device = “xcvu3p-ffvc1517-2-e”
参考:
https://thedatabus.io/convolver
https://github.com/sumanth-kalluri/cnn_hardware_acclerator_for_fpga
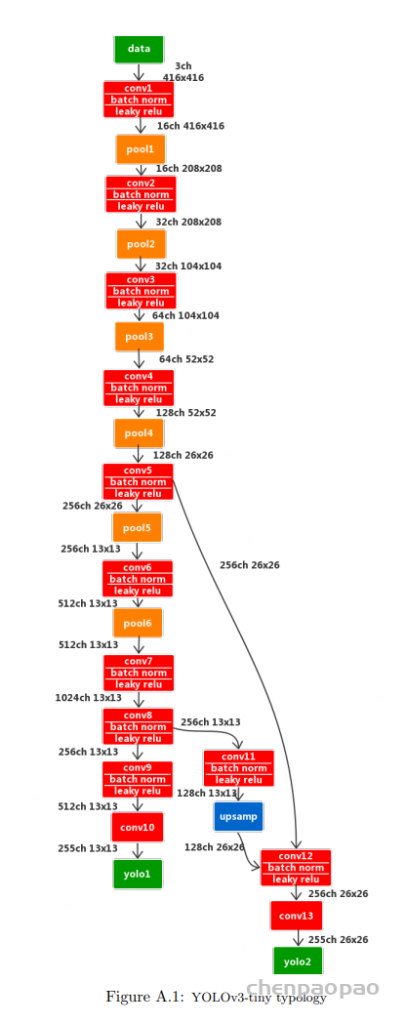
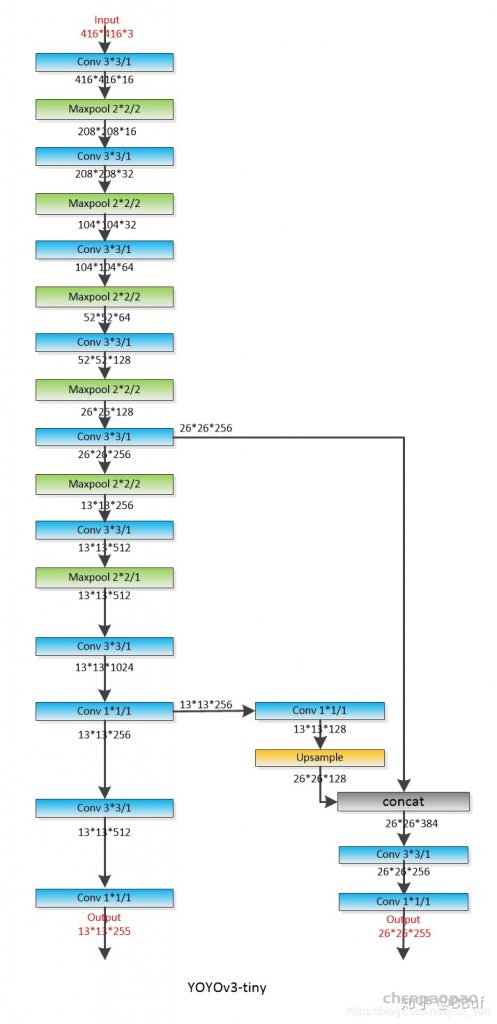
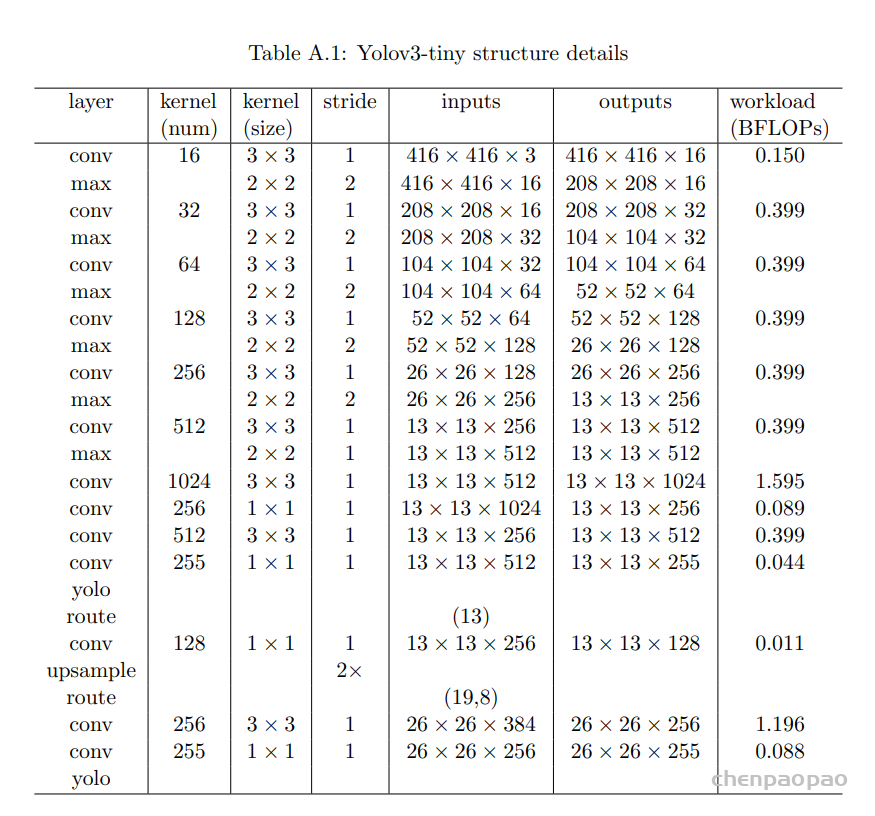
1、网络结构分析:
YOLOv3 的剪枝量化:
https://github.com/coldlarry/YOLOv3-complete-pruning
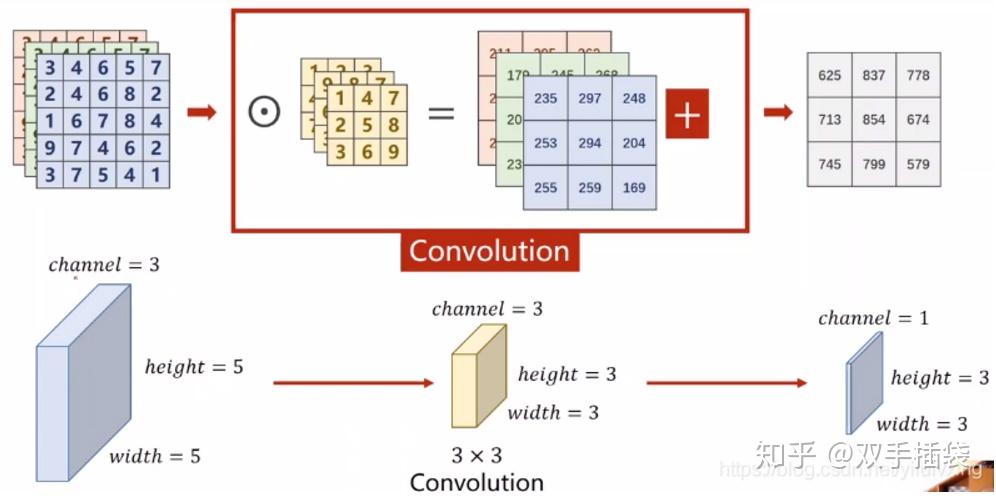
输出为单个通道:上述过程中,每一个卷积核的通道数量,必须要求与输入通道数量一致,因为要对每一个通道的像素值要进行卷积运算,所以每一个卷积核的通道数量必须要与输入通道数量保持一致
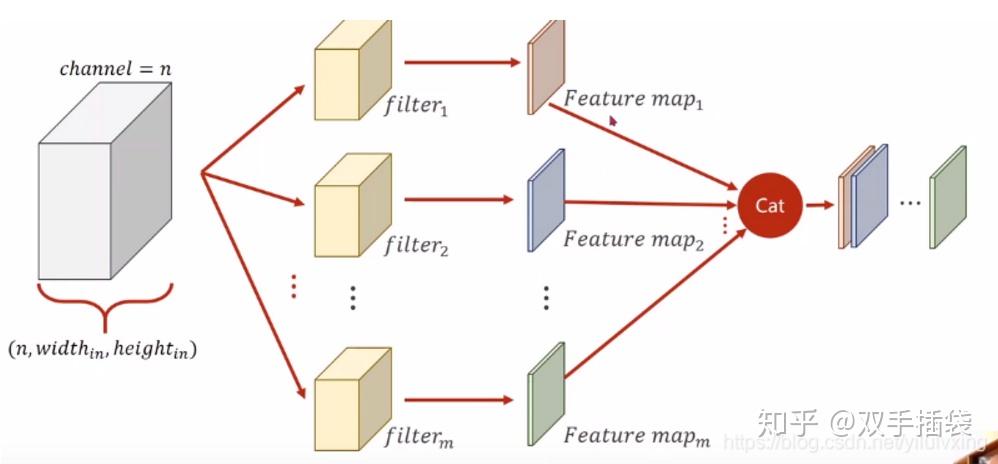
多通道:
输入 416*416*3 = 519,168 个值
conv0 : input_height=418 原因:这里是做1的填充,所以 最终输入是 416+2 =418
conv_0_param={.kernel_dim=3,
.pad=1,
.input_channel=3,
.input_width=418,
.input_height=418,
.output_channel=16,
.output_width=416,
.output_height=416};16*3个卷积核:一共16*3*9个卷积核参数 +16个bias == 》 432+16 个参数
输出: 416 *416* 16 个值,即2768896个输出
conv1 :
conv_1_param={.kernel_dim=3,
.pad=1,
.input_channel=16,
.input_width=210,
.input_height=210,
.output_channel=32,
.output_width=208,
.output_height=208};一共 32*16个卷积核 4608个卷积核权重参数,36个bias参数
该层输出: 208 *208* 32 = 1384448
conv2 :
conv_2_param={.kernel_dim=3,
.pad=1,
.input_channel=32,
.input_width=106,
