
github: https://github.com/MIC-DKFZ/nnUNet
论文地址: https://arxiv.org/abs/1809.10486

相较于常规的自然图像,以UNet为代表的编解码网络在医学图像分割中应用更为广泛。常见的各类医学成像方式,包括计算机断层扫描(Computed Tomography, CT)、核磁共振成像(Magnetic Resonance Imaging, MRI)、超声成像(Ultrasound Imaging)、X光成像(X-ray Imaging)和光学相干断层扫描(Optical Coherence Tomography, OCT)等。对于临床而言,影像学的检查是一项非常重要的诊断方式。在各类模态的影像检查中,精准地对各种器官和病灶进行分割是影像分析的关键步骤,目前深度学习图像分割在各类影像检测和分割中大放异彩。比如基于胸部CT的肺结节检测、基于颅内MR影像的脑胶质瘤分割、基于心脏CT的左心室分割、基于甲状腺超声的结节检测和基于X光的胸片肺部器官分割等。
虽然基于UNet的系列编解码分割网络在各类医学图像分割上取得了长足的进展,并且部分基于相关模型的应用设计已经广泛用于临床分析中。但医学影像本身的复杂性和差异性也极度影响着分割模型的泛化性和通用性,主要体现在以下几个方面:
(1)各类模态的医学影像之间差异大,如研究队列的大小、图像尺寸和维度、分辨率和体素(voxel)强度等。
(2)分割的语义标签的极度不平衡。相较于影像中的正常组织,病变区域一般都只占极少部分,这就造成了正常组织的体素标签与病灶组织的体素标签之间极度的类不平常。
(3)不同影像数据之间的专家标注差异大,并且一些图像的标注结果会存在模棱两可的情况。
(4)一些数据集在图像几何和形状等属性上差异明显,切片不对齐和各向异性的问题也非常严重。
提出一种鲁棒的基于2D UNet和3D UNet的自适应框架nnUMet。作者在各种任务上拿这个框架和目前的STOA方法进行了比较,且该方法不需要手动调参。最终nnUNet得到了最高的平均dice。
当前的医学图像分割被CNN的方法主导,但是在不同的任务上需要不同的结构和不同的调参策略才达到了各自任务的最佳,这些在某个任务上拿到第一的方法,在其他任务上却不行。
The Medical Segmentation Decathlon计划通过这种方式解决这个问题:希望参赛者设计一种算法,在10种数据集上进行测试,都能够达到很好的效果,而算法不能够针对某种数据集进行人为的调整,只能自动的去适应。
比赛分为两个阶段:(1)开发阶段参与者拿到7个数据集用于优化算法;(2)冻结代码后公开剩余的3个数据集,用于评估。
作者认为过多的人为调整网络结构,会导致对于特定数据集的过拟合。非网络结构方面的影响可能对于分割任务影响更大。
作者提出一种nnUNet(no-new-Net)框架,基于原始的UNet(很小的修改),不去采用哪些新的结构,如相残差连接、dense连接、注意力机制等花里胡哨的东西。相反的,把重心放在:预处理(resampling和normalization)、训练(loss,optimizer设置、数据增广)、推理(patch-based策略、test-time-augmentations集成和模型集成等)、后处理(如增强单连通域等)。
- 网络结构
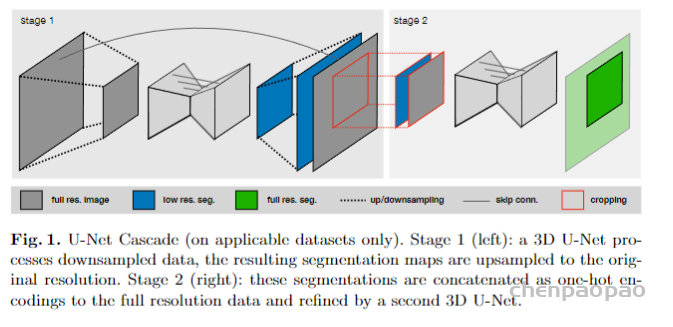
基础版UNet:2D UNet,3D UNet,UNet级联(第一级对下采样低分辨率图像进行粗分割,第二级结合第一级的结果进行微调,两级都用3DUNet)
微小修改:
(1)ReLU换 leaky ReLU(neg.slope 1e-2);
(2)Batch Norm换Instance Norm
网络拓扑自适应:输入图像尺寸会有不同,而硬件的资源是有限的,因此需要在网络容量和Batch-size上做到权衡。
默认参数设置:
2D UNet:crop-size<=256×256(中值尺寸小于256时,采用中值尺寸); batch-size<=42; base-channel=30; pooling to size>=8; pooling_num<6
3D UNet: crop-size<=128x128x128(中值尺寸小于128时,采用中值尺寸); batch-size>=2; base_channel=30; pooling to size>=8; poolingnum<6
- 预处理
整体数据Crop:只在非零区域内crop,减少计算消耗
Resample:数据集中存在不同spacing的数据,默认自动归一化到数据集所有数据spacing的中值spacing。原始数据使用三阶spline插值;Mask使用最邻近插值。
UNet Cascade采用特殊的Resample策略:中值尺寸大于显存限制下可处理尺寸的4倍时(batch-size=2),采用级联策略,对数据进行下采样(采样2的倍数,直到满足前面的要求);如果数据分辨率三个轴方向不相等,先降采样高分辨率轴使得三轴相等,再三轴同时降采样直到满足上述要求。
Normalization:
CT:通过统计整个数据集中mask内像素的HU值范围,clip出[0.05,99.5]百分比范围的HU值范围,然后使用z-score方法进行归一化;
MR:对每个患者数据单独执行z-score归一化。
如果crop导致数据集的平均尺寸减小到1/4甚至更小,则只在mask内执行标准化,mask设置为0.
- 训练过程
从头训练,使用五折交叉验证,loss函数:结合dice loss和交叉熵loss:

对于在全训练集上训练的3D-UNet(UNet Cascade的第一阶段和非级联的3D UNet,不包括UNet Cascade的第二阶段),对每一个样本单独计算dice loss,然后在batch上去平均。对其他的网络(2D UNet和UNet Cascade的第二阶段),将一个batch内的所有样本当做一个整体的样本计算整个batch上的dice(防止当crop后出现局部区域内不存在某一类时单独计算该类loss导致分母为零的情况,这也要保证batch-size不能太小)。
dice loss形式如下:

其中u为概率输出(softmax output),v为硬编码(one hot encoding)的ground truth。K为多分类类别数。
其他训练参数:
Adam优化器,学习率3e-4;250个batch/epoch;
学习率调整策略:计算训练集和验证集的指数移动平均loss,如果训练集的指数移动平均loss在30个epoch内减少不够5e-3,则学习率衰减5倍;
训练停止条件:当验证集指数移动平均loss在60个epoch内减少不够5e-3,或者学习率小于1e-6,则停止训练。
数据增广:随机旋转、随机缩放、随机弹性变换、伽马校正、镜像。
注意:
1.如果3D UNet的输入patch的尺寸的最大边长是最短边长的两倍以上,那么应用三维数据扩充可能是次优的。这种情况下可以使用2D的数据增广。
2.UNet Cascade的stage 2接收前一阶段的输出作为输入的一部分,为了防止强co-adaptation,我们可以应用随机形态学操作(erode、dilate、open、close),随机的去除掉一些分割结果的连通域。
patch采样:为了增加网络的稳定性,patch采样的时候会保证一个batch的样本中有超过1/3的像素是前景类的像素。这个很关键,否则你的前景dice会收敛的很慢。
- 推理(Inference)
所有的推理都是基于patch的。
patch的边界上精度会有损,因此在对patch重叠处的像素进行fuse时,边界的像素权重低,中心的像素权重高;patch重叠的stride为size/2;使用test-data-augmentation(增广方式:绕各个轴的镜像增广);使用了5个训练的模型集成进行推理(5个模型是通过5折交叉验证产生的5个模型)
- 后处理
主要就是使用连通域分析