
论文(2015):SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
Github:https://github.com/alexgkendall/caffe-segnet

- 把本文提出的架构和FCN、DeepLab-LargeFOV、DeconvNet做了比较,这种比较揭示了在实现良好分割性能的前提下内存使用情况与分割准确性的权衡。
- SegNet的主要动机是场景理解的应用。因此它在设计的时候考虑了要在预测期间保证内存和计算时间上的效率。
- 定量的评估表明,SegNet在和其他架构的比较上,时间和内存的使用都比较高效。
SegNet论文提出了max pooling的改进版,使用该pooling操作既可以进行下采样操作,也可以进行上采样操作。在下采样操作中同时输出pooling后的结果和pooling过程中的索引。在上采样操作中,利用下采样对应位置的索引,进行上采样操作,这样的优势在于记住了最亮特征像素的空间位置。(去除了unet里面的反卷积操作)
优点,
- 可以提高物体边界的分割效果
- 相比反卷积操作,减少了参数数量,减少了运算量,相比resize操作,减少了插值的运算量,而实际增加的索引参数也很少。
- 该pooling操作可以应用于任何基于编码-解码的分割模型。
SegNet网络结构如下图所示,是一个编解码完全对称的结构。其编码器直接用了VGG16的结构,并将全连接层全部改为卷积层,实际训练时可使用VGG16的预训练权重进行初始化;编码器将13层卷积层分为5组卷积块,每组卷积块之间用最大池化层进行下采样。作为一个对称结构,SegNet解码器也有13层卷积层,同样分为5组卷积块,每组卷积块之间用双线性插值和最大池化位置索引进行上采样,这也是SegNet最大的特色。
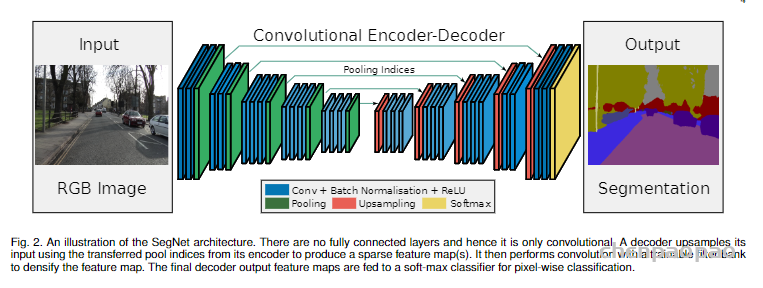
SegNet研究团队认为编码器下采样过程中图像信息损失较多,直接存储所有卷积块的特征图又非常占用内存,因而在SegNet中提出在每一次最大池化下采样前存储最大池化的位置索引(Max-pooling indices),即记住最大池化操作中,最大值在2*2池化窗口中的位置。每个2*2窗口仅需要2 bits内存存储量,这种池化位置索引可用于上采样解码时恢复图像信息。下图给出了SegNet与FCN之间的上采样方法对比。可以观察到,SegNet使用双线性插值并结合最大池化位置索引进行上采样,而FCN则是基于去卷积结合编码器卷积特征图进行上采样。
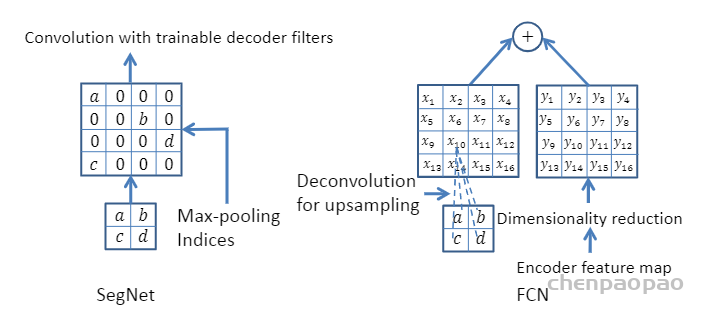
SegNet这种轻量化的上采样方式,不仅能够提升图像边界分割效果,在端到端的实时分割项目中速度也非常快,并且这种结构设计可以配置到任意的编解码网络中,是一种优秀的分割网络设计方式。下述代码给出了SegNet的一个简易的结构实现,因为SegNet解码器的特殊性,我们单独定义了一个解码器类,编码器部分直接使用VGG16的预训练权重层,然后在编解码器基础上搭建SegNet并定义前向计算流程。
# 导入PyTorch相关模块
import torch
import torch.nn as nn
import torch.nn.init as init
import torch.nn.functional as F
from torchvision import models
# 定义SegNet解码器类
class SegNetDec(nn.Module):
def __init__(self, in_channels, out_channels, num_layers):
super().__init__()
layers = [
nn.Conv2d(in_channels, in_channels // 2, 3, padding=1),
nn.BatchNorm2d(in_channels // 2),
nn.ReLU(inplace=True),
]
layers += [
nn.Conv2d(in_channels // 2, in_channels // 2, 3, padding=1),
nn.BatchNorm2d(in_channels // 2),
nn.ReLU(inplace=True),
] * num_layers
layers += [
nn.Conv2d(in_channels // 2, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
]
self.decode = nn.Sequential(*layers)
def forward(self, x):
return self.decode(x)
### 定义SegNet类
class SegNet(nn.Module):
def __init__(self, classes):
super().__init__()
# 编码器使用vgg16预训练权重
vgg16 = models.vgg16(pretrained=True)
features = vgg16.features
self.enc1 = features[0: 4]
self.enc2 = features[5: 9]
self.enc3 = features[10: 16]
self.enc4 = features[17: 23]
self.enc5 = features[24: -1]
# 编码器卷积层不参与训练
for m in self.modules():
if isinstance(m, nn.Conv2d):
m.requires_grad = False
self.dec5 = SegNetDec(512, 512, 1)
self.dec4 = SegNetDec(512, 256, 1)
self.dec3 = SegNetDec(256, 128, 1)
self.dec2 = SegNetDec(128, 64, 0)
self.final = nn.Sequential(*[
nn.Conv2d(64, classes, 3, padding=1),
nn.BatchNorm2d(classes),
nn.ReLU(inplace=True)
])
# 定义SegNet前向计算流程
def forward(self, x):
x1 = self.enc1(x)
e1, m1 = F.max_pool2d(x1, kernel_size=2, stride=2,
return_indices=True)
x2 = self.enc2(e1)
e2, m2 = F.max_pool2d(x2, kernel_size=2, stride=2,
return_indices=True)
x3 = self.enc3(e2)
e3, m3 = F.max_pool2d(x3, kernel_size=2, stride=2,
return_indices=True)
x4 = self.enc4(e3)
e4, m4 = F.max_pool2d(x4, kernel_size=2, stride=2,
return_indices=True)
x5 = self.enc5(e4)
e5, m5 = F.max_pool2d(x5, kernel_size=2, stride=2,
return_indices=True)
def upsample(d):
d5 = self.dec5(F.max_unpool2d(d, m5, kernel_size=2,
stride=2, output_size=x5.size()))
d4 = self.dec4(F.max_unpool2d(d5, m4, kernel_size=2,
stride=2, output_size=x4.size()))
d3 = self.dec3(F.max_unpool2d(d4, m3, kernel_size=2,
stride=2, output_size=x3.size()))
d2 = self.dec2(F.max_unpool2d(d3, m2, kernel_size=2,
stride=2, output_size=x2.size()))
d1 = F.max_unpool2d(d2, m1, kernel_size=2, stride=2,
output_size=x1.size())
return d1
d = upsample(e5)
return self.final(d)