.input_height=106,
.output_channel=64,
.output_width=104,
.output_height=104};一共 64 *32个卷积核 18432个卷积核权重参数,64个bias参数
该层输出: 104 *104*64 = 692224
conv3:
conv_3_param={.kernel_dim=3,
.pad=1,
.input_channel=64,
.input_width=54,
.input_height=54,
.output_channel=128,
.output_width=52,
.output_height=52};
一共 128*64个卷积核 73728个卷积核权重参数,128个bias参数
该层输出: 52 *52*128 = 346112
conv4: 256*128*9= 294912 个卷积核权重参数 ,256个偏置, 输出:26*26*256=173056
conv_4_param={.kernel_dim=3,
.pad=1,
.input_channel=128,
.input_width=28,
.input_height=28,
.output_channel=256,
.output_width=26,
.output_height=26};conv5:256*512*9 = 1179648个卷积核权重 512 个bias, 输出:13*13*512=86528
conv6:512*1024*9=4718592个卷积核权重,1024个bias,输出:13*13*1024=173056
conv7:1024*256*1 =262144个卷积层权重,256个bias,输出:13*13*256=43264
conv8:256*512*9 =1179648 个卷积层权重 ,512个bias 输出:13*13*512=86528
上面的卷积层:后面紧跟一个batchnormal层
CONV 9 and 12 have no batch norm layer
conv9 : 最后一层:512*255*1=130560个卷积权重,255个bias, 13*13*255= 43095
conv10: 256*128*1=32768个权重 128个bias 输出13*13*128=21632
conv11: 384*256*3 =305280 个参数 256个bias 输出26*26*256=173056
conv12: 256*255*1=65280个权重 255个bias 输出26*26*255 = 172380
