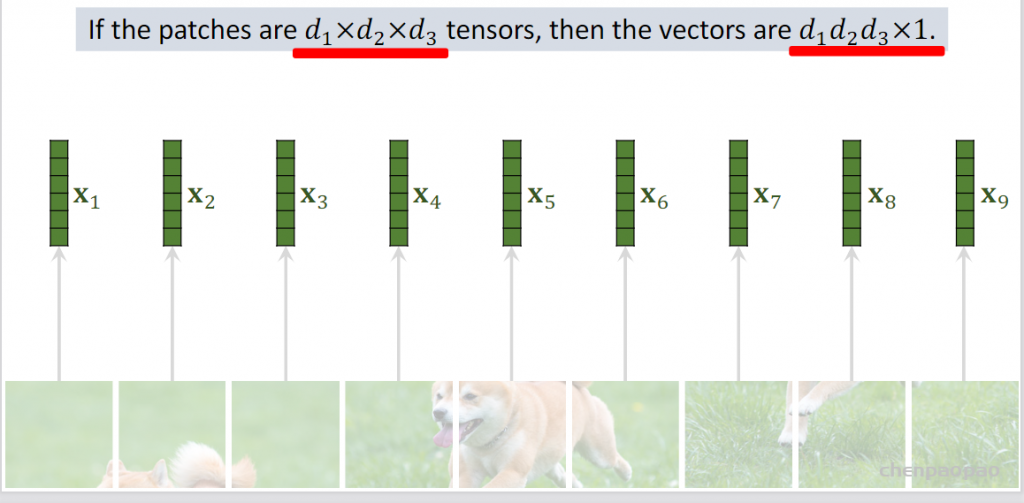
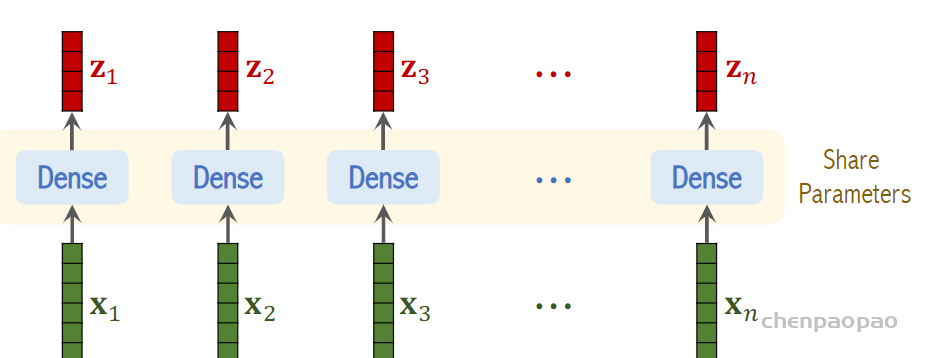
step3:向量线性变换:(linear embedding线性嵌入层)
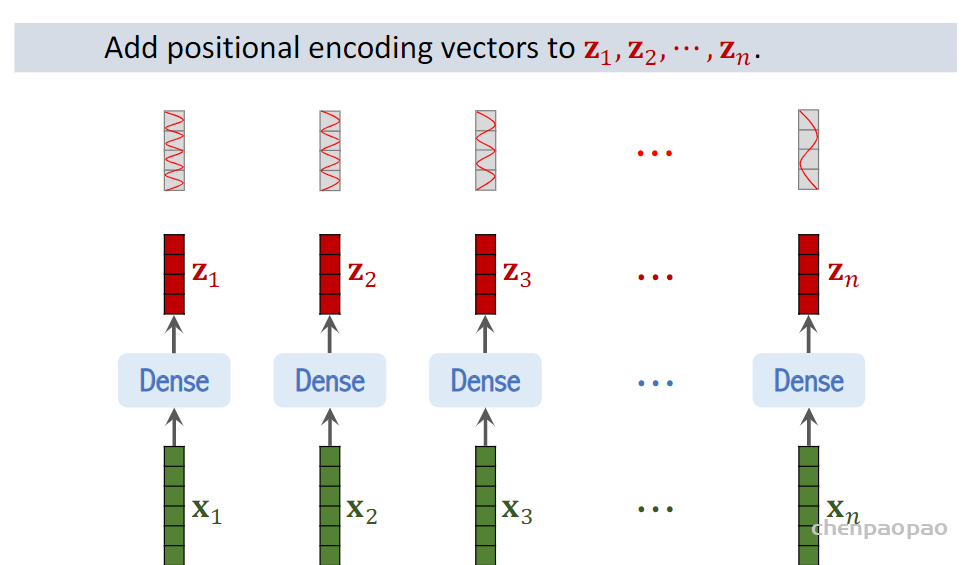
step4:将位置编码添加到z上:
step4:添加一个cls向量:
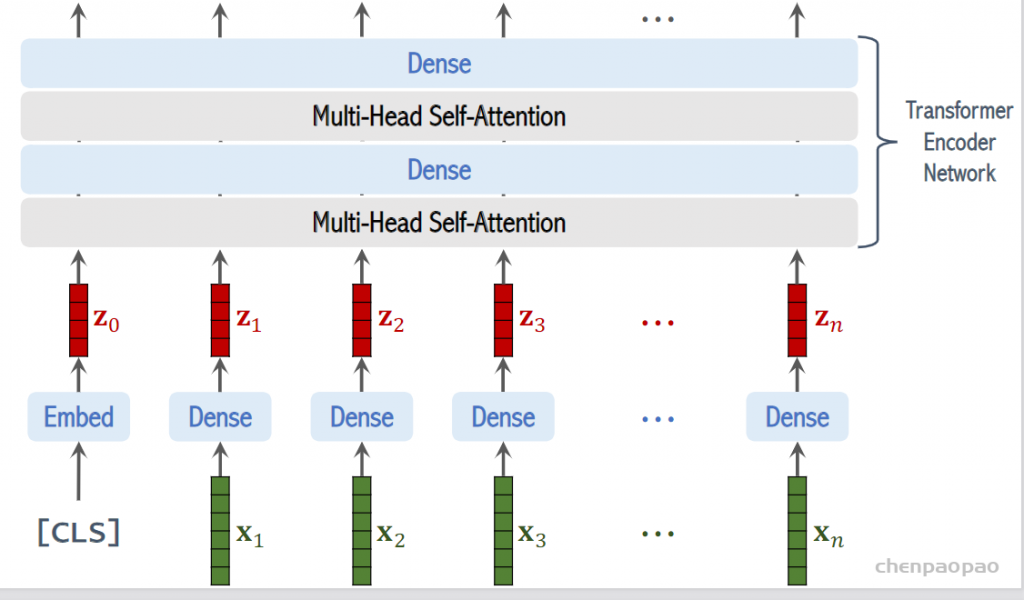
step5:只利用cls的输出

按照上面的流程图,一个ViT block可以分为以下几个步骤
(1) patch embedding:例如输入图片大小为224×224,将图片分为固定大小的patch,patch大小为16×16,则每张图像会生成224×224/16×16=196个patch,即输入序列长度为196,每个patch维度16x16x3=768,线性投射层的维度为768xN (N=768),因此输入通过线性投射层之后的维度依然为196×768,即一共有196个token,每个token的维度是768。这里还需要加上一个特殊字符cls,因此最终的维度是197×768。到目前为止,已经通过patch embedding将一个视觉问题转化为了一个seq2seq问题
(2) positional encoding(standard learnable 1D position embeddings):ViT同样需要加入位置编码,位置编码可以理解为一张表,表一共有N行,N的大小和输入序列长度相同,每一行代表一个向量,向量的维度和输入序列embedding的维度相同(768)。注意位置编码的操作是sum,而不是concat。加入位置编码信息之后,维度依然是197×768
