软件部分–以硬件为指导中心
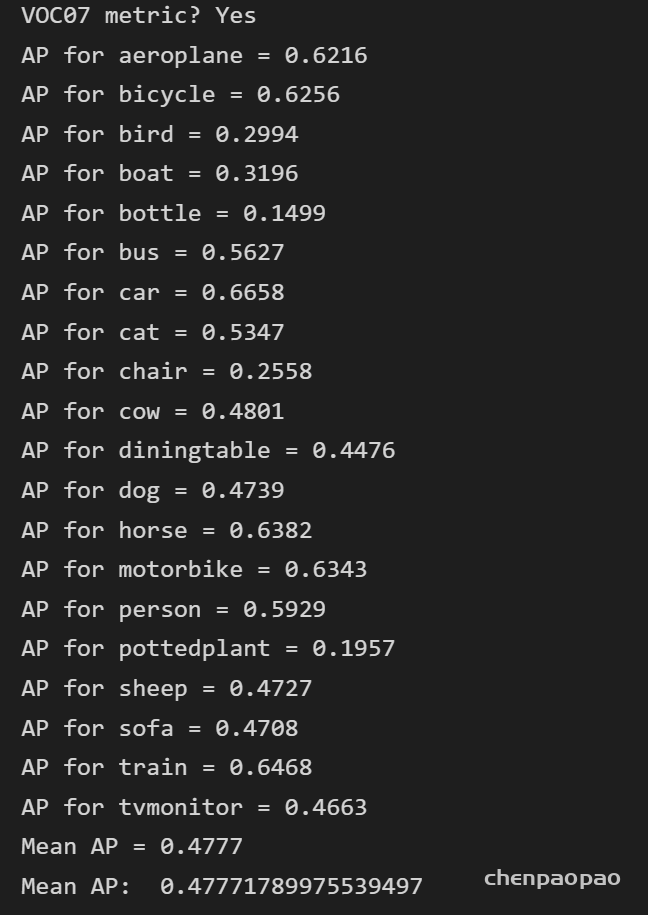
1、软件测试结果:
Nvidia 2070 Ti 单张图片预测时间 在0.02-0.025 S 之间

测试结果:







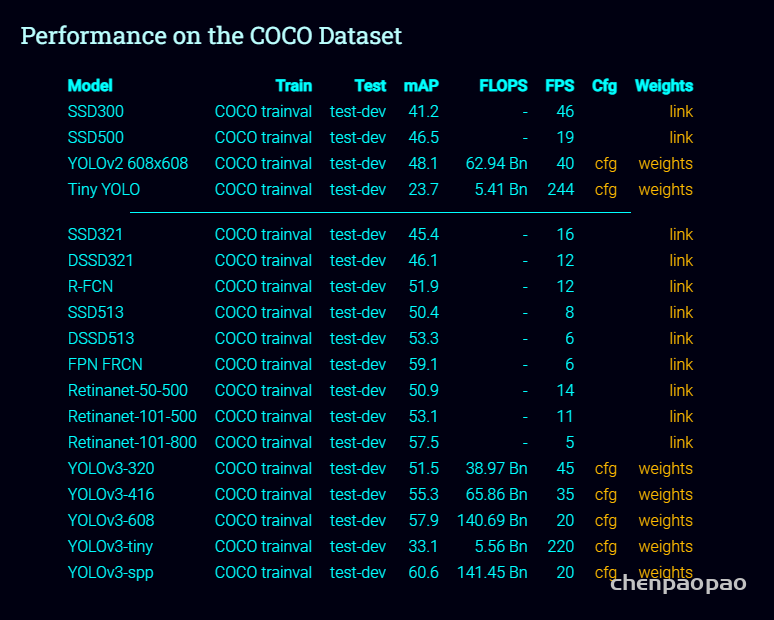
BN_conv融和:
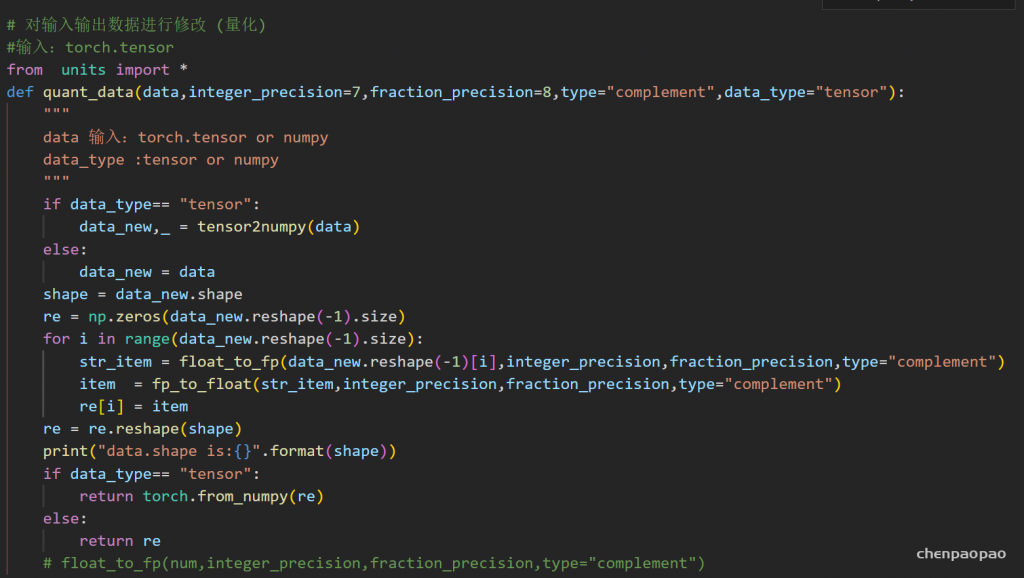
YOLOv3_tiny_quantize_bnfuse(
(a_tracker_in): AveragedRangeTracker()
(conv1): Conv2d_fuse(
(convs): Sequential(
(0): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): LeakyReLU(negative_slope=0.125, inplace=True)
)
)
(a_tracker1): AveragedRangeTracker()
(pool1): MaxPool2d(kernel_size=(2, 2), stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d_fuse(
(convs): Sequential(
(0): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): LeakyReLU(negative_slope=0.125, inplace=True)
)
)
(a_tracker2): AveragedRangeTracker()
(pool2): MaxPool2d(kernel_size=(2, 2), stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3): Conv2d_fuse(
(convs): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): LeakyReLU(negative_slope=0.125, inplace=True)
)
)
(a_tracker3): AveragedRangeTracker()
(pool3): MaxPool2d(kernel_size=(2, 2), stride=2, padding=0, dilation=1, ceil_mode=False)
(conv4): Conv2d_fuse(
(convs): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): LeakyReLU(negative_slope=0.125, inplace=True)
)
)
(a_tracker4): AveragedRangeTracker()
(pool4): MaxPool2d(kernel_size=(2, 2), stride=2, padding=0, dilation=1, ceil_mode=False)
(conv5): Conv2d_fuse(
(convs): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): LeakyReLU(negative_slope=0.125, inplace=True)
)
)
(a_tracker5): AveragedRangeTracker()
(pool5): MaxPool2d(kernel_size=(2, 2), stride=2, padding=0, dilation=1, ceil_mode=False)
(conv6): Conv2d_fuse(
(convs): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): LeakyReLU(negative_slope=0.125, inplace=True)
)
)
(a_tracker6): AveragedRangeTracker()
(pool6): Sequential(
(0): ZeroPad2d(padding=(0, 1, 0, 1), value=0.0)
(1): MaxPool2d(kernel_size=(2, 2), stride=1, padding=0, dilation=1, ceil_mode=False)
)
(conv7): Conv2d_fuse(
(convs): Sequential(
(0): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): LeakyReLU(negative_slope=0.125, inplace=True)
)
)
(a_tracker7): AveragedRangeTracker()
(conv_set_2): Conv2d_fuse(
(convs): Sequential(
(0): Conv2d(1024, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): LeakyReLU(negative_slope=0.125, inplace=True)
)
)
(a_tracker8): AveragedRangeTracker()
(conv_1x1_2): Conv2d_fuse(
(convs): Sequential(
(0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(1): LeakyReLU(negative_slope=0.125, inplace=True)
)
)
(a_tracker9): AveragedRangeTracker()
(extra_conv_2): Conv2d_fuse(
(convs): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): LeakyReLU(negative_slope=0.125, inplace=True)
)
)
(a_tracker11): AveragedRangeTracker()
(pred_2): Conv2d(512, 75, kernel_size=(1, 1), stride=(1, 1))
(a_tracker12): AveragedRangeTracker()
(conv_set_1): Conv2d_fuse(
(convs): Sequential(
(0): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): LeakyReLU(negative_slope=0.125, inplace=True)
)
)
(a_tracker10): AveragedRangeTracker()
(pred_1): Conv2d(256, 75, kernel_size=(1, 1), stride=(1, 1))
(a_tracker13): AveragedRangeTracker()
)
输入的数据预处理:
归一化(0-1之间)、resize到416*416
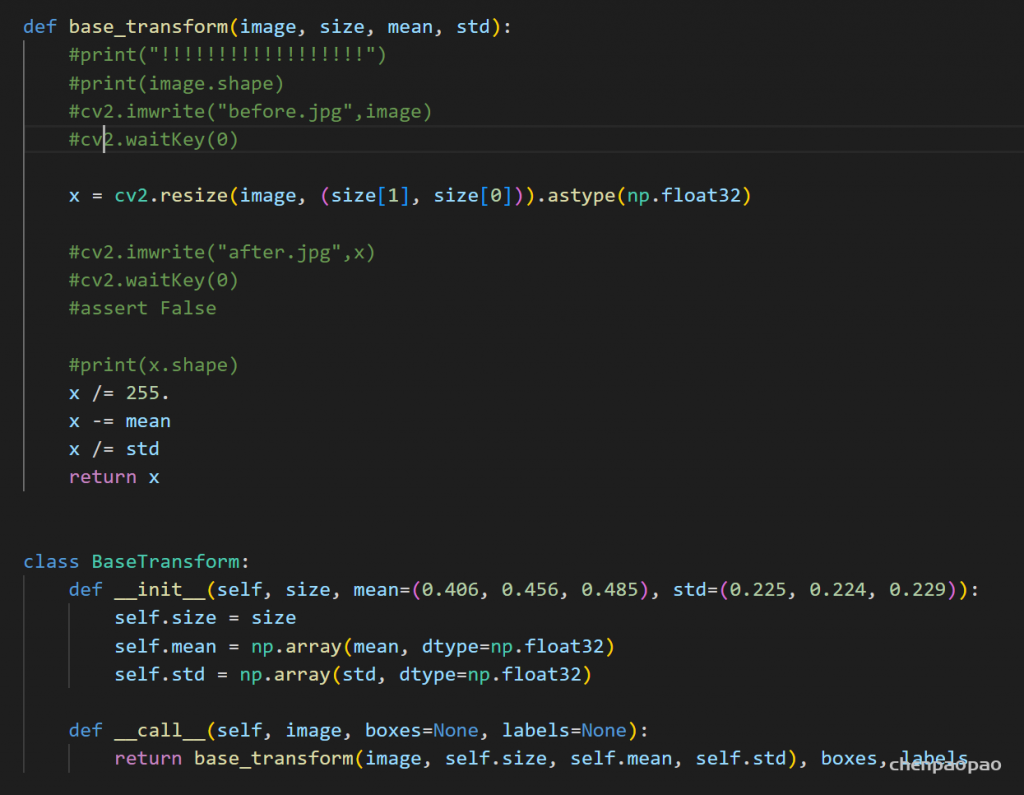
数据分布:
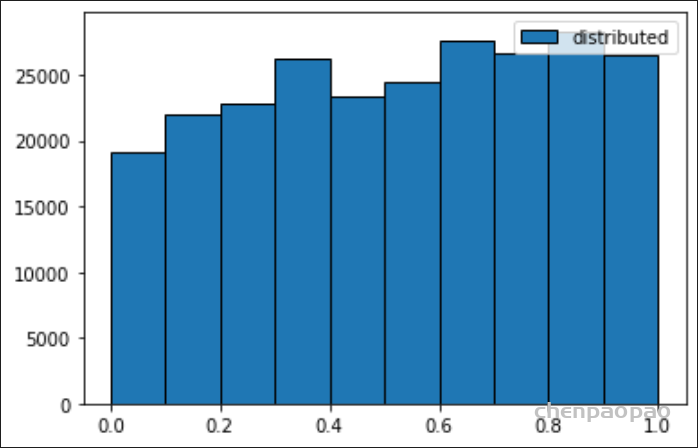
原始权重:
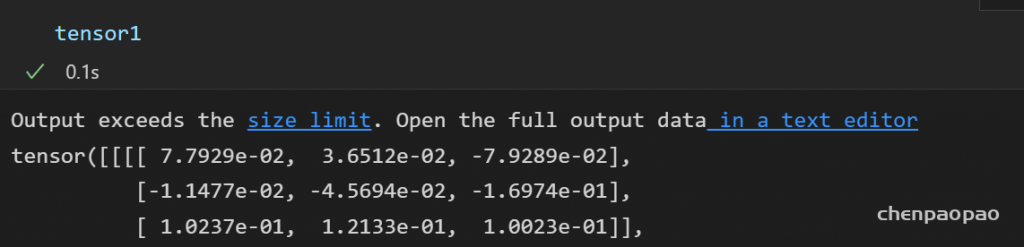
BN融合+微调+量化:
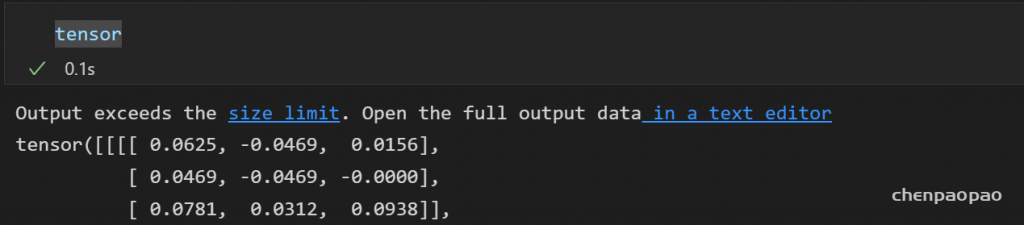
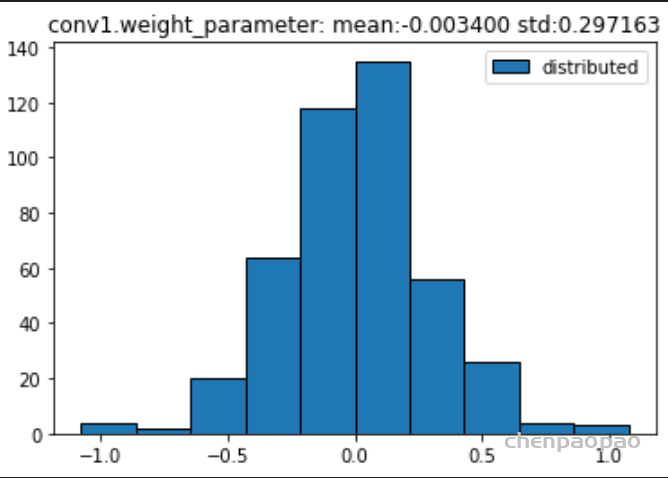
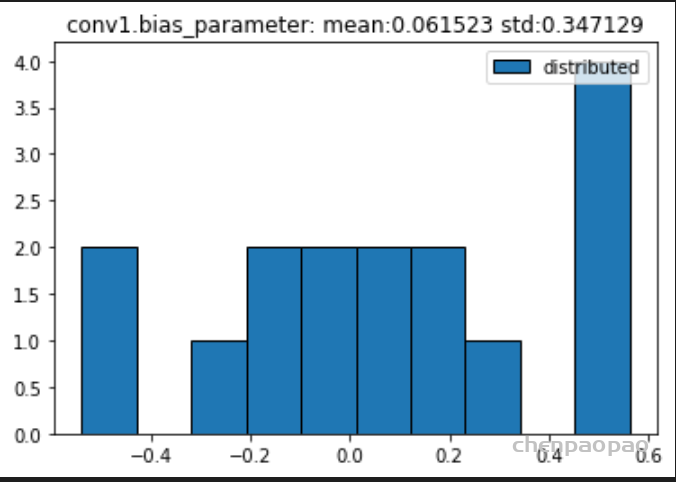
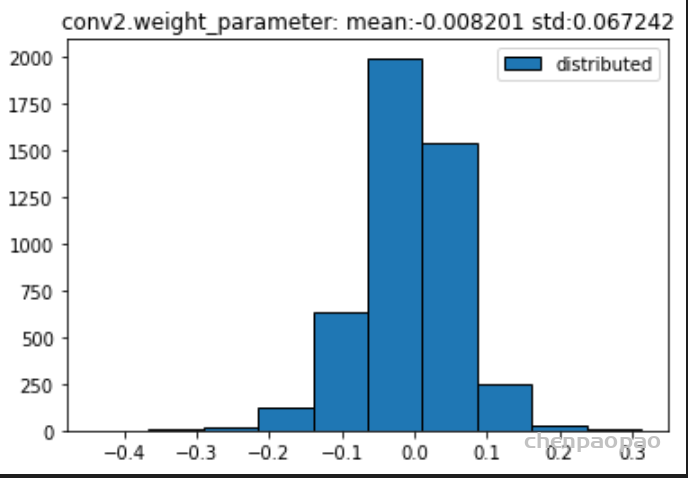
权重分布:
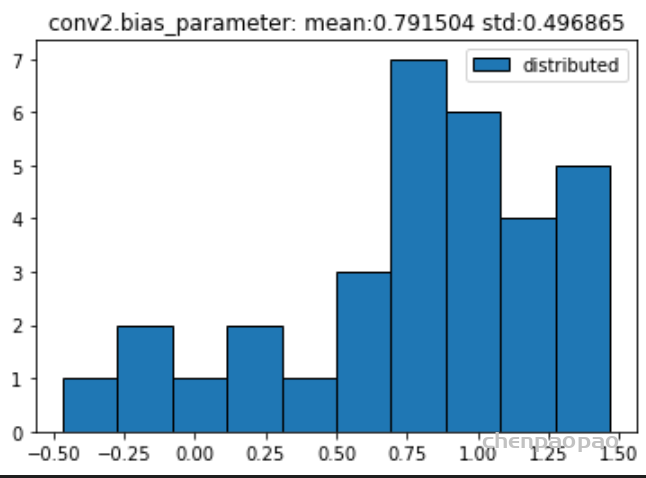
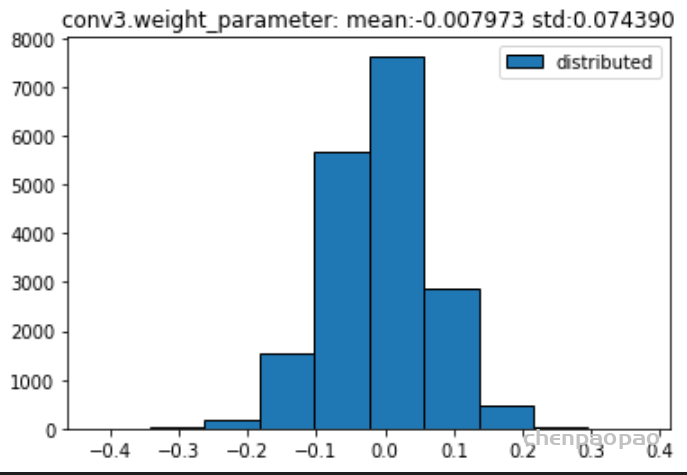
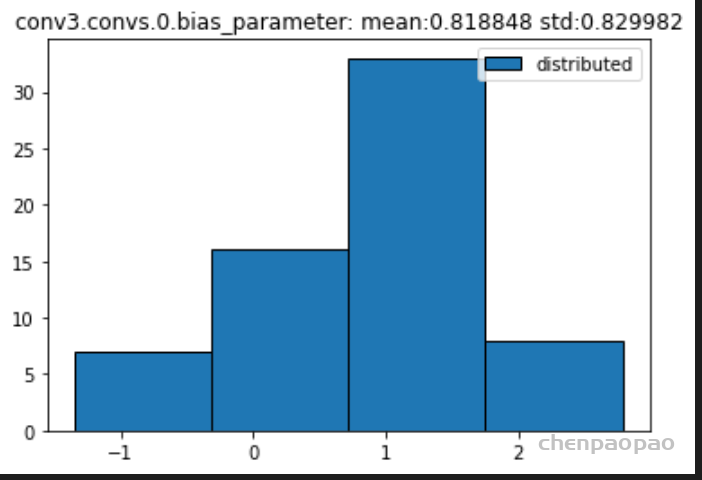
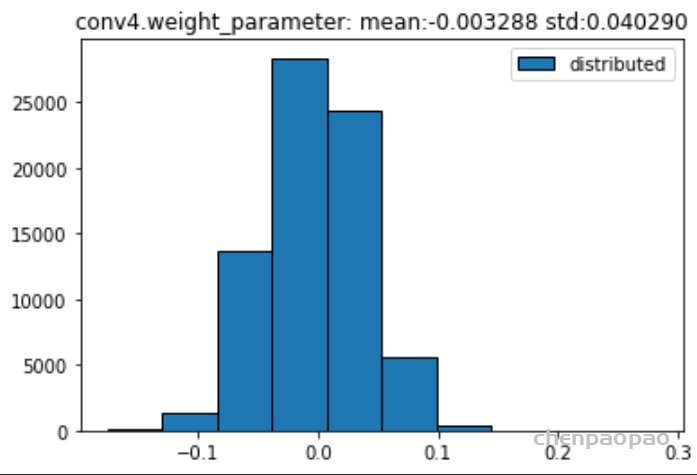
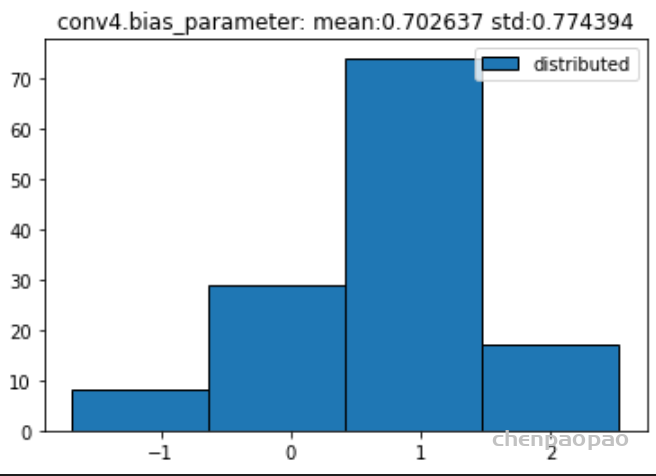
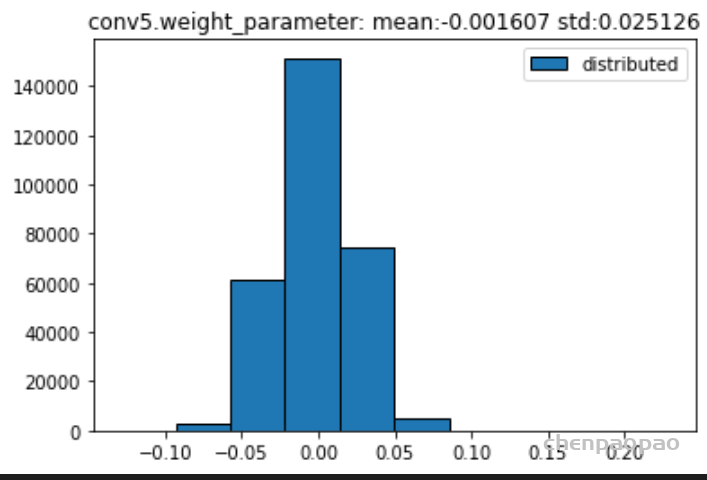
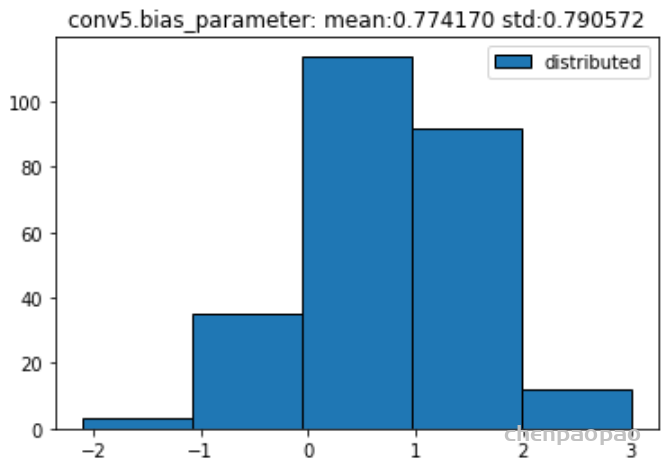
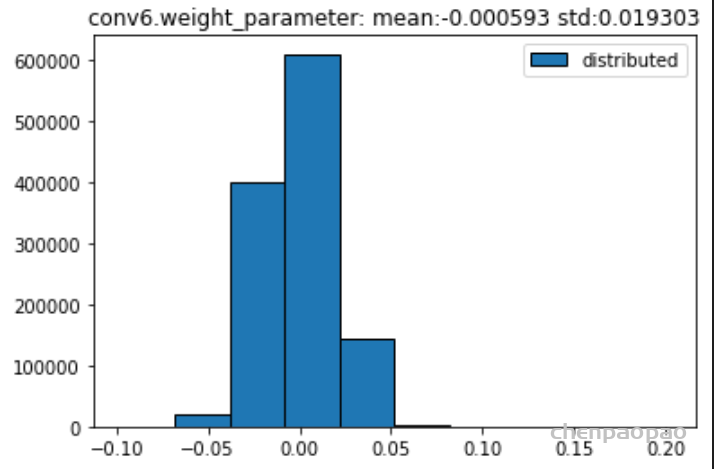
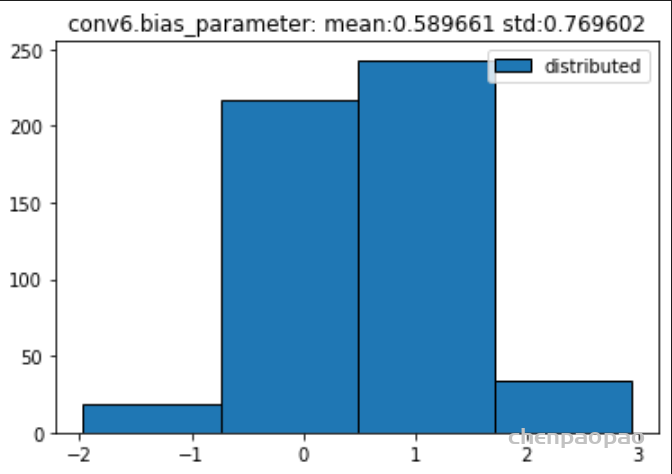
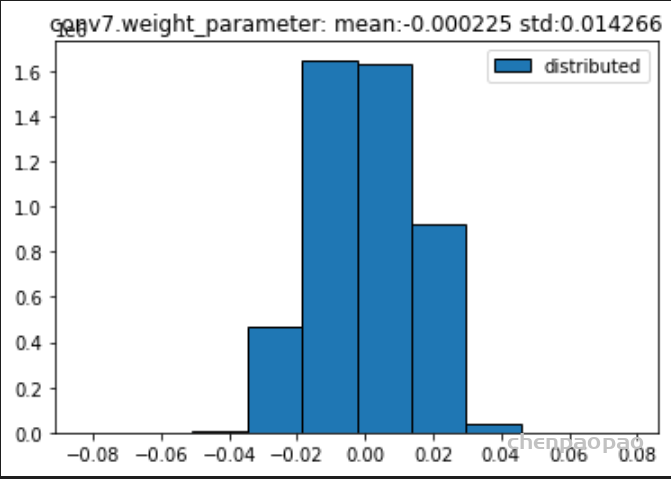
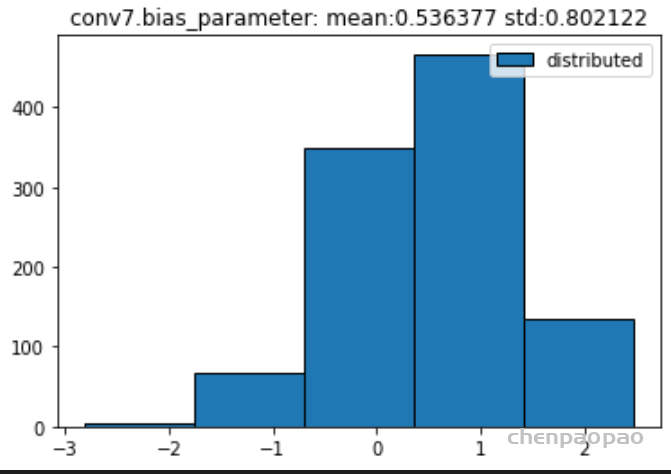
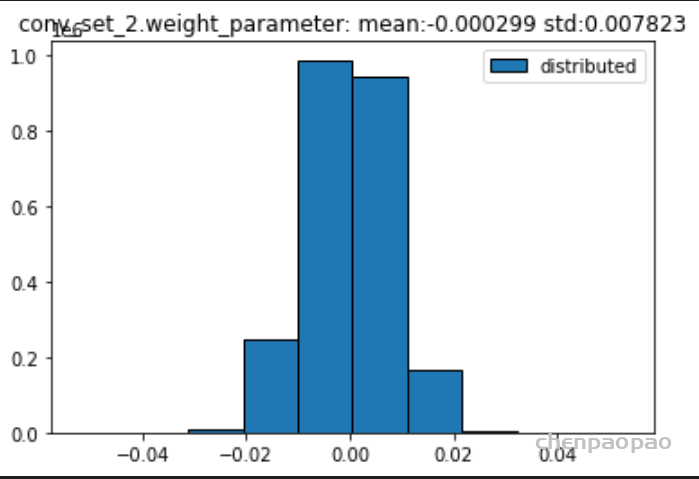
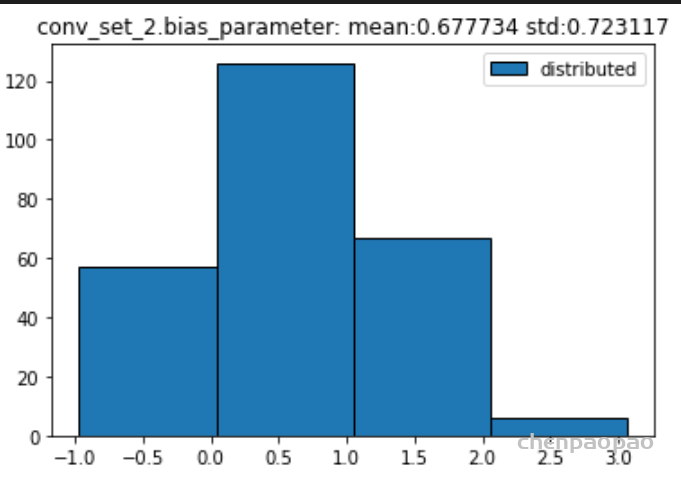
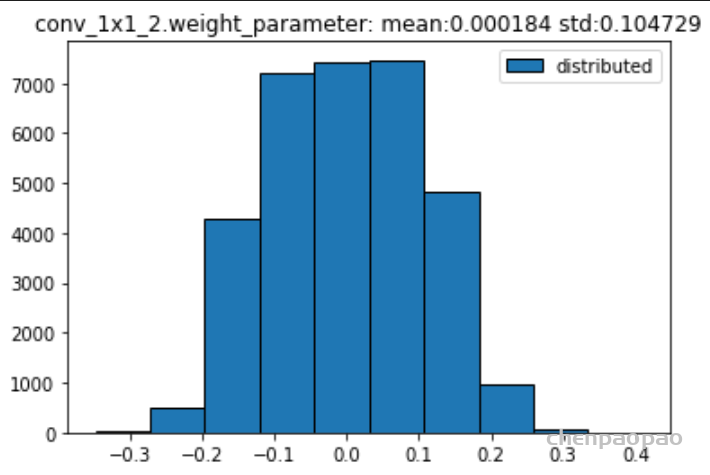
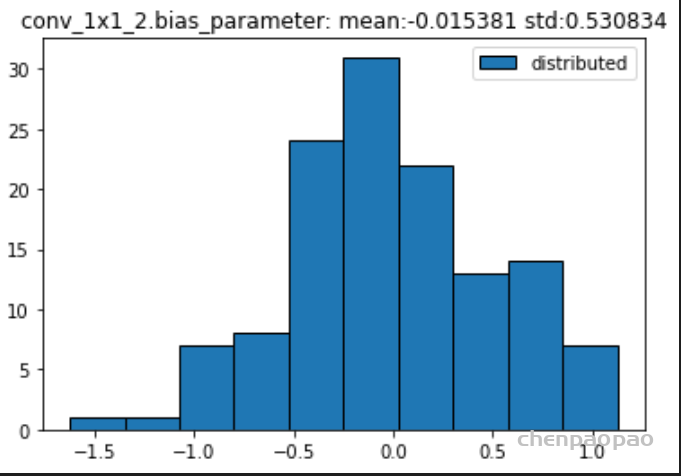
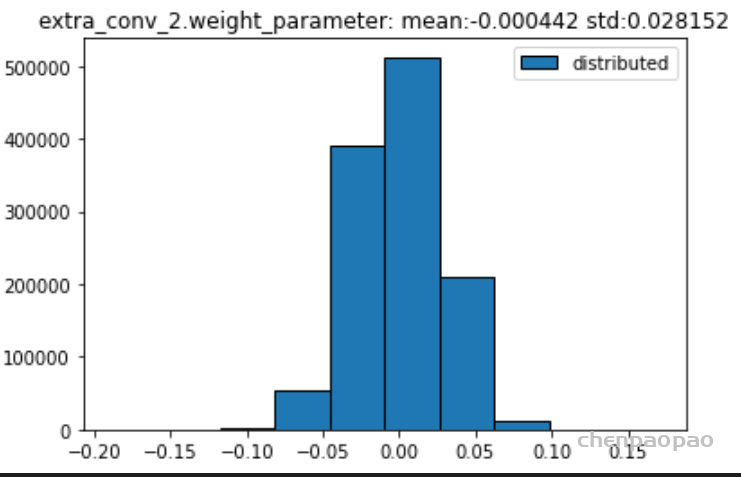

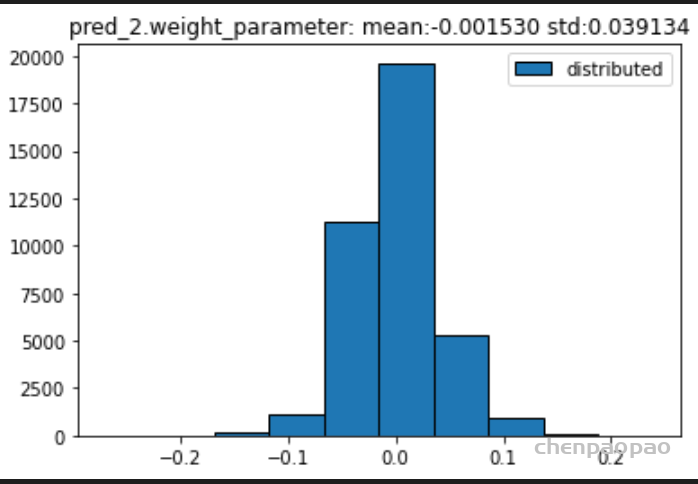
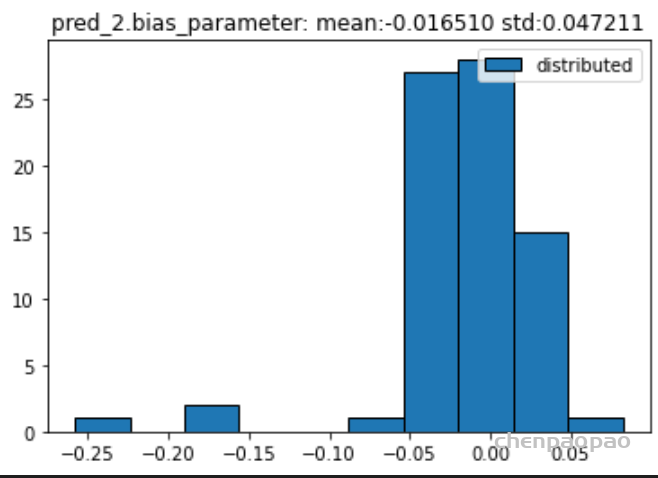
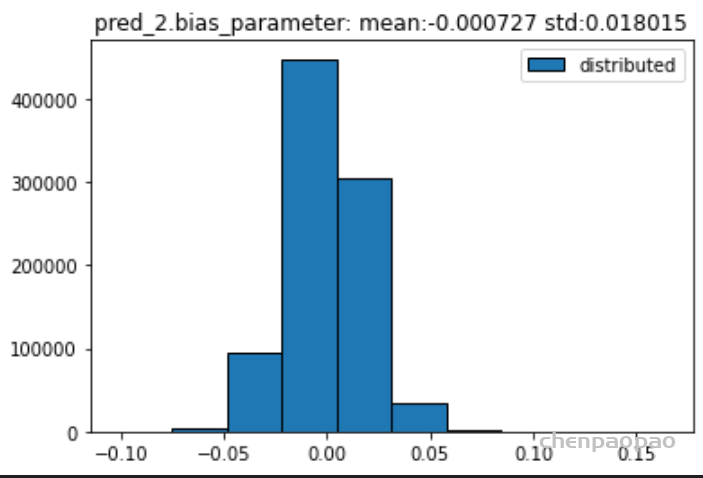
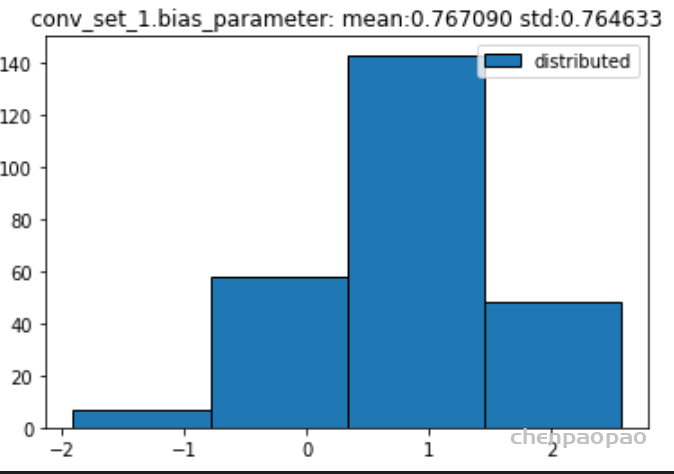
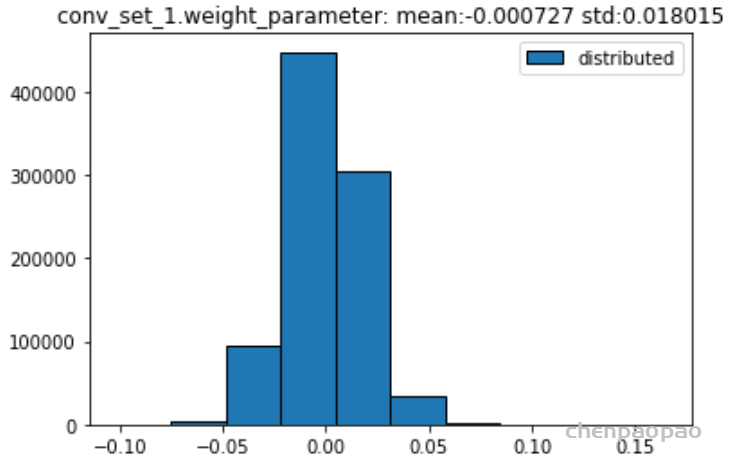
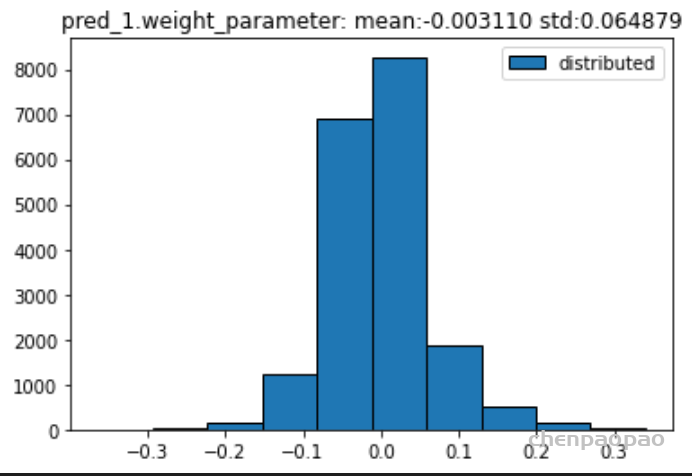
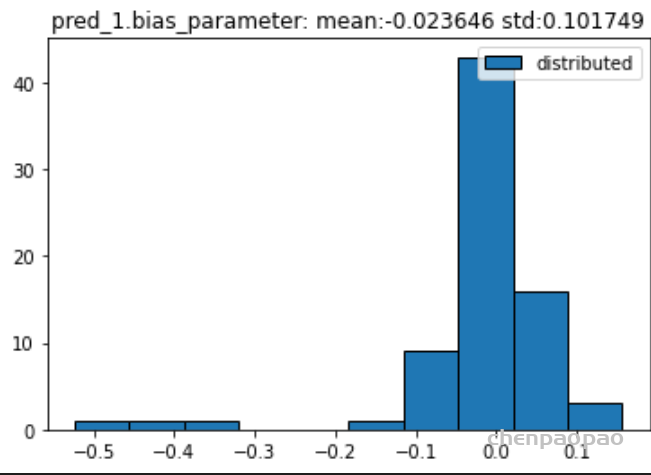
输入各层的分布:
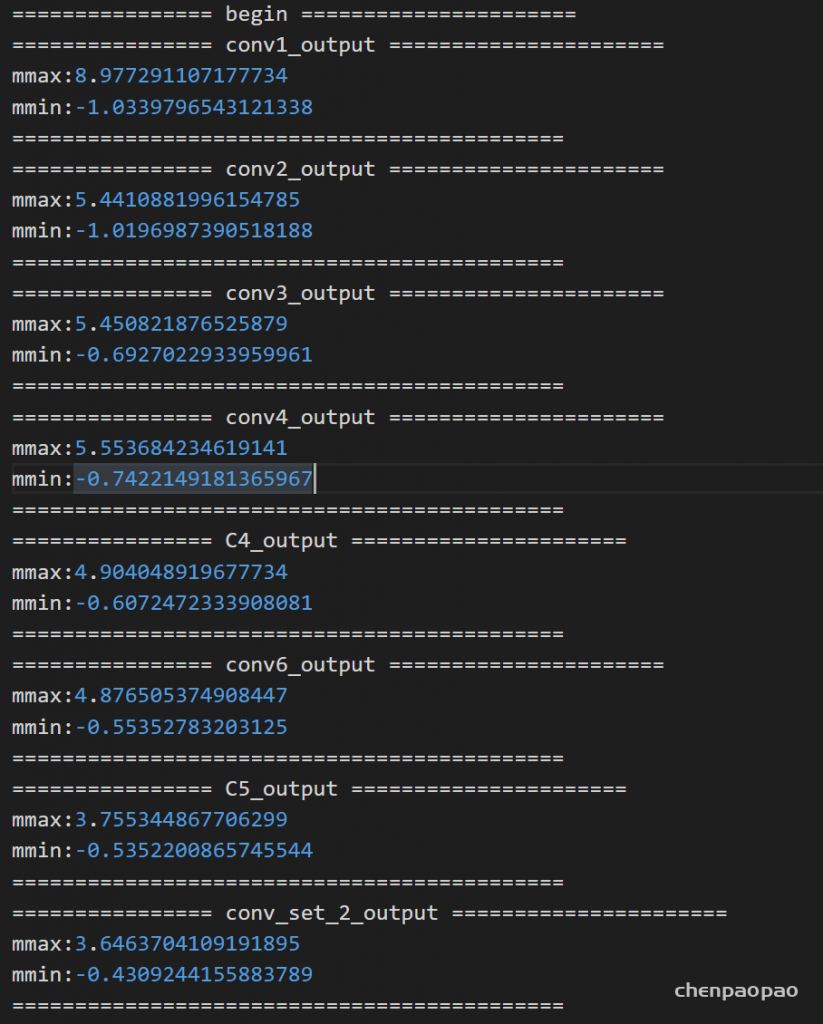
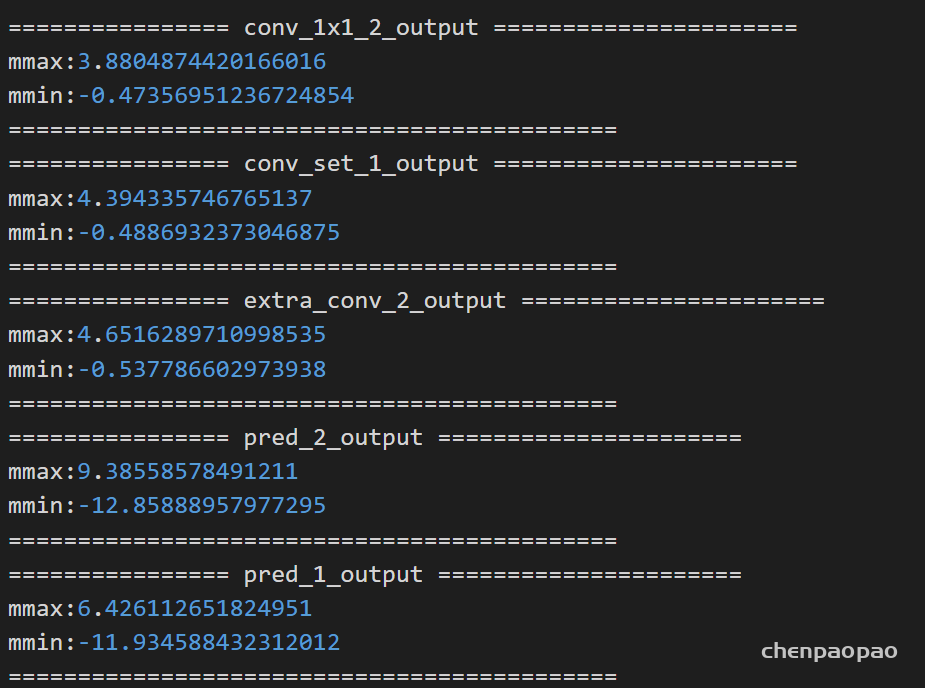
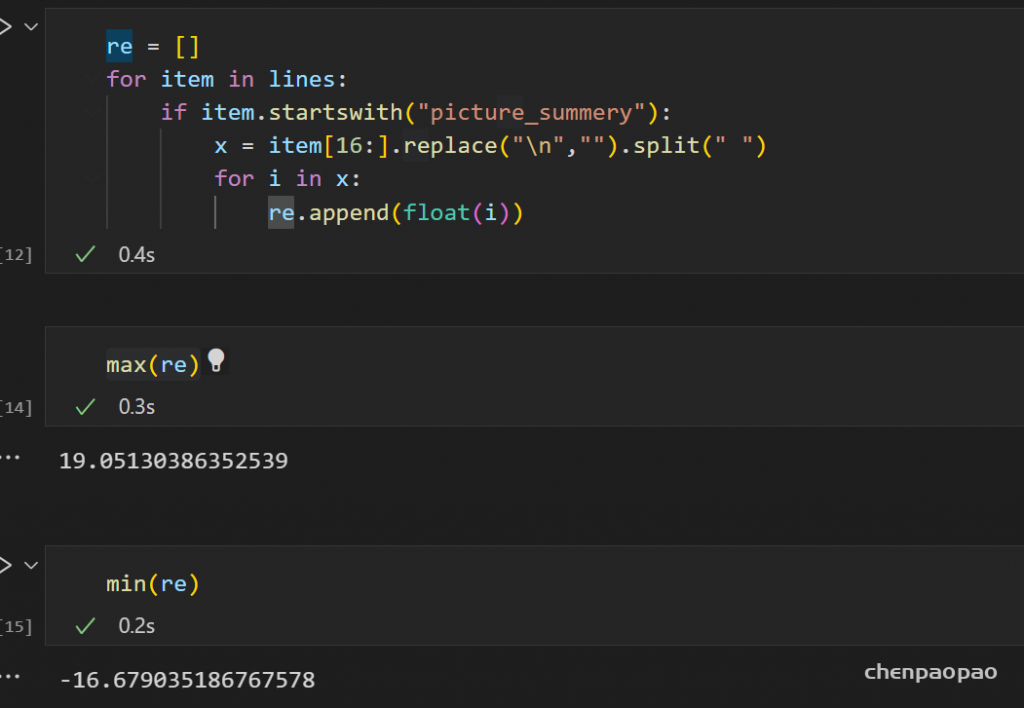
测试了100张图片:最大的输出19,最小的输出-16
根据硬件之前的测试结果反应:
以前的测试说明在输入-1–+1的数据范围内,权重-1到+1之间,16bit(7+8)情况下的error为0.01量级,因此我们使用以下函数模拟每层的扰动:
# 生成 -+0.05之间的随机数
pred_2 = pred_2 + 5*torch.rand(pred_2.shape).to(self.device)/100
我们每层的输出大概在-10+10范围内,权重再+1-1之间,因此上述假设是可行的。
最终生成的结果:


看一下log日志输出:
未加扰动输出:最终的累计扰动在0.1范围内

添加扰动(每一层)




再回到上次组会说的,为了验证 FPGA的具体计算过程中出现的问题,我们需要完全模拟硬件的卷积算法:即
1、需要将每层的输入输出数据进行16bit量化
2、需要对网络权重重新16bit量化,并写入
接下来进行修改:
1、对输入数据进行修改:
step1:对输入图片进行resize、标准化、转tensor等处理
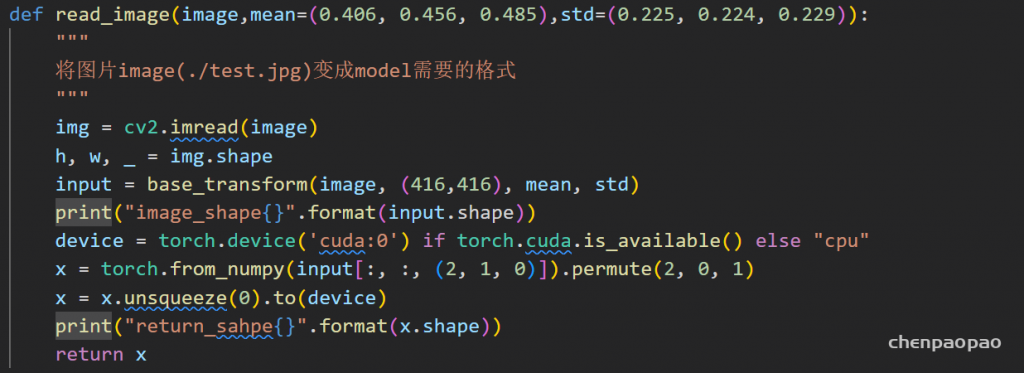
step2:对数据进行转化量化
转化 结果:


2、对权重进行修改
所有的权重:
这里对权重调整,并且要重新保存模型,注意因为之前统计过各层的权重分布,所以转换的时候不会出现数据的溢出
具体来说,就是先提取 pth的那个权重值,然后 使用函数转换为16bit所表示的数,再重新写入(注意写入顺序)
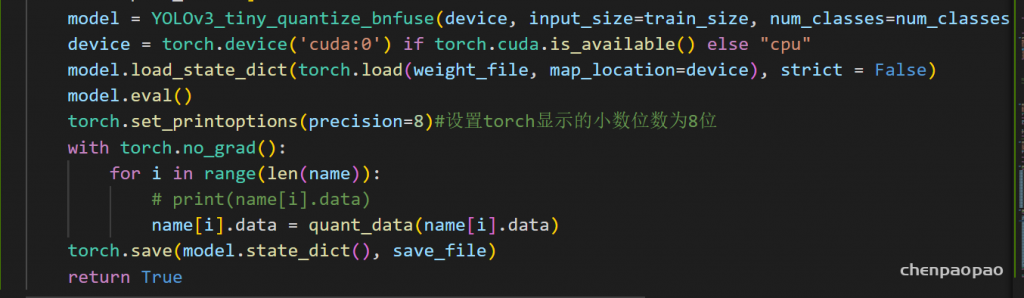
就是将下面的参数data,通过quant_data进行数据量化,最后save