wight= [448,4608,36,18432,64,73728,128,294912,256,1179648,512,4718592,1024,262144,256,1179648 ,512,130560,255,32768,128,305280,256,65280,255]
out: [ 519168,2768896,1384448, 692224,346112,173056,86528,173056,43264,86528,43095,21632,173056,172380]汇总:8269730个wight((八百多万) 输出结果中最大 2768896,最小21632
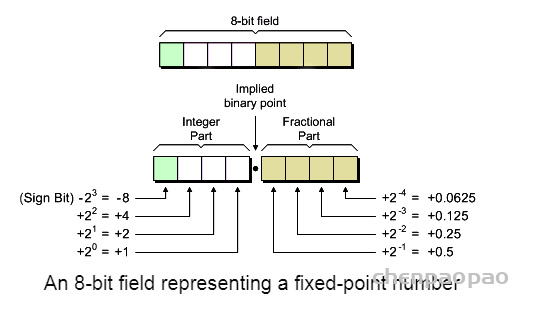
数据位宽:
在定点实现中,首先确定整数和小数部分使用了多少位是很重要的。对于线性量化,整数的位宽度与极值以及是否会发生溢出有关。另一方面,分数部分的长度影响量化误差。此外,量化的步长将影响数据的分布。对于不同的网络类型,应在比特宽度和网络精度之间进行彻底的权衡。
在定点实现中,首先确定整数和小数部分使用了多少位是很重要的。对于线性量化,整数的位宽度与极值以及是否会发生溢出有关。另一方面,分数部分的长度影响量化误差。此外,量化的步长将影响数据的分布。对于不同的网络类型,应在比特宽度和网络精度之间进行彻底的权衡。
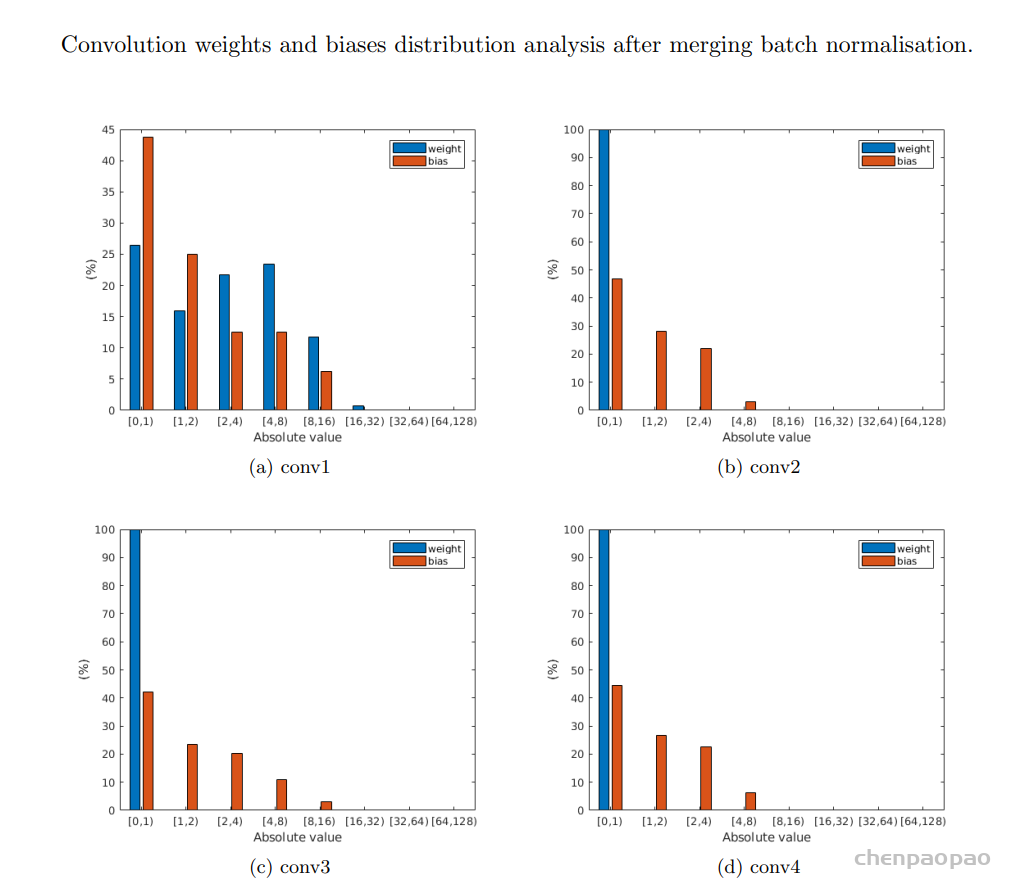
就总比特而言,2的幂次更可取。为了确定合适的比特宽度,在包含5000幅图像的COCO2014-val5k数据集上进行了实验。下表总结了所有卷积层的数据分布。很明显,所有输入和输出的绝对值都小于128。这意味着在不造成任何溢出的情况下,为有符号整数部分分配8位就足够了。

尝试使用8位表示整数部分,另外8位表示小数。建立了软件定点仿真系统:
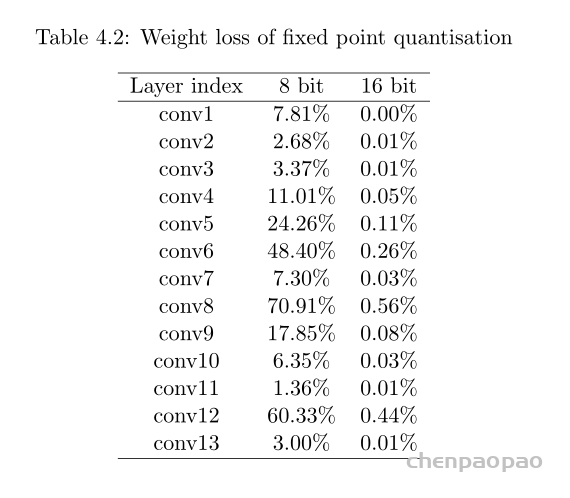
因此选择16bit存储权重以及16bit的数据权重,两者都由16位定点数字表示。对于卷积窗口的结果,采用32位以减少可能的溢出,并提供更高的累积精度。通过实施定点优化,数据宽度从32位压缩到16位,从而实现更高效的DMA传输。此外,使用定点表示为延迟和资源带来了实实在在的好处。
激活函数实现:
官方 float leaky_activate(float x){return (x>0) ? x : .1*x;}
使用动态定点量化时,激活函数 Leaky ReLU 也要进行相应的量化操作。当位宽 bw 为 16 时,使用与 0xccc 相乘和右移 15 位的定点运算来拟合与 0.1 相乘的操作。量化后的 Leaky ReLU 如下所示:
𝑓′(𝑥) = (𝑥 < 0)? (𝑥 ∗ 0xccc) ≫ 15: 𝑥
合并 Batch Normalisation
OLOv3 tiny中的大多数卷积层在激活前都会进行批量归一化。使用一些数学技术消除批次标准化是安全的。可以很容易地得到以下方程式。
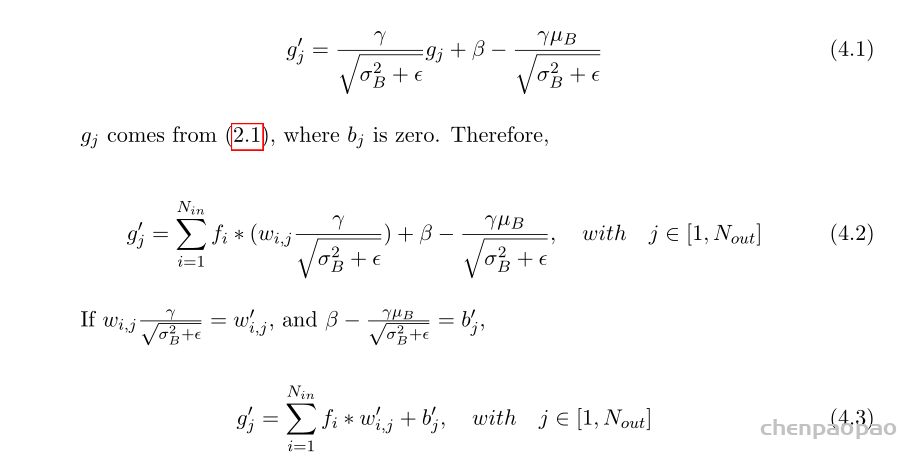
w’0ij和b’j是新的权重和偏差。因为这种转换可以在运行时之前完成,浮点计算过程中的一些可忽略的精度损失外。合并批次归一化也会影响权重的分布。
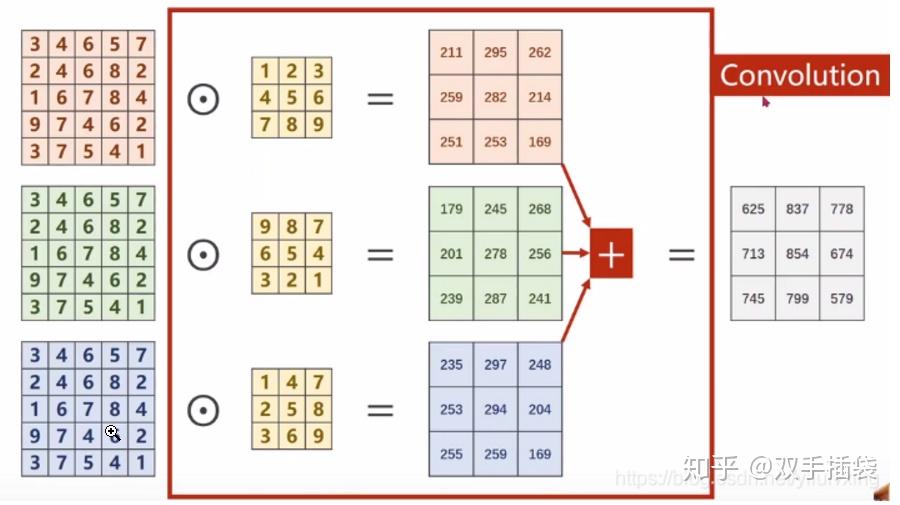
二维卷积:
2D 卷积是一种采用权重内核(或窗口或矩阵)并使用这些权重(此矩阵中的值)以某种方式修改输入图像(或特征图或激活图)的操作,pad 默认补0操作
激活函数
在神经网络中的各种数学线性运算之间引入了激活函数,目的是为整个网络引入非线性。没有它,整个神经网络将简化为单个线性函数,我们都知道这样的函数不足以模拟任何复杂的东西,忘记像图像识别这样的东西。
文献中有多种用于此目的的函数,但最常用(也是第一个)使用的函数是 ReLu(整流线性单元)和 Tanh(双曲正切)函数。
池化函数
池化本质上是一种“下采样”操作,旨在减少数据在网络中传播时的参数数量和复杂性。此过程涉及在输入上运行“池化窗口”并使用某种算法减小输入的大小。到目前为止,最常见的算法是 Max – Pooling 和 Average – Pooling。
最大池化——在这种方法中,我们只保留落入池化窗口的所有值中的最大值,并丢弃其他值。
平均池化 – 在此方法中,计算池化窗口内所有元素的平均值,并保留该值而不是所有值。
upsaming 上采样:
torch.nn.functional.upsample
nearest 采样
yolov3 中的上采样层使用的是2*2上采样:

import torch
from torch import nn
input = torch.arange(1, 5, dtype=torch.float32).view(1, 1, 2, 2)
input
tensor([[[[1., 2.],
[3., 4.]]]])
m = nn.Upsample(scale_factor=2, mode='nearest')
m(input)
返回:
tensor([[[[1., 1., 2., 2.],
[1., 1., 2., 2.],
[3., 3., 4., 4.],
[3., 3., 4., 4.]]]])
