

Transformer模型是目前机器翻译等NLP问题最好的解决办法,比RNN有大幅提高。Bidirectional Encoder Representations from Transformers (BERT) 是预训练Transformer最常用的方法,可以大幅提升Transformer的表现。
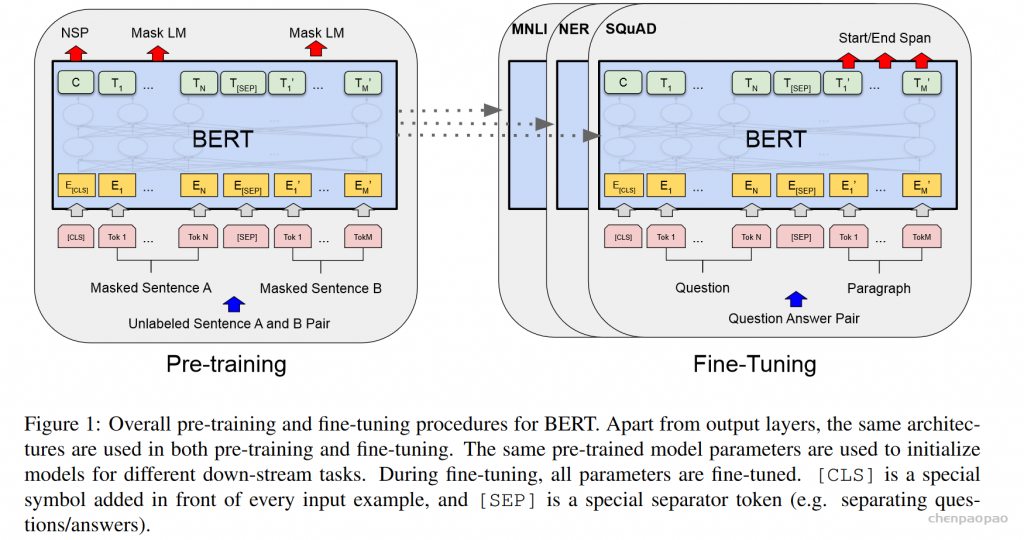
bert主要使用两个任务做训练:
1、预测被遮挡的单词
2、判断两句话是否相邻
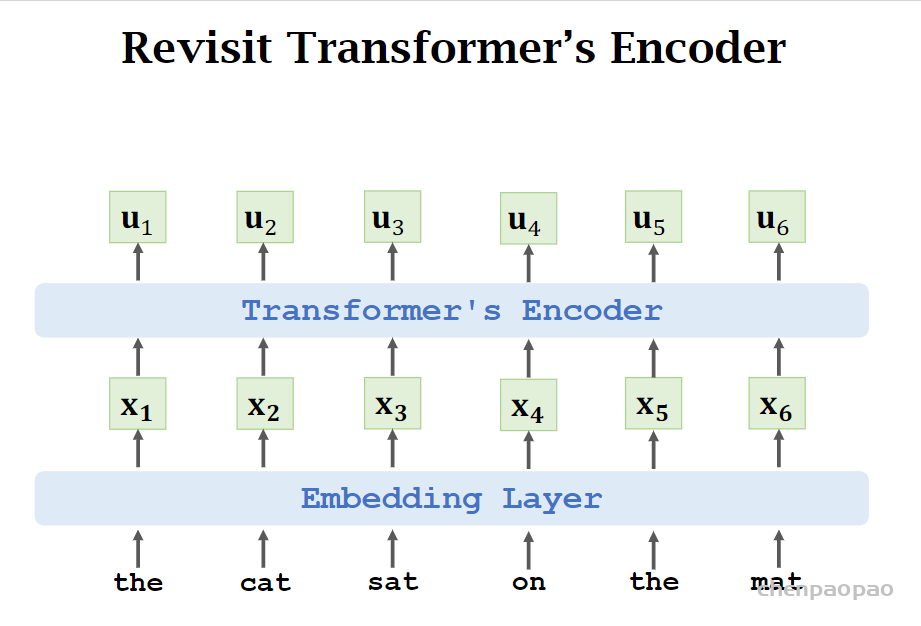
任务一:
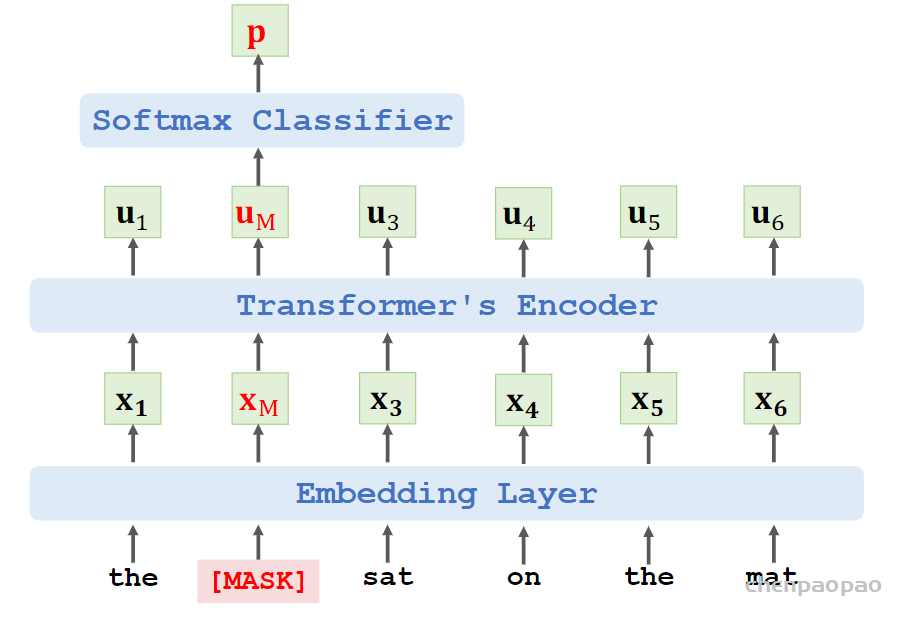
·𝐞: one-hot vector of the masked word “cat”.
• 𝐩: output probability distribution at the masked position.
• Loss = CrossEntropy(𝐞, 𝐩) .
• Performing one gradient descent to update the model parameters.
Task 2: Predict the Next Sentence
Given the sentence:
“calculus is a branch of math”.
• Is this the next sentence?
“it was developed by newton and leibniz”
Input:两句话之间有sep符号分开,cls表示分类任务
[CLS] “calculus is a branch of math”
[SEP] “it was developed by newton and leibniz”
• [CLS] is a token for classification.
• [SEP] is for separating sentences.
Input:
[CLS] “calculus is a branch of math”
[SEP] “it was developed by newton and leibniz”
• Target: true
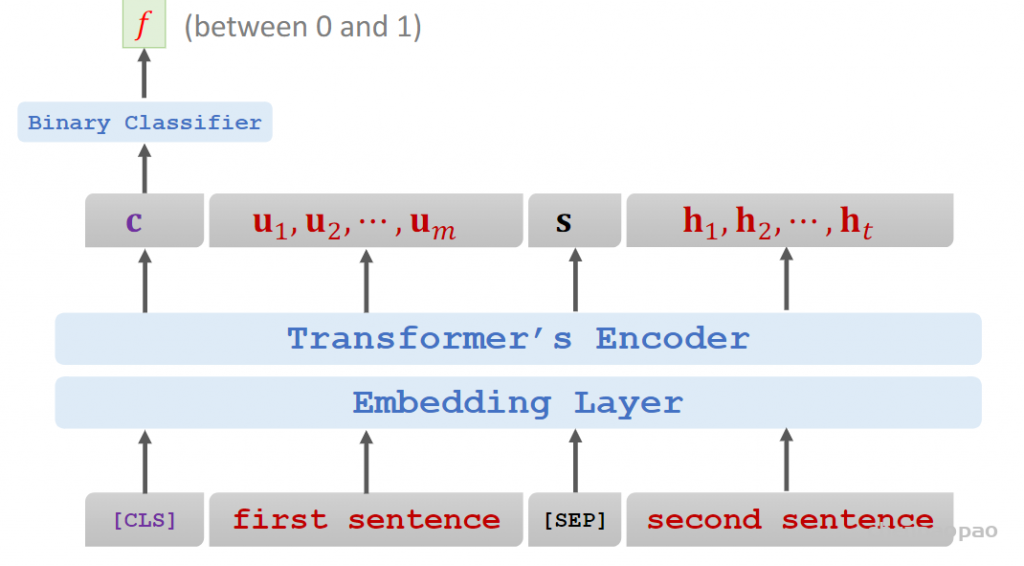
Combining the two methods:
• Input:
“[CLS] calculus is a [MASK] of math
[SEP] it [MASK] developed by newton and leibniz”.
• Targets: true, “branch”, “was”.
bert同时使用两种任务结合:
Loss 1 is for binary classification (i.e., predicting the next
sentence.)
• Loss 2 and Loss 3 are for multi-class classification (i.e., predicting
the masked words.)
• Objective function is the sum of the three loss functions.
• Update model parameters by performing one gradient descent
数据集:

BERT的bidirectional如何体现的?
论文研究团队有理由相信,深度双向模型比left-to-right 模型或left-to-right and right-to-left模型的浅层连接更强大。从中可以看出BERT的双向叫深度双向,不同于以往的双向理解,以往的双向是从左到右和从右到左结合,这种虽然看着是双向的,但是两个方向的loss计算相互独立,所以其实还是单向的,只不过简单融合了一下,而bert的双向是要同时看上下文语境的,所有不同。
为了训练一个深度双向表示(deep bidirectional representation),研究团队采用了一种简单的方法,即随机屏蔽(masking)部分输入token,然后只预测那些被屏蔽的token,(我理解这种情况下,模型如果想预测出这个masked的词,就必须结合上下文来预测,所以就达到了双向目的,有点类似于我们小学时候做的完形填空题目,你要填写对这个词,就必须结合上下文,BERT就是这个思路训练机器的,看来利用小学生的教学方式,有助于训练机器)。论文将这个过程称为“Masked Language Model”(MLM)。
Masked双向语言模型这么做:随机选择语料中15%的单词,把它抠掉,也就是用[Mask]掩码代替原始单词,然后要求模型去正确预测被抠掉的单词。但是这里有个问题:训练过程大量看到[mask]标记,但是真正后面用的时候是不会有这个标记的,这会引导模型认为输出是针对[mask]这个标记的,但是实际使用又见不到这个标记,这自然会有问题。为了避免这个问题,Bert改造了一下,15%的被上天选中要执行[mask]替身这项光荣任务的单词中,只有80%真正被替换成[mask]标记,10%被狸猫换太子随机替换成另外一个单词,10%情况这个单词还待在原地不做改动。这就是Masked双向语音模型的具体做法。
例如在这个句子“my dog is hairy”中,它选择的token是“hairy”。然后,执行以下过程:
数据生成器将执行以下操作,而不是始终用[MASK]替换所选单词:
80%的时间:用[MASK]标记替换单词,例如,my dog is hairy → my dog is [MASK]
10%的时间:用一个随机的单词替换该单词,例如,my dog is hairy → my dog is apple
10%的时间:保持单词不变,例如,my dog is hairy → my dog is hairy. 这样做的目的是将表示偏向于实际观察到的单词。
Transformer encoder不知道它将被要求预测哪些单词或哪些单词已被随机单词替换,因此它被迫保持每个输入token的分布式上下文表示。此外,因为随机替换只发生在所有token的1.5%(即15%的10%),这似乎不会损害模型的语言理解能力。
使用MLM的第二个缺点是每个batch只预测了15%的token,这表明模型可能需要更多的预训练步骤才能收敛。团队证明MLM的收敛速度略慢于 left-to-right的模型(预测每个token),但MLM模型在实验上获得的提升远远超过增加的训练成本。