
https://yolox.readthedocs.io/en/latest/quick_run.html
论文地址:https://arxiv.org/abs/2107.08430
github:https://github.com/Megvii-BaseDetection/YOLOX
网络结构可视化: https://blog.csdn.net/nan355655600/article/details/119329848
YOLOX 是 YOLO 的无锚版本,设计更简单但性能更好!它旨在弥合研究和工业界之间的差距。
YOLO系列始终追求实时应用的最佳速度和精度取舍,提取了当时可用的最先进的检测技术(例如,anchor用于YOLOv2,残差网络用于YOLOv3),并优化最佳实践的实现。
然而在过去的两年中,目标检测学术界的主要进展集中在anchor_free检测器,高级标签分配策略和端到端(NMS-free)检测器,这些研究成果还没有被集成在YOLO系列中,YOLOv4和YOLOv5目前还是使用了anchor_based及手动的指定训练分配规则(比如anchor相关的设置)。
作者还认为,YOLOv4和YOLOv5中对anchor有点过度的优化,所以重新将YOLOv3-SPP版本作为优化起点。原因是,YOLOv3由于计算资源有限,在各种实际应用中软件支持不足,仍然是行业中应用最广泛的探测器之一。
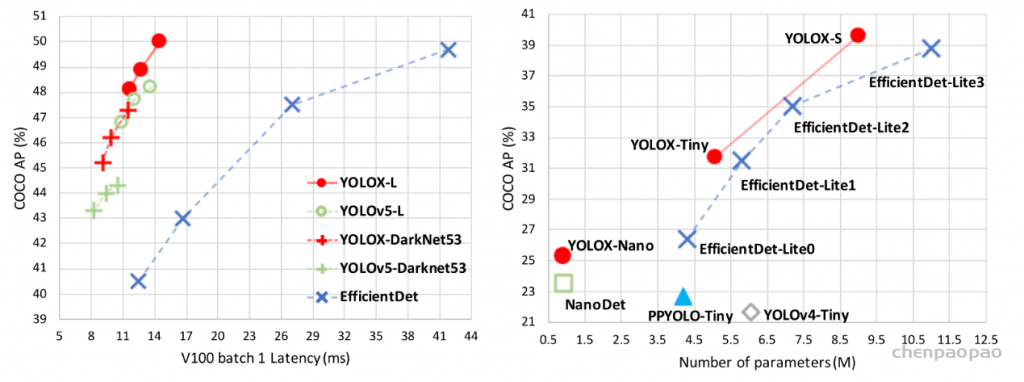
1、网络结构:
先看下Yolov3、Yolov4、Yolov5的网络结构图,而后面的Yolox网络,都是在此基础上延伸而来的。
① Yolov3网络结构图
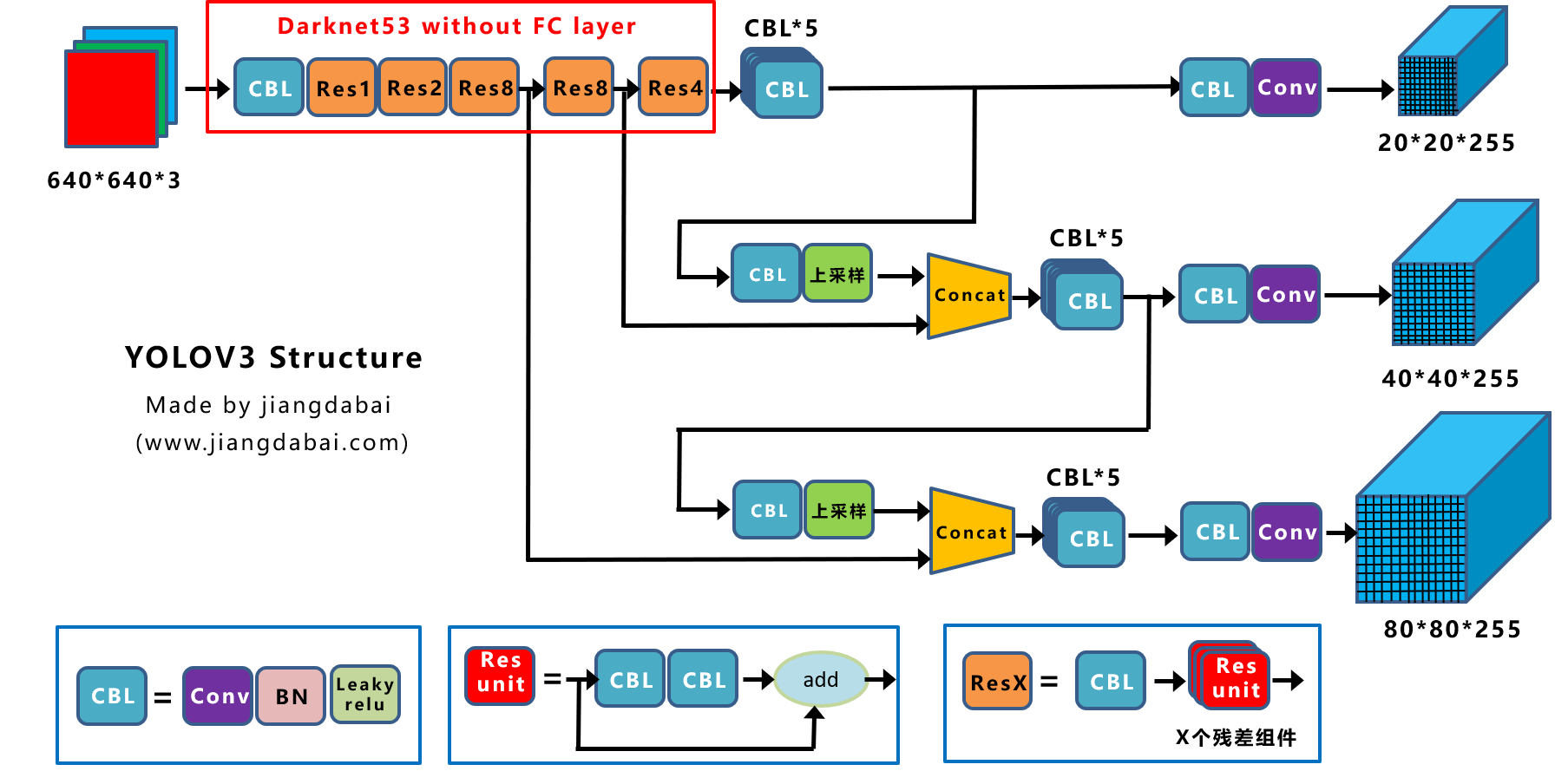
Yolov3是在2018年提出,也是工业界使用非常广泛的目标检测算法。
不过在Yolox系列中的,Yolox-Darknet53模型,采用的Baseline基准网络,采用的并不是Yolov3版本,而是改进后的Yolov3_spp版本。
而Yolov3和Yolov3_spp的不同点在于,Yolov3的主干网络后面,添加了spp组件,这里需要注意。
② Yolov4网络结构图
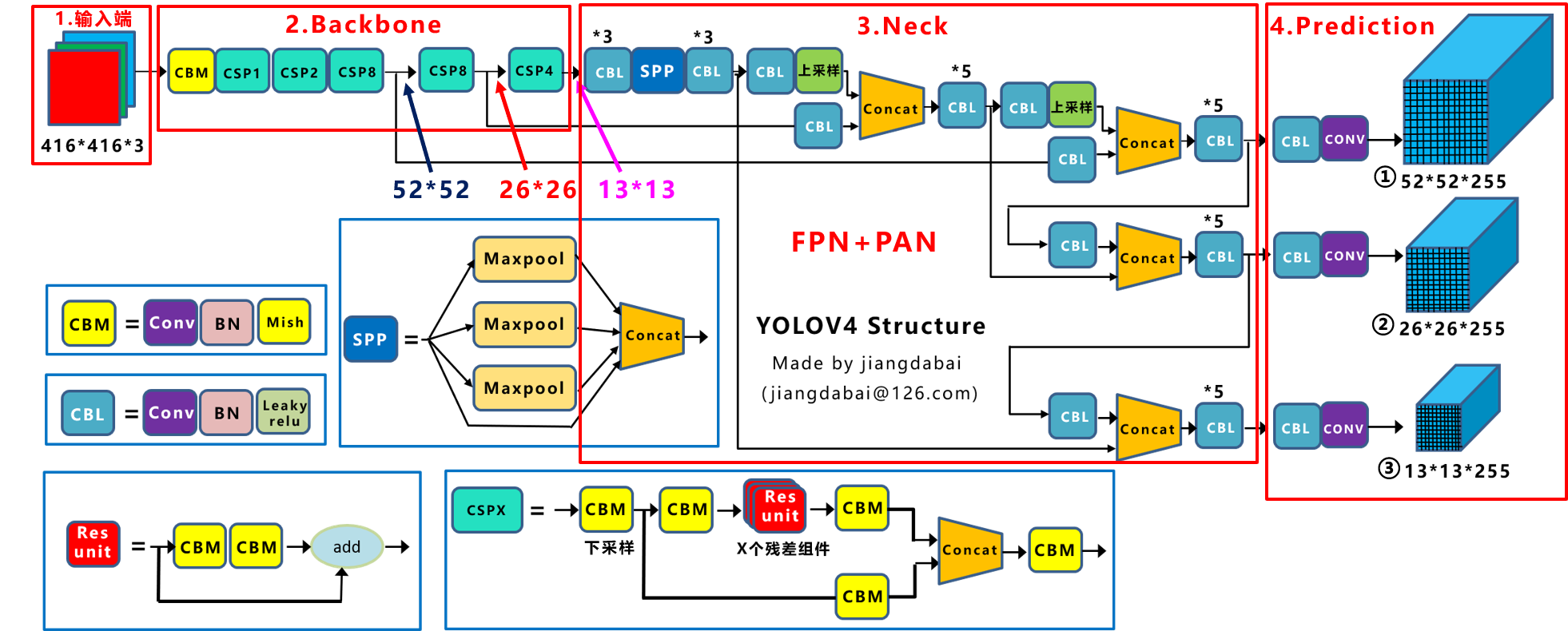
上图是DarknetAB大神,在2020年提出的Yolov4算法。
在此算法中,网络的很多地方,都进行了改进。
比如输入端:采用Mosaic数据增强;
Backbone:采用了CSPDarknet53、Mish激活函数、Dropblock等方式;
Neck:采用了SPP(按照DarknetAB的设定)、FPN+PAN结构;
输出端:采用CIOU_Loss、DIOU_Nms操作。
因此可以看出,Yolov4对Yolov3的各个部分,都进行了很多的整合创新。
③ Yolov5网络结构图
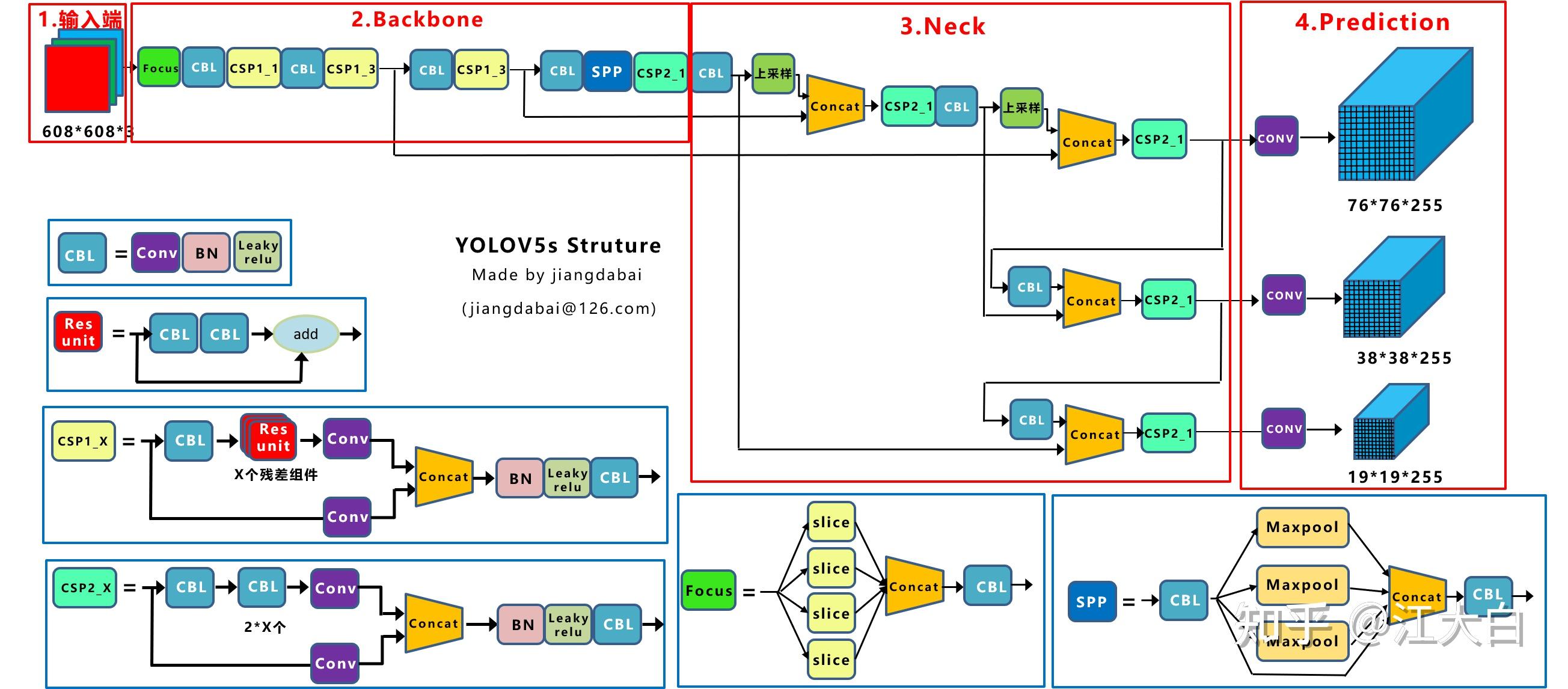
而在Yolov5网络中,和Yolov4不同,最大的创新点在于,作者将网络结构,做成了可选择配置的方式。
比如主干网络结构,根据各个网络的宽度、高度不同,可以分为Yolov5s、Yolov5l、Yolov5s、Yolo5x等版本。
这种转变,在目标检测领域,引领了一股网络拆分的热潮。
本文的Yolox算法,也从这个角度出发,将Yolox模型,变为多种可选配的网络,比如标准网络结构和轻量级网络结构。
(1)标准网络结构:Yolox-s、Yolox-m、Yolox-l、Yolox-x、Yolox-Darknet53。
(2)轻量级网络结构:Yolox-Nano、Yolox-Tiny。
在实际的项目中,大家可以根据不同项目需求,进行挑选使用。
从上面的描述中,我们可以知道Yolox整体的改进思路:
(1)基准模型:Yolov3_spp
选择Yolov3_spp结构,并添加一些常用的改进方式,作为Yolov3 baseline基准模型;
(2)Yolox-Darknet53
对Yolov3 baseline基准模型,添加各种trick,比如Decoupled Head、SimOTA等,得到Yolox-Darknet53版本;
(3)Yolox-s、Yolox-m、Yolox-l、Yolox-x系列
对Yolov5的四个版本,采用这些有效的trick,逐一进行改进,得到Yolox-s、Yolox-m、Yolox-l、Yolox-x四个版本;
(4)轻量级网络
设计了Yolox-Nano、Yolox-Tiny轻量级网络,并测试了一些trick的适用性;
基准模型:Yolov3_spp
在设计算法时,为了对比改进trick的好坏,常常需要选择基准的模型算法。
而在选择Yolox的基准模型时,作者考虑到:
Yolov4和Yolov5系列,从基于锚框的算法角度来说,可能有一些过度优化,因此最终选择了Yolov3系列。
不过也并没有直接选择Yolov3系列中,标准的Yolov3算法,而是选择添加了spp组件,进而性能更优的Yolov3_spp版本。
以下是论文中的解释:
Considering YOLOv4 and YOLOv5 may be a little over-optimized for the anchor-based pipeline, we choose YOLOv3 [25] as our start point (we set YOLOv3-SPP as the default YOLOv3)。
为了便于理解,在前面Yolov3结构图的基础上,添加上spp组件,变为下图所示的Yolov3_spp网络。
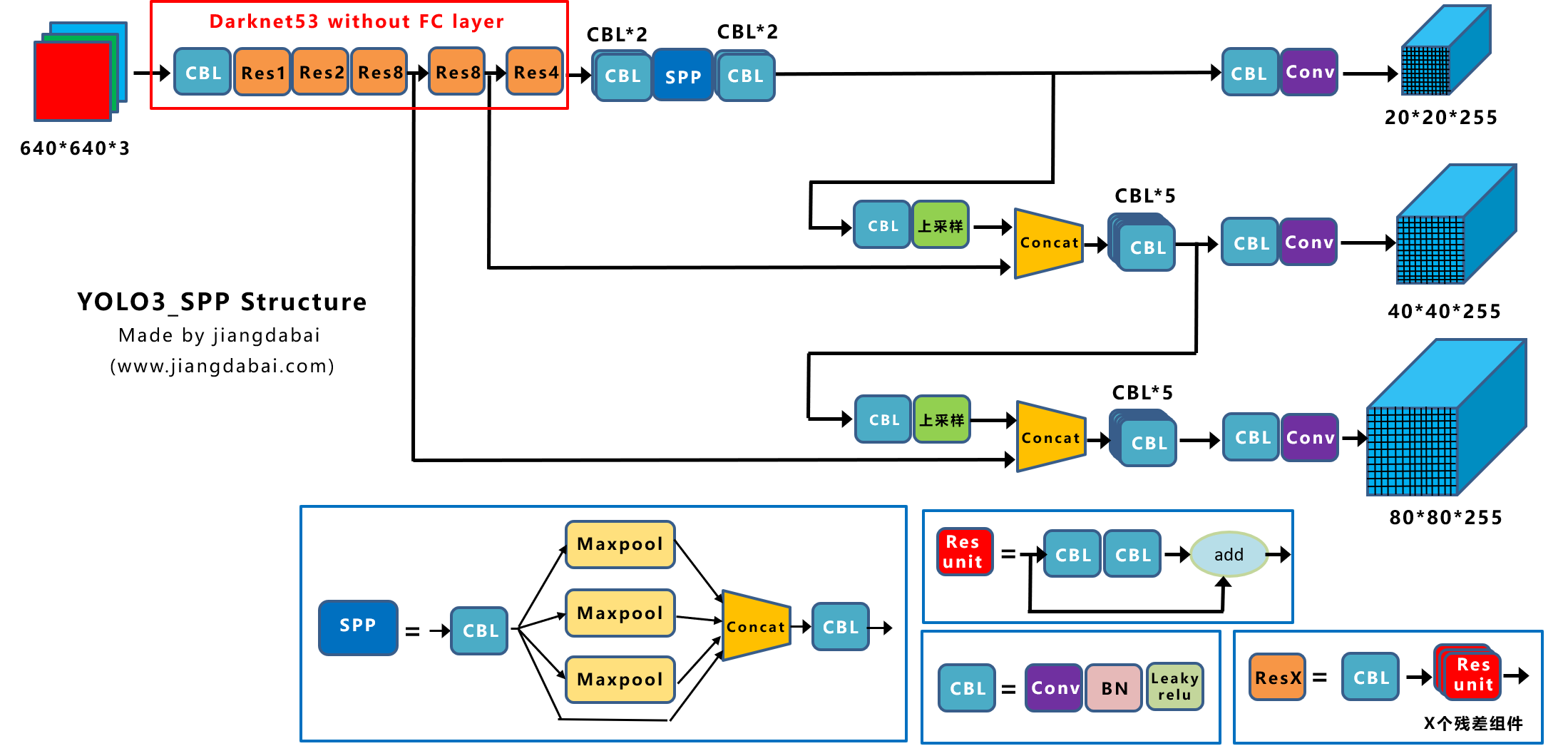
大家可以看到,主干网络Backbone后面,增加了一个SPP组件。
当然在此基础上,对网络训练过程中的很多地方,都进行了改进,比如:
(1)添加了EMA权值更新、Cosine学习率机制等训练技巧
(2)使用IOU损失函数训练reg分支,BCE损失函数训练cls与obj分支
(3)添加了RandomHorizontalFlip、ColorJitter以及多尺度数据增广,移除了RandomResizedCrop。
在此基础上,Yolov3_spp的AP值达到38.5,即下图中的Yolov3 baseline。
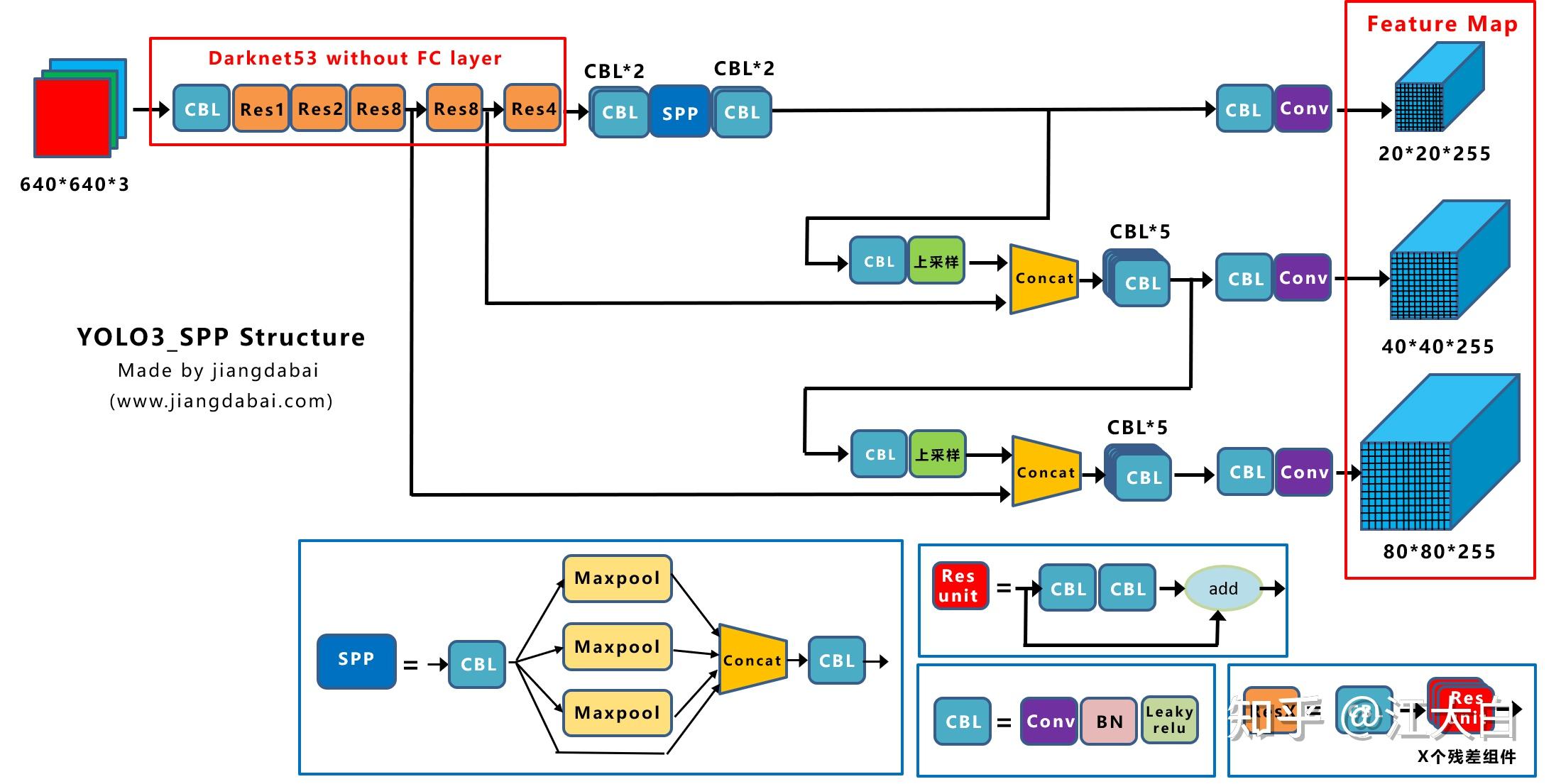
Yolox-Darknet53
我们在前面知道,当得到Yolov3 baseline后,作者又添加了一系列的trick,最终改进为Yolox-Darknet53网络结构。
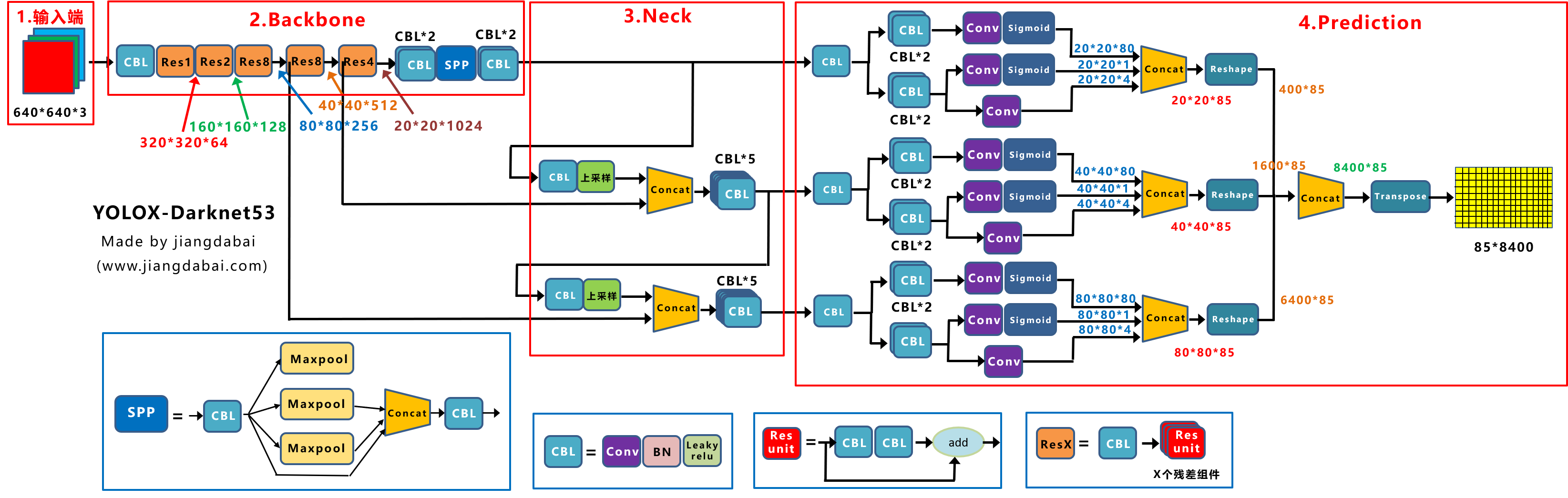
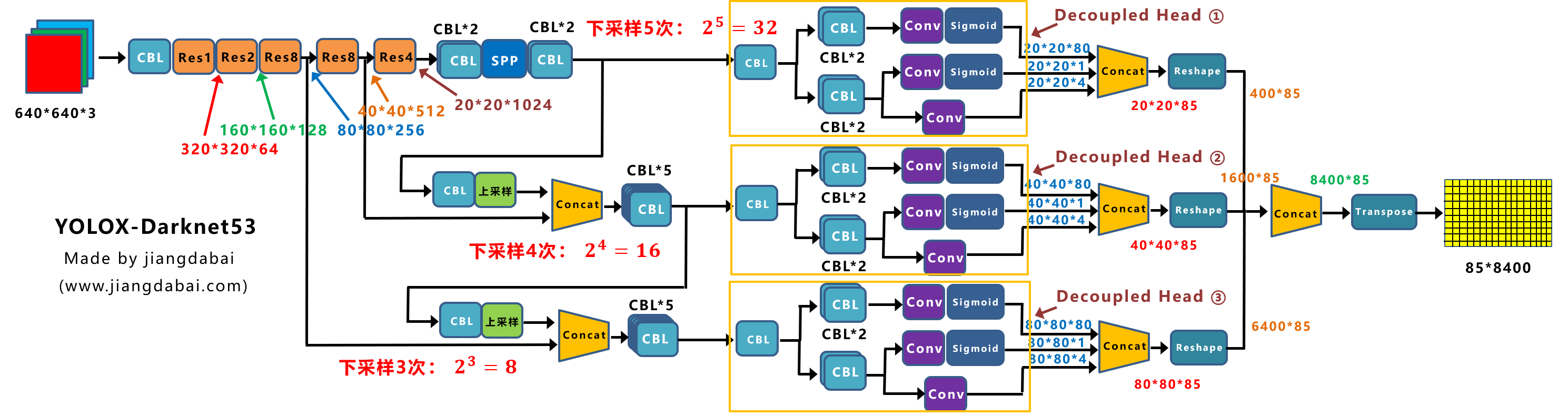
上图即是Yolox-Darknet53网络结构图。
为了便于分析改进点,我们对Yolox-Darknet53网络结构进行拆分,变为四个板块:
① 输入端:Strong augmentation数据增强
② BackBone主干网络:主干网络没有什么变化,还是Darknet53。
③ Neck:没有什么变化,Yolov3 baseline的Neck层还是FPN结构。
④ Prediction:Decoupled Head、End-to-End YOLO、Anchor-free、Multi positives。
在经过一系列的改进后,Yolox-Darknet53最终达到AP47.3的效果。
下面我们对于Yolox-Darknet53的输入端、Backbone、Neck、Prediction四个部分,进行详解的拆解。
输入端:
(1)Strong augmentation
在网络的输入端,Yolox主要采用了Mosaic、Mixup两种数据增强方法。
而采用了这两种数据增强,直接将Yolov3 baseline,提升了2.4个百分点。
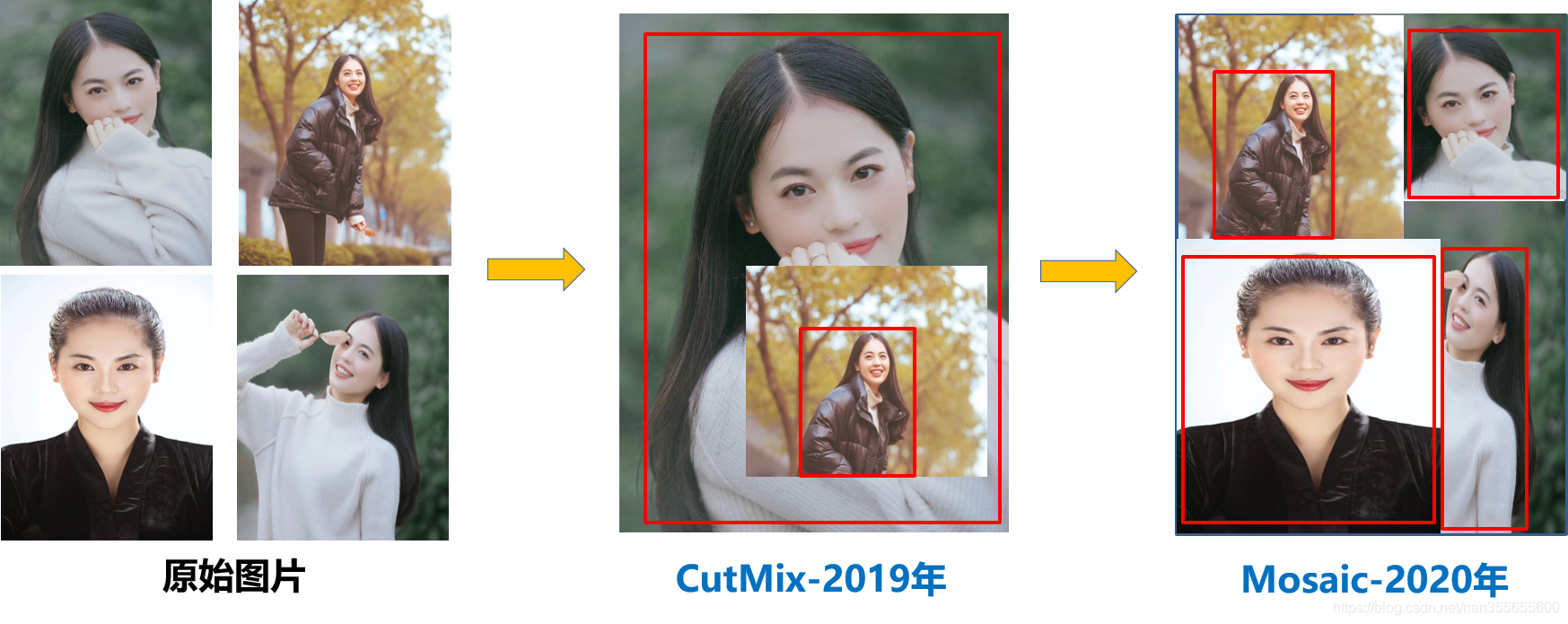
① Mosaic数据增强
Mosaic增强的方式,是U版YOLOv3引入的一种非常有效的增强策略。
而且在Yolov4、Yolov5算法中,也得到了广泛的应用。
通过随机缩放、随机裁剪、随机排布的方式进行拼接,对于小目标的检测效果提升,还是很不错的。
② MixUp数据增强
MixUp是在Mosaic基础上,增加的一种额外的增强策略。
主要来源于2017年,顶会ICLR的一篇论文《mixup: Beyond Empirical Risk Minimization》。当时主要应用在图像分类任务中,可以在几乎无额外计算开销的情况下,稳定提升1个百分点的分类精度。
而在Yolox中,则也应用到目标检测中,代码在yolox/datasets/mosaicdetection.py这个文件中。