最邻近插值算法
首先假设原图是一个像素大小为W*H的图片,缩放后的图片是一个像素大小为w*h的图片,这时候我们是已知原图中每个像素点上的像素值(即灰度值等)的(⚠️像素点对应像素值的坐标都是整数)。这个时候已知缩放后有一个像素点为(x,y),想要得到该像素点的像素值,那么就要根据缩放比例去查看其对应的原图的像素点的像素值,然后将该像素值赋值给该缩放后图片的像素点(x,y)
缩放公式为:
- 根据横轴,即宽可得:X/x = W/w
- 根据纵轴,即高可得:Y/y = H/h
- 那么能够得到 f(X,Y)= f( W/w * x, H/h *y)
因此这个时候缩放后的图片像素点(x,y)的像素值就对应着原图像素点( W/w * x, H/h *y)的像素值
但是这个时候会出现一个问题就是因为缩放比例的原因,会导致像素点( W/w * x, H/h *y)中的值不是整数,那么就不知道应该对应的是哪个像素点的像素值
这个时候最邻近插值算法使用的方法就是四舍五入法,表示为[.],所以像素值f(x,y) = f( [W/w * x], [H/h *y])
举个例子,如果原图为5*5,缩放后的图为3*3,那么缩放后的图的像素点(1,1)对应的就是原图中([5/3 * 1], [5/3 * 1]) = ([0.6], [0.6]) = (1,1) 像素点对应的像素值
这种方法的好处就是简单,但是坏处就是太过粗暴,会缺失精度,造成缩放后的图像灰度上的不连续,在变化地方可能出现明显锯齿状,如下图所示:(左原图,右缩放后)
累加层accumulate:
在yolo中存在累加操作:conv层 的输出与另外一个conv层输出加和:
yolo输出层
yolo在经过多个卷积和上采样之后最终得到的是2个个卷积结果(13*13*255,26*26*255),每一个卷积结果的长和宽分别是(13×13,26×26),深度信息是 [4(box信息)+1(物体判别信息)+80(classNum置信度)] *3(每个点上面计算几个anchor)
对于具有Gh×Gw×Nin输入的YoLO层,它将原始图像划分为 Gh×Gw 网格。通道数n等于(4 +1+C)×B,其中B表示在一个网格中可以检测到多少个对象,C表示对象类别的数量。在YOLOv3 tiny中,B设置为3,COCO数据集中有80个类(c=80).
因此,YLO层的输入具有255的恒定值,这进一步分为3组( 表示在一个网格中可以检测 3种对象)。在每组中,4个通道提供关于边界框的信息,1个通道表示对象分数,其余80个通道表示单个类分数。Yolo层在所有通道上使用Sigmod激活函数,除了表示边界框宽度和高度的通道以外。关键在于指定哪些通道应该通过sigmoid函数,哪些通道应该不被触及。解决方案是提供一个表,其中每个位都表示是否应转换通道。
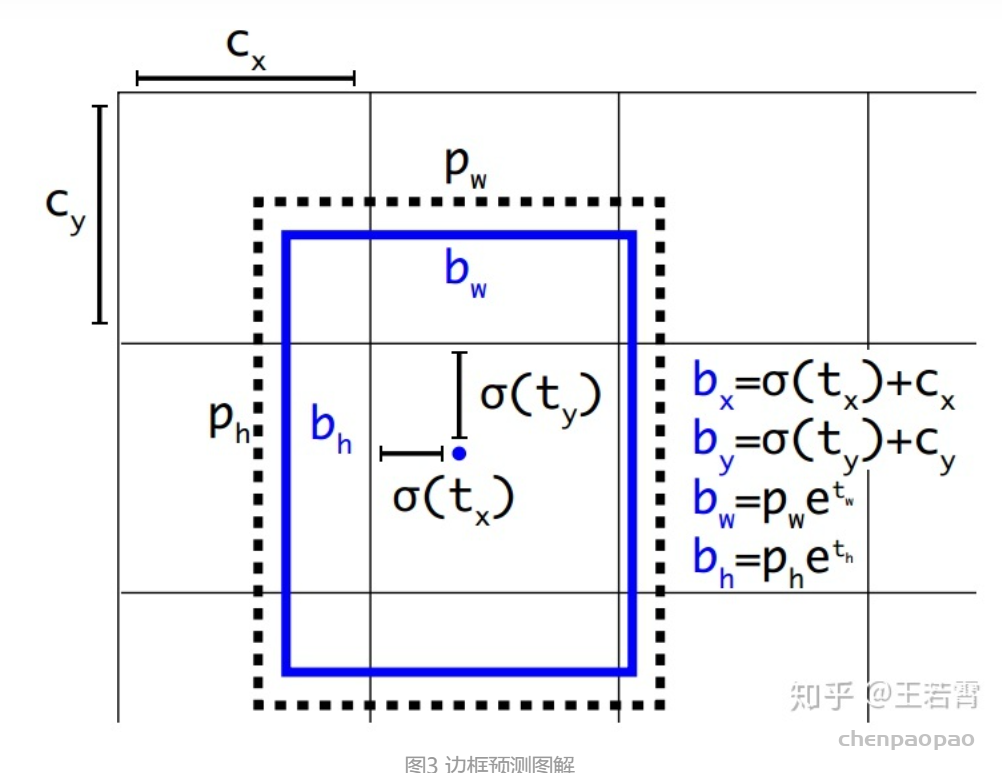
