
论文下载地址:https://arxiv.org/abs/2101.03697
官方源码(Pytorch实现):https://github.com/DingXiaoH/RepVGG
这篇论文对于我来说最大的用处是提出了结构的重重参数化:
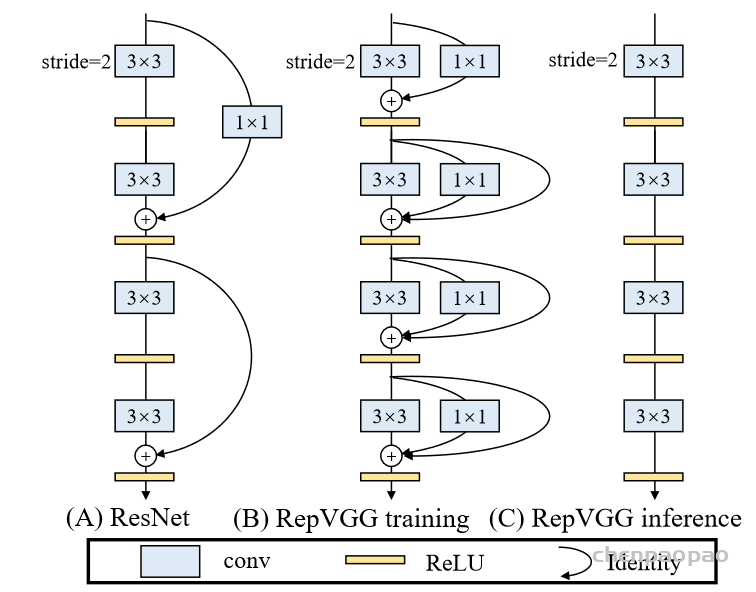
在推理时将三个并行分支合并成单个分支,并保证输出输出不变。
结构重参数化主要分为两步,第一步主要是将Conv2d算子和BN算子融合以及将只有BN的分支转换成一个Conv2d算子,第二步将每个分支上的3x3卷积层融合成一个卷积层。
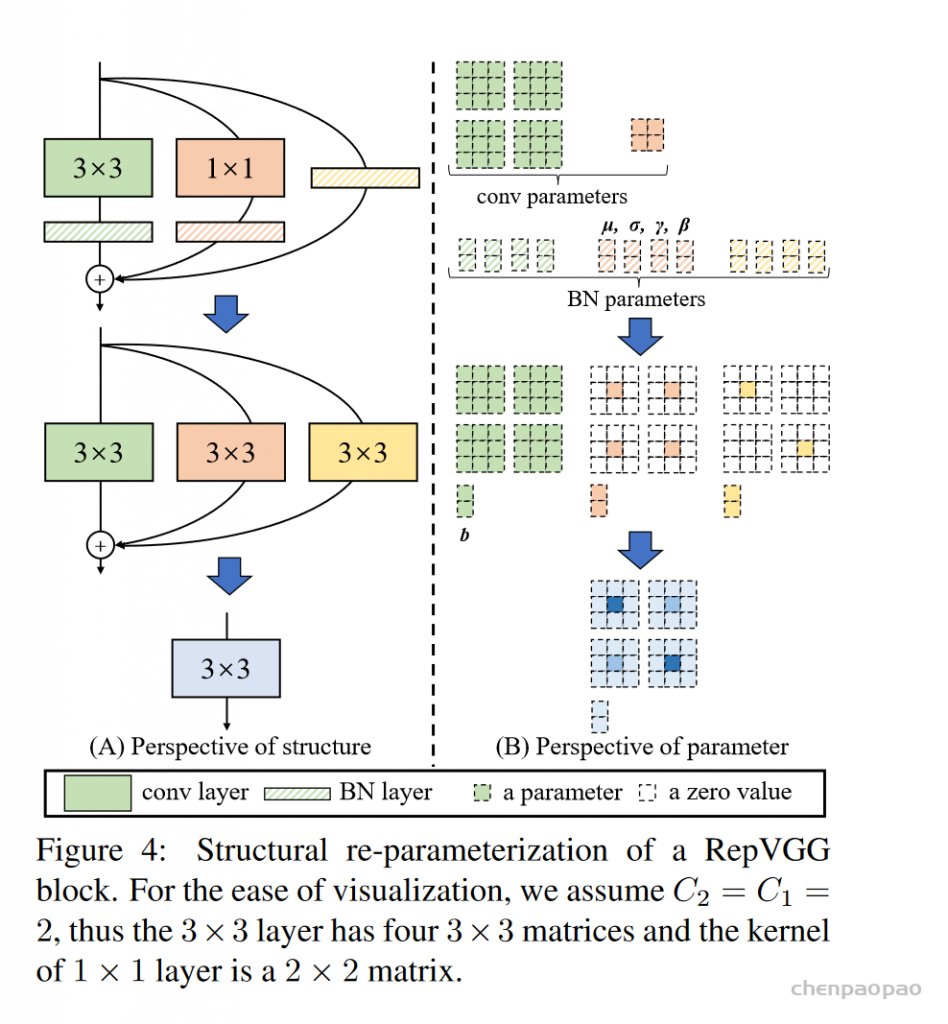
1、Conv2d和BN 这个已经是非常常见的,因为卷积核bn都是线性运算,所以可以进行合并。
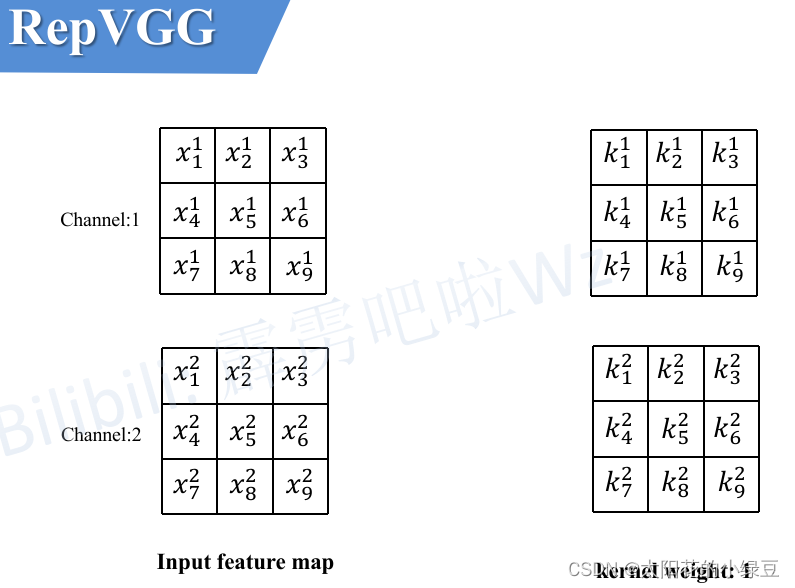
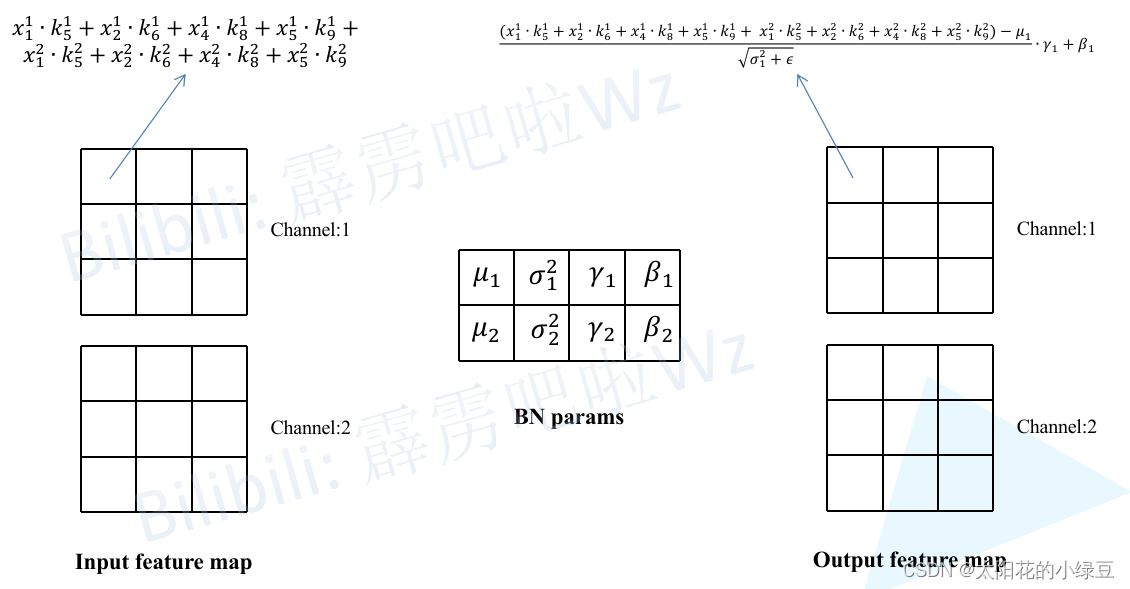
这里假设输入的特征图(Input feature map)如下图所示,输入通道数为2,然后采用两个卷积核(图中只画了第一个卷积核对应参数)。
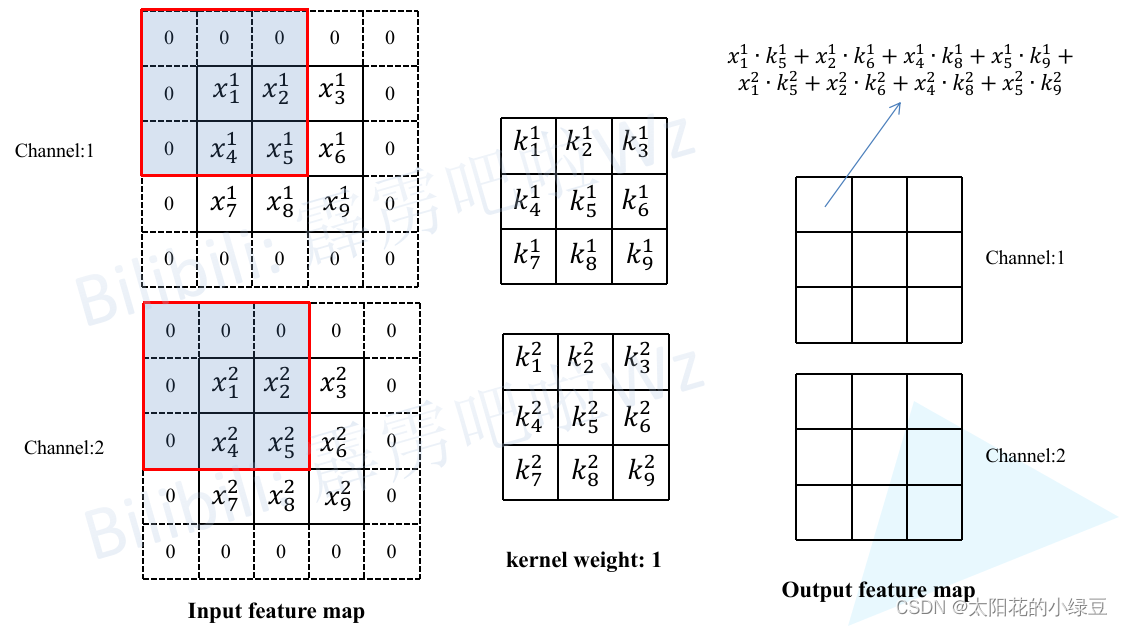
接着计算一下输出特征图(Output feature map)通道1上的第一个元素,即当卷积核1在输入特征图红色框区域卷积时得到的值(为了保证输入输出特征图高宽不变,所以对Input feature map进行了Padding)。其他位置的计算过程类似这里就不去演示了。
然后再将卷积层输出的特征图作为BN层的输入,这里同样计算一下输出特征图(Output feature map)通道1上的第一个元素,按照上述BN在推理时的计算公式即可得到如下图所示的计算结果。

代码
Conv2d+BN融合实验(Pytorch)
下面是参考作者提供的源码改的一个小实验,首先创建了一个module包含了卷积和BN模块,然后按照上述转换公式将卷积层的权重和BN的权重进行融合转换,接着载入到新建的卷积模块fused_conv中,最后随机创建一个Tensor(f1)将它分别输入到module以及fused_conv中,通过对比两者的输出可以发现它们的结果是一致的。
from collections import OrderedDict
import numpy as np
import torch
import torch.nn as nn
def main():
torch.random.manual_seed(0)
f1 = torch.randn(1, 2, 3, 3)
module = nn.Sequential(OrderedDict(
conv=nn.Conv2d(in_channels=2, out_channels=2, kernel_size=3, stride=1, padding=1, bias=False),
bn=nn.BatchNorm2d(num_features=2)
))
module.eval()
with torch.no_grad():
output1 = module(f1)
print(output1)
# fuse conv + bn
kernel = module.conv.weight
running_mean = module.bn.running_mean
running_var = module.bn.running_var
gamma = module.bn.weight
beta = module.bn.bias
eps = module.bn.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1) # [ch] -> [ch, 1, 1, 1]
kernel = kernel * t
bias = beta - running_mean * gamma / std
fused_conv = nn.Conv2d(in_channels=2, out_channels=2, kernel_size=3, stride=1, padding=1, bias=True)
fused_conv.load_state_dict(OrderedDict(weight=kernel, bias=bias))
with torch.no_grad():
output2 = fused_conv(f1)
print(output2)
np.testing.assert_allclose(output1.numpy(), output2.numpy(), rtol=1e-03, atol=1e-05)
print("convert module has been tested, and the result looks good!")
if __name__ == '__main__':
main()
repVGG中大量运用conv+BN层,我们知道将层合并,减少层数能提升网络性能,下面的推理是conv带有bias的过程:

这其实就是一个卷积层,只不过权重考虑了BN的参数 我们令:
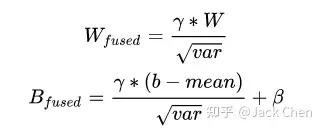
最终的融合结果即为:
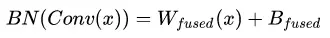
相关融合代码如下图所示:
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
...
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std2、如何将不同分支合并:
作者这里首先将不同分支的卷积核都变成3*3:
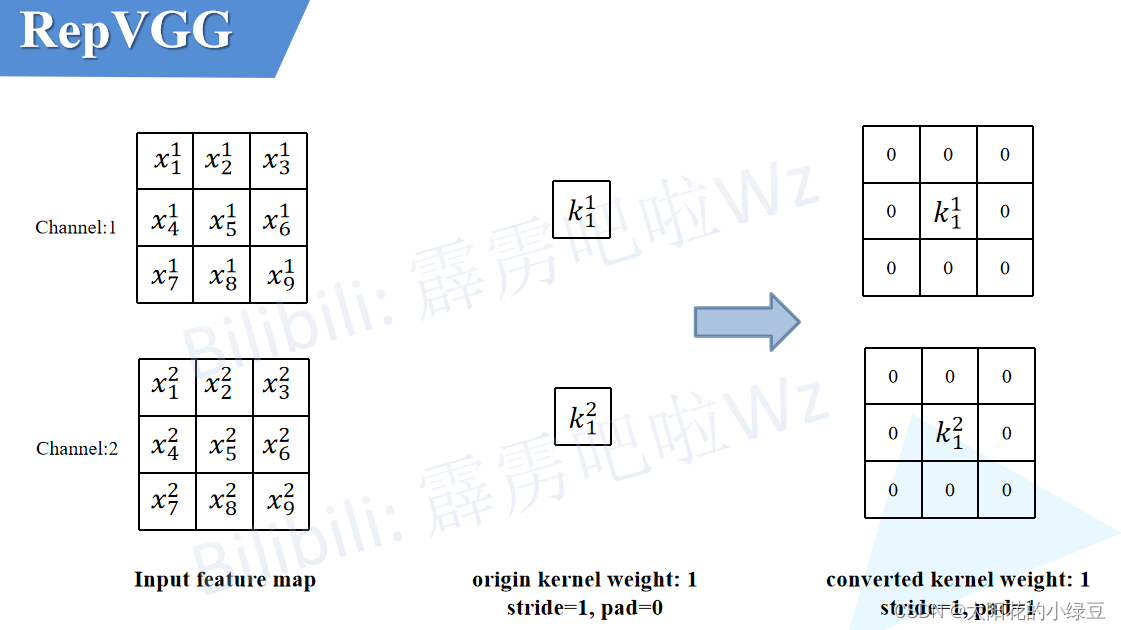
2.1 将1×1卷积转换成3×3卷积
这个过程比较简单,如下图所示,以1×1卷积层中某一个卷积核为例,只需在原来权重周围补一圈零就行了,这样就变成了3×3的卷积层,注意为了保证输入输出特征图高宽不变,此时需要将padding设置成1(原来卷积核大小为1×1时padding为0)。最后按照上述2.1中讲的内容将卷积层和BN层进行融合即可。
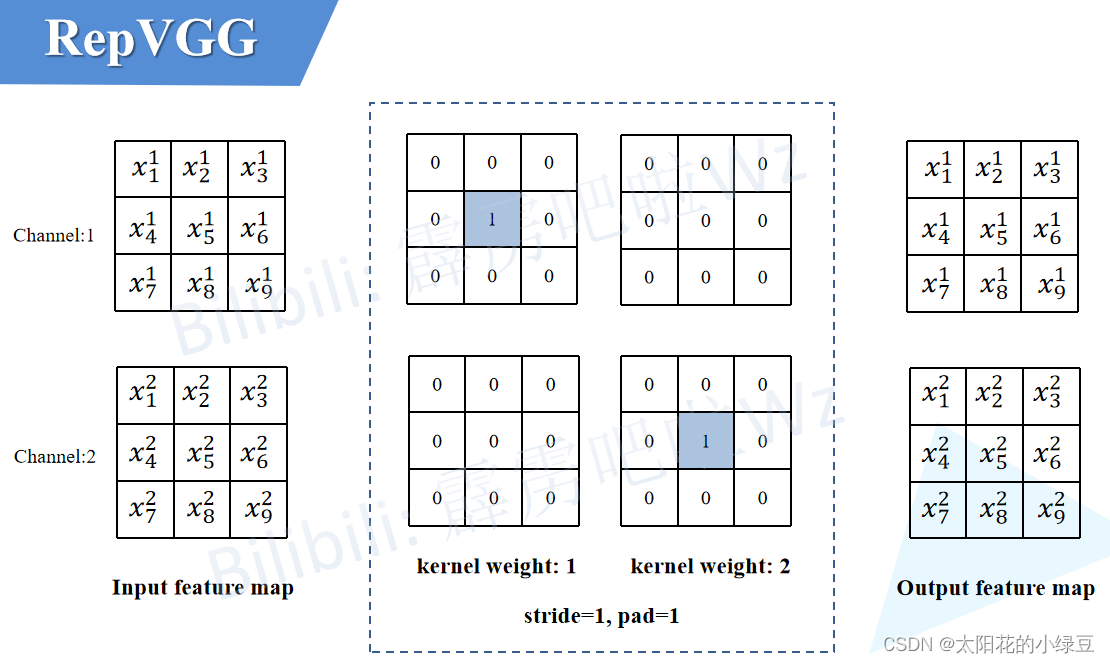
2.2将BN转换成3×3卷积
对于只有BN的分支由于没有卷积层,所以我们可以先自己构建出一个卷积层来。如下图所示,构建了一个3×3的卷积层,该卷积层只做了恒等映射,即输入输出特征图不变。既然有了卷积层,那么又可以按照上述2.1中讲的内容将卷积层和BN层进行融合。
2.3 多分支融合
在上面的章节中,我们已经讲了怎么把每个分支融合转换成一个3×3的卷积层,接下来需要进一步将多分支转换成一个单路3×3卷积层。
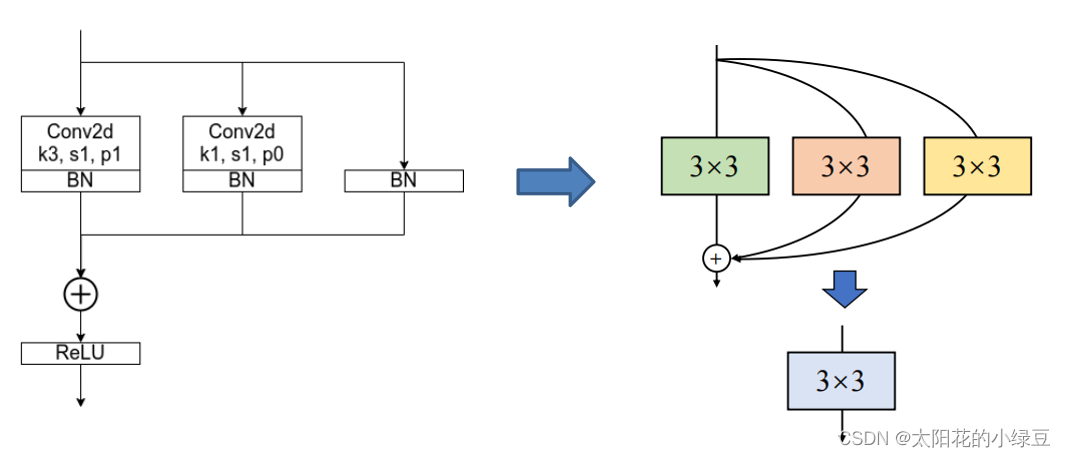
合并的过程其实也很简单,直接将这三个卷积层的参数相加即可,具体推理过程就不讲了,如果不了解的可以自己动手算算。
总的来说,这篇论文的目标是Simple is Fast, Memory-economical, Flexible,提出了很多想法去实现上述目标,对于当前我的工作还是比较有启发的,尤其是最后对网络进行合并以及量化部分。下一步要好好学习下torch的量化QAT (torch.quantization.prepare_qat)