
《Generalizing from a Few Examples: A Survey on Few-Shot Learning》https://arxiv.org/pdf/1904.05046.pdf
作者提供了对应的github仓库:https://github.com/tata1661/FewShotPapers
这个仓库主要包含:
- FewShotPapers:跟踪 FSL 研究进展的论文列表
- PaddleFSL : 一个基于 Paddle 的 FSL python 库


《Generalizing from a Few Examples: A Survey on Few-Shot Learning》https://arxiv.org/pdf/1904.05046.pdf
作者提供了对应的github仓库:https://github.com/tata1661/FewShotPapers
这个仓库主要包含:
论文(2015):SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
Github:https://github.com/alexgkendall/caffe-segnet

SegNet论文提出了max pooling的改进版,使用该pooling操作既可以进行下采样操作,也可以进行上采样操作。在下采样操作中同时输出pooling后的结果和pooling过程中的索引。在上采样操作中,利用下采样对应位置的索引,进行上采样操作,这样的优势在于记住了最亮特征像素的空间位置。(去除了unet里面的反卷积操作)
优点,
SegNet网络结构如下图所示,是一个编解码完全对称的结构。其编码器直接用了VGG16的结构,并将全连接层全部改为卷积层,实际训练时可使用VGG16的预训练权重进行初始化;编码器将13层卷积层分为5组卷积块,每组卷积块之间用最大池化层进行下采样。作为一个对称结构,SegNet解码器也有13层卷积层,同样分为5组卷积块,每组卷积块之间用双线性插值和最大池化位置索引进行上采样,这也是SegNet最大的特色。
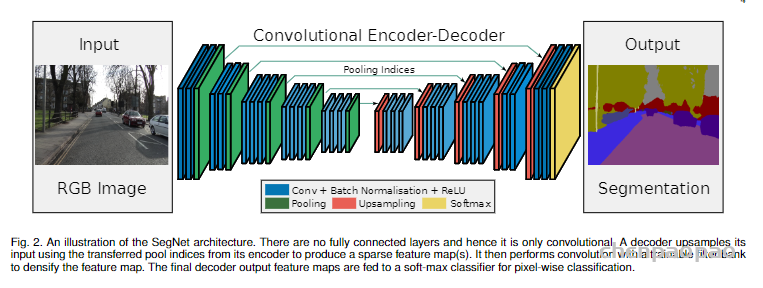
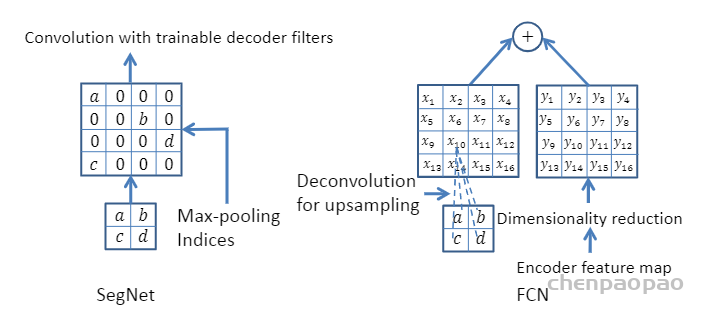
SegNet研究团队认为编码器下采样过程中图像信息损失较多,直接存储所有卷积块的特征图又非常占用内存,因而在SegNet中提出在每一次最大池化下采样前存储最大池化的位置索引(Max-pooling indices),即记住最大池化操作中,最大值在2*2池化窗口中的位置。每个2*2窗口仅需要2 bits内存存储量,这种池化位置索引可用于上采样解码时恢复图像信息。下图给出了SegNet与FCN之间的上采样方法对比。可以观察到,SegNet使用双线性插值并结合最大池化位置索引进行上采样,而FCN则是基于去卷积结合编码器卷积特征图进行上采样。
SegNet这种轻量化的上采样方式,不仅能够提升图像边界分割效果,在端到端的实时分割项目中速度也非常快,并且这种结构设计可以配置到任意的编解码网络中,是一种优秀的分割网络设计方式。下述代码给出了SegNet的一个简易的结构实现,因为SegNet解码器的特殊性,我们单独定义了一个解码器类,编码器部分直接使用VGG16的预训练权重层,然后在编解码器基础上搭建SegNet并定义前向计算流程。
# 导入PyTorch相关模块
import torch
import torch.nn as nn
import torch.nn.init as init
import torch.nn.functional as F
from torchvision import models
# 定义SegNet解码器类
class SegNetDec(nn.Module):
def __init__(self, in_channels, out_channels, num_layers):
super().__init__()
layers = [
nn.Conv2d(in_channels, in_channels // 2, 3, padding=1),
nn.BatchNorm2d(in_channels // 2),
nn.ReLU(inplace=True),
]
layers += [
nn.Conv2d(in_channels // 2, in_channels // 2, 3, padding=1),
nn.BatchNorm2d(in_channels // 2),
nn.ReLU(inplace=True),
] * num_layers
layers += [
nn.Conv2d(in_channels // 2, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
]
self.decode = nn.Sequential(*layers)
def forward(self, x):
return self.decode(x)
### 定义SegNet类
class SegNet(nn.Module):
def __init__(self, classes):
super().__init__()
# 编码器使用vgg16预训练权重
vgg16 = models.vgg16(pretrained=True)
features = vgg16.features
self.enc1 = features[0: 4]
self.enc2 = features[5: 9]
self.enc3 = features[10: 16]
self.enc4 = features[17: 23]
self.enc5 = features[24: -1]
# 编码器卷积层不参与训练
for m in self.modules():
if isinstance(m, nn.Conv2d):
m.requires_grad = False
self.dec5 = SegNetDec(512, 512, 1)
self.dec4 = SegNetDec(512, 256, 1)
self.dec3 = SegNetDec(256, 128, 1)
self.dec2 = SegNetDec(128, 64, 0)
self.final = nn.Sequential(*[
nn.Conv2d(64, classes, 3, padding=1),
nn.BatchNorm2d(classes),
nn.ReLU(inplace=True)
])
# 定义SegNet前向计算流程
def forward(self, x):
x1 = self.enc1(x)
e1, m1 = F.max_pool2d(x1, kernel_size=2, stride=2,
return_indices=True)
x2 = self.enc2(e1)
e2, m2 = F.max_pool2d(x2, kernel_size=2, stride=2,
return_indices=True)
x3 = self.enc3(e2)
e3, m3 = F.max_pool2d(x3, kernel_size=2, stride=2,
return_indices=True)
x4 = self.enc4(e3)
e4, m4 = F.max_pool2d(x4, kernel_size=2, stride=2,
return_indices=True)
x5 = self.enc5(e4)
e5, m5 = F.max_pool2d(x5, kernel_size=2, stride=2,
return_indices=True)
def upsample(d):
d5 = self.dec5(F.max_unpool2d(d, m5, kernel_size=2,
stride=2, output_size=x5.size()))
d4 = self.dec4(F.max_unpool2d(d5, m4, kernel_size=2,
stride=2, output_size=x4.size()))
d3 = self.dec3(F.max_unpool2d(d4, m3, kernel_size=2,
stride=2, output_size=x3.size()))
d2 = self.dec2(F.max_unpool2d(d3, m2, kernel_size=2,
stride=2, output_size=x2.size()))
d1 = F.max_unpool2d(d2, m1, kernel_size=2, stride=2,
output_size=x1.size())
return d1
d = upsample(e5)
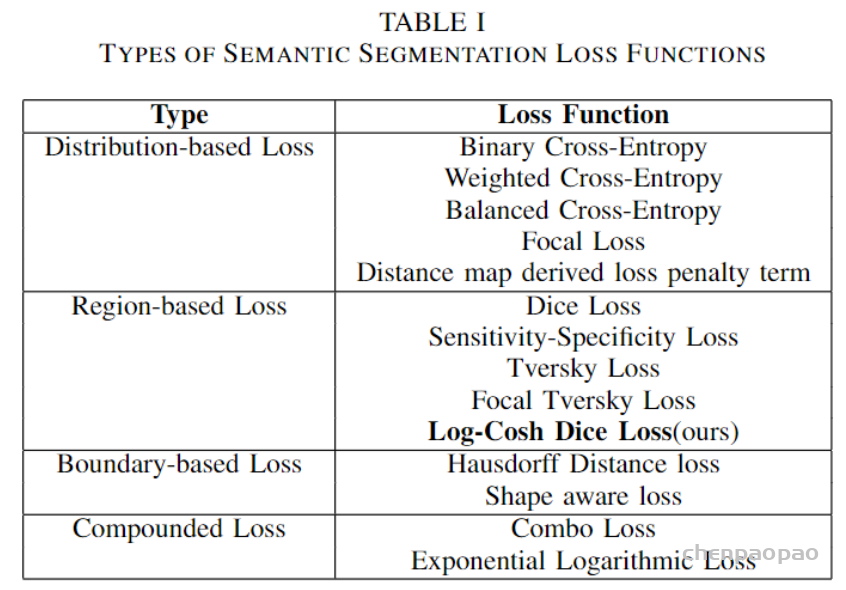
return self.final(d)汇总语义分割中常用的损失函数:
参考论文:Medical Image Segmentation Using Deep Learning:A Survey
论文地址:A survey of loss functions for semantic segmentation
代码地址:https://github.com/shruti-jadon/Semantic-Segmentation-Loss-Functions
项目推荐:https://github.com/JunMa11/SegLoss
图像分割一直是一个活跃的研究领域,因为它有可能修复医疗领域的漏洞,并帮助大众。在过去的5年里,各种论文提出了不同的目标损失函数,用于不同的情况下,如偏差数据,稀疏分割等。
图像分割可以定义为像素级别的分类任务。图像由各种像素组成,这些像素组合在一起定义了图像中的不同元素,因此将这些像素分类为一类元素的方法称为语义图像分割。在设计基于复杂图像分割的深度学习架构时,通常会遇到了一个至关重要的选择,即选择哪个损失/目标函数,因为它们会激发算法的学习过程。损失函数的选择对于任何架构学习正确的目标都是至关重要的,因此自2012年以来,各种研究人员开始设计针对特定领域的损失函数,以为其数据集获得更好的结果。
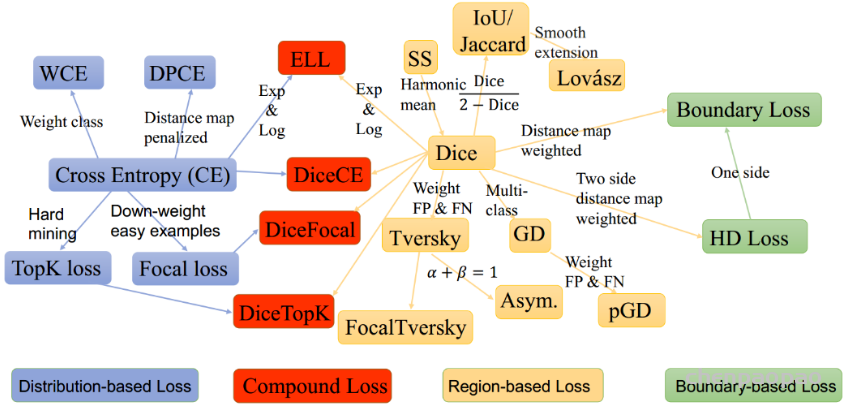
这些损失函数可大致分为4类:基于分布的损失函数,基于区域的损失函数,基于边界的损失函数和基于复合的损失函数( Distribution-based,Region-based, Boundary-based, and Compounded)。
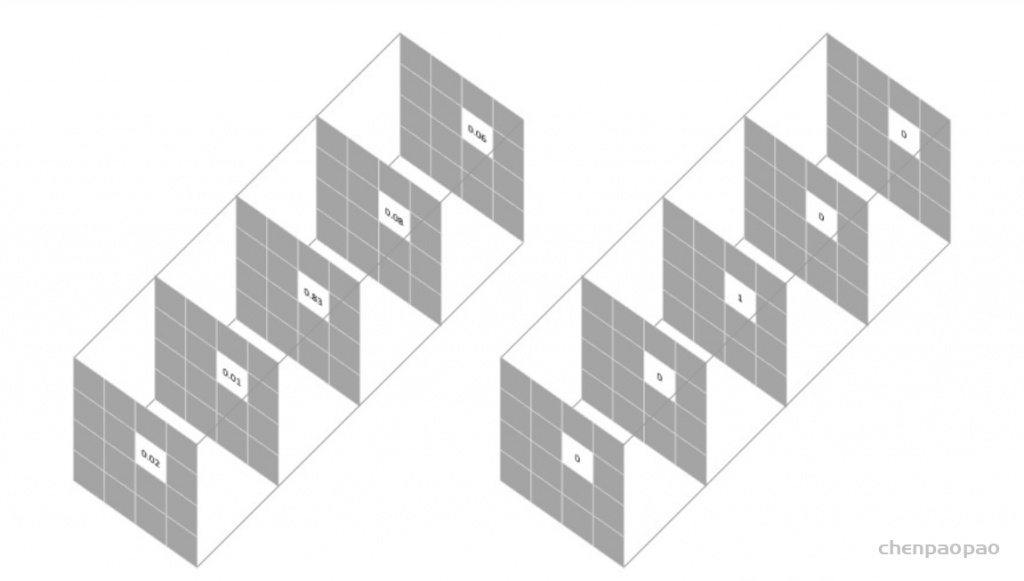
用于图像语义分割任务的最常用损失函数是像素级别的交叉熵损失,这种损失会逐个检查每个像素,将对每个像素类别的预测结果(概率分布向量)与我们的独热编码标签向量进行比较。
假设我们需要对每个像素的预测类别有5个,则预测的概率分布向量长度为5:
每个像素对应的损失函数为:
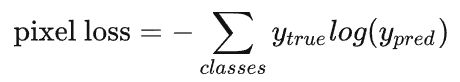
整个图像的损失就是对每个像素的损失求平均值。
特别注意的是,binary entropy loss 是针对类别只有两个的情况,简称 bce loss,损失函数公式为:
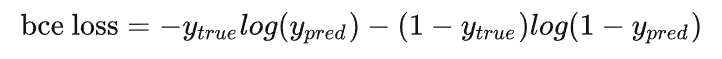
#二值交叉熵,这里输入要经过sigmoid处理
import torch
import torch.nn as nn
import torch.nn.functional as F
nn.BCELoss(F.sigmoid(input), target)
#多分类交叉熵, 用这个 loss 前面不需要加 Softmax 层
nn.CrossEntropyLoss(input, target)由于交叉熵损失会分别评估每个像素的类别预测,然后对所有像素的损失进行平均,因此我们实质上是在对图像中的每个像素进行平等地学习。如果多个类在图像中的分布不均衡,那么这可能导致训练过程由像素数量多的类所主导,即模型会主要学习数量多的类别样本的特征,并且学习出来的模型会更偏向将像素预测为该类别。
FCN论文和U-Net论文中针对这个问题,对输出概率分布向量中的每个值进行加权,即希望模型更加关注数量较少的样本,以缓解图像中存在的类别不均衡问题。
比如对于二分类,正负样本比例为1: 99,此时模型将所有样本都预测为负样本,那么准确率仍有99%这么高,但其实该模型没有任何使用价值。
为了平衡这个差距,就对正样本和负样本的损失赋予不同的权重,带权重的二分类损失函数公式如下:
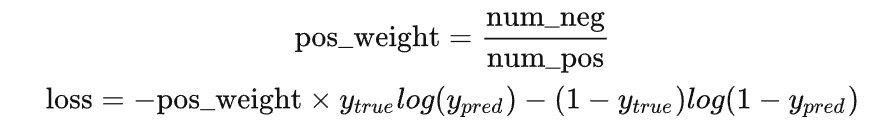
要减少假阴性样本的数量,可以增大 pos_weight;要减少假阳性样本的数量,可以减小 pos_weight。
class WeightedCrossEntropyLoss(torch.nn.CrossEntropyLoss):
"""
Network has to have NO NONLINEARITY!
"""
def __init__(self, weight=None):
super(WeightedCrossEntropyLoss, self).__init__()
self.weight = weight
def forward(self, inp, target):
target = target.long()
num_classes = inp.size()[1]
i0 = 1
i1 = 2
while i1 < len(inp.shape): # this is ugly but torch only allows to transpose two axes at once
inp = inp.transpose(i0, i1)
i0 += 1
i1 += 1
inp = inp.contiguous()
inp = inp.view(-1, num_classes)
target = target.view(-1,)
wce_loss = torch.nn.CrossEntropyLoss(weight=self.weight)
return wce_loss(inp, target)上面针对不同类别的像素数量不均衡提出了改进方法,但有时还需要将像素分为难学习和容易学习这两种样本。
容易学习的样本模型可以很轻松地将其预测正确,模型只要将大量容易学习的样本分类正确,loss就可以减小很多,从而导致模型不怎么顾及难学习的样本,所以我们要想办法让模型更加关注难学习的样本。
对于较难学习的样本,将 bce loss 修改为:
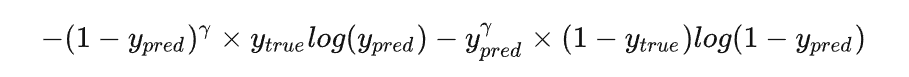
其中的 γ 通常设置为2。
通过这种修改,就可以使模型更加专注于学习难学习的样本。
而将这个修改和对正负样本不均衡的修改合并在一起,就是大名鼎鼎的 focal loss:
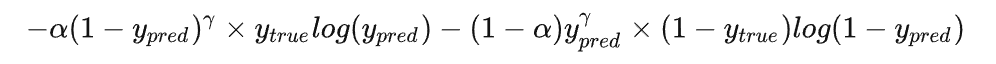
class FocalLoss(nn.Module):
"""
copy from: https://github.com/Hsuxu/Loss_ToolBox-PyTorch/blob/master/FocalLoss/FocalLoss.py
This is a implementation of Focal Loss with smooth label cross entropy supported which is proposed in
'Focal Loss for Dense Object Detection. (https://arxiv.org/abs/1708.02002)'
Focal_Loss= -1*alpha*(1-pt)*log(pt)
:param num_class:
:param alpha: (tensor) 3D or 4D the scalar factor for this criterion
:param gamma: (float,double) gamma > 0 reduces the relative loss for well-classified examples (p>0.5) putting more
focus on hard misclassified example
:param smooth: (float,double) smooth value when cross entropy
:param balance_index: (int) balance class index, should be specific when alpha is float
:param size_average: (bool, optional) By default, the losses are averaged over each loss element in the batch.
"""
def __init__(self, apply_nonlin=None, alpha=None, gamma=2, balance_index=0, smooth=1e-5, size_average=True):
super(FocalLoss, self).__init__()
self.apply_nonlin = apply_nonlin
self.alpha = alpha
self.gamma = gamma
self.balance_index = balance_index
self.smooth = smooth
self.size_average = size_average
if self.smooth is not None:
if self.smooth < 0 or self.smooth > 1.0:
raise ValueError('smooth value should be in [0,1]')
def forward(self, logit, target):
if self.apply_nonlin is not None:
logit = self.apply_nonlin(logit)
num_class = logit.shape[1]
if logit.dim() > 2:
# N,C,d1,d2 -> N,C,m (m=d1*d2*...)
logit = logit.view(logit.size(0), logit.size(1), -1)
logit = logit.permute(0, 2, 1).contiguous()
logit = logit.view(-1, logit.size(-1))
target = torch.squeeze(target, 1)
target = target.view(-1, 1)
# print(logit.shape, target.shape)
#
alpha = self.alpha
if alpha is None:
alpha = torch.ones(num_class, 1)
elif isinstance(alpha, (list, np.ndarray)):
assert len(alpha) == num_class
alpha = torch.FloatTensor(alpha).view(num_class, 1)
alpha = alpha / alpha.sum()
elif isinstance(alpha, float):
alpha = torch.ones(num_class, 1)
alpha = alpha * (1 - self.alpha)
alpha[self.balance_index] = self.alpha
else:
raise TypeError('Not support alpha type')
if alpha.device != logit.device:
alpha = alpha.to(logit.device)
idx = target.cpu().long()
one_hot_key = torch.FloatTensor(target.size(0), num_class).zero_()
one_hot_key = one_hot_key.scatter_(1, idx, 1)
if one_hot_key.device != logit.device:
one_hot_key = one_hot_key.to(logit.device)
if self.smooth:
one_hot_key = torch.clamp(
one_hot_key, self.smooth/(num_class-1), 1.0 - self.smooth)
pt = (one_hot_key * logit).sum(1) + self.smooth
logpt = pt.log()
gamma = self.gamma
alpha = alpha[idx]
alpha = torch.squeeze(alpha)
loss = -1 * alpha * torch.pow((1 - pt), gamma) * logpt
if self.size_average:
loss = loss.mean()
else:
loss = loss.sum()
return loss语义分割任务中常用的还有一个基于 Dice 系数的损失函数,该系数实质上是两个样本之间重叠的度量。此度量范围为 0~1,其中 Dice 系数为1表示完全重叠。Dice 系数最初是用于二进制数据的,可以计算为:
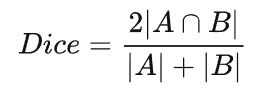
|A∩B| 代表集合A和B之间的公共元素,并且 |A| 代表集合A中的元素数量(对于集合B同理)。
对于在预测的分割掩码上评估 Dice 系数,我们可以将 |A∩B| 近似为预测掩码和标签掩码之间的逐元素乘法,然后对结果矩阵求和。

计算 Dice 系数的分子中有一个2,那是因为分母中对两个集合的元素个数求和,两个集合的共同元素被加了两次。 为了设计一个可以最小化的损失函数,可以简单地使用 1−Dice。 这种损失函数被称为 soft Dice loss,这是因为我们直接使用预测出的概率,而不是使用阈值将其转换成一个二进制掩码。
Dice loss是针对前景比例太小的问题提出的,dice系数源于二分类,本质上是衡量两个样本的重叠部分。
对于神经网络的输出,分子与我们的预测和标签之间的共同激活有关,而分母分别与每个掩码中的激活数量有关,这具有根据标签掩码的尺寸对损失进行归一化的效果。
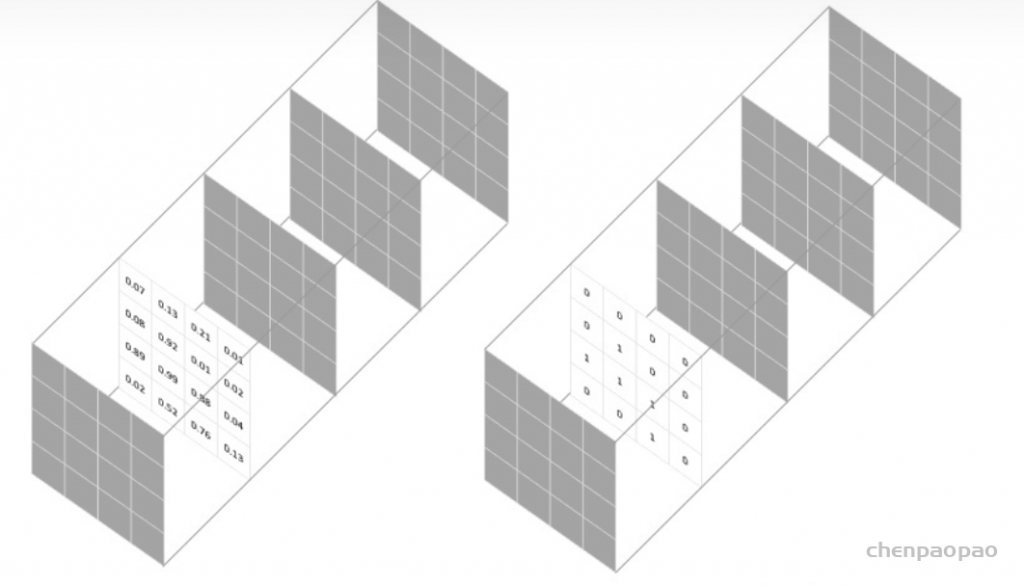
对于每个类别的mask,都计算一个 Dice 损失:
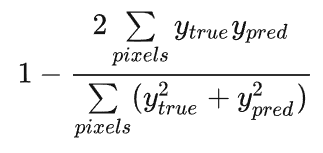
将每个类的 Dice 损失求和取平均,得到最后的 Dice soft loss。
下面是代码实现:
def soft_dice_loss(y_true, y_pred, epsilon=1e-6):
'''
Soft dice loss calculation for arbitrary batch size, number of classes, and number of spatial dimensions.
Assumes the `channels_last` format.
# Arguments
y_true: b x X x Y( x Z...) x c One hot encoding of ground truth
y_pred: b x X x Y( x Z...) x c Network output, must sum to 1 over c channel (such as after softmax)
epsilon: Used for numerical stability to avoid divide by zero errors
# References
V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation
https://arxiv.org/abs/1606.04797
More details on Dice loss formulation
https://mediatum.ub.tum.de/doc/1395260/1395260.pdf (page 72)
Adapted from https://github.com/Lasagne/Recipes/issues/99#issuecomment-347775022
'''
# skip the batch and class axis for calculating Dice score
axes = tuple(range(1, len(y_pred.shape)-1))
numerator = 2. * np.sum(y_pred * y_true, axes)
denominator = np.sum(np.square(y_pred) + np.square(y_true), axes)
return 1 - np.mean(numerator / (denominator + epsilon)) # average over classes and batch前面我们知道计算 Dice 系数的公式,其实也可以表示为:
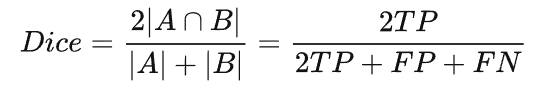
其中 TP 为真阳性样本,FP 为假阳性样本,FN 为假阴性样本。分子和分母中的 TP 样本都加了两次。
IoU 的计算公式和这个很像,区别就是 TP 只计算一次:
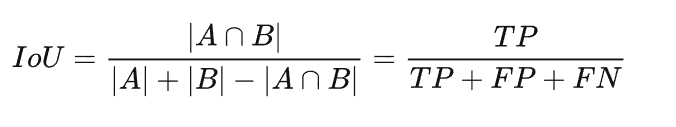
和 Dice soft loss 一样,通过 IoU 计算损失也是使用预测的概率值:
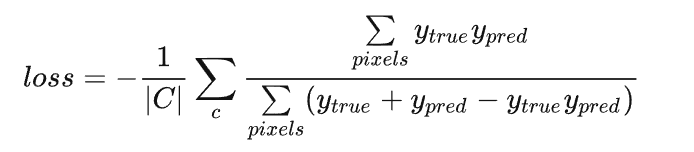
其中 C 表示总的类别数。
论文地址为:https://arxiv.org/pdf/1706.05…
医学影像中存在很多的数据不平衡现象,使用不平衡数据进行训练会导致严重偏向高精度但低召回率(sensitivity)的预测,这是不希望的,特别是在医学应用中,假阴性比假阳性更难容忍。本文提出了一种基于Tversky指数的广义损失函数,解决了三维全卷积深神经网络训练中数据不平衡的问题,在精度和召回率之间取得了较好的折衷。
Dice loss的正则化版本,以控制假阳性和假阴性对损失函数的贡献,TL被定义为
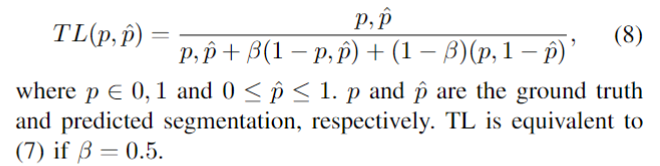
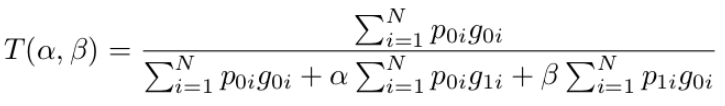

