
论文地址: https://arxiv.org/abs/1706.05587

Deeplab v3是v2版本的进一步升级,作者们在对空洞卷积重新思考的基础上,进一步对Deeplab系列的基本框架进行了优化,去掉了v1和v2版本中一直坚持的CRF后处理模块,升级了主干网络和ASPP模块,使得网络能够更好地处理语义分割中的多尺度问题。提出Deeplab v3的论文为Rethinking Atrous Convolution for Semantic Image Segmentation,是Deeplab系列后期网络的代表模型。
DeepLab V3的改进主要包括以下几方面:
1)提出了更通用的框架,适用于任何网络
2)复制了ResNet最后的block,并级联起来
3)在ASPP中使用BN层
4)去掉了CRF
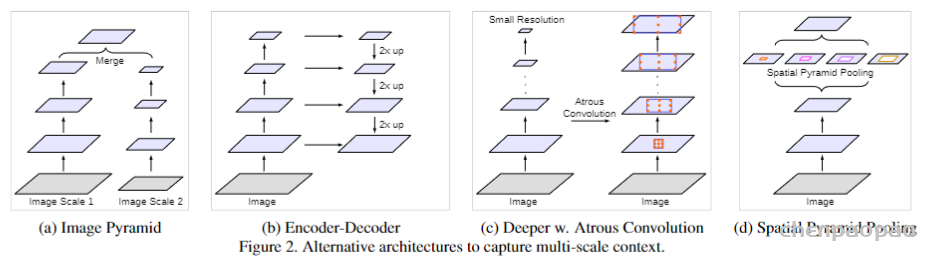
随着语义分割的发展,逐渐有两大问题亟待解决:一个是连续的池化和卷积步长导致的下采样图像信息丢失问题,这个问题已经通过空洞卷积扩大感受野得到比较好的处理;另外一个则是多尺度和利用上下文信息问题。论文中分别回顾了四种基于多尺度和上下文信息进行语义分割的方法,如图1所示,包括图像金字塔、编解码架构、深度空洞卷积网络以及空间金字塔池化,这四种方法各有优缺点,ASPP可以算是深度空洞卷积和空间金字塔池化的一种结合,Deeplab v3在v2的ASPP基础上,进一步探索了空洞卷积在多尺度和上下文信息中的作用。
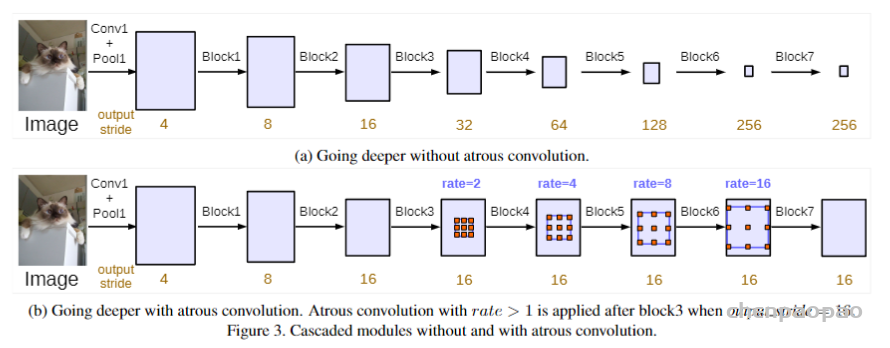
Deeplab v3可作为通用框架融入到任意网络结构中,具体地,以串行方式设计空洞卷积模块,复制ResNet的最后一个卷积块,并将复制后的卷积块以串行方式进行级联,如图2所示。DeepLab V3将空洞卷积应用在级联模块。具体来说,我们取ResNet中最后一个block,在下图中为block4,并在其后面增加级联模块。
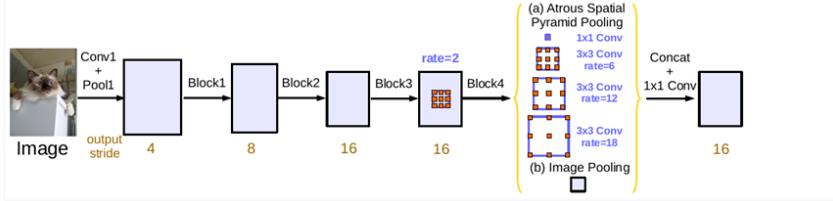
在卷积块串行级联基础上,Deeplab v3又对ASPP模块进行并行级联,v3对ASPP模块进行了升级,相较于v2版本加入了批归一化(Batch Normalization,BN),通过组织不同的空洞扩张率的卷积块,同时加入图像级特征,能够更好地捕捉多尺度上下文信息,并且也能够更容易训练,如图3所示。
1)ASPP中应用了BN层
2)随着采样率的增加,滤波器中有效的权重减少了(有效权重减少,难以捕获原距离信息,这要求合理控制采样率的设置)
3)使用模型最后的特征映射的全局平均池化(为了克服远距离下有效权重减少的问题)
总结来看,Deeplab v3更充分的利用了空洞卷积来获取大范围的图像上下文信息。具体包括:多尺度信息编码、带有逐步翻倍的空洞扩张率的级联模块以及带有图像级特征的ASPP模块。实验结果表明,该模型在 PASCAL VOC数据集上相较于v2版本有了显着进步,取得了当时SOTA精度水平。
Deeplab v3的PyTorch实现可参考:
https://github.com/pytorch/vision/blob/main/torchvision/models/segmentation/deeplabv3.py
代码实现:
class DeeplabV3(ResNet):
def __init__(self, n_class, block, layers, pyramids, grids, output_stride=16):
self.inplanes = 64
super(DeeplabV3, self).__init__()
if output_stride == 16:
strides = [1, 2, 2, 1]
rates = [1, 1, 1, 2]
elif output_stride == 8:
strides = [1, 2, 1, 1]
rates = [1, 1, 2, 2]
else:
raise NotImplementedError
# Backbone Modules
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # h/4, w/4
self.layer1 = self._make_layer(block, 64, layers[0], stride=strides[0], rate=rates[0]) # h/4, w/4
self.layer2 = self._make_layer(block, 128, layers[1], stride=strides[1], rate=rates[1]) # h/8, w/8
self.layer3 = self._make_layer(block, 256, layers[2], stride=strides[2], rate=rates[2]) # h/16,w/16
self.layer4 = self._make_MG_unit(block, 512, blocks=grids, stride=strides[3], rate=rates[3])# h/16,w/16
# Deeplab Modules
self.aspp1 = ASPP_module(2048, 256, rate=pyramids[0])
self.aspp2 = ASPP_module(2048, 256, rate=pyramids[1])
self.aspp3 = ASPP_module(2048, 256, rate=pyramids[2])
self.aspp4 = ASPP_module(2048, 256, rate=pyramids[3])
self.global_avg_pool = nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)),
nn.Conv2d(2048, 256, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU())
# get result features from the concat
self._conv1 = nn.Sequential(nn.Conv2d(1280, 256, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU())
# generate the final logits
self._conv2 = nn.Conv2d(256, n_class, kernel_size=1, bias=False)
self.init_weight()
def forward(self, input):
x = self.conv1(input)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x1 = self.aspp1(x)
x2 = self.aspp2(x)
x3 = self.aspp3(x)
x4 = self.aspp4(x)
# image-level features
x5 = self.global_avg_pool(x)
x5 = F.upsample(x5, size=x4.size()[2:], mode='bilinear', align_corners=True)
x = torch.cat((x1, x2, x3, x4, x5), dim=1)
x = self._conv1(x)
x = self._conv2(x)
x = F.upsample(x, size=input.size()[2:], mode='bilinear', align_corners=True)
return x其中重要的_makelayer, _make_MG_unit和ASSP模块实现如下:
def _make_layer(self, block, planes, blocks, stride=1, rate=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, rate, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def _make_MG_unit(self, block, planes, blocks=[1, 2, 4], stride=1, rate=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, rate=blocks[0] * rate, downsample=downsample))
self.inplanes = planes * block.expansion
for i in range(1, len(blocks)):
layers.append(block(self.inplanes, planes, stride=1, rate=blocks[i] * rate))
return nn.Sequential(*layers)
class ASPP_module(nn.Module):
def __init__(self, inplanes, planes, rate):
super(ASPP_module, self).__init__()
if rate == 1:
kernel_size = 1
padding = 0
else:
kernel_size = 3
padding = rate
self.atrous_convolution = nn.Conv2d(inplanes, planes, kernel_size=kernel_size,
stride=1, padding=padding, dilation=rate, bias=False)
self.bn = nn.BatchNorm2d(planes)
self.relu = nn.ReLU()
self._init_weight()
def forward(self, x):
x = self.atrous_convolution(x)
x = self.bn(x)
return self.relu(x)
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()训练策略:
Crop size:
- 为了大采样率的空洞卷积能够有效,需要较大的图片大小;否则,大采样率的空洞卷积权值就会主要用于padding区域。
- 在Pascal VOC 2012数据集的训练和测试中我们采用了513的裁剪尺寸。
Batch normalization:
- 我们在ResNet之上添加的模块都包括BN层
- 当output_stride=16时,采用batchsize=16,同时BN层的参数做参数衰减0.9997。
- 在增强的数据集上,以初始学习率0.007训练30K后,冻结BN层参数,然后采用output_stride=8,再使用初始学习率0.001在PASCAL官方的数据集上训练30K。
- 训练output_stride=16比output_stride=8要快很多,因为其中间的特征映射在空间上小四倍。但output_stride=16在特征映射上相对粗糙,快是因为牺牲了精度。
Upsampling logits:
- 在先前的工作上,我们是将output_stride=8的输出与Ground Truth下采样8倍做比较。
- 现在我们发现保持Ground Truth更重要,故我们是将最终的输出上采样8倍与完整的Ground Truth比较。
Data augmentation:
在训练阶段,随机缩放输入图像(从0.5到2.0)和随机左-右翻转