
论文: https://arxiv.org/abs/1505.04597

FCN虽然做出了开创性的工作,FCN-8s相较于此前的SOTA分割表现,已经取得了巨大的优势。但从分割效果上看还很粗糙,对图像的细节处理还很不成熟,也没有考虑到像素与像素之间的上下文(context)关系,所以FCN更像是一项抛砖引玉式的工作,随着U形的编解码结构成为通用的语义分割网络设计范式,各种网络如雨后春笋般涌现。UNet是U形网络结构最经典和最主要的代表网络,因其网络结构是一个U形而得名,这类编解码的结构也因而被称之为U形结构。提出UNet的论文为U-Net: Convolutional Networks for Biomedical Image Segmentation,与FCN提出时间相差了两个月,其结构设计在FCN基础上做了进一步的改进,设计初衷主要是用于医学图像的分割。截至到本书写稿,UNet在谷歌学术上的引用次数已达44772次,堪称深度学习语义分割领域的里程碑式的工作。
1、与FCN区别
U-Net和FCN非常的相似,U-Net比FCN稍晚提出来,但都发表在2015年,和FCN相比,U-Net的第一个特点是完全对称,也就是左边和右边是很类似的,而FCN的decoder相对简单,只用了一个deconvolution的操作,之后并没有跟上卷积结构。第二个区别就是skip connection,FCN用的是加操作(summation),U-Net用的是叠操作(concatenation)。这些都是细节,重点是它们的结构用了一个比较经典的思路,也就是编码和解码(encoder-decoder),早在2006年就被Hinton大神提出来发表在了nature上.
当时这个结构提出的主要作用并不是分割,而是压缩图像和去噪声。输入是一幅图,经过下采样的编码,得到一串比原先图像更小的特征,相当于压缩,然后再经过一个解码,理想状况就是能还原到原来的图像。这样的话我们存一幅图的时候就只需要存一个特征和一个解码器即可。这个想法我个人认为是很漂亮了。同理,这个思路也可以用在原图像去噪,做法就是在训练的阶段在原图人为的加上噪声,然后放到这个编码解码器中,目标是可以还原得到原图。
后来把这个思路被用在了图像分割的问题上,也就是现在我们看到的U-Net结构,在它被提出的三年中,有很多很多的论文去讲如何改进U-Net或者FCN,不过这个分割网络的本质的拓扑结构是没有改动的。举例来说,去年ICCV上凯明大神提出的Mask RCNN. 相当于一个检测,分类,分割的集大成者,我们仔细去看它的分割部分,其实使用的也就是这个简单的FCN结构。说明了这种“U形”的编码解码结构确实非常的简洁,并且最关键的一点是好用。
2、为什么有效
相比于FCN和Deeplab等,UNet共进行了4次上采样,并在同一个stage使用了skip connection,而不是直接在高级语义特征上进行监督和loss反传,这样就保证了最后恢复出来的特征图融合了更多的low-level的feature,也使得不同scale的feature得到了的融合,从而可以进行多尺度预测和DeepSupervision。4次上采样也使得分割图恢复边缘等信息更加精细。
其次我们聊聊【医疗影像】,医疗影像有什么样的特点呢(尤其是相对于自然影像而言)?
1.图像语义较为简单、结构较为固定。我们做脑的,就用脑CT和脑MRI,做胸片的只用胸片CT,做眼底的只用眼底OCT,都是一个固定的器官的成像,而不是全身的。由于器官本身结构固定和语义信息没有特别丰富,所以高级语义信息和低级特征都显得很重要(UNet的skip connection和U型结构就派上了用场)。
2.数据量少。医学影像的数据获取相对难一些,很多比赛只提供不到100例数据。所以我们设计的模型不宜多大,参数过多,很容易导致过拟合。
原始UNet的参数量在28M左右(上采样带转置卷积的UNet参数量在31M左右),而如果把channel数成倍缩小,模型可以更小。缩小两倍后,UNet参数量在7.75M。缩小四倍,可以把模型参数量缩小至2M以内,非常轻量。个人尝试过使用Deeplab v3+和DRN等自然图像语义分割的SOTA网络在自己的项目上,发现效果和UNet差不多,但是参数量会大很多。
为什么适用于医学图像?
(1)因为医学图像边界模糊、梯度复杂,需要较多的高分辨率信息。高分辨率用于精准分割。
(2)人体内部结构相对固定,分割目标在人体图像中的分布很具有规律,语义简单明确,低分辨率信息能够提供这一信息,用于目标物体的识别。
UNet结合了低分辨率信息(提供物体类别识别依据)和高分辨率信息(提供精准分割定位依据),完美适用于医学图像分割。
网络结构
在医学图像领域,具体到更加细分的医学图像识别任务时,大量的带有高质量标注的图像数据十分难得,在此之前的通常做法是采用滑动窗口卷积(类似于图像分块)的方式来进行图像局部预测,这么做的好处是可以做图像像素做到一定程度定位,其次就是滑窗分块能够使得训练样本量增多。但缺点也很明显,一个是滑窗操作非常耗时,推理的时候效率低下,其次就是不能兼顾定位精度和像素上下文信息的利用率。UNet在FCN的基础上,完整地给出了U形的编解码结构,如下图所示
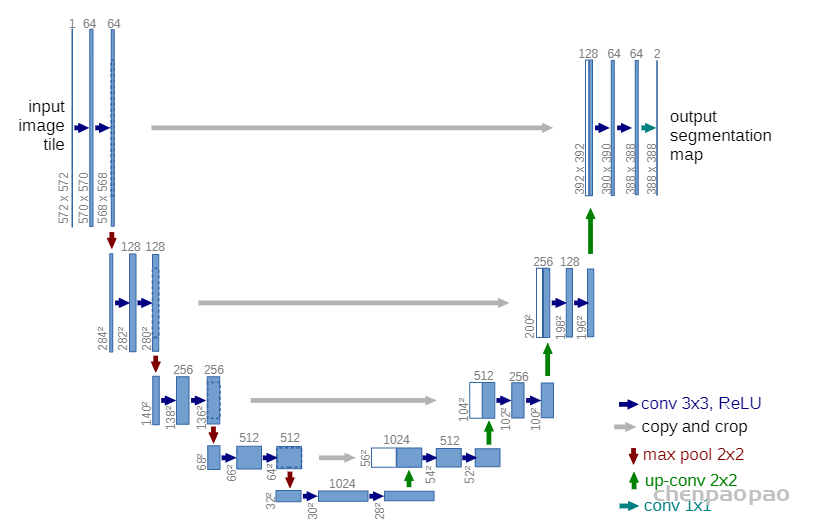
输入是一幅图,输出是目标的分割结果。继续简化就是,一幅图,编码,或者说降采样,然后解码,也就是升采样,然后输出一个分割结果。根据结果和真实分割的差异,反向传播来训练这个分割网络。我们可以说,U-Net里面最精彩的部分就是这三部分:
- 下采样
- 上采样
- skip connection
UNet结构包括编码器下采样、解码器上采样和同层跳跃连接三个组成部分。编码器由4组卷积、ReLU激活和最大池化构成,每一组均有两次3*3的卷积,每个卷积层后面都有一次ReLU激活函数,然后再进行一次步长为2的2*2最大池化进行下采样,如第一组操作输入图像大小为572*572,两轮3*3的卷积之后的特征图大小为568*568,再经过22最大池化后的输出尺寸为284*284。解码器由4组2*2转置卷积、3*3卷积构成和一个ReLU激活函数构成,在最后的输出层又补充了一个1*1卷积。最后是同层跳跃连接,这也是UNet的特色操作之一,指的是将下采样时每一层的输出裁剪后连接到同层的上采样层做融合。每一次下采样都会有一个跳跃连接与对应的上采样进行融合,这种不同尺度的特征融合对上采样恢复像素大有帮助,具体来说就是高层(浅层)下采样倍数小,特征图具备更加细致的图特征,低层(深层)下采样倍数大,信息经过大量浓缩,空间损失大,但有助于目标区域(分类)判断,当高层和低层的特征进行融合时,分割效果往往会非常好。从某种程度上讲,这种跳跃连接也可以视为一种深度监督。
我们将UNet结构按照编码器、解码器和同层跳跃连接进行简化,如下图所示。编码器下采样用于特征提取和语义信息浓缩,解码器上采样用于图像像素恢复,跳跃连接则用于信息补充。自此,基于U形结构的编解码设计成为深度学习语义分割中的奠基性的网络结构,经过近几年的发展,语义分割虽然取得了长足的进步,但UNet和编解码结构一直是新的模型设计的参照对象。
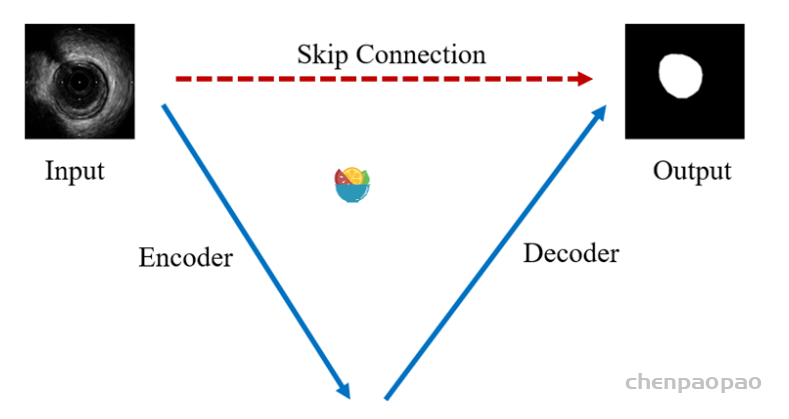
代码实现:
# 导入PyTorch相关模块
import torch
import torch.nn as nn
import torch.nn.functional as F
### 编码块
class UNetEnc(nn.Module):
def __init__(self, in_channels, out_channels, dropout=False):
super().__init__()
# 每一个编码块中的结构
layers = [
nn.Conv2d(in_channels, out_channels, 3, dilation=2),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, dilation=2),
nn.ReLU(inplace=True),
]
if dropout:
layers += [nn.Dropout(.5)]
layers += [nn.MaxPool2d(2, stride=2, ceil_mode=True)]
self.down = nn.Sequential(*layers)
# 编码块前向计算流程
def forward(self, x):
return self.down(x)
### 解码块
class UNetDec(nn.Module):
def __init__(self, in_channels, features, out_channels):
super().__init__()
# 每一个解码块中的结构
self.up = nn.Sequential(
nn.Conv2d(in_channels, features, 3),
nn.ReLU(inplace=True),
nn.Conv2d(features, features, 3),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(features, out_channels, 2, stride=2),
nn.ReLU(inplace=True),
)
# 解码块前向计算流程
def forward(self, x):
return self.up(x)
### 基于编解码的U-Net
class UNet(nn.Module):
def __init__(self, num_classes):
super().__init__()
# 四个编码块
self.enc1 = UNetEnc(3, 64)
self.enc2 = UNetEnc(64, 128)
self.enc3 = UNetEnc(128, 256)
self.enc4 = UNetEnc(256, 512, dropout=True)
# 中间部分(U形底部)
self.center = nn.Sequential(
nn.Conv2d(512, 1024, 3),
nn.ReLU(inplace=True),
nn.Conv2d(1024, 1024, 3),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.ConvTranspose2d(1024, 512, 2, stride=2),
nn.ReLU(inplace=True),
)
# 四个解码块
self.dec4 = UNetDec(1024, 512, 256)
self.dec3 = UNetDec(512, 256, 128)
self.dec2 = UNetDec(256, 128, 64)
self.dec1 = nn.Sequential(
nn.Conv2d(128, 64, 3),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, 3),
nn.ReLU(inplace=True),
)
self.final = nn.Conv2d(64, num_classes, 1)
# 前向传播过程
def forward(self, x):
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
enc4 = self.enc4(enc3)
center = self.center(enc4)
# 包含了同层分辨率级联的解码块
dec4 = self.dec4(torch.cat([
center, F.upsample_bilinear(enc4, center.size()[2:])], 1))
dec3 = self.dec3(torch.cat([
dec4, F.upsample_bilinear(enc3, dec4.size()[2:])], 1))
dec2 = self.dec2(torch.cat([
dec3, F.upsample_bilinear(enc2, dec3.size()[2:])], 1))
dec1 = self.dec1(torch.cat([
dec2, F.upsample_bilinear(enc1, dec2.size()[2:])], 1))
return F.upsample_bilinear(self.final(dec1), x.size()[2:])