(3) LN/multi-head attention/LN:LN输出维度依然是197×768。多头自注意力时,先将输入映射到q,k,v,如果只有一个头,qkv的维度都是197×768,如果有12个头(768/12=64),则qkv的维度是197×64,一共有12组qkv,最后再将12组qkv的输出拼接起来,输出维度是197×768,然后在过一层LN,维度依然是197×768
(4) MLP:将维度放大再缩小回去,197×768放大为197×3072,再缩小变为197×768
一个block之后维度依然和输入相同,都是197×768,因此可以堆叠多个block。最后会将特殊字符cls对应的输出 zL0 作为encoder的最终输出 ,代表最终的image presentation(另一种做法是不加cls字符,对所有的tokens的输出做一个平均),如下图公式(4),后面接一个MLP进行图片分类
vit需要预训练+微调

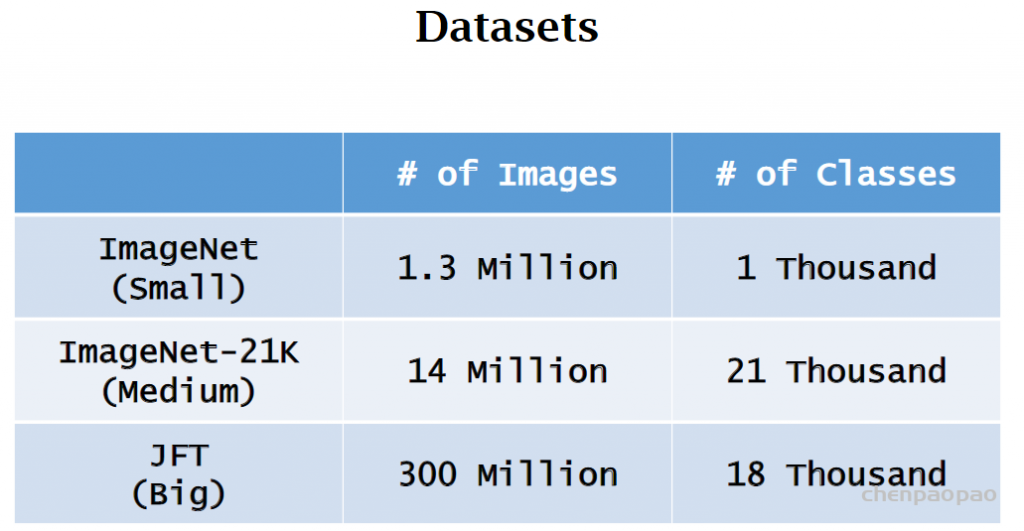
• Pretrain the model on Dataset A, fine-tune the model on Dataset B,
and evaluate the model on Dataset B.
• Pretrained on ImageNet (small), ViT is slightly worse than ResNet.
• Pretrained on ImageNet-21K (medium), ViT is comparable to ResNet.
• Pretrained on JFT (large), ViT is slightly better than ResNet.
效果:
