
激活函数 fpga实现
激活函数是为了实现多层神经网络而引入的非线性函数,而不是最终得到线性函数。
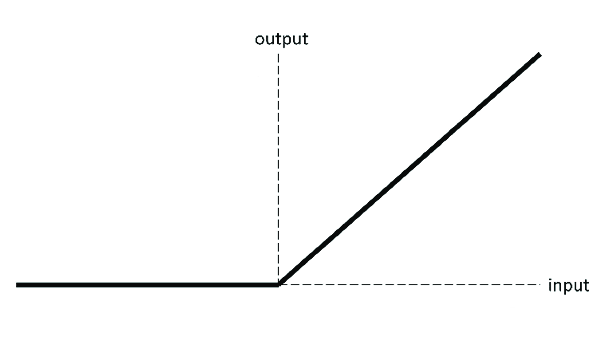
注意:由于 RELU 函数的输出根据输入的符号而有所不同,因此只有当我们开始使用有符号数字而不仅仅是整数时,它才能在硬件中实现。然而,正负的概念只是软件层面的一个数学概念。在硬件中,没有负数这样的东西。一切都只是一定位数的寄存器(在我们的例子中是 32 位)。但是,有符号二进制表示等概念允许我们在硬件中实现正数和负数的概念。当然,在实际硬件之上还需要另一层,以便解释这些数字的符号并根据需要使用它们。
在 Verilog 中实现 ReLu 函数
//file: relu.v
`timescale 1ns / 1ps
module relu(
input [31:0] din_relu,
output [31:0] dout_relu
);
assign dout_relu = (din_relu[31] == 0)? din_relu : 0; //if the sign bit is high, send zero on the output else send the input
endmodule

在 Verilog 中实现 leakrelu函数 (0.125)
`timescale 1ns / 1ps
module leakrelu(
input signed[31:0] din_relu,
output signed[31:0] dout_relu
);
parameter N = 0;//通过右移位实现除2的幂操作
assign dout_relu = (din_relu[31] == 0)? din_relu:din_relu>>>N; //if the sign bit is high, send zero on the output else send the input
endmodule


在 Verilog 中实现sigmod
https://blog.csdn.net/kebu12345678/article/details/81673111
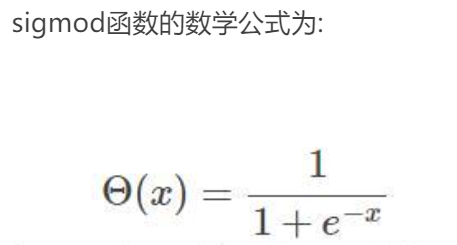
参考论文 :神经网络激活函数及其导数的FPGA实现 作者:张智明 张仁杰
采用折线斜率为2的次幂的分段线性逼近方法实现激活函数(sigmoid函数)及其导数的映射。该方法在FPGA实现时不需要使用硬件乘法器,而且可以节约大量的RAM单元。由于神经网络的并行计算需要消耗大量的硬件乘法器和RAM,因此,与其他方法相比,该方法为整个神经网络的FPGA实现有效地节省了大量宝贵的FPGA资源,可以较好地应用在BP神经网络的在线训练中。
//输入16位,最高位为符号位,整数占3位,小数占12位;输出16位,最高位为符号位,小数占15位
module sigmoid(clk,rst,a,b
);
input clk;
input rst;
input [15:0] a;
output[15:0] b;
reg[15:0] b;
reg[15:0] a_reg;
always@(posedge clk)
begin
if(rst)
b=0;
else
begin
if(a[15]==0)
begin
b[15:12]=4'b0000;
case(a[14:12])
3'b000:b[11:0]=12'b100000000000+(a[11:0]>>2);//加号的优先级大于移位运算的优先级,记得加括号
3'b001:b[11:0]=12'b110000000000+(a[11:0]>>3);
3'b010:b[11:0]=12'b111000000000+(a[11:0]>>4);
3'b011:b[11:0]=12'b111100000000+(a[11:0]>>5);
3'b100:b[11:0]=12'b111110000000+(a[11:0]>>6);
3'b101:b[11:0]=12'b111111000000+(a[11:0]>>7);
3'b110:b[11:0]=12'b111111100000+(a[11:0]>>8);
3'b111:b[11:0]=12'b111111110000+(a[11:0]>>9);
endcase
b=b<<3;//输入16位,最高位为符号位,整数占3位,小数占12位;输出16位,最高位为符号位,小数占15位
end
else
begin
a_reg=~a+1;//取a的绝对值
b[15:12]=4'b0000;
case(a_reg[14:12])
3'b000:b[11:0]=12'b100000000000+(a_reg[11:0]>>2);
3'b001:b[11:0]=12'b110000000000+(a_reg[11:0]>>3);
3'b010:b[11:0]=12'b111000000000+(a_reg[11:0]>>4);
3'b011:b[11:0]=12'b111100000000+(a_reg[11:0]>>5);
3'b100:b[11:0]=12'b111110000000+(a_reg[11:0]>>6);
3'b101:b[11:0]=12'b111111000000+(a_reg[11:0]>>7);
3'b110:b[11:0]=12'b111111100000+(a_reg[11:0]>>8);
3'b111:b[11:0]=12'b111111110000+(a_reg[11:0]>>9);
endcase
b=b<<3;//输入16位,最高位为符号位,整数占3位,小数占12位;输出16位,最高位为符号位,小数占15位
b[14:0]=~b[14:0]+1;//f(x)=1-f(-x)
end
end
end
endmodule
在 Verilog 中实现双曲正切
Tanh 是另一个非常流行和广泛使用的激活函数。它只是一个缩放的 sigmoid,并且具有一些非常有用的属性。这是这个函数的图:
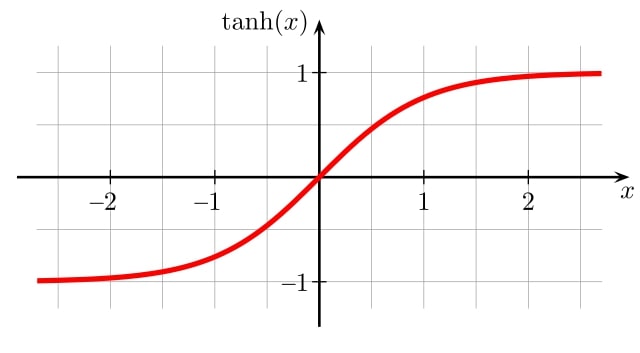
在硬件实现方面,我们可以通过多种方式实现这种非线性函数。例如:
- 简单查找表,恰好是实现一个功能的最简单、最快的方法,但在需要非常高的精度时也占用了大量资源。
- 带有插值的查找表,这也是一种基于查找表的方法,但使用一些额外的算术来改善结果,超出为查找表本身分配的精度。还有一些方法使用两个查找表,一个具有粗粒度值,另一个具有细粒度值,这些值被添加到初始近似值上。
- CORDIC,这是另一种非常流行的方法,广泛用于大多数需要非线性函数(如正弦、sqrt、tanh 等)的 DSP 应用程序中。这是一种非常优雅的方法,它使用基本的移位加法电路来实现非常好的结果。您可以阅读这篇文章以了解 CORDIC 的良好实现。大多数 FPGA 供应商还为 CORDIC 单元提供封装的 IP 块。
- 泰勒级数和多项式逼近,这些方法使用三角函数的传统多项式逼近,并尝试在这些多项式中实现高阶变量。
- DCT 插值和更复杂的方法,这些方法使用更专业的方法来实现所需的精确精度和资源使用。本文展示了一种这样的方法。
简单的表查找
- 对于这个实现,我们可以利用 Tanh 函数的对称性,即我们只需要存储与函数的正相关的值,并且由于负输入的函数输出只是镜像,我们可以输出相同的值以他们的 2 的补码格式。
- 我们可以轻松利用的另一个属性是 Tanh 函数在超过某个输入值后饱和到 1(或在另一侧为 -1)。在准确度没有任何显着损失的情况下,我们可以直接为高于阈值的输入输出 1(或 -1)。因此,我们不必将函数值存储在查找表中以查找高于阈值的输入。我使用输入值 3(或 -3)作为此阈值,因为tanh(3) = 0.9950547536867305 并且对于高于 3(或低于 -3)的所有输入,可以轻松地将输出视为 1(或 -1) .
- 对于这个实现,我使用了一个具有 1024 个位置的 RAM,每个位置都保存 16 位数据,以实现查找表。这意味着我们将有 10 个(= log2(1024))地址位来访问这个 ram。但是我们的相位输入将是一个 16 位的定点数。那么我们如何选择 10 个特定的位来寻址这个 ram?
以下是 tanh 函数的 (3,12) 格式的 16 位定点输入示例:
reg [15:0] phase = 16'b0_001_011000100101
在这,
- MSB ( phase[15] ) 是符号位,它将告诉我们是输出直接值还是 2 的补码形式。
- 接下来的三个 MSB 代表这个数字的整数部分。由于我们只关心幅度小于 3 的数字,如果第二个 MSB ( phase[14] ) 很高(对于一个正数),它告诉我们这个数字的幅度大于 3 并且我们可以直接输出 1 。否则,我们可以从表中输出值。
- 接下来的 10 个 MSB(阶段 [13:4])将用作查找表的输入。是的,我们将丢失 LSB(phase[3:0])中的信息,但如果我们也想使用它们,我们需要一个 16 倍大的查找表。只要我们的应用程序获得合理的准确性,我们就不必担心。再往下,我们将研究一种也利用这些 LSB 的技术。
`timescale 1ns / 1ps
module tanh_lut #(
parameter AW = 10, //AW will be based on the size of the ROM we can afford in our design.
//in the best case AW = N;
parameter DW = 16,
parameter N = 16,
parameter Q = 12
)(
input clk,
input [AW-1:0] phase,
output [DW-1:0] tanh
);
reg [AW-1:0] addr_reg;
(* ram_style = "block" *)reg [DW-1:0] mem [1<<AW-1:0]; //ram_style can be 'block' or 'distributed' // based on the utilization and other
//requirements in the project
initial
begin
$readmemb("tanh_data.mem",mem); //loading data into our RAM via a file
end
always@(posedge clk)
begin
addr_reg <= phase[AW-1:0];
end
assign tanh = mem[addr_reg];
具有线性插值的查找表
线性插值技术是数学中常用的技巧,用于在数据中没有足够的分辨率时改进值的近似值。即,当您想要两个连续数据点之间的离散函数的值时,您可以绘制一条连接这两个点的直线,并将您的输出近似为该线上的某个位置。这显着提高了我们函数的准确性。
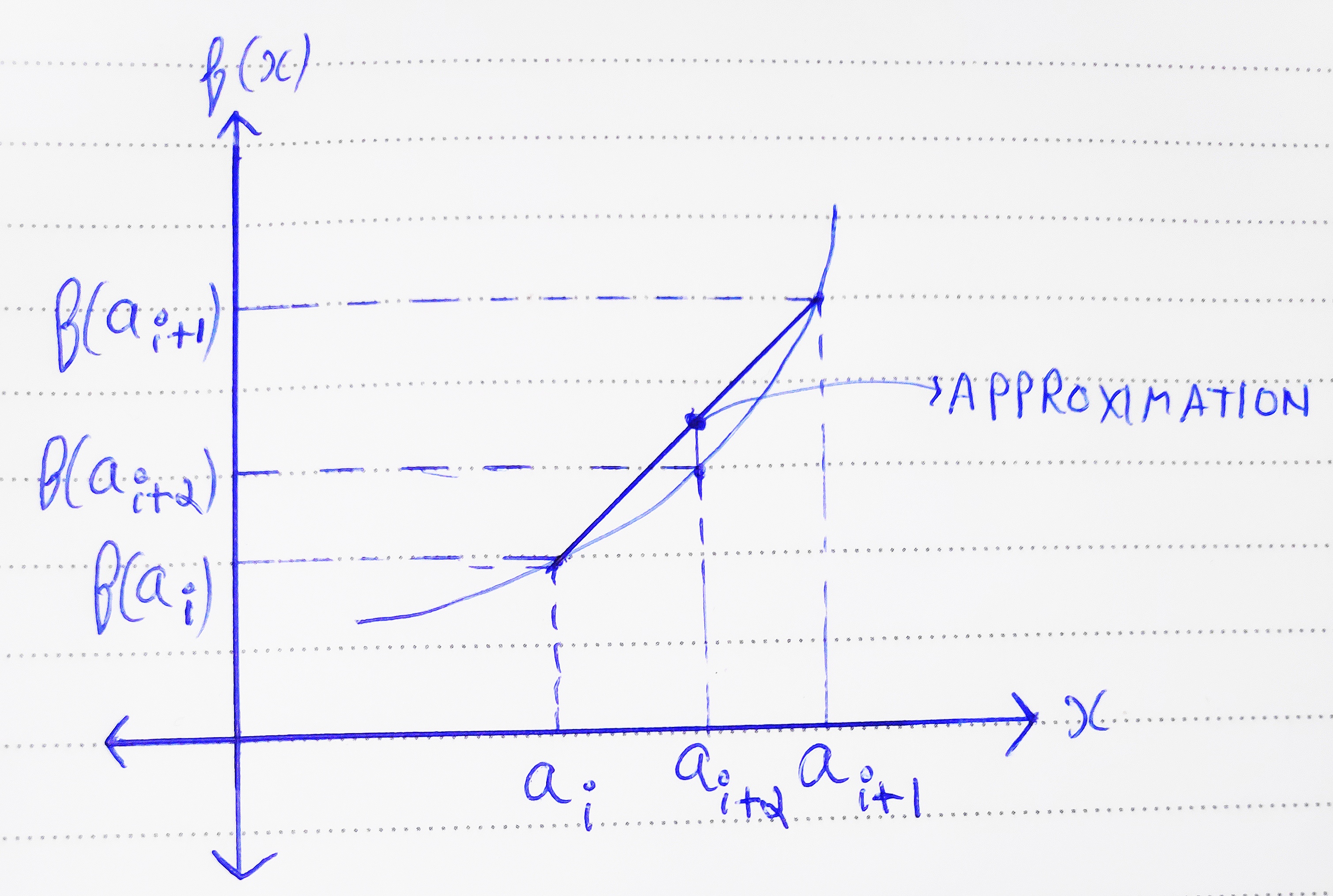
现在,为了解释这个想法,看看上面的图片。假设a i和a i+1是两个连续的点,我们知道函数 f(a i ) 和 f(a i+1 ) 的值。也就是说,在我们的例子中,这些是 RAM 中的两个条目,用于两个连续点的 Tanh 值。
假设我们要在a i+α点找到函数的值, 其中α是小于 1 的小数值。这告诉我们,我们需要两个已知点之间的 f(x) 值,因为我们没有关于这两个点之间曲线的实际形状的信息,一种近似的方法是假设两个已知点。通过使用基本的线性数学,我们可以找出对应于 x = a i+α的直线上的点的值。
你可以猜到,这个近似值是 f( a i ) + x( (f( a i+1 ) – a i )/1 ) = xf( a i ) + (1-x)f( a i+ 1 ) 产生的误差为 xf( a i ) + (1-x)f( a i+1 ) – f( a i+α )
这个结果将比查找表中的初始近似值相对更准确。在我们的例子中, α的值将来自在实际查找表中被忽略的剩余 4 个 LSB。下面是这种方法的代码:
注意:我正在为 16 位宽的数据路径编写代码。ie N = 16 如果您一直在阅读本系列的其他文章。但是,它可以非常参数化以使用任何位宽。
`timescale 1ns / 1ps
module tanh_lut #(
parameter AW = 10, //AW will be based on the size of the ROM we can afford in our design.
//in the best case AW = N;
parameter DW = 16,
parameter N = 16,
parameter Q = 12
)(
input clk,
input [N-1:0] phase,
output [DW-1:0] tanh
);
reg [9:0] addra_reg;
reg [9:0] addrb_reg;
wire [15:0] tanha;
wire [15:0] tanhb;
wire ovr1,ovr2;
wire [15:0] frac,one_minus_frac;
wire [15:0] A1,A2;
wire [15:0] one;
wire [DW-1:0] tanh_temp;
(* ram_style = "block" *)reg [15:0] mem [1<<10-1:0]; //ram_style can be 'block' or 'distributed' based on the
//utilization and other requirements in the project
initial
begin
$readmemb("tanh_data.mem",mem); //loading our RAM via a file
end
always@(posedge clk)
begin
addra_reg <= phase[9:0];
addrb_reg <= phase[9:0] + 1'b1;
end
assign tanha = mem[addra_reg];
assign tanhb = mem[addrb_reg];
assign frac = {'d0,phase[N-AW-'d2-1:0]}; //rest of the LSBs that were not accounted for owing to the limited ROM size
assign one = 16'b0001000000000000; //'d1 in (N,Q) = (3,12) format
assign one_minus_frac = one - frac;
//qmult is the fixed point multiplier module, visit the fixed point arithmetic
//article further in the series to learn of its exact operation
qmult #(N,Q) mul1 (tanha,frac,A1,ovr1); //calculates x*f(Ai)
qmult #(N,Q) mul2 (tanhb,one_minus_frac,A2,ovr2); //calculates (1-x)*f(Ai+1)
assign tanh_temp = A1 + A2; // linear interpolation formula: x*Ai + (1-x)*Ai+1
//now, if the phase input is above 3 or below -3 then we just output 1, otherwise we output the calculated value
//we also check for the sign, if the phase is negative, we return 2's complemented version of the calculated value
assign tanh = (phase [N-1]) ? (phase[N-2] ? (16'b1111000000000000) : (~tanh_temp + 1'b1)) :(phase[N-2] ? (16'b0001000000000000):(tanh_temp));
endmodule