class TverskyLoss(nn.Module):
def __init__(self, apply_nonlin=None, batch_dice=False, do_bg=True, smooth=1.,
square=False):
"""
paper: https://arxiv.org/pdf/1706.05721.pdf
"""
super(TverskyLoss, self).__init__()
self.square = square
self.do_bg = do_bg
self.batch_dice = batch_dice
self.apply_nonlin = apply_nonlin
self.smooth = smooth
self.alpha = 0.3
self.beta = 0.7
def forward(self, x, y, loss_mask=None):
shp_x = x.shape
if self.batch_dice:
axes = [0] + list(range(2, len(shp_x)))
else:
axes = list(range(2, len(shp_x)))
if self.apply_nonlin is not None:
x = self.apply_nonlin(x)
tp, fp, fn = get_tp_fp_fn(x, y, axes, loss_mask, self.square)
tversky = (tp + self.smooth) / (tp + self.alpha*fp + self.beta*fn + self.smooth)
if not self.do_bg:
if self.batch_dice:
tversky = tversky[1:]
else:
tversky = tversky[:, 1:]
tversky = tversky.mean()
return -tversky Dice loss虽然一定程度上解决了分类失衡的问题,但却不利于严重的分类不平衡。例如小目标存在一些像素的预测误差,这很容易导致Dice的值发生很大的变化。Sudre等人提出了Generalized Dice Loss (GDL)
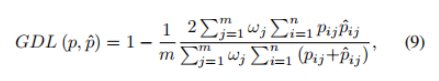
GDL优于Dice损失,因为不同的区域对损失有相似的贡献,并且GDL在训练过程中更稳定和鲁棒。
为了解决类别不平衡的问题,Kervadec等人[95]提出了一种新的用于脑损伤分割的边界损失。该损失函数旨在最小化分割边界和标记边界之间的距离。作者在两个没有标签的不平衡数据集上进行了实验。结果表明,Dice los和Boundary los的组合优于单一组合。复合损失的定义为
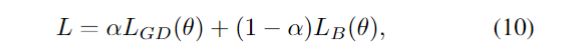
其中第一部分是一个标准的Dice los,它被定义为
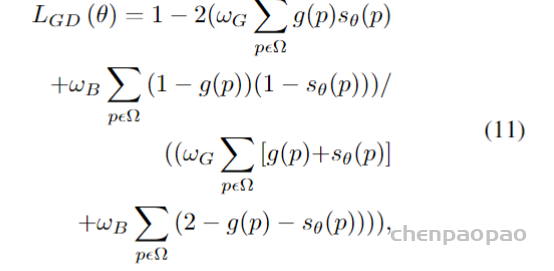
第二部分是Boundary los,它被定义为
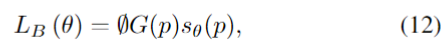
在(9)中,加权Dice los实际上是得到的Dice值除以每个标签的和,对不同尺度的对象达到平衡。因此,Wong等人结合focal loss [96] 和dice loss,提出了用于脑分割的指数对数损失(EXP损失),以解决严重的类不平衡问题。通过引入指数形式,可以进一步控制损失函数的非线性,以提高分割精度。EXP损失函数的定义为
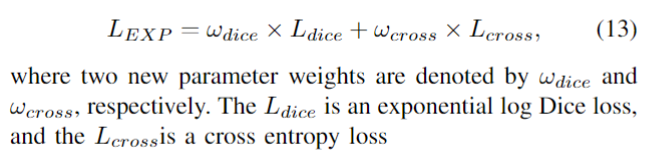
其中,两个新的参数权重分别用ωdice和ωcross表示。Ldice是指数对数骰子损失,而交叉损失是交叉熵损失
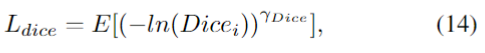