最终得到的边框坐标值是bx,by,bw,bh即边界框bbox相对于feature map的位置和大小,是我们需要的预测输出坐标。但网络实际上的学习目标是tx,ty,tw,th这4个偏移量(offsets),其中tx,ty是预测的坐标偏移值,tw,th是尺度缩放,有了这4个offsets,自然可以根据图2的公式去求得真正需要的bx,by,bw,bh4个坐标。bx,by是预测框中心坐标,bw,bh是预测框的宽高

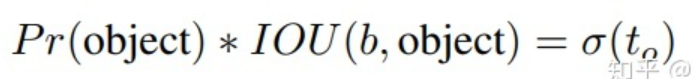
其中 \(C_{x} C_{y}\)是 feature map上anchor box的宽和高, \(t_{y}, t_{w} t_{z} t_{x}\)是 4个通道提供关于边界框的信息

Cx,Cy是feature map中grid cell的左上角坐标,在yolov3中每个grid cell在feature map中的宽和高均为1。如图3的情形时,这个bbox边界框的中心属于第二行第二列的grid cell,它的左上角坐标为(1,1),故Cx=1,Cy=1。Pw、Ph是预设的anchor box映射到feature map中的宽和高,在yolov3.cfg文件中的anchor box原本设定是相对于416*416坐标系下的坐标,代码中是把cfg中读取的坐标除以stride如32映射到feature map坐标系中。
yolov3.cfg文件中的anchor box :
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
问题:anchor box作用的详细描述。
解答:YOLO3为每种FPN预测特征图(13*13,26*26,52*52)设定3种anchor box,总共聚类出9种尺寸的anchor box。在COCO数据集这9个anchor box是:(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90),(156×198),(373×326)。分配上,在最小的13*13特征图上由于其感受野最大故应用最大的anchor box (116×90),(156×198),(373×326),(这几个坐标是针对416*416下的,当然要除以32把尺度缩放到13*13下),适合检测较大的目标。中等的26*26特征图上由于其具有中等感受野故应用中等的anchor box (30×61),(62×45),(59×119),适合检测中等大小的目标。较大的52*52特征图上由于其具有较小的感受野故应用最小的anchor box(10×13),(16×30),(33×23),适合检测较小的目标。同Faster-Rcnn一样,特征图的每个像素(即每个grid)都会有对应的三个anchor box,如13*13特征图的每个grid都有三个anchor box (116×90),(156×198),(373×326)(这几个坐标需除以32缩放尺寸)。