其实方式很简单,比如我们在做人脸检测的任务。
先读取一张图片,图像两侧填充,缩放到640*640大小,即Image_1,人脸检测框为红色框。
再随机选取一张图片,图像上下填充,也缩放到640*640大小,即Image_2,人脸检测框为蓝色框。
然后设置一个融合系数,比如上图中,设置为0.5,将Image_1和Image_2,加权融合,最终得到右面的Image。
从右图可以看出,人脸的红色框和蓝色框是叠加存在的。
我们知道,在Mosaic和Mixup的基础上,Yolov3 baseline增加了2.4个百分点。
不过有两点需要注意:
(1)在训练的最后15个epoch,这两个数据增强会被关闭掉。
而在此之前,Mosaic和Mixup数据增强,都是打开的,这个细节需要注意。
(2)由于采取了更强的数据增强方式,作者在研究中发现,ImageNet预训练将毫无意义,因此,所有的模型,均是从头开始训练的。
2 Backbone
Yolox-Darknet53的Backbone主干网络,和原本的Yolov3 baseline的主干网络都是一样的。
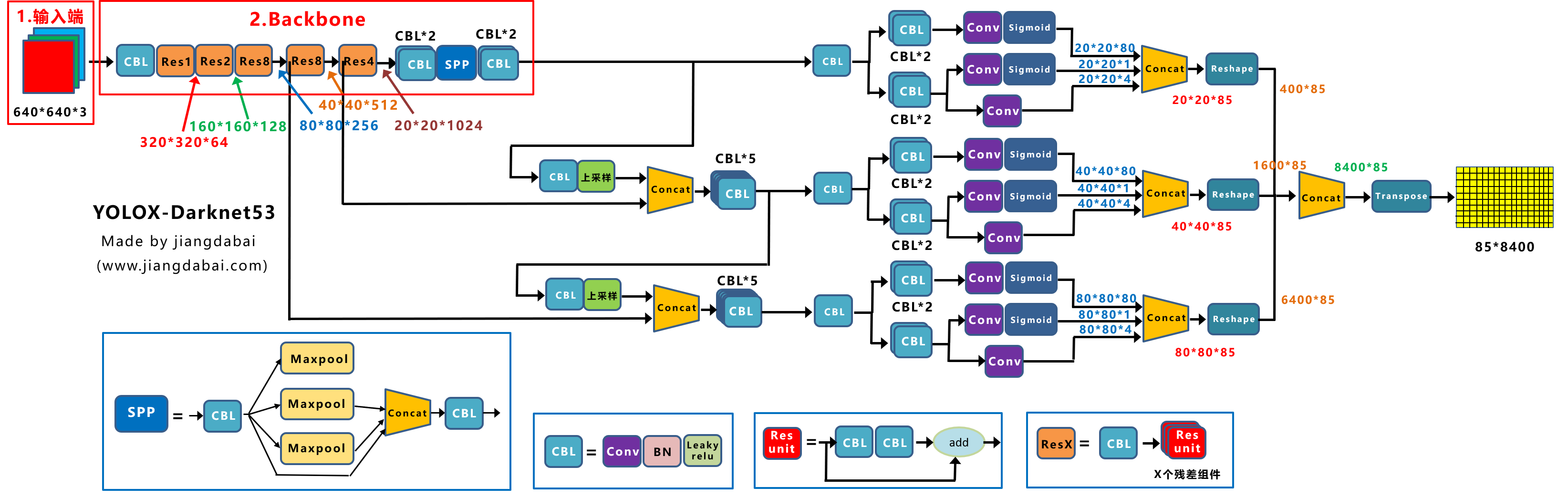
都是采用Darknet53的网络结构
3 Neck
在Neck结构中,Yolox-Darknet53和Yolov3 baseline的Neck结构,也是一样的,都是采用FPN的结构进行融合。
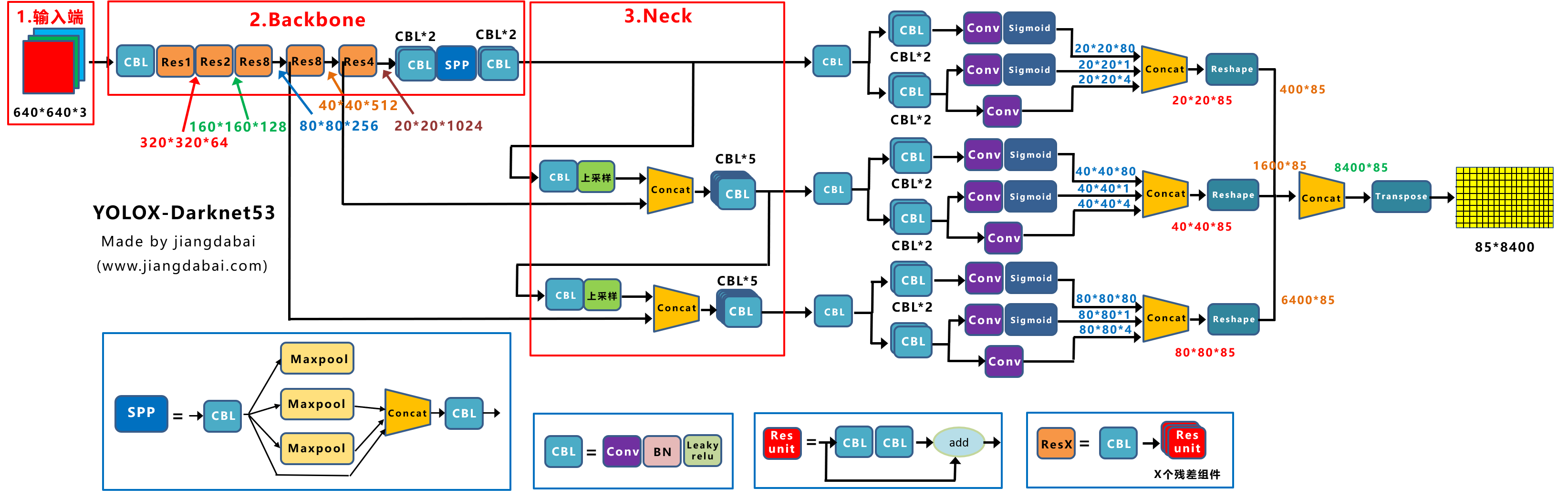
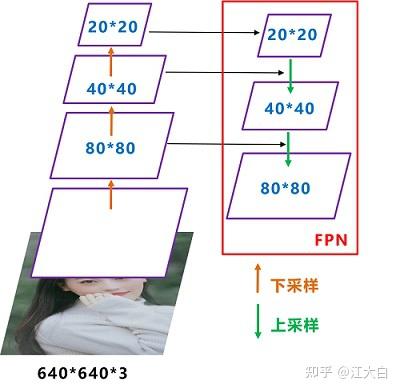
如下图所示,FPN自顶向下,将高层的特征信息,通过上采样的方式进行传递融合,得到进行预测的特征图。
Prediction层
在输出层中,主要从四个方面进行讲解:Decoupled Head、Anchor Free、标签分配、Loss计算。
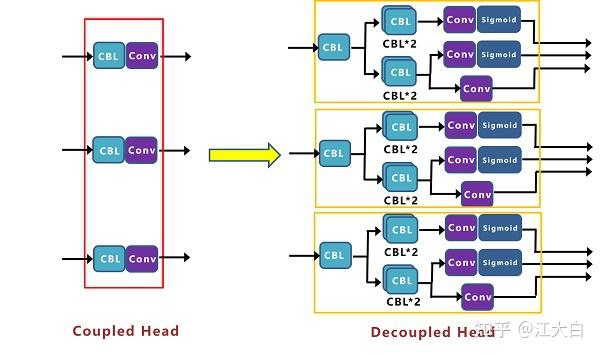
(1)Decoupled Head
我们先来看一下Decoupled Head,目前在很多一阶段网络中都有类似应用,比如RetinaNet、FCOS等。
而在Yolox中,作者增加了三个Decoupled Head,俗称“解耦头”
大白这里从两个方面对Decoupled Head进行讲解:
① 为什么使用Decoupled Head?
② Decoupled Head的细节?

从上图右面的Prediction中,我们可以看到,有三个Decoupled Head分支。
① 为什么使用Decoupled Head?
在了解原理前,我们先了解下改进的原因。为什么将原本的Yolo head,修改为Decoupled Head呢?
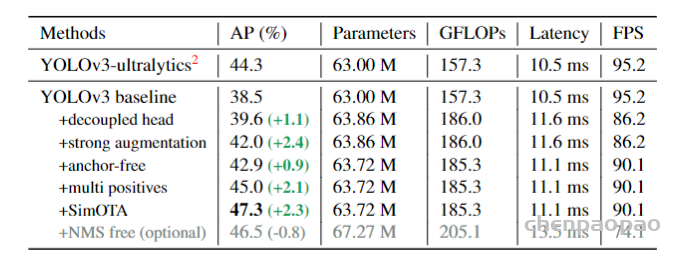
我们先看一张论文中的表格:

在前面3.2.1 基准网络中,我们知道Yolov3 baseline的AP值为38.5。
作者想继续改进,比如输出端改进为End-to-end的方式(即无NMS的形式)。
但意外的发现,改进完之后的AP值只有34.3。
而在2020年12月份,旷视科技发表的《End-to-End Object Detection with Fully Convolution Network》中。
在对FCOS改进为无NMS时,在COCO上,达到了与有NMS的FCOS,相当的性能。
那这时就奇怪了,为什么在Yolo上改进,会下降这么多?
在偶然间,作者将End-to-End中的Yolo Head,修改为Decoupled Head的方式。
惊喜的发现,End-to-end Yolo的AP值,从34.3增加到38.8。
那End-to-end的方式有效果,Yolov3 baseline中是否也有效果呢?
然后作者又将Yolov3 baseline 中Yolo Head,也修改为Decoupled Head。
发现AP值,从38.5,增加到39.6。
当然作者在实验中还发现,不单单是精度上的提高。替换为Decoupled Head后,网络的收敛速度也加快了。
但是需要注意的是:将检测头解耦,会增加运算的复杂度。
因此作者经过速度和性能上的权衡,最终使用 1个1×1 的卷积先进行降维,并在后面两个分支里,各使用了 2个3×3 卷积,最终调整到仅仅增加一点点的网络参数。
而且这里解耦后,还有一个更深层次的重要性:
Yolox的网络架构,可以和很多算法任务,进行一体化结合。
比如:
(1)YOLOX + Yolact/CondInst/SOLO ,实现端侧的实例分割。
(2)YOLOX + 34 层输出,实现端侧人体的 17 个关键点检测。
② Decoupled Head的细节?
了解了Decoupled Head的来源,再看一下Decoupled Head的细节。
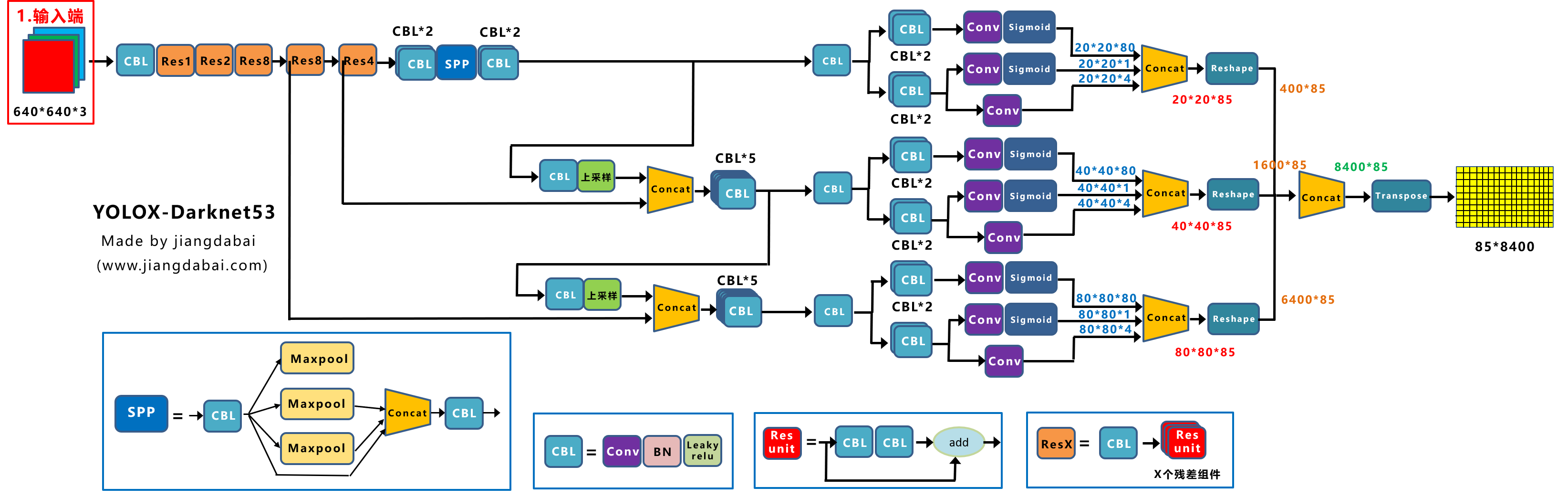
我们将Yolox-Darknet53中,Decoupled Head①提取出来,经过前面的Neck层,这里Decouple Head①输入的长宽为20*20。
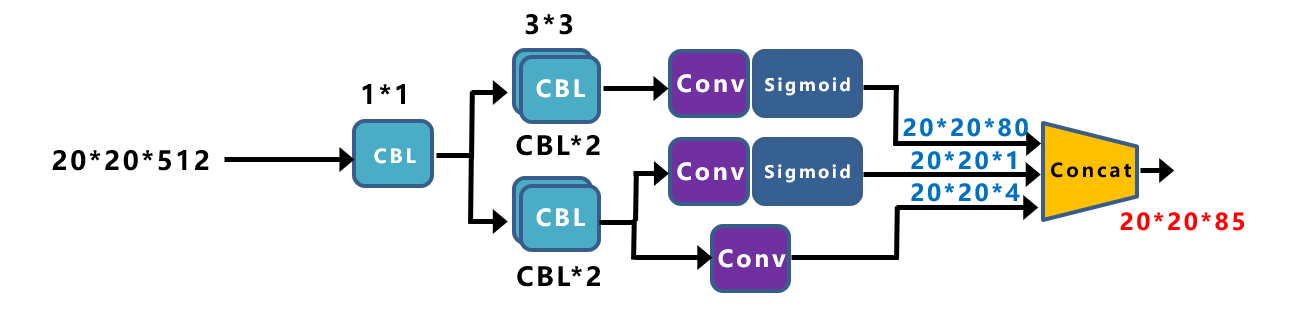
从图上可以看出,Concat前总共有三个分支:
(1)cls_output:主要对目标框的类别,预测分数。因为COCO数据集总共有80个类别,且主要是N个二分类判断,因此经过Sigmoid激活函数处理后,变为20*20*80大小。
(2)obj_output:主要判断目标框是前景还是背景,因此经过Sigmoid处理好,变为20*20*1大小。
(3)reg_output:主要对目标框的坐标信息(x,y,w,h)进行预测,因此大小为20*20*4。
最后三个output,经过Concat融合到一起,得到20*20*85的特征信息。
当然,这只是Decoupled Head①的信息,再对Decoupled Head②和③进行处理。
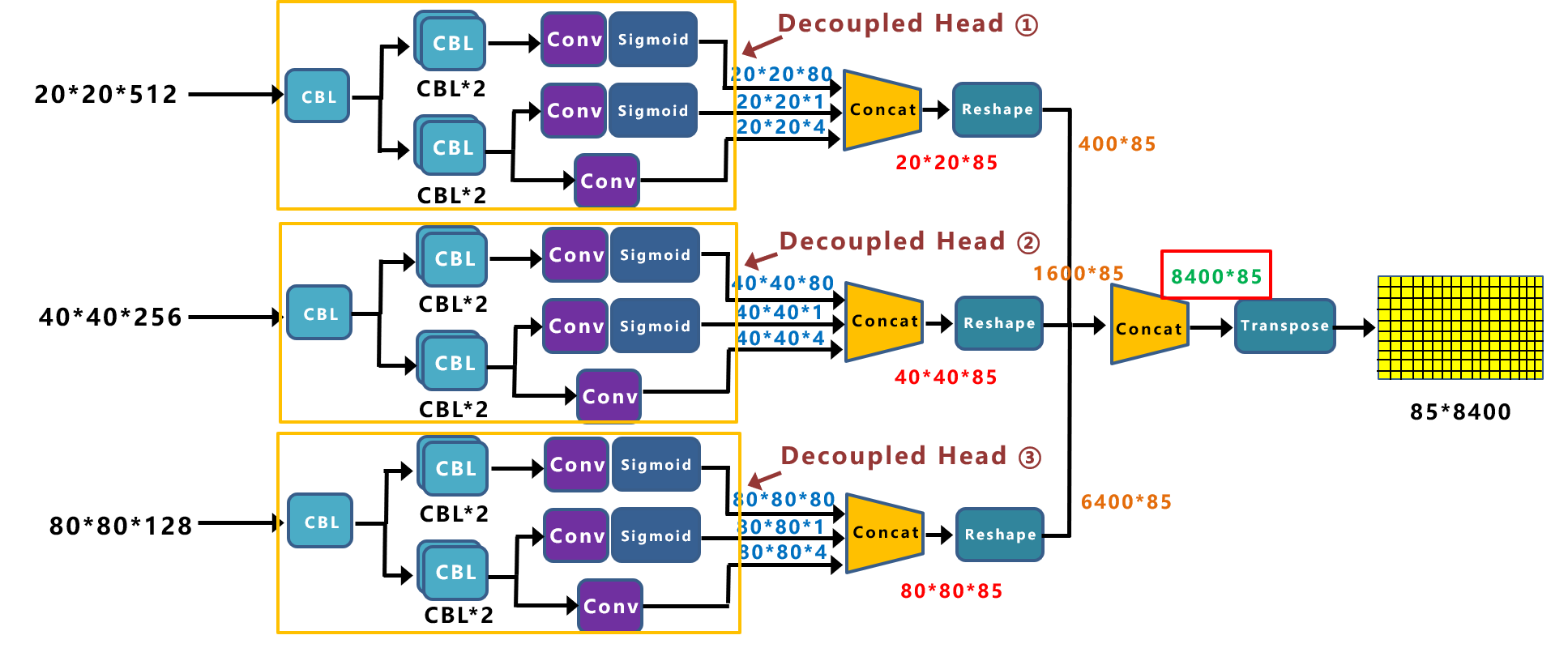
Decoupled Head②输出特征信息,并进行Concate,得到40*40*85特征信息。
Decoupled Head③输出特征信息,并进行Concate,得到80*80*85特征信息。
再对①②③三个信息,进行Reshape操作,并进行总体的Concat,得到8400*85的预测信息。
并经过一次Transpose,变为85*8400大小的二维向量信息。
这里的8400,指的是预测框的数量,而85是每个预测框的信息(reg,obj,cls)。
有了预测框的信息,下面我们再了解,如何将这些预测框和标注的框,即groundtruth进行关联,从而计算Loss函数,更新网络参数呢?
(2)Anchor-free
这里就要引入Anchor的内容,目前行业内,主要有Anchor Based和Anchor Free两种方式。
在Yolov3、Yolov4、Yolov5中,通常都是采用Anchor Based的方式,来提取目标框,进而和标注的groundtruth进行比对,判断两者的差距。
① Anchor Based方式
比如输入图像,经过Backbone、Neck层,最终将特征信息,传送到输出的Feature Map中。
这时,就要设置一些Anchor规则,将预测框和标注框进行关联。
从而在训练中,计算两者的差距,即损失函数,再更新网络参数。
比如在下图的,最后的三个Feature Map上,基于每个单元格,都有三个不同尺寸大小的锚框。
这里为了更形象的展示,以大白Yolov3视频中,输入图像大小416*416为例。

当输入为416*416时,网络最后的三个特征图大小为13*13,26*26,52*52。
我们可以看到,黄色框为小狗的Groundtruth,即标注框。
而蓝色的框,为小狗中心点所在的单元格,所对应的锚框,每个单元格都有3个蓝框。
当采用COCO数据集,即有80个类别时。
基于每个锚框,都有x、y、w、h、obj(前景背景)、class(80个类别),共85个参数。
因此会产生3*(13*13+26*26+52*52)*85=904995个预测结果。
如果将输入从416*416,变为640*640,最后的三个特征图大小为20*20,40*40,80*80。
则会产生3*(20*20+40*40+80*80)*85=2142000个预测结果。
② Anchor Free方式
而Yolox-Darknet53中,则采用Anchor Free的方式。
我们从两个方面,来对Anchor Free进行了解。
a.输出的参数量
我们先计算下,当得到包含目标框所有输出信息时,所需要的参数量?
这里需要注意的是:
最后黄色的85*8400,不是类似于Yolov3中的Feature Map,而是特征向量。

从图中可知,当输入为640*640时,最终输出得到的特征向量是85*8400。
我们看下,和之前Anchor Based方式,预测结果数量相差多少?
通过计算,8400*85=714000个预测结果,比基于Anchor Based的方式,少了2/3的参数量。
b.Anchor框信息
在前面Anchor Based中,我们知道,每个Feature map的单元格,都有3个大小不一的锚框。
那么Yolox-Darknet53就没有吗?
其实并不然,这里只是巧妙的,将前面Backbone中,下采样的大小信息引入进来。
比如上图中,最上面的分支,下采样了5次,2的5次方为32。
并且Decoupled Head①的输出,为20*20*85大小。
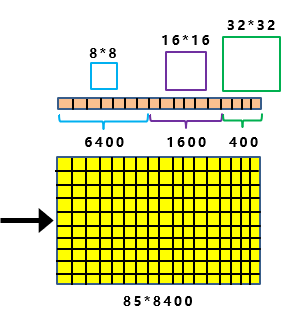
因此如上图所示:
最后8400个预测框中,其中有400个框,所对应锚框的大小,为32*32。
同样的原理,中间的分支,最后有1600个预测框,所对应锚框的大小,为16*16。
最下面的分支,最后有6400个预测框,所对应锚框的大小,为8*8。
当有了8400个预测框的信息,每张图片也有标注的目标框的信息。
这时的锚框,就相当于桥梁。
这时需要做的,就是将8400个锚框,和图片上所有的目标框进行关联,挑选出正样本锚框。
而相应的,正样本锚框所对应的位置,就可以将正样本预测框,挑选出来。
这里采用的关联方式,就是标签分配。
(3)标签分配
当有了8400个Anchor锚框后,这里的每一个锚框,都对应85*8400特征向量中的预测框信息。
不过需要知道,这些预测框只有少部分是正样本,绝大多数是负样本。
那么到底哪些是正样本呢?
这里需要利用锚框和实际目标框的关系,挑选出一部分适合的正样本锚框。
比如第3、10、15个锚框是正样本锚框,则对应到网络输出的8400个预测框中,第3、10、15个预测框,就是相应的正样本预测框。
训练过程中,在锚框的基础上,不断的预测,然后不断的迭代,从而更新网络参数,让网络预测的越来越准。
那么在Yolox中,是如何挑选正样本锚框的呢?
这里就涉及到两个关键点:初步筛选、SimOTA。
① 初步筛选
初步筛选的方式主要有两种:根据中心点来判断、根据目标框来判断;
这部分的代码,在models/yolo_head.py的get_in_boxes_info函数中。
a. 根据中心点来判断:
规则:寻找anchor_box中心点,落在groundtruth_boxes矩形范围的所有anchors。
比如在get_in_boxes_info的代码中,通过groundtruth的[x_center,y_center,w,h],计算出每张图片的每个groundtruth的左上角、右下角坐标。
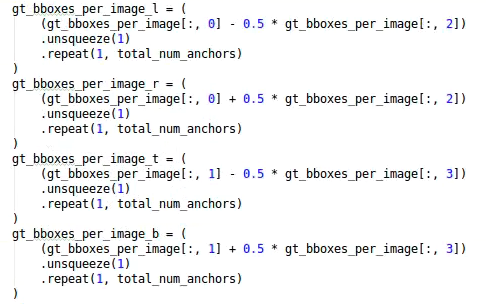
为了大家更容易理解,大白以人脸检测的任务绘制图片:
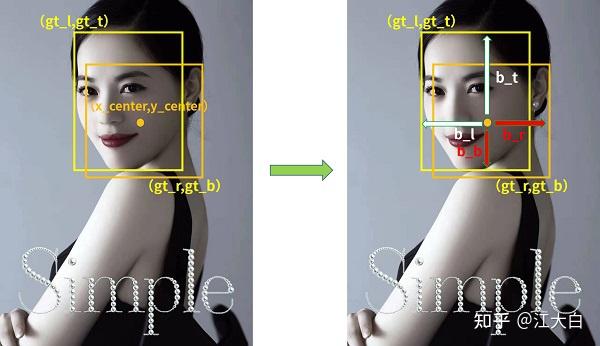
通过上面的公式,可以对左面人脸图片,计算出左上角(gt_l,gt_t),右下角(gt_r,gt_b)。
groundtruth的矩形框范围确定了,再根据范围去选择适合的锚框。
这里再绘制一个锚框的中心点,(x_center,y_center)。
而右面的图片,就是寻找锚框和groundtruth的对应关系。
即计算锚框中心点(x_center,y_center),和人脸标注框左上角(gt_l,gt_t),右下角(gt_r,gt_b)两个角点的相应距离。
比如下面代码图片中的前四行代码:
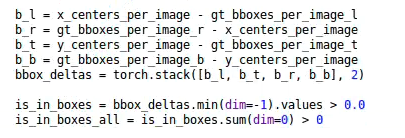
而在第五行,将四个值叠加之后,通过第六行,判断是否都大于0?
就可以将落在groundtruth矩形范围内的所有anchors,都提取出来了。
因为ancor box的中心点,只有落在矩形范围内,这时的b_l,b_r,b_t,b_b都大于0。
b.根据目标框来判断:
除了根据锚框中心点,和groundtruth两边距离判断的方式外,作者还设置了根据目标框判断的方法。
规则:以groundtruth中心点为基准,设置边长为5的正方形,挑选在正方形内的所有锚框。
同样在get_in_boxes_info的代码中,通过groundtruth的[x_center,y_center,w,h],绘制了一个边长为5的正方形。

为了大家容易理解,大白还是以人脸检测的任务绘制图片:
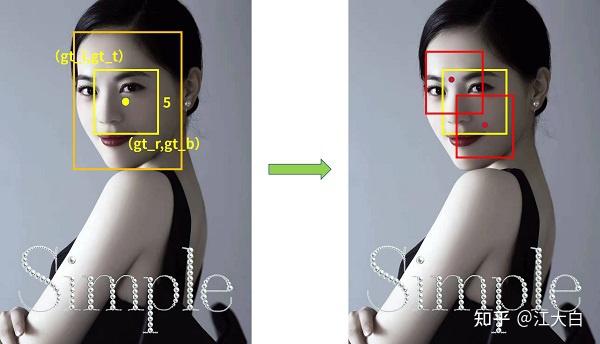
在左面的人脸图片中,基于人脸标注框的中心点,利用上面的公式,绘制了一个边长为5的正方形。左上角点为(gt_l,gt_t),右下角点为(gt_r,gt_b)。
这时groundtruth正方形范围确定了,再根据范围去挑选锚框。
而右面的图片,就是找出所有中心点(x_center,y_center)在正方形内的锚框。

在代码图片中的前四行代码,也是计算锚框中心点,和正方形两边的距离。
通过第五行的叠加,再在第六行,判断c_l,c_r,c_t,c_b是否都大于0?
就可以将落在边长为5的正方形范围内,所有的anchors,都提取出来了,因为这时的c_l,c_r,c_t,c_b都大于0。
经过上面两种挑选的方式,就完成初步筛选了,挑选出一部分候选的anchor,进入下一步的精细化筛选。
② 精细化筛选
而在精细化筛选中,就用到论文中提到的SimOTA了:
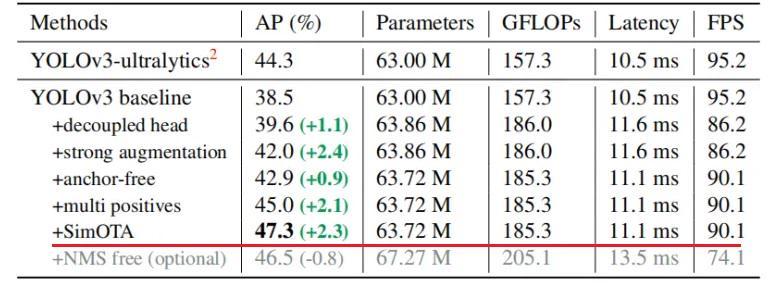
从提升效果上来看,引入SimOTA后,AP值提升了2.3个百分点,还是非常有效的。
而SimOAT方法的提出,主要来源于旷视科技,2021年初CVPR上的一篇论文:《Ota: Optimal transport assignment for object detection》。
我们将SimOTA的前后流程进行拆解,看一下是如何进行精细化筛选的?
整个筛选流程,主要分为四个阶段:
a.初筛正样本信息提取
b.Loss函数计算
c.cost成本计算
d.SimOTA求解
为了便于理解,我们假定图片上有3个目标框,即3个groundtruth。
再假定目前在做的项目是对人脸和人体检测,因此检测类别是2。
上一节中,我们知道有8400个锚框,但是经过初步筛选后,假定有1000个锚框是正样本锚框。
a.初筛正样本信息提取
初筛出的1000个正样本锚框的位置,我们是知道的。
而所有锚框的位置,和网络最后输出的85*8400特征向量是一一对应。
所以根据位置,可以将网络预测的候选检测框位置bboxes_preds、前景背景目标分数obj_preds、类别分数cls_preds等信息,提取出来。

上面的代码位于yolo_head.py的get_assignments函数中。
以前面的假定信息为例,代码图片中的bboxes_preds_per_image因为是候选检测框的信息,因此维度为[1000,4]。
obj_preds因为是目标分数,所以维度是[1000,1]。
cls_preds因为是类别分数,所以维度是[1000,2]。
b.Loss函数计算
针对筛选出的1000个候选检测框,和3个groundtruth计算Loss函数。
计算的代码,也在yolo_head.py的get_assignments函数中。
首先是位置信息的loss值:pair_wise_ious_loss

通过第一行代码,可以计算出3个目标框,和1000个候选框,每个框相互之间的iou信息pair_wise_ious,因为向量维度为[3,1000]。
再通过-torch.log计算,得到位置损失,即代码中的pair_wise_iou_loss。
然后是综合类别信息和目标信息的loss值:pair_wise_cls_loss

通过第一行代码,将类别的条件概率和目标的先验概率做乘积,得到目标的类别分数。
再通过第二行代码,F.binary_cross_entroy的处理,得到3个目标框和1000个候选框的综合loss值,即pair_wise_cls_loss,向量维度为[3,1000]。
c.cost成本计算
有了reg_loss和cls_loss,就可以将两个损失函数加权相加,计算cost成本函数了。
这里涉及到论文中提到的一个公式:
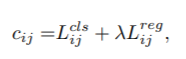
相应的,对应于yolo_head.py的get_assignments函数中的代码:

可以看出,公式中的加权系数,即代码中的3。
d.SimOTA
有了上面的一系列信息,标签分配问题,就转换为了标准的OTA问题。
但是经典的Sinkhorn-Knopp算法,需要多次迭代求得最优解。
作者也提到,该算法会导致25%额外训练时间,所以采用一种简化版的SimOTA方法,求解近似最优解。这里对应的函数,是get_assignments函数中的self.dynamic_k_matching:
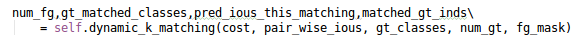
其中的流程如下:
第一步:设置候选框数量

首先按照cost值的大小,新建一个全0变量matching_matrix,这里是[3,1000]。

通过上面第二行代码,设置候选框数量为10。
再通过第三行代码,从前面的pair_wise_ious中,给每个目标框,挑选10个iou最大的候选框。
因为前面假定有3个目标,因此这里topk_ious的维度为[3,10]。
第二步:通过cost挑选候选框
下面再通过topk_ious的信息,动态选择候选框,这里是个关键。
代码如dynamic_k_matching函数中,下图所示:

为了便于大家理解,大白先把第一行制作成图示效果。
这里的topk_ious,是3个目标框和预测框中,最大iou的10个候选框:
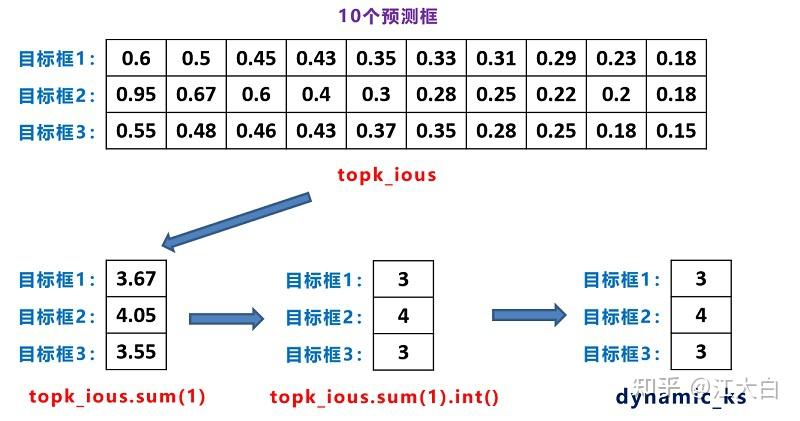
经过torch.clamp函数,得到最终右面的dynamic_ks值。
我们就知道,目标框1和3,给他分配3个候选框,而目标框2,给它分配4个候选框。
那么基于什么标准分配呢?
这时就要利用前面计算的cost值,即[3,1000]的损失函数加权信息。
在for循环中,针对每个目标框挑选,相应的cost值最低的一些候选框。
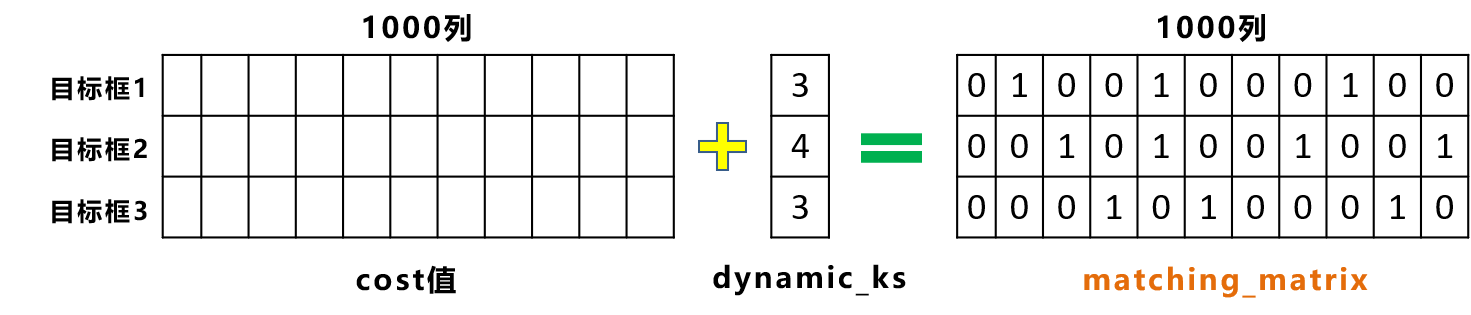
比如右面的matching_matrix中,cost值最低的一些位置,数值为1,其余位置都为0。
因为目标框1和3,dynamic_ks值都为3,因此matching_matrix的第一行和第三行,有3个1。
而目标框2,dynamic_ks值为4,因此matching_matrix的第二行,有4个1。
第三步:过滤共用的候选框
不过在分析matching_matrix时,我们发现,第5列有两个1。
这也就说明,第五列所对应的候选框,被目标检测框1和2,都进行关联。
因此对这两个位置,还要使用cost值进行对比,选择较小的值,再进一步筛选。

这里为了便于理解,还是采用图示的方式:
首先第一行代码,将matching_matrix,对每一列进行相加。

这时anchor_matching_gt中,只要有大于1的,说明有共用的情况。
上图案例中,表明第5列存在共用的情况。
再利用第三行代码,将cost中,第5列的值取出,并进行比较,计算最小值所对应的行数,以及分数。
我们将第5列两个位置,假设为0.4和0.3。

经过第三行代码,可以找到最小的值是0.3,即cost_min为0.3,所对应的行数,cost_argmin为2。

经过第四行代码,将matching_matrix第5列都置0。
再利用第五行代码,将matching_matrix第2行,第5列的位置变为1。
最终我们可以得到3个目标框,最合适的一些候选框,即matching_matrix中,所有1所对应的位置。
(4)Loss计算
经过第三部分的标签分配,就可以将目标框和正样本预测框对应起来了。
下面就可以计算两者的误差,即Loss函数。
计算的代码,位于yolo_head.py的get_losses函数中。

我们可以看到:
检测框位置的iou_loss,Yolox中使用传统的iou_loss,和giou_loss两种,可以进行选择。
而obj_loss和cls_loss,都是采用BCE_loss的方式。
当然除此之外,还有两点需要注意:
a.在前面精细化筛选中,使用了reg_loss和cls_loss,筛选出和目标框所对应的预测框。
因此这里的iou_loss和cls_loss,只针对目标框和筛选出的正样本预测框进行计算。
而obj_loss,则还是针对8400个预测框。
b.在Decoupled Head中,cls_output和obj_output使用了sigmoid函数进行归一化,
但是在训练时,并没有使用sigmoid函数,原因是训练时用的nn.BCEWithLogitsLoss函数,已经包含了sigmoid操作。
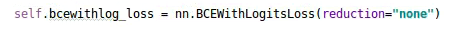
而在推理过程中,是使用Sigmoid函数的。

文章来源:https://zhuanlan.zhihu.com/p/397993315