其中x是像素位置,i是标签,l是位置x处的地面真值。pi(x)是从softmax输出的概率值。
在(17)中,fk是标签k出现的频率,该参数可以减少更频繁出现的标签的影响。γDice和γcross都用于增强损失函数的非线性。
与“Focal loss”相似,后者着重于通过降低易用/常见损失的权重来说明困难的例子。Focal Tversky Loss还尝试借助γ系数来学习诸如在ROI(感兴趣区域)较小的情况下的困难示例,如下所示:
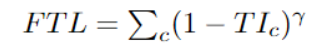
class FocalTversky_loss(nn.Module):
"""
paper: https://arxiv.org/pdf/1810.07842.pdf
author code: https://github.com/nabsabraham/focal-tversky-unet/blob/347d39117c24540400dfe80d106d2fb06d2b99e1/losses.py#L65
"""
def __init__(self, tversky_kwargs, gamma=0.75):
super(FocalTversky_loss, self).__init__()
self.gamma = gamma
self.tversky = TverskyLoss(**tversky_kwargs)
def forward(self, net_output, target):
tversky_loss = 1 + self.tversky(net_output, target) # = 1-tversky(net_output, target)
focal_tversky = torch.pow(tversky_loss, self.gamma)
return focal_tversky 首先敏感性就是召回率,检测出确实有病的能力:

特异性,检测出确实没病的能力:

而Sensitivity Specificity Loss为:


class SSLoss(nn.Module):
def __init__(self, apply_nonlin=None, batch_dice=False, do_bg=True, smooth=1.,
square=False):
"""
Sensitivity-Specifity loss
paper: http://www.rogertam.ca/Brosch_MICCAI_2015.pdf
tf code: https://github.com/NifTK/NiftyNet/blob/df0f86733357fdc92bbc191c8fec0dcf49aa5499/niftynet/layer/loss_segmentation.py#L392
"""
super(SSLoss, self).__init__()
self.square = square
self.do_bg = do_bg
self.batch_dice = batch_dice
self.apply_nonlin = apply_nonlin
self.smooth = smooth
self.r = 0.1 # weight parameter in SS paper
def forward(self, net_output, gt, loss_mask=None):
shp_x = net_output.shape
shp_y = gt.shape
# class_num = shp_x[1]
with torch.no_grad():
if len(shp_x) != len(shp_y):
gt = gt.view((shp_y[0], 1, *shp_y[1:]))
if all([i == j for i, j in zip(net_output.shape, gt.shape)]):
# if this is the case then gt is probably already a one hot encoding
y_onehot = gt
else:
gt = gt.long()
y_onehot = torch.zeros(shp_x)
if net_output.device.type == "cuda":
y_onehot = y_onehot.cuda(net_output.device.index)
y_onehot.scatter_(1, gt, 1)
if self.batch_dice:
axes = [0] + list(range(2, len(shp_x)))
else:
axes = list(range(2, len(shp_x)))
if self.apply_nonlin is not None:
softmax_output = self.apply_nonlin(net_output)
# no object value
bg_onehot = 1 - y_onehot
squared_error = (y_onehot - softmax_output)**2
specificity_part = sum_tensor(squared_error*y_onehot, axes)/(sum_tensor(y_onehot, axes)+self.smooth)
sensitivity_part = sum_tensor(squared_error*bg_onehot, axes)/(sum_tensor(bg_onehot, axes)+self.smooth)
ss = self.r * specificity_part + (1-self.r) * sensitivity_part
if not self.do_bg:
if self.batch_dice:
ss = ss[1:]
else:
ss = ss[:, 1:]
ss = ss.mean()
return ssDice系数是一种用于评估分割输出的度量标准。它也已修改为损失函数,因为它可以实现分割目标的数学表示。但是由于其非凸性,它多次都无法获得最佳结果。Lovsz-softmax损失旨在通过添加使用Lovsz扩展的平滑来解决非凸损失函数的问题。同时,Log-Cosh方法已广泛用于基于回归的问题中,以平滑曲线。


将Cosh(x)函数和Log(x)函数合并,可以得到Log-Cosh Dice Loss:

def log_cosh_dice_loss(self, y_true, y_pred):
x = self.dice_loss(y_true, y_pred)
return tf.math.log((torch.exp(x) + torch.exp(-x)) / 2.0) Hausdorff Distance Loss(HD)是分割方法用来跟踪模型性能的度量。它定义为:

任何分割模型的目的都是为了最大化Hausdorff距离,但是由于其非凸性,因此并未广泛用作损失函数。有研究者提出了基于Hausdorff距离的损失函数的3个变量,它们都结合了度量用例,并确保损失函数易于处理。
class HDDTBinaryLoss(nn.Module):
def __init__(self):
"""
compute haudorff loss for binary segmentation
https://arxiv.org/pdf/1904.10030v1.pdf
"""
super(HDDTBinaryLoss, self).__init__()
def forward(self, net_output, target):
"""
net_output: (batch_size, 2, x,y,z)
target: ground truth, shape: (batch_size, 1, x,y,z)
"""
net_output = softmax_helper(net_output)
pc = net_output[:, 1, ...].type(torch.float32)
gt = target[:,0, ...].type(torch.float32)
with torch.no_grad():
pc_dist = compute_edts_forhdloss(pc.cpu().numpy()>0.5)
gt_dist = compute_edts_forhdloss(gt.cpu().numpy()>0.5)
# print('pc_dist.shape: ', pc_dist.shape)
pred_error = (gt - pc)**2
dist = pc_dist**2 + gt_dist**2 # \alpha=2 in eq(8)
dist = torch.from_numpy(dist)
if dist.device != pred_error.device:
dist = dist.to(pred_error.device).type(torch.float32)
multipled = torch.einsum("bxyz,bxyz->bxyz", pred_error, dist)
hd_loss = multipled.mean()
return hd_loss交叉熵损失把每个像素都当作一个独立样本进行预测,而 dice loss 和 iou loss 则以一种更“整体”的方式来看待最终的预测输出。
这两类损失是针对不同情况,各有优点和缺点,在实际应用中,可以同时使用这两类损失来进行互补。
论文地址: https://arxiv.org/abs/1706.05587

Deeplab v3是v2版本的进一步升级,作者们在对空洞卷积重新思考的基础上,进一步对Deeplab系列的基本框架进行了优化,去掉了v1和v2版本中一直坚持的CRF后处理模块,升级了主干网络和ASPP模块,使得网络能够更好地处理语义分割中的多尺度问题。提出Deeplab v3的论文为Rethinking Atrous Convolution for Semantic Image Segmentation,是Deeplab系列后期网络的代表模型。
DeepLab V3的改进主要包括以下几方面:
1)提出了更通用的框架,适用于任何网络
2)复制了ResNet最后的block,并级联起来
3)在ASPP中使用BN层
4)去掉了CRF
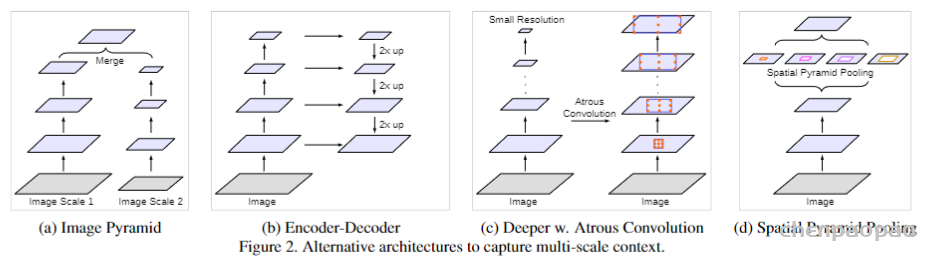
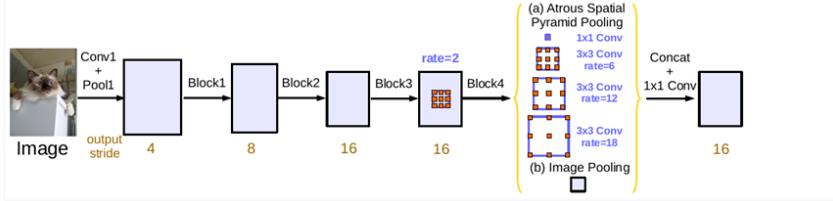
随着语义分割的发展,逐渐有两大问题亟待解决:一个是连续的池化和卷积步长导致的下采样图像信息丢失问题,这个问题已经通过空洞卷积扩大感受野得到比较好的处理;另外一个则是多尺度和利用上下文信息问题。论文中分别回顾了四种基于多尺度和上下文信息进行语义分割的方法,如图1所示,包括图像金字塔、编解码架构、深度空洞卷积网络以及空间金字塔池化,这四种方法各有优缺点,ASPP可以算是深度空洞卷积和空间金字塔池化的一种结合,Deeplab v3在v2的ASPP基础上,进一步探索了空洞卷积在多尺度和上下文信息中的作用。
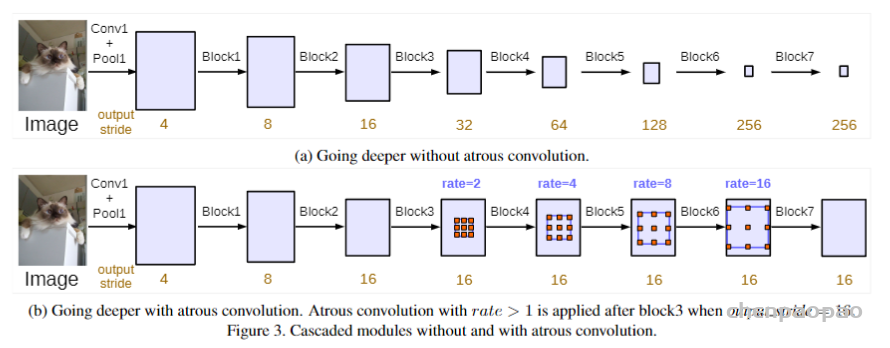
Deeplab v3可作为通用框架融入到任意网络结构中,具体地,以串行方式设计空洞卷积模块,复制ResNet的最后一个卷积块,并将复制后的卷积块以串行方式进行级联,如图2所示。DeepLab V3将空洞卷积应用在级联模块。具体来说,我们取ResNet中最后一个block,在下图中为block4,并在其后面增加级联模块。
在卷积块串行级联基础上,Deeplab v3又对ASPP模块进行并行级联,v3对ASPP模块进行了升级,相较于v2版本加入了批归一化(Batch Normalization,BN),通过组织不同的空洞扩张率的卷积块,同时加入图像级特征,能够更好地捕捉多尺度上下文信息,并且也能够更容易训练,如图3所示。
1)ASPP中应用了BN层
2)随着采样率的增加,滤波器中有效的权重减少了(有效权重减少,难以捕获原距离信息,这要求合理控制采样率的设置)
3)使用模型最后的特征映射的全局平均池化(为了克服远距离下有效权重减少的问题)
总结来看,Deeplab v3更充分的利用了空洞卷积来获取大范围的图像上下文信息。具体包括:多尺度信息编码、带有逐步翻倍的空洞扩张率的级联模块以及带有图像级特征的ASPP模块。实验结果表明,该模型在 PASCAL VOC数据集上相较于v2版本有了显着进步,取得了当时SOTA精度水平。
Deeplab v3的PyTorch实现可参考:
https://github.com/pytorch/vision/blob/main/torchvision/models/segmentation/deeplabv3.py
代码实现:
class DeeplabV3(ResNet):
def __init__(self, n_class, block, layers, pyramids, grids, output_stride=16):
self.inplanes = 64
super(DeeplabV3, self).__init__()
if output_stride == 16:
strides = [1, 2, 2, 1]
rates = [1, 1, 1, 2]
elif output_stride == 8:
strides = [1, 2, 1, 1]
rates = [1, 1, 2, 2]
else:
raise NotImplementedError
# Backbone Modules
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # h/4, w/4
self.layer1 = self._make_layer(block, 64, layers[0], stride=strides[0], rate=rates[0]) # h/4, w/4
self.layer2 = self._make_layer(block, 128, layers[1], stride=strides[1], rate=rates[1]) # h/8, w/8
self.layer3 = self._make_layer(block, 256, layers[2], stride=strides[2], rate=rates[2]) # h/16,w/16
self.layer4 = self._make_MG_unit(block, 512, blocks=grids, stride=strides[3], rate=rates[3])# h/16,w/16
# Deeplab Modules
self.aspp1 = ASPP_module(2048, 256, rate=pyramids[0])
self.aspp2 = ASPP_module(2048, 256, rate=pyramids[1])
self.aspp3 = ASPP_module(2048, 256, rate=pyramids[2])
self.aspp4 = ASPP_module(2048, 256, rate=pyramids[3])
self.global_avg_pool = nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)),
nn.Conv2d(2048, 256, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU())
# get result features from the concat
self._conv1 = nn.Sequential(nn.Conv2d(1280, 256, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU())
# generate the final logits
self._conv2 = nn.Conv2d(256, n_class, kernel_size=1, bias=False)
self.init_weight()
def forward(self, input):
x = self.conv1(input)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x1 = self.aspp1(x)
x2 = self.aspp2(x)
x3 = self.aspp3(x)
x4 = self.aspp4(x)
# image-level features
x5 = self.global_avg_pool(x)
x5 = F.upsample(x5, size=x4.size()[2:], mode='bilinear', align_corners=True)
x = torch.cat((x1, x2, x3, x4, x5), dim=1)
x = self._conv1(x)
x = self._conv2(x)
x = F.upsample(x, size=input.size()[2:], mode='bilinear', align_corners=True)
return x其中重要的_makelayer, _make_MG_unit和ASSP模块实现如下:
def _make_layer(self, block, planes, blocks, stride=1, rate=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, rate, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def _make_MG_unit(self, block, planes, blocks=[1, 2, 4], stride=1, rate=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, rate=blocks[0] * rate, downsample=downsample))
self.inplanes = planes * block.expansion
for i in range(1, len(blocks)):
layers.append(block(self.inplanes, planes, stride=1, rate=blocks[i] * rate))
return nn.Sequential(*layers)
class ASPP_module(nn.Module):
def __init__(self, inplanes, planes, rate):
super(ASPP_module, self).__init__()
if rate == 1:
kernel_size = 1
padding = 0
else:
kernel_size = 3
padding = rate
self.atrous_convolution = nn.Conv2d(inplanes, planes, kernel_size=kernel_size,
stride=1, padding=padding, dilation=rate, bias=False)
self.bn = nn.BatchNorm2d(planes)
self.relu = nn.ReLU()
self._init_weight()
def forward(self, x):
x = self.atrous_convolution(x)
x = self.bn(x)
return self.relu(x)
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()训练策略:
Crop size:
Batch normalization:
Upsampling logits:
Data augmentation:
在训练阶段,随机缩放输入图像(从0.5到2.0)和随机左-右翻转
论文地址 https://arxiv.org/abs/1706.05587

Deeplab v3+是Deeplab系列最后一个网络结构,也是基于空洞卷积和多尺度系列模型的集大成者。相较于Deeplab v3,v3+版本参考了UNet系列网络,对基于空洞卷积的Deeplab网络引入了编解码结构,一定程度上来讲,Deeplab v3+是编解码和多尺度这两大系列网络的一个大融合,在很长一段时间内代表了自然图像语义分割的SOTA水平的分割模型。提出Deeplab v3+的论文为Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation,至今仍然是最常用的一个语义分割网络模型。
对于语义分割问题,尽管各种网络模型很多,但Deeplab v3+的作者们认为迄今为止仅有两大主流设计:一个是以UNet为代表的编解码结构,另一个就是以Deeplab为代表的ASPP和多尺度设计,前者以获取图像中目标对象细致的图像边界见长,后者则更擅长捕捉图像中丰富的上下文多尺度信息。鉴于此,Deeplab v3+将编解码结构引入到v3网络中,Deeplab v3直接作为编码器,然后再加入解码器设计,这样就构成了一个SPP(空间金字塔池化)+Atrous Conv(空洞卷积)+Encoder-Decoder(编解码)包含众多丰富元素的组合结构。这三种结构如下图所示。
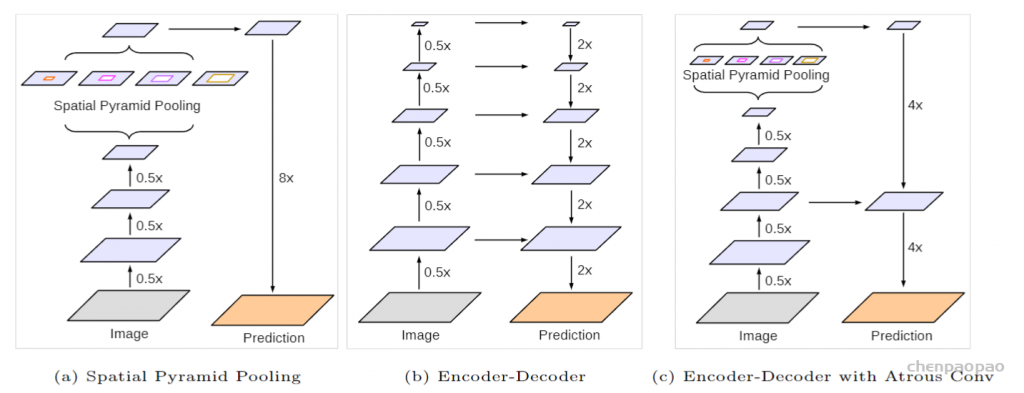
完整的Deeplab v3+网络结构如下图所示。可以看到,输入图像先进入有深度空洞卷积构成的编码器部分中,由并行的ASPP模块构建并且融入图像级的池化特征,然后再进行合并并通过1*1卷积降低通道数后得到编码器的输出,编码器部分没有做特别的改动,直接使用了Deeplab v3的结构作为编码器,旨在提取图像的多尺度上下文信息。解码器部分则是做了一些特别的设计,编码器输出先经过4倍双线性插值上采样,同时也从编码器部分链接浅层的图像特征到解码器部分,并经1*1卷积降维后与4倍上采样的输出进行拼接,最后经过一个3*3卷积后再经过一次4倍上采样后得到最终的分割输出结果。

另外,Deeplab v3+除了延用之前的ResNet系列作为backbone之外,也尝试了以轻量级着称的Xception网络,具体做法就是将深度可分离卷积(Depth separable convolution)引入到空洞卷积中,能够极大的减少计算量,虽然有一定的精度损失,但在追求速度性能上不失为一种非常好的选择。下面简单介绍一下深度可分离卷积。
从维度的角度看,卷积核可以看成是一个空间维(宽和高)和通道维的组合,而卷积操作则可以视为空间相关性和通道相关性的联合映射。从Inception的1*1卷积来看,卷积中的空间相关性和通道相关性是可以解耦的,将它们分开进行映射,可能会达到更好的效果。
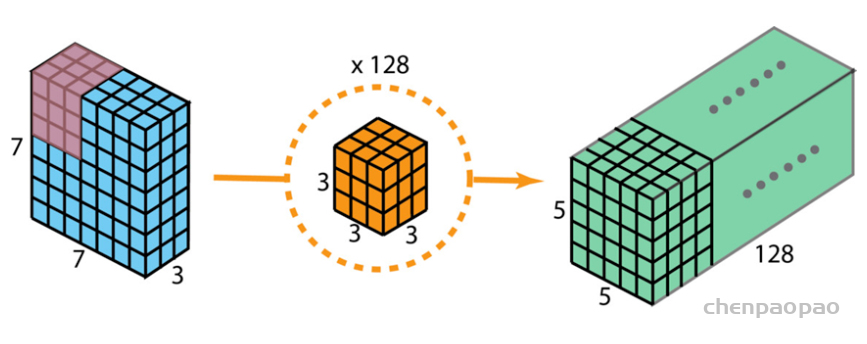
深度可分离卷积是在1*1卷积基础上的一种创新。主要包括两个部分:深度卷积和1*1卷积。深度卷积的目的在于对输入的每一个通道都单独使用一个卷积核对其进行卷积,也就是通道分离后再组合。1*1卷积的目的则在于加强深度。下面以一个例子来看一下深度可分离卷积:假设我们用128个3*3*3的滤波器对一个7*7*3的输入进行卷积,可得到5*5*128的输出,其计算量为5*5*128*3*3*3=86400,如下图所示。
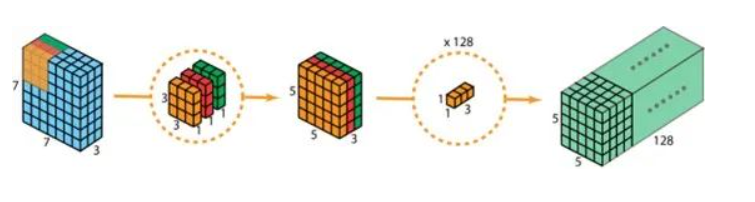
然后我们看如何使用深度可分离卷积来实现同样的结果。深度可分离卷积的第一步是深度卷积。这里的深度卷积,就是分别用3个3*3*1的滤波器对输入的3个通道分别做卷积,也就是说要做3次卷积,每次卷积都有一个5*5*1的输出,组合在一起便是5*5*3的输出。现在为了拓展深度达到128,我们需要执行深度可分离卷积的第二步:1*1卷积。现在我们用128个1*1*3的滤波器对5*5*3进行卷积,就可以得到5*5*128的输出。完整过程如下图所示。
看一下深度可分离卷积的计算量如何。第一步深度卷积的计算量:5*5*1*3*3*1*3=675。第二步11卷积的计算量:5*5*128*1*1*3=9600,合计计算量为10275次。可见,相同的卷积计算输出,深度可分离卷积要比常规卷积节省12倍的计算成本。典型的应用深度可分离卷积的网络模型包括Xception和MobileNet等。本质上而言,Xception就是应用了深度可分离卷积的Inception网络。
Deeplab v3+在PASCAL VOC和Cityscapes等公开数据集上均取得了SOTA的结果,即使在深度学习语义分割发展日新月异发展的今天,Deeplab v3+仍然不失为一个非常好的语义分割解决方案。
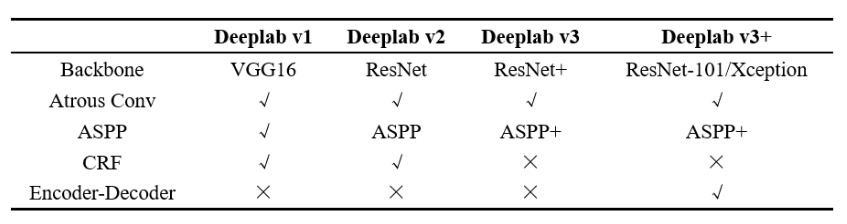
关于Deeplab系列各版本的技术要点总结如下表所示。
TPAMI 2018
Deeplab v2 严格上算是Deeplab v1版本的一次不大的更新,在v1的空洞卷积和CRF基础上,重点关注了网络对于多尺度问题的适用性。多尺度问题一直是目标检测和语义分割任务的重要挑战之一,以往实现多尺度的惯常做法是对同一张图片进行不同尺寸的缩放后获取对应的卷积特征图,然后将不同尺寸的特征图分别上采样后再融合来获取多尺度信息,但这种做法最大的缺点就是计算开销太大。Deeplab v2借鉴了空间金字塔池化(Spatial Pyramaid Pooling, SPP)的思路,提出了基于空洞卷积的空间金字塔池化(Atrous Spatial Pyramaid Pooling, ASPP),这也是Deeplab v2最大的亮点。提出Deeplab v2的论文为DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs,是Deeplab系列网络中前期结构的重要代表。
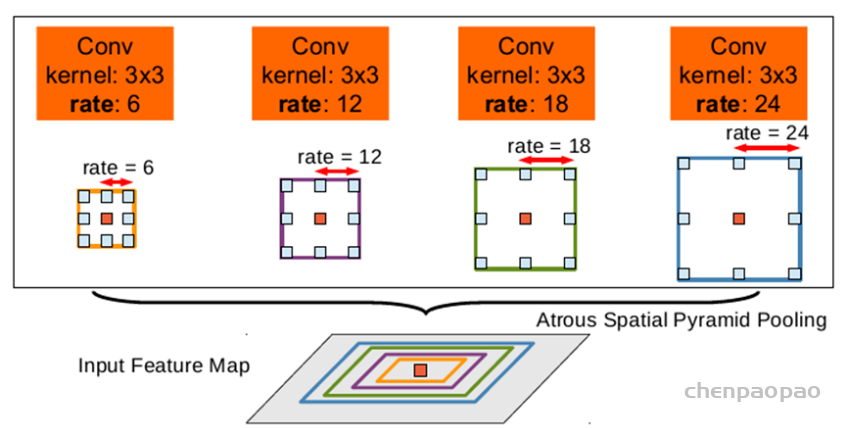
ASPP来源于R-CNN(Regional CNN)目标检测领域中SPP结构,该方法表明任意尺度的图像区域可以通过对单一尺度提取的卷积特征进行重采样而准确有效地分类。ASPP在其基础上将普通卷积改为空洞卷积,通过使用多个不同扩张率且并行的空洞卷积进行特征提取,最后在对每个分支进行融合。ASPP结构如下图所示。
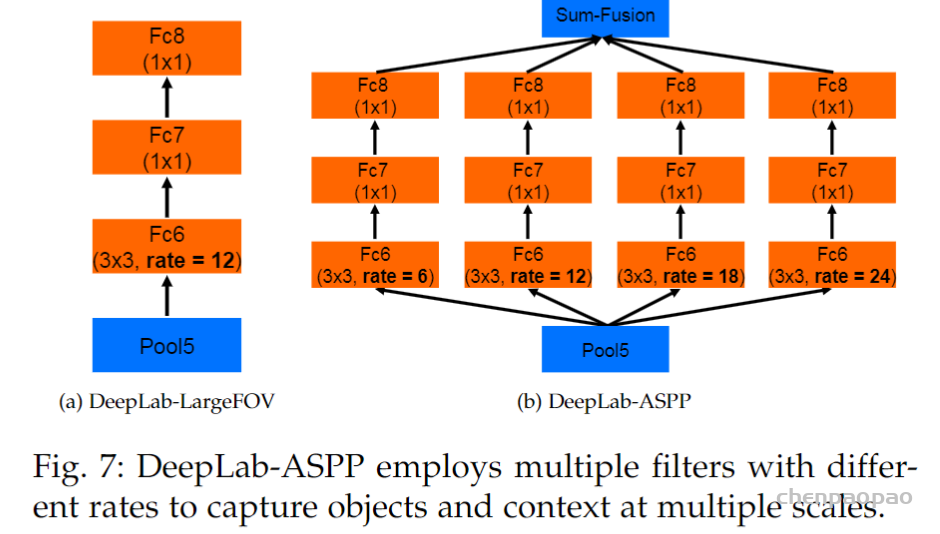
除了ASPP之外,Deeplab v2还将v1中VGG-16的主干网络换成了ResNet-101,算是对编码器的一次升级,使其具备更强的特征提取能力。Deeplab v2在PASCAL VOC和Cityscapes等语义分割数据集上均取得了当时的SOTA结果。关于ASPP模块的一个简单实现参考如下代码所示,先是分别定义了ASPP的卷积和池化方法,然后在其基础上定义了ASPP模块。
### 定义ASPP卷积方法
class ASPPConv(nn.Sequential):
def __init__(self, in_channels, out_channels, dilation):
modules = [
nn.Conv2d(in_channels, out_channels, 3, padding=dilation,
dilation=dilation, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
]
super(ASPPConv, self).__init__(*modules)
### 定义ASPP池化方法
class ASPPPooling(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(ASPPPooling, self).__init__(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True))
def forward(self, x):
size = x.shape[-2:]
x = super(ASPPPooling, self).forward(x)
return F.interpolate(x, size=size, mode='bilinear',
align_corners=False)
### 定义ASPP模块
class ASPP(nn.Module):
def __init__(self, in_channels, atrous_rates):
super(ASPP, self).__init__()
out_channels = 256
modules = []
modules.append(nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)))
rate1, rate2, rate3 = tuple(atrous_rates)
modules.append(ASPPConv(in_channels, out_channels, rate1))
modules.append(ASPPConv(in_channels, out_channels, rate2))
modules.append(ASPPConv(in_channels, out_channels, rate3))
modules.append(ASPPPooling(in_channels, out_channels))
self.convs = nn.ModuleList(modules)
self.project = nn.Sequential(
nn.Conv2d(5 * out_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Dropout(0.1),)
# ASPP前向计算流程
def forward(self, x):
res = []
for conv in self.convs:
res.append(conv(x))
res = torch.cat(res, dim=1)
return self.project(res)
下图是Deeplab v2在Cityscapes数据集上的分割效果:
DeepLabv1:
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
ICLR 2015
在语义分割发展早期,一些研究观点认为将CNN用于图像分割主要存在两个问题:一个是下采样导致的信息丢失问题,另一个则是CNN的空间不变性问题,这与CNN本身的特性有关,这种空间不变性有利于图像分类但却不利于图像分割中的像素定位。从多尺度和上下文信息的角度来看,这两个问题是导致FCN分割效果有限的重要原因。因而,相关研究针对上述两个问题提出了Deeplab v1网络,通过在常规卷积中引入空洞(Atrous)和对CNN分割结果补充CRF作为后处理来优化分割效果。提出Deeplab v1的论文为Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs,是Deeplab系列的开篇之作。
针对第一个问题,池化下采样操作引起信息丢失,Deeplab v1给出的解决方案算是另辟蹊径。常规卷积中,使用池化下采样的主要目的是增大每个像素的感受野,但在Deeplab v1中,作者们的想法是可以不用池化也可以增大像素的感受野,尝试在卷积操作本身上重新进行设计。在Deeplab v1,一种在常规卷积核中插入空洞的设计被提出,相较于池化下采样,空洞卷积能够在不降低图像分辨率的情况下扩大像素感受野,从而就避免了信息损失的问题。
空洞卷积(Dilated/Atrous Convolution)也叫扩张卷积或者膨胀卷积,字面意思上来说就是在卷积核中插入空洞,起到扩大感受野的作用。空洞卷积的直接做法是在常规卷积核中填充0,用来扩大感受野,且进行计算时,空洞卷积中实际只有非零的元素起了作用。假设以一个变量a来衡量空洞卷积的扩张系数,则加入空洞之后的实际卷积核尺寸与原始卷积核尺寸之间的关系:
K=k+(k-1)(a-1)
其中为k原始卷积核大小,a为空洞率(Dilation Rate),K为经过扩展后实际卷积核大小。除此之外,空洞卷积的卷积方式跟常规卷积一样。当a=1时,空洞卷积就退化为常规卷积。a=1,2,4时,空洞卷积示意图如下图所示。


对于语义分割而言,空洞卷积主要有三个作用:
第一是扩大感受野,具体前面已经说的比较多了,这里不做重复。但需要明确一点,池化也可以扩大感受野,但空间分辨率降低了,相比之下,空洞卷积可以在扩大感受野的同时不丢失分辨率,且保持像素的相对空间位置不变。简单而言就是空洞卷积可以同时控制感受