卷积:
yolo卷积默认补0
主要思想是构建一个高度流水线的流式架构,其中处理模块不必在任何时间点停止。即卷积器的任何部分都不会等待任何其他部分完成其工作并提供结果。每个阶段在每个时钟周期的输入的不同部分上连续执行整个工作的一小部分。这不仅仅是该设计的一个特点,它是一种称为“流水线”的一般原则,广泛用于将大型计算过程分解为更小的步骤,并提高整个电路可以运行的最高频率。
- 设计使用 MAC(乘法和累加)单元,旨在将这些操作映射到 FPGA 的 DSP 模块。实现这一点将使乘法和加法运算更快,并且消耗更少的功率,因为 DSP 模块是在硬宏中实现的。也就是说,DSP 模块已经以最有效的方式合成、放置和路由到 FPGA 设备上的硅片中,这与一般 IP 模块不同,后者只向您提供经过试验和测试的 RTL 代码并且可以合成随心所欲。
- 卷积器只不过是一组 MAC 单元和一些移位寄存器,当它们提供正确的输入时,在固定数量的时钟周期后输出卷积的结果
- 输入特征图(图像)的大小是一个维度
NxN,我们的内核(过滤器/窗口)是维度KxK。显然可以理解,即K < N. -
s表示窗口在特征图上移动的步幅值。 - 我们还有一些信号,例如
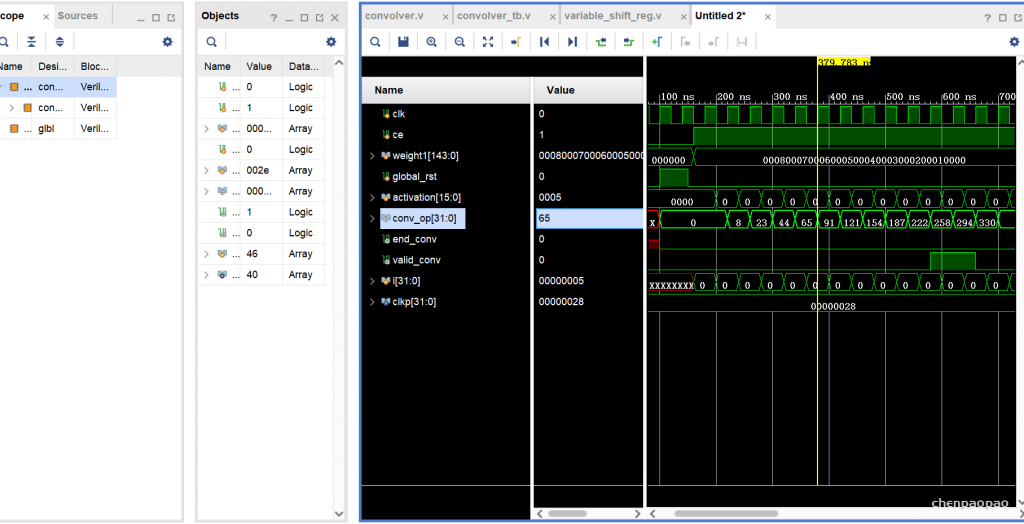
valid_conv和end_conv信号,它们告诉外界这个卷积器模块的输出是否有效。但是为什么卷积器首先会产生无效的结果呢?窗口在输入的特定行上完成移动后,它会继续环绕到下一行,从而创建无效输出。可以避免在环绕期间进行计算,但这需要我们停止流水线,这违反了我们的流式设计原则。因此,我们只是在信号的帮助下丢弃我们认为无效的输出valid conv。
具体流程:
下一次从a1开始输入,输出 输出 = w0*a01+ w1*a2 + w2*a3 + w3*a5 + w4*a6 + w5*a7 + w6*a9 + w7*a10 + w8*a11
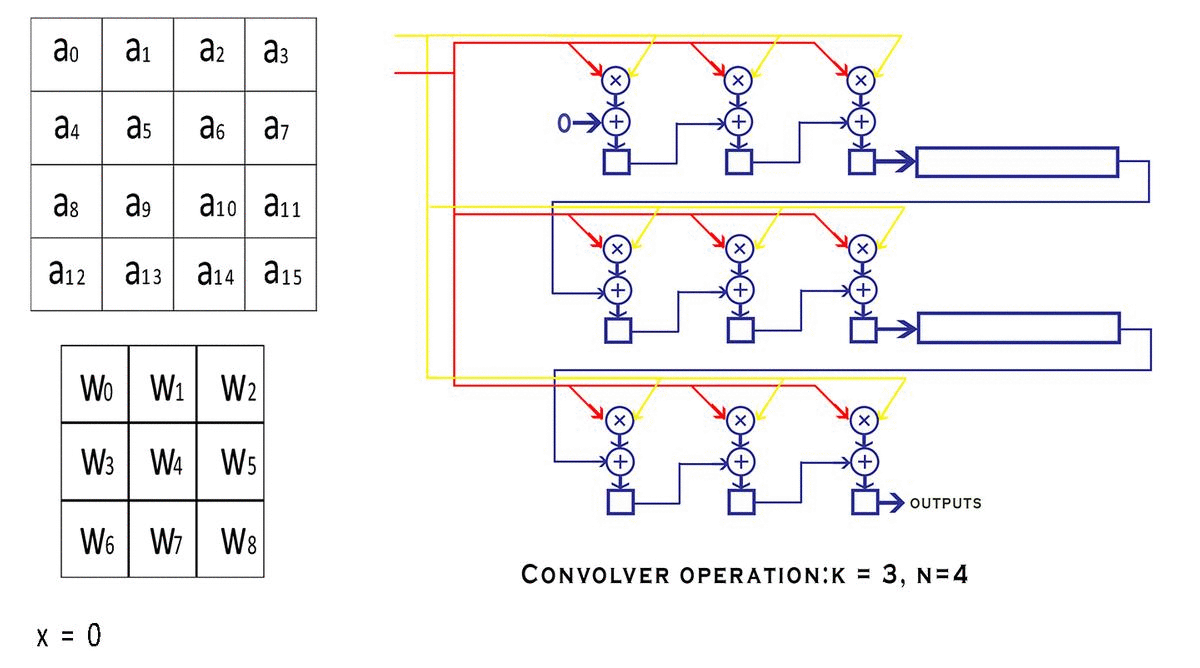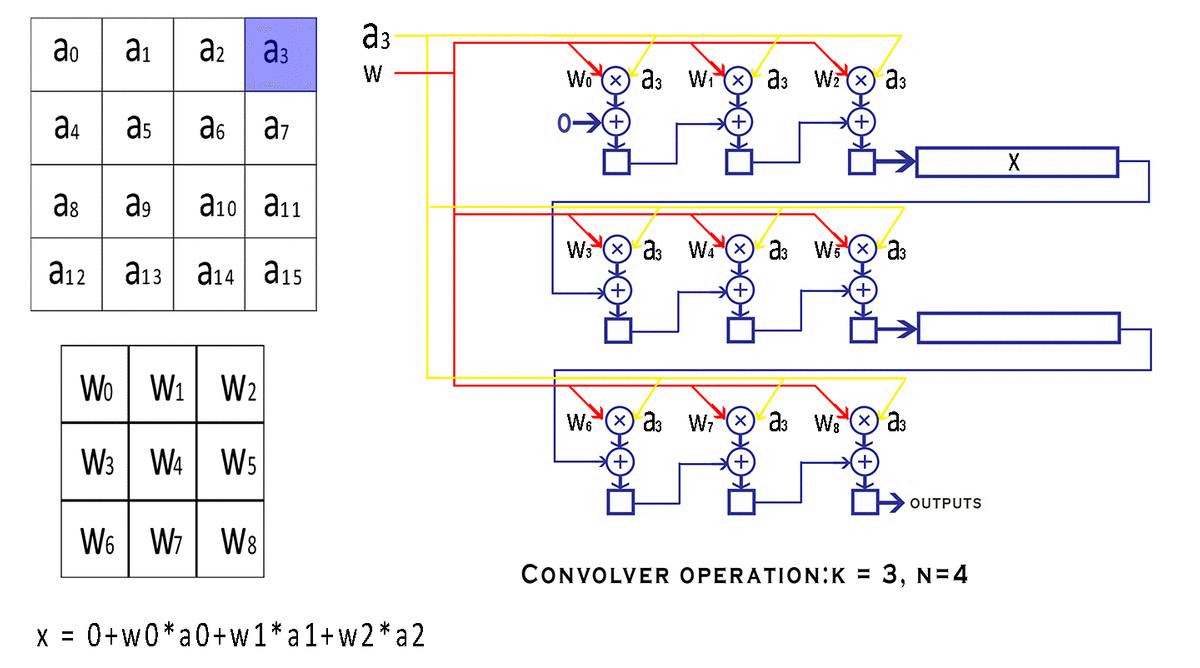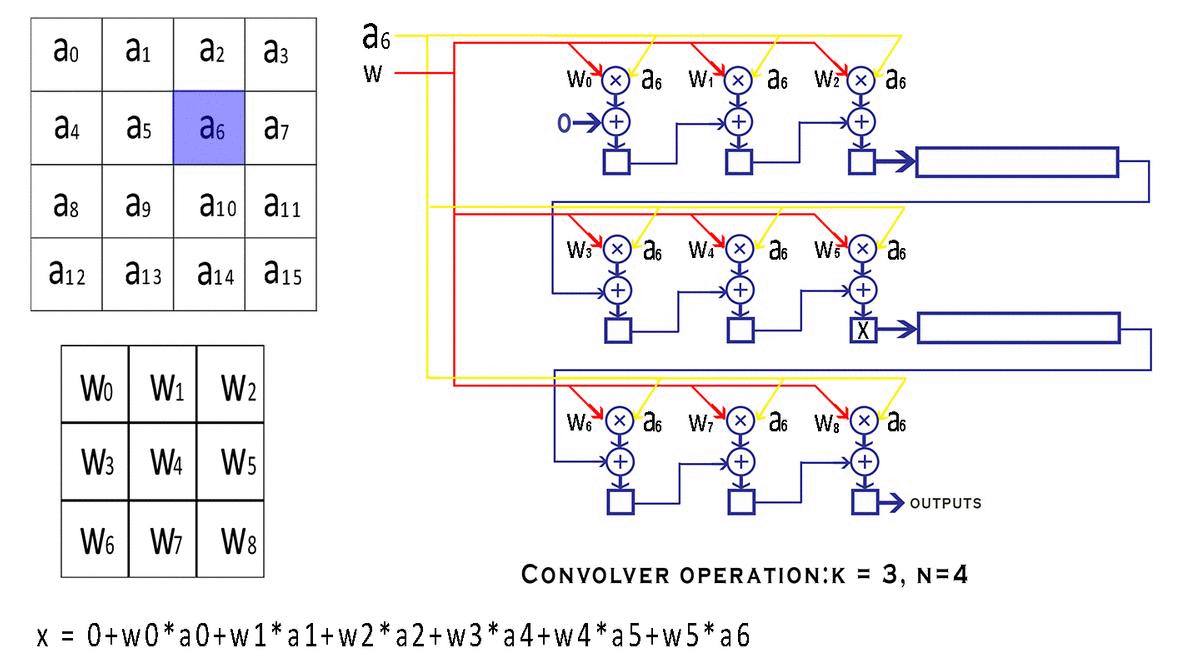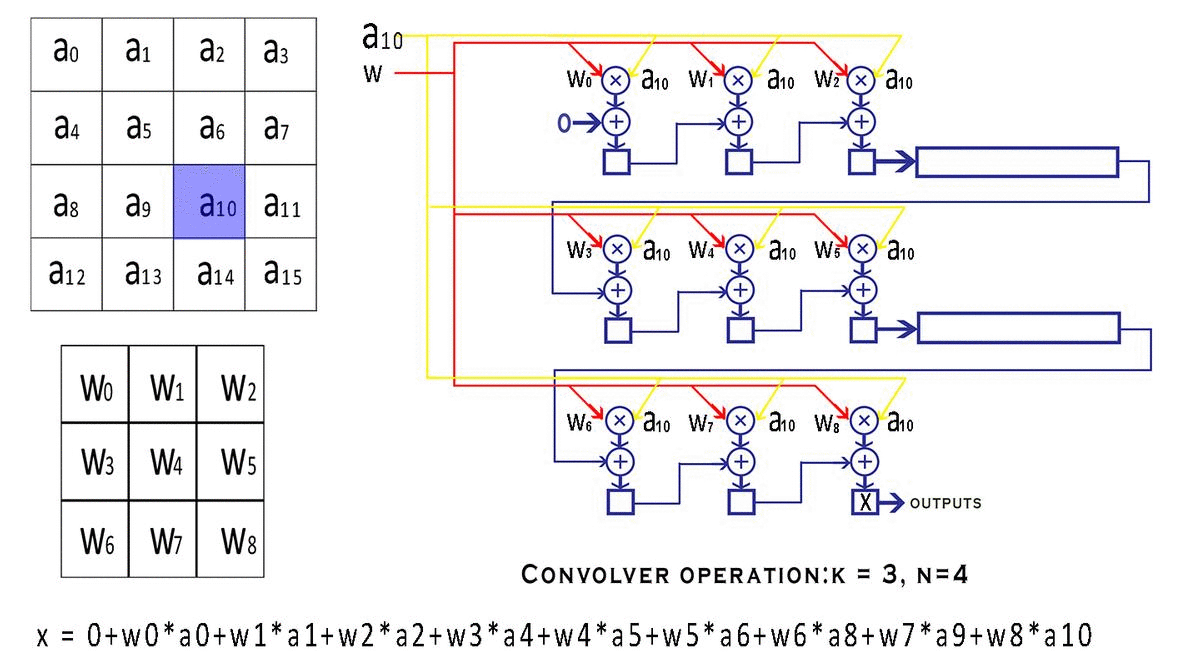
输出 = w0*a0 + w1*a1 + w2*a2 + w3*a4 + w4*a5 + w5*a6 + w6*a8 + w7*a9 + w8*a10
这种架构的优点:
- 输入特征图只需发送一次(即存储的激活必须从内存中访问一次),从而大大减少了内存访问时间和存储需求。移位寄存器为先前访问的值创建一种本地缓存。
- 可以使用此架构计算任何大小输入的卷积,而无需由于计算能力低而中断输入或将其临时存储在其他地方
- 对于一些需要更大步幅的奇异架构,步幅值也可以更改。
代码:
import numpy as np
from scipy import signal
ksize = 3 #ksize x ksize convolution kernel
im_size = 4 #im_size x im_size input activation map
def strideConv(arr, arr2, s): #the function that performs the 2D convolution
return signal.convolve2d(arr, arr2[::-1, ::-1], mode='valid')[::s, ::s]
kernel = np.arange(0,ksize*ksize,1).reshape((ksize,ksize)) #the kernel is a matrix of increasing numbers
act_map = np.arange(0,im_size*im_size,1).reshape((im_size,im_size)) #the activation map is a matrix of increasin numbers
conv = strideConv(act_map,kernel,1)
print(kernel)
print(act_map)
print(conv) 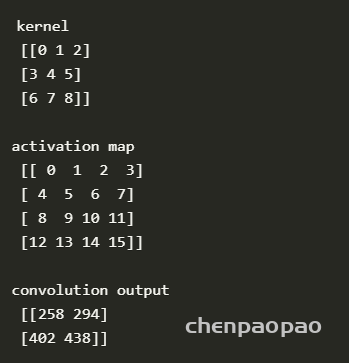
单个加法:
module mac_manual #(
parameter N = 16,
parameter Q = 12
)(
input clk,sclr,ce,
input [N-1:0] a,
input [N-1:0] b,
input [N-1:0] c,
output reg [N-1:0] p
);
always@(posedge clk,posedge sclr)
begin
if(sclr)
begin
p<=0;
end
else if(ce)
begin
p <= (a*b+c); //performs the multiply accumulate operation
end
end
endmodule
卷积中的偏置:
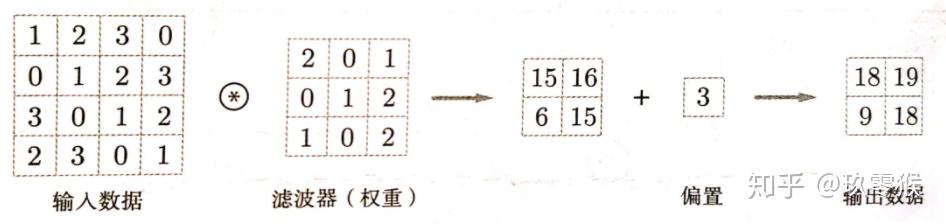
多卷积核的偏置:同一个通道的卷积核共用一个偏置。每个卷积核卷积后的结果+bias
https://cs231n.github.io/assets/conv-demo/index.html
定点表示:
定点数字是小数点位置保持固定的数字,与数字所代表的值无关。与浮点数相比,这使得定点数更易于理解以及在硬件中实现。与浮点运算相比,定点运算使用的资源也少得多。当然,所有这些都需要权衡。浮点运算可以为特定位宽提供比定点运算更高的精度。当我们使用二进制点位于固定位置的数字时,我们会在量化噪声方面受到打击,尽管该数字表示幅度。