
- github学习地址:https://github.com/datawhalechina/learn-nlp-with-transformers
自然语言处理(Natural Language Processing, NLP)是一种重要的人工智能(Artificial Intelligence, AI)技术。我们随处可以见到NLP技术的应用,比如网络搜索,广告,电子邮件,智能客服,机器翻译,智能新闻播报等等。最近几年,基于深度学习(Deep Learning, DL)的NLP技术在各项任务中取得了很好的效果,这些基于深度学习模型的NLP任务解决方案通常不使用传统的、特定任务的特征工程而是仅仅使用一个端到端(end-to-end)的神经网络模型就可以获得很好的效果。本教程将会基于最前沿的深度学习模型结构(transformers)来解决NLP里的几个经典任务。通过本教程的学习,我们将能够了解transformer相关原理、熟练使用transformer相关的深度学习模型来解决NLP里的实际问题以及在各类任务上取得很好的效果。
自然语言与深度学习的课程推荐:CS224n: Natural Language Processing with Deep Learning 自然语言处理的书籍推荐:Speech and Language Processing
常见的NLP任务
本教程将NLP任务划分为4个大类:1、文本分类, 2、序列标注,3、问答任务——抽取式问答和多选问答,4、生成任务——语言模型、机器翻译和摘要生成。
- 文本分类:对单个、两个或者多段文本进行分类。举例:“这个教程真棒!”这段文本的情感倾向是正向的,“我在学习transformer”和“如何学习transformer”这两段文本是相似的。
- 序列标注:对文本序列中的token、字或者词进行分类。举例:“我在国家图书馆学transformer。”这段文本中的国家图书馆是一个地点,可以被标注出来方便机器对文本的理解。
- 问答任务——抽取式问答和多选问答:1、抽取式问答根据问题从一段给定的文本中找到答案,答案必须是给定文本的一小段文字。举例:问题“小学要读多久?”和一段文本“小学教育一般是六年制。”,则答案是“六年”。2、多选式问答,从多个选项中选出一个正确答案。举例:“以下哪个模型结构在问答中效果最好?“和4个选项”A、MLP,B、cnn,C、lstm,D、transformer“,则答案选项是D。
- 生成任务——语言模型、机器翻译和摘要生成:根据已有的一段文字生成(generate)一个字通常叫做语言模型,根据一大段文字生成一小段总结性文字通常叫做摘要生成,将源语言比如中文句子翻译成目标语言比如英语通常叫做机器翻译。
虽然各种基于transformer的深度学习模型已经在多个人工构建的NLP任务中表现出色,但由于人类语言博大精深,深度学习模型依然有很长的路要走。
Transformer的兴起
2017年,Attention Is All You Need论文首次提出了Transformer模型结构并在机器翻译任务上取得了The State of the Art(SOTA, 最好)的效果。2018年,BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding使用Transformer模型结构进行大规模语言模型(language model)预训练(Pre-train),再在多个NLP下游(downstream)任务中进行微调(Finetune),一举刷新了各大NLP任务的榜单最高分,轰动一时。2019年-2021年,研究人员将Transformer这种模型结构和预训练+微调这种训练方式相结合,提出了一系列Transformer模型结构、训练方式的改进(比如transformer-xl,XLnet,Roberta等等)。如下图所示,各类Transformer的改进不断涌现。
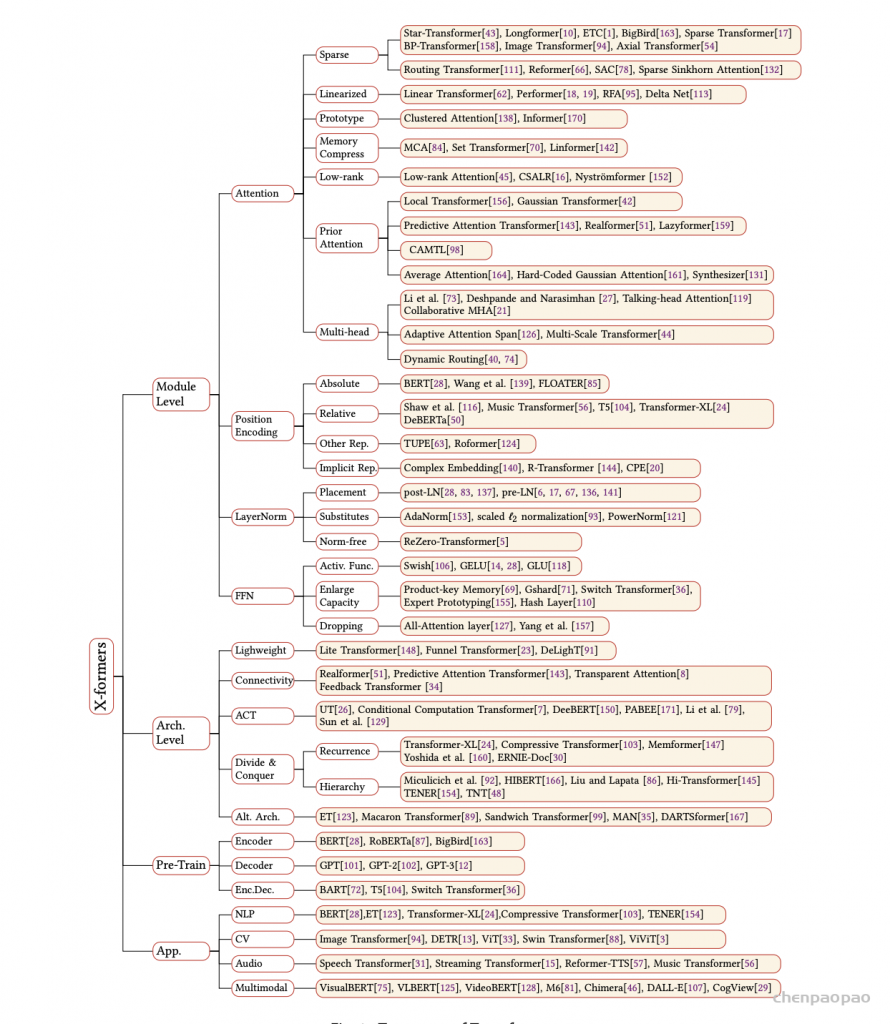
另外,由于Transformer优异的模型结构,使得其参数量可以非常庞大从而容纳更多的信息,因此Transformer模型的能力随着预训练不断提升,随着近几年计算能力的提升,越来越大的预训练模型以及效果越来越好的Transformers不断涌现,简单的统计可以从下图看出:
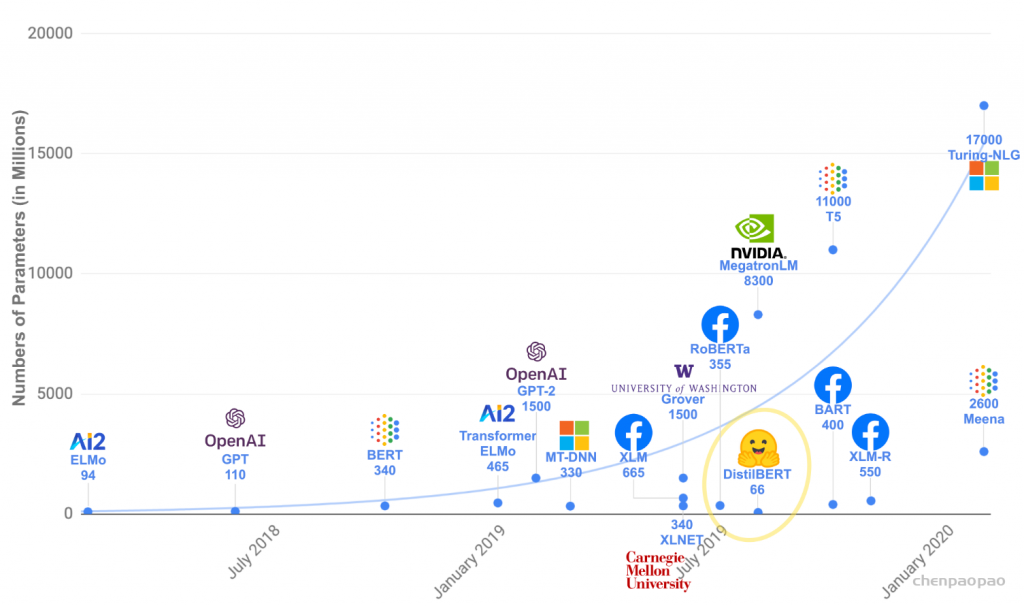
尽管各类Transformer的研究非常多,总体上经典和流行的Transformer模型都可以通过HuggingFace/Transformers, 48.9k Star获得和免费使用,为初学者、研究人员提供了巨大的帮助。
本教程也将基于HuggingFace/Transformers, 48.9k Star进行具体的编程和任务解决方案实现。
NLP中的预训练+微调的训练方式推荐阅读: 2021年如何科学的“微调”预训练模型? 和从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史