
———– ConvMixer 网络
论文地址:https://openreview.net/pdf?id=TVHS5Y4dNvM
Github 地址:https://github.com/tmp-iclr/convmixer
ConvMixer is now integrated into the timm framework itself. You can see the PR here.
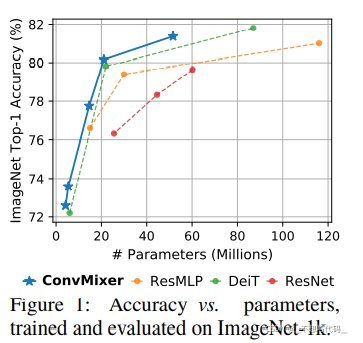
Conv Mixer 这篇文章提出的初衷是想去弄清楚,ViT系列模型表现优越,到底是图片分块的功劳 还是网络中Attention的功劳。于是作者就根据深度可分离卷积,在ViT 和 MLP Mixer 的启发中 设计了Conv Mixer。并且在表现上超越了一些ViT (某些ViT结构),MLP Mixer 和 ResNet。文章本身并没去追求模型的速度,和表现能力。

网络结构详解:
1、 Patch embedding
这里的Patch embedding实际上是使用一个卷积层 实现的
nn.Conv2d(3,dim,kernel_size=patch_size,stride=patch_size)
其中 kernel_size 就是patch的大小
2、GELU激活函数(高斯误差线性单元)
这个是最近很多模型都在用的函数(dert、高斯误差线性单元激活函数在最近的 Transformer 模型)GELUs正是在激活中引入了随机正则的思想,是一种对神经元输入的概率描述,直观上更符合自然的认识,同时实验效果要比Relus与ELUs都要好。
GELUs其实是 dropout、zoneout、Relus的综合,GELUs对于输入乘以一个0,1组成的mask,而该mask的生成则是依概率随机的依赖于输入。假设输入为X, mask为m,则m服从一个伯努利分布(Φ ( x ) \Phi(x)Φ(x), Φ ( x ) = P ( X < = x ) , X 服 从 标 准 正 太 分 布 \Phi(x)=P(X<=x), X服从标准正太分布Φ(x)=P(X<=x),X服从标准正太分布),这么选择是因为神经元的输入趋向于正太分布,这么设定使得当输入x减小的时候,输入会有一个更高的概率被dropout掉,这样的激活变换就会随机依赖于输入了。
看得出来,这就是某些函数(比如双曲正切函数 tanh)与近似数值的组合。没什么过多可说的。有意思的是这个函数的图形:
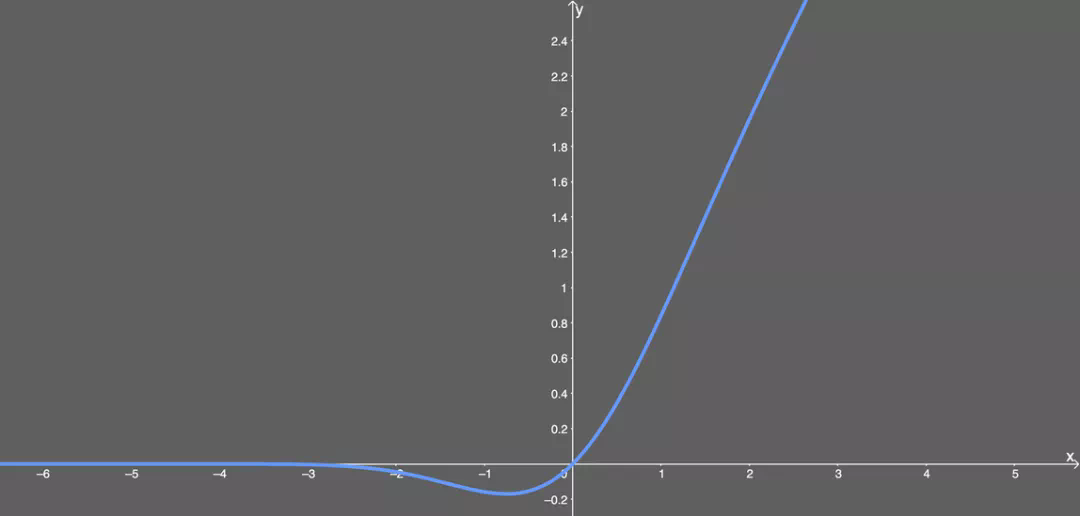
可以看出,当 x 大于 0 时,输出为 x;但 x=0 到 x=1 的区间除外,这时曲线更偏向于 y 轴。
优点:
- 似乎是 NLP 领域的当前最佳;尤其在 Transformer 模型中表现最好;
- 能避免梯度消失问题。
3、ConvMixerLayer
class ConvMixerLayer(nn.Module):
def __init__(self,dim,kernel_size = 9):
super().__init__()
#残差结构
self.Resnet = nn.Sequential(
nn.Conv2d(dim,dim,kernel_size=kernel_size,groups=dim,padding='same'),
nn.GELU(),
nn.BatchNorm2d(dim)
)
#逐点卷积
self.Conv_1x1 = nn.Sequential(
nn.Conv2d(dim,dim,kernel_size=1),
nn.GELU(),
nn.BatchNorm2d(dim)
)
def forward(self,x):
x = x +self.Resnet(x)
x = self.Conv_1x1(x)
return 在ConvMixer Layer 中, 使用了深度可分离卷积,GELU 激活函数,逐点卷积。
论文中将图中红色部 称为 “channel wise mixing” 蓝色部分称为 “spatial mixing”
论文得到的结论是当深度可分离卷积部分的卷积核越大,模型的性能越好。文章中的使用的是9×9的卷积核,因为卷积核越大表现越好。
文章最后也认为,ViT 表现如此优越 是因为patch embedding (图片分块)的原因。
作者认为 patch embedding 操作就能完成神经网络的所有下采样过程,降低了图片的分辨率,增加了感受野,更容易找到远处的空间信息。从而模型表现良好