16bit量化结果:(8bit小数情况:最大误差0.003量级)


接下来为了验证我们量化的正确性:
统计每一层的error误差范围
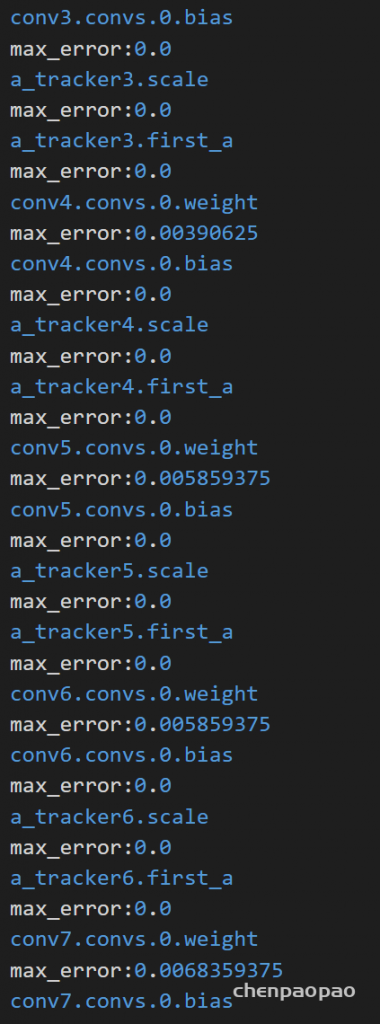
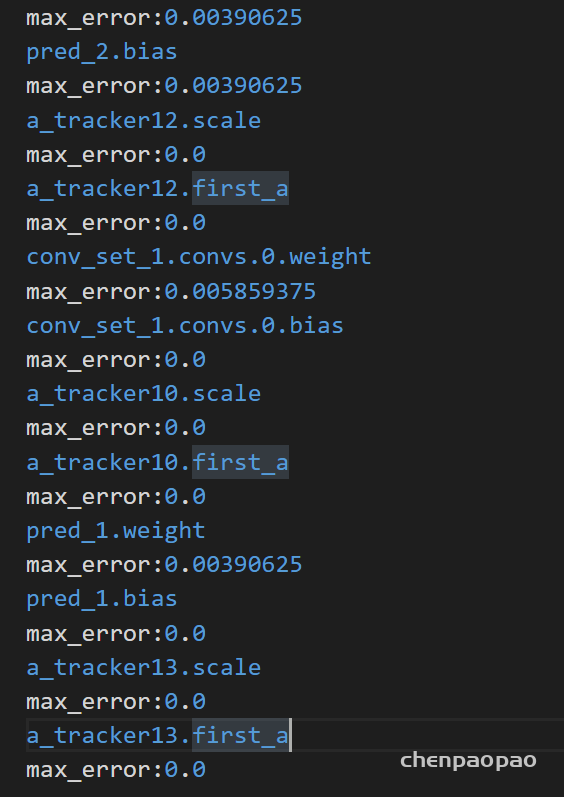
最终,将数据和权重量化完成和原始进行结果比较:




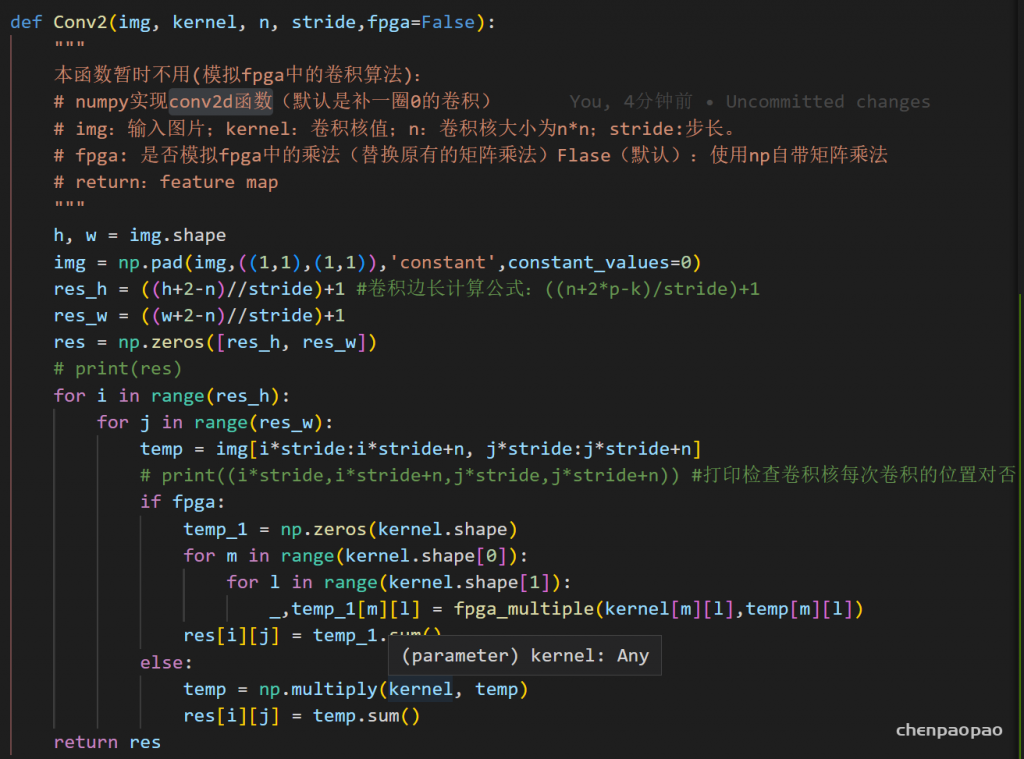
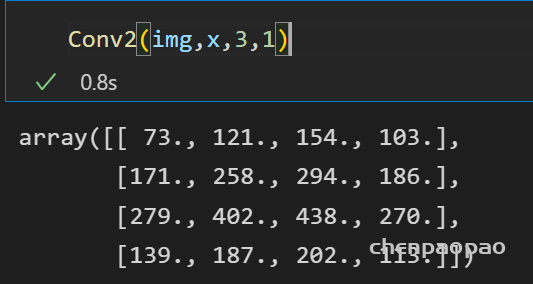
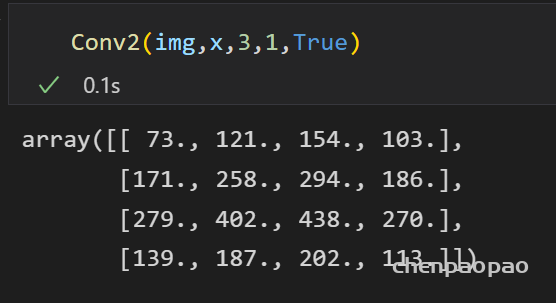
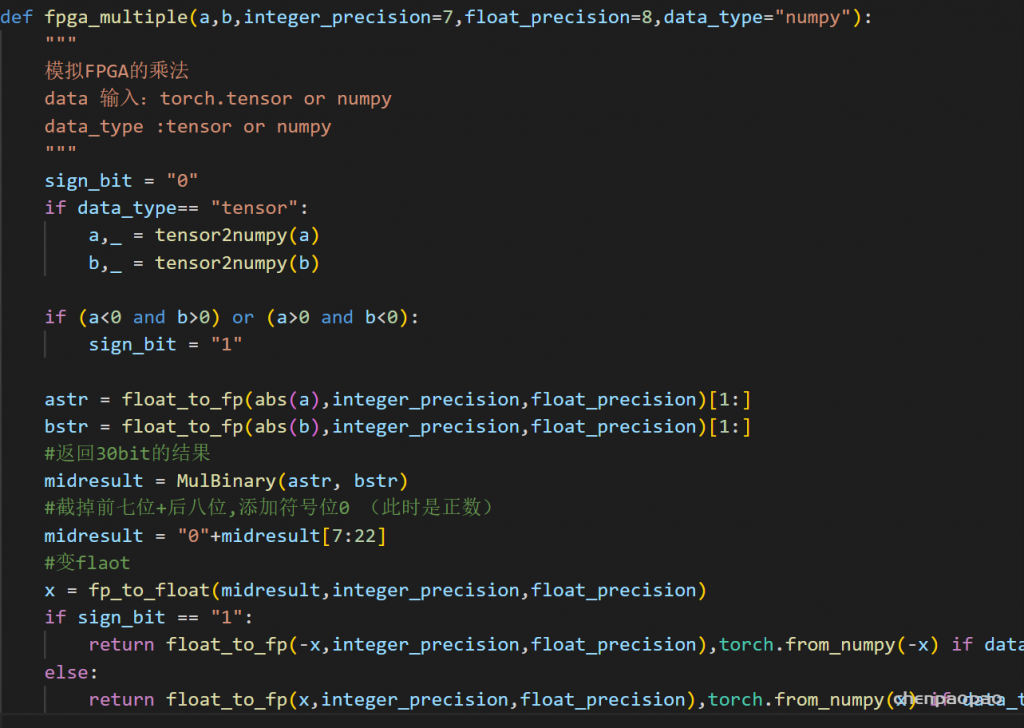
接下来来到最核心的:模拟fpga中的乘法,之前我么们无论是自己写的python辅助函数 or torch提供的卷积,都是使用现有的api,小数乘法。因此需要重写conv卷积函数,(关键是其中的乘法部分)
1、首先修改乘法
输入 0011011101
0011110111000011 * 0011110111000011 = 32bit
删去前8bit +最后8bit
实现很麻烦:
验证:1.1234*1.1234
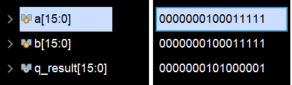
软件模拟fpga操作:
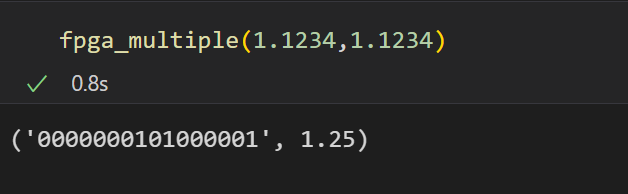

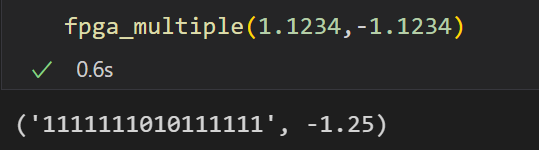
基础的乘法器已经完成了,下一步就是要替换掉卷积中的乘法运算,因为之前使用的conv函数是库自带的api,无法对其进行修改,因此需要手写一个conv2d的卷积函数: