
ISCAS 2022的一篇文章,作为首个Swin Transformer在图像去噪领域的应用,效果来说感觉还有很大提高空间。但不的不说,自从Swin Transformer(2021)提出后,在整个cv领域独领风骚。作为一个通用的架构,可以将其应用在各个cv领域,从paperwithcode里就可以见其影响力:(截止到22.8.28)
1、目标检测:
2、图像超分辨率

3、实例分割:
4、3D医学图像分割:

今天,就来看看Swin Transformer 对于图像去噪任务的处理效果:
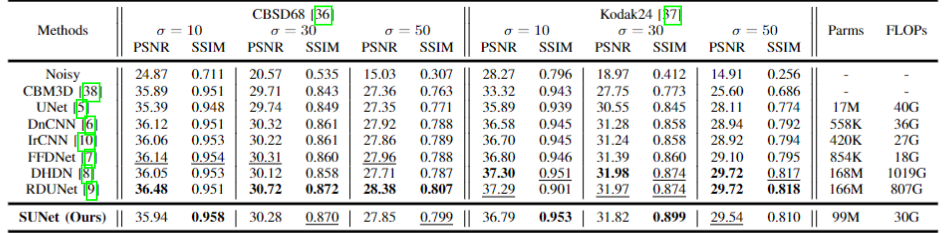

个人觉得 Swin Transformer 对于去噪来说还有很大的扩展空间,这篇论文的模型效果不是很好,可以值得去尝试尝试,看看有没有更好的方法提高模型效果。
论文的主要贡献:
1、结合Unet网络+ Swin Transformer
2、提出了一个双上采样模块 dual up-sample block
3、首个将Swin +unet用于图像去噪领域
4、在 两个通用数据集中测试的结果还不错
网络结构:

网络分为三个部分:1)Shallow feature extraction; 2) UNet feature extraction; and
3) Reconstruction module
1、Shallow feature extraction
使用3*3卷积,提取特征,输出通道96
2、 UNet feature extraction
带有 Swin Transformer Block 的UNET体系结构,其中包含8个 Swin Transformer 层,以取代卷积。
Swin Transformer Block(STB)和Swin Transformer层(STL):
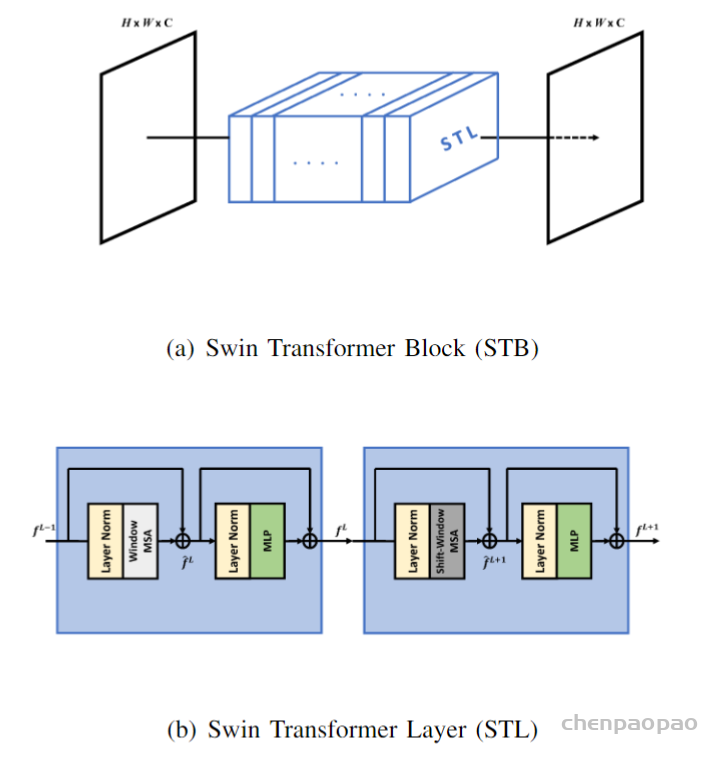
这块建议去看 Swin Transformer 论文,讲的比较清楚。注意此时的输入输出大小完全一致,因此需要下采样。
下采样: Patch merging
Patch merging:通过查看Patch merging的源码,可以看到,其实就是一个下采样的过程,它可以看成一种加权池化的过程。实现维度下采样、特征加倍的效果。
class PatchMerging(nn.Module):
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x上采样:Dual up-sample
作者提出了 上采样,
该模块包括两种现有的上样本方法(即双线性和PixelShuffle),以防止棋盘伪影(Deconvolution and Checkerboard Artifacts中提出的)https://distill.pub/2016/deconv-checkerboard/ 产生原因:主要是出现在反卷积中。

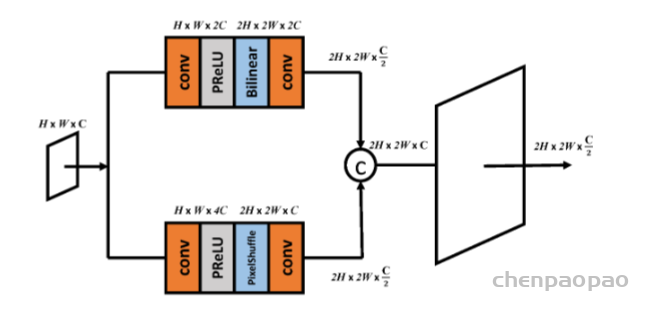
通过两种上采样后,cat维度拼接后,通过一个卷积层将维度减半C/2
实验:
如上图所示。