
FPGA大规模加法树的实现
思路:generate 生成 n 个数,对n个数求和,将v1中的 mult_w[i] 改为我们并行N个conv的输出 reg[N-1:0] out[16:0]
参考博客1
github
之前在设计中遇到过1个问题,如何在verilog中并行实现大量数据(几十、几百个甚至更多)的加法操作。
最直接想到的方法一般会类似:
reg [7:0]
data [N - 1 : 0];
wire[M:0]
sum; assign sum = data[0] + data[1] + ... + data[N-1];这种方法本身没有问题,但是随着N不断增大,代码量也会随之不断增加,而且很容易写错。 另外,加法是组合逻辑,为了提高时序性能,需要在若干个数的加法结果之后插入一级register,进行pipeline设计。在这种情况下,如果按照上面那种方式写代码量就更大了。 后来又想到用generate for语句,代码量同样很大。
在项目过程中需要用FPGA在尽量少的时钟周期内实现多个数据相加。如果直接用组合的形式实现延迟太高,占用资源也太多,因此考虑基于流水线的并行加法树来实现多个数据相加
上述程序都是使用system verilog设计的,其中最精髓的一个思想就是模块的递归调用。仅通过1个模块就可以实现任意bit位宽,任意数量的数据进行并行加法计算。
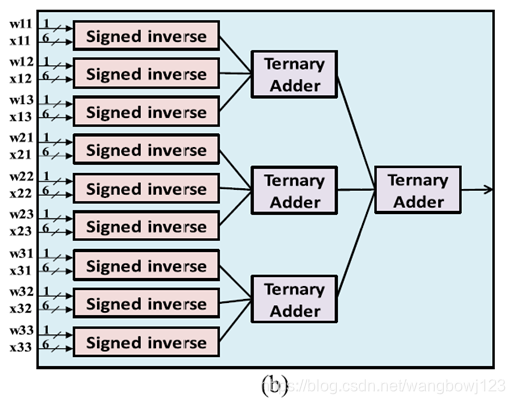
主要原理为:通过N分法,将输入数据分成N组,每一组递归调用模块自身,然后在递归调用的模块里再继续分为N组……不断重复,直到最后分解为X组N个数的加法或单个数,类似于二叉树的结构。然后计算过程就是从二叉树的最底层逐层向上进行,直到达到最顶层得出最后的计算结果。同时,在每层N叉树的节点都插入1级pipeline register,相当于每N个数的加法逻辑后都插入1级pipeline register。这种设计结构可称之为并行加法树。
版本1:
为了进一步增加并行性,加法树结构采用二叉树。即,对每2个子节点进行求和。最终得到一个部分和。实现方式是写一个加法器模块,再写一个乘法器模块(模拟conv层),之后再写一个总体的模块将这些乘法器和加法器进行结合。
// 加法器模块
module adder(
input clk,
input rst_n,
input [15 : 0] a,
input [15 : 0] b,
input [15 : 0] c,
output [15 : 0] result
);
reg [15 : 0] result_reg;
assign result = result_reg;
always @ (posedge clk or negedge rst_n)
begin
if(!rst_n)
result_reg <= 16'b0;
else
begin
result_reg <= a + b ;
end
end
endmodule
无流水线加法器树:实现的8个输入,三级加法树:实现了1到8的平方和
module add_module(
input clk,
input rst_n,
output [15 : 0]result
);
reg [15 : 0] result_reg;
wire [15:0] mult_w [7:0];
wire [15:0] adder_w [3 : 0];
reg [15:0] num_reg [7:0];
wire [15:0] second [1:0];
genvar i;
generate
for(i = 0; i < 8; i = i + 1)
begin: mults
mult
u_mult(
.clk(clk),
.rst_n(rst_n),
.a(num_reg[i]),
.b(num_reg[i]),
.result(mult_w[i])
);
end
endgenerate
genvar j;
generate
for(j = 0; j < 4; j = j + 1)
begin: adders
adder
u1_adder(
.clk(clk),
.rst_n(rst_n),
.a(mult_w[j * 2 + 0]),
.b(mult_w[j * 2 + 1]),
.result(adder_w[j])
);
end
endgenerate
genvar k;
generate
for(k = 0; k < 2; k = k + 1)
begin: adders_2
adder
u2_adder(
.clk(clk),
.rst_n(rst_n),
.a(adder_w[k * 2 + 0]),
.b(adder_w[k * 2 + 1]),
.result(second[k])
);
end
endgenerate
adder
fin_adder(
.clk(clk),
.rst_n(rst_n),
.a(second[0]),
.b(second[1]),
.result(result)
);
integer s;
always@(posedge clk)
begin
if(!rst_n)
begin
result_reg <= 16'b0;
for(s = 0; s < 8; s = s + 1)
begin
num_reg[s] <= 16'd0;
end
end
else
begin
end
end
genvar l;
generate
for(l = 0; l < 8; l = l + 1)
begin:nums
always@(posedge clk or posedge rst_n)
begin
if(rst_n)
num_reg[l] <= l + 1;
end
end
endgenerate
endmodule最后在FPGA硬件上验证通过。
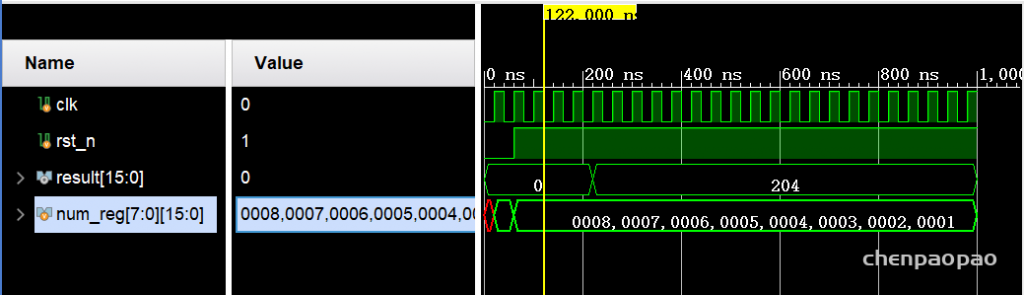
num_reg 含有8个16位寄存器,result输出204,表示 1-8的平方和
进阶版本1:无流水线有符号加法树的实现+参数化输入个数和数据位宽
参数化:求lenght个位宽为data_width的数的和。 lenght data_width 可配置
思路:在 lenght >1时,将 data_width 个数分为两块,每块分别递归例化一个同样的子模块,模块的输出为两个子模块输出的和;在 lenght ==1时,递归终止,模块的输出等于输入。
module AdderTree_v1(in_addends, out_sum);
parameter data_width = 8; //输入的数据宽度
parameter lenght = 4; //输入的数据个数
localparam out_width = data_width + $clog2(lenght);
localparam lenght_A = lenght / 2;
localparam lenght_B = lenght - lenght_A;
localparam out_width_A = data_width + $clog2(lenght_A);
localparam out_width_B = data_width + $clog2(lenght_B);
input signed [data_width*lenght-1:0] in_addends;
output signed [out_width-1:0] out_sum;
generate
//终止条件
if (lenght == 1) begin
assign out_sum = in_addends;
end else begin
wire signed [out_width_A-1:0] sum_a;
wire signed [out_width_B-1:0] sum_b;
reg signed [data_width*lenght_A-1:0] addends_a;
reg signed [data_width*lenght_B-1:0] addends_b;
always@(*) begin
addends_a = in_addends[data_width*lenght_A-1:0];
addends_b = in_addends[data_width*lenght-1:data_width*lenght_A];
end
//divide set into two chunks, conquer
//模块的递归调用
AdderTree_v1 #(
.data_width(data_width),
.lenght(lenght_A)
) subtree_a (
.in_addends(addends_a),
.out_sum(sum_a)
);
AdderTree_v1 #(
.data_width(data_width),
.lenght(lenght_B)
) subtree_b (
.in_addends(addends_b),
.out_sum(sum_b)
);
assign out_sum = sum_a + sum_b;
end
endgenerate
endmodule
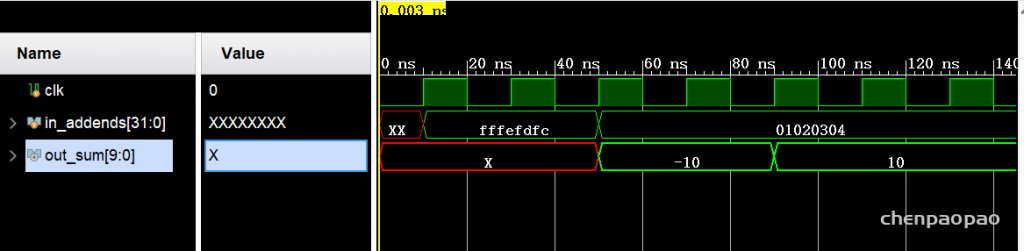
in_addends[31:0] 输入 {-1,-2,-3,-4},输出: out_sum
电路图:并行计算高位两数的和与低位两数的和,再将所得结果相加,没有产生多余的逻辑。

进阶版本2:基于流水线有符号加法树的实现+参数化输入个数和数据位宽
使用流水线加法器树:当待求和的数据较多时,往往需要在加法器之间插入寄存器形成流水线。
思路:尝试将组合逻辑
assign out_sum = sum_a + sum_b;
修改为时序逻辑:
always@(posedge clk)begin
out_sum <= sum_a + sum_b;
end
出现的问题1
但是这样编译器会报错,因为我在同一个模块中既把out_sum当做wire类型来用,又把它当做reg类型来用。
解决办法 :定义一个 reg类型 out_sum_buf
reg signed [OUT_WIDTH-1:0] out_sum_buf;
assign out_sum = out_sum_buf;
always@(posedge clk)begin
out_sum_buf <= sum_a + sum_b;
end出现的问题2
如果lenght是2的整数次幂,这样就足够了。但是当 lenght 不是2的整数次幂时,就会出现下面这种情况( lenght ==3):

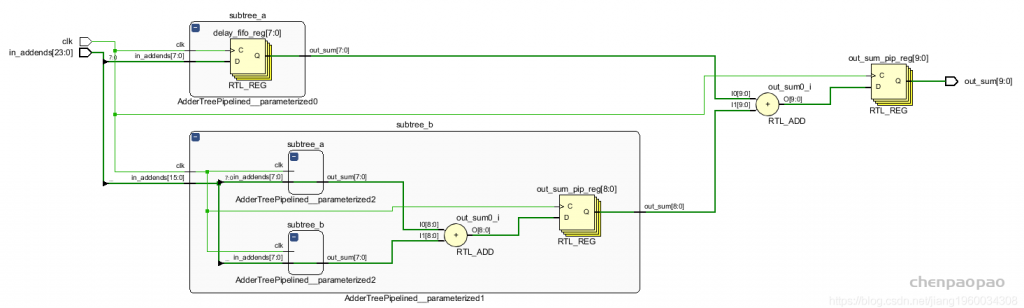
当lenght不是2的整数次幂时,每条路径上的加法器数目可能会不同。在纯组合逻辑中,它会导致输出产生毛刺,我们可以通过在输出端加一级寄存器将其去除。而在时序逻辑中,如果我们只是简单地在每个加法器后面插一个寄存器,会直接导致时序错位。
以上图为例,输入in_addends的高16位(高位数)经过一级寄存器后到达第二个加法器,而低8位(低位数)直接到达第二个加法器,于是输出变成了输入的低位数与上一周期的高位数的和。
正确的电路应当是这样的:
在lenght等于1时,同样需要判断是否需要插入寄存器。好在判断的逻辑并不复杂。考虑到在递归开始前我们就可以确定每条路径应当有几级寄存器,即log2( lenght),另外,子模块的寄存器级数比它的上一级少1。我们可以增加一个参数delay_stage,在最高层它的值为$clog2(lenght),每次例化子模块时使用的值为 delay_stage -1。这样,在 lenght 等于1时, delay_stage 的数值就是该模块还需要插入的寄存器级数。
插入 delay_stage 级寄存器可以用移位寄存器实现:
if (LENGTH == 1) begin
// 该分支是 无法整除的分支
if (DELAY_STAGE > 1) begin
reg [DELAY_STAGE * DATA_WIDTH - 1 : 0]delay_fifo;
always@(posedge clk) begin
delay_fifo <= {delay_fifo[(DELAY_STAGE-1)*DATA_WIDTH-1:0],in_addends};
end
assign out_sum = delay_fifo[(DELAY_STAGE-1)*DATA_WIDTH-1:0];
end
else if (DELAY_STAGE == 1) begin
reg [DATA_WIDTH - 1 : 0]delay_fifo;
always@(posedge clk) begin
delay_fifo <= in_addends;
end
assign out_sum = delay_fifo;
end
else begin
assign out_sum = in_addends;
end
end 这里额外加了个DELAY_STAGE 等于1的分支,是因为DELAY_STAGE 等于1时delay_fifo[(DELAY_STAGE-1)*DATA_WIDTH-1:0]变成了delay_fifo[-1:0],这也是编译器不允许的。
module AdderTreePipelined(in_addends, out_sum, clk);
parameter DATA_WIDTH = 8;
parameter LENGTH = 3;
parameter DELAY_STAGE = $clog2(LENGTH);
localparam OUT_WIDTH = DATA_WIDTH + $clog2(LENGTH);
localparam LENGTH_A = LENGTH / 2;
localparam LENGTH_B = LENGTH - LENGTH_A;
localparam OUT_WIDTH_A = DATA_WIDTH + $clog2(LENGTH_A);
localparam OUT_WIDTH_B = DATA_WIDTH + $clog2(LENGTH_B);
input clk ;
input [DATA_WIDTH*LENGTH-1:0] in_addends ;
output signed [OUT_WIDTH-1:0] out_sum ;
reg signed[OUT_WIDTH-1:0] out_sum_pip;
generate
genvar i;
if (LENGTH == 1) begin
if (DELAY_STAGE > 1) begin
reg [DELAY_STAGE * DATA_WIDTH - 1 : 0]delay_fifo;
always@(posedge clk) begin
delay_fifo <= {delay_fifo[(DELAY_STAGE-1)*DATA_WIDTH-1:0],in_addends};
end
assign out_sum = delay_fifo[(DELAY_STAGE-1)*DATA_WIDTH-1:0];
end
else if (DELAY_STAGE == 1) begin
reg [DATA_WIDTH - 1 : 0]delay_fifo;
always@(posedge clk) begin
delay_fifo <= in_addends;
end
assign out_sum = delay_fifo;
end
else begin
assign out_sum = in_addends;
end
end
else begin
wire signed[OUT_WIDTH_A-1:0] sum_a;
wire signed[OUT_WIDTH_B-1:0] sum_b;
wire [DATA_WIDTH * LENGTH_A - 1:0] addends_a;
wire [DATA_WIDTH * LENGTH_B - 1:0] addends_b;
assign addends_a = in_addends[DATA_WIDTH * LENGTH_A - 1: 0];
assign addends_b = in_addends[LENGTH * DATA_WIDTH - 1: DATA_WIDTH * LENGTH_A];
//divide set into two chunks, conquer
AdderTreePipelined #(
.DATA_WIDTH(DATA_WIDTH),
.LENGTH(LENGTH_A),
.DELAY_STAGE(DELAY_STAGE - 1)
) subtree_a (
.in_addends(addends_a),
.out_sum(sum_a),
.clk(clk)
);
AdderTreePipelined #(
.DATA_WIDTH(DATA_WIDTH),
.LENGTH(LENGTH_B),
.DELAY_STAGE(DELAY_STAGE - 1)
) subtree_b (
.in_addends(addends_b),
.out_sum(sum_b),
.clk(clk)
);
always@(posedge clk) begin
out_sum_pip <= sum_a + sum_b;
end
assign out_sum = out_sum_pip;
end
endgenerate
endmodule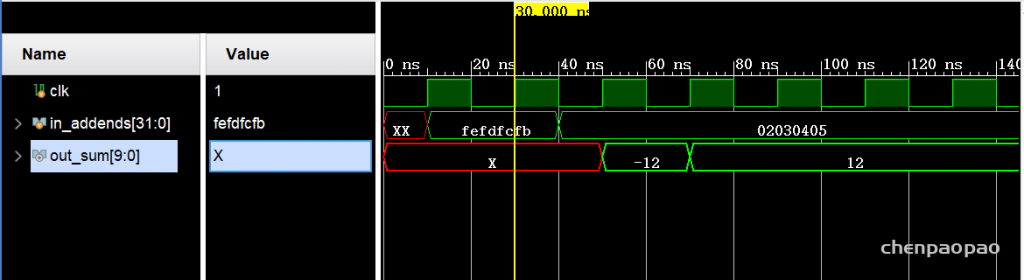
in_addends = {-8’d1,-8’d2,-8’d3,-8’d4,-8’d5};
in_addends = {8’d1,8’d2,8’d3,8’d4,8’d5};