
这两个都是用在rpn之后的。具体来说,从feature map上经过RPN得到一系列的proposals,大概2k个,这些bbox大小不等,如何将这些bbox的特征进行统一表示就变成了一个问题。即需要找一个办法从大小不等的框中提取特征使输出结果是等长的。
最开始目标检测模型Faster RCNN中用了一个简单粗暴的办法,叫ROI Pooling。
该方式在语义分割这种精细程度高的任务中,不够精准,由此发展来了ROI Align。
今天就总结下两者的思想。
ROI Pooling
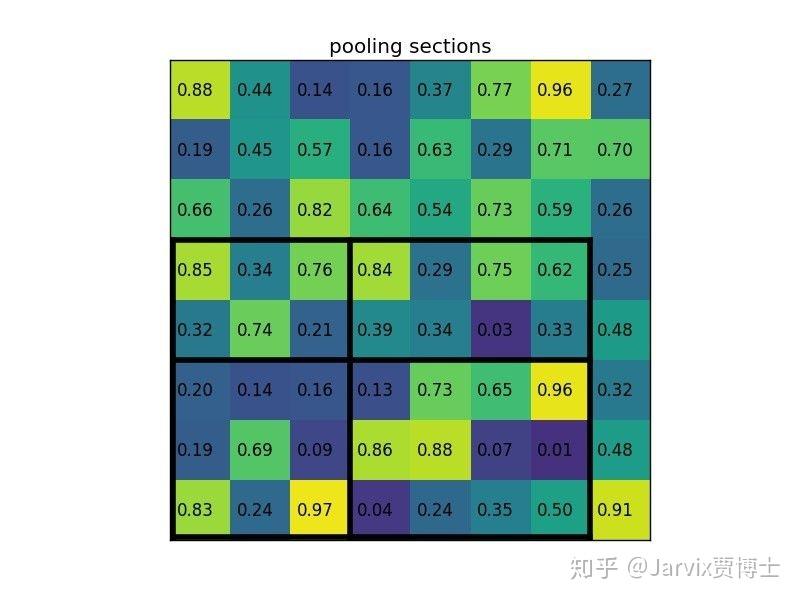
假如现在有一个8×8的feature map,现在希望得到2×2的输出,有一个bbox坐标为[0,3,7,8]。
这个bbox的w=7,h=5,如果要等分成四块是做不到的,因此在ROI Pooling中会进行取整。就有了上图看到的h被分割为2,3,w被分割成3,4。这样之后在每一块(称为bin)中做max pooling,可以得到下图的结果。
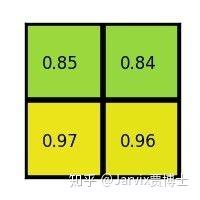
这样就可以将任意大小bbox转成2×2表示的feature。
ROI Pooling需要取整,这样的取整操作进行了两次,一次是得到bbox在feature map上的坐标时。
例如:原图上的bbox大小为665×665,经backbone后,spatial scale=1/32。因此bbox也相应应该缩小为665/32=20.78,但是这并不是一个真实的pixel所在的位置,因此这一步会取为20。0.78的差距反馈到原图就是0.78×32=25个像素的差距。如果是大目标这25的差距可能看不出来,但对于小目标而言差距就比较巨大了。

ROI Align
因此有人提出不需要进行取整操作,如果计算得到小数,也就是没有落到真实的pixel上,那么就用最近的pixel对这一点虚拟pixel进行双线性插值,得到这个“pixel”的值。
具体做法如下图所示:

- 将bbox区域按输出要求的size进行等分,很可能等分后各顶点落不到真实的像素点上
- 没关系,在每个bin中再取固定的4个点(作者实验后发现取4效果较好),也就是图二右侧的蓝色点
- 针对每一个蓝点,距离它最近的4个真实像素点的值加权(双线性插值),求得这个蓝点的值
- 一个bin内会算出4个新值,在这些新值中取max,作为这个bin的输出值
- 最后就能得到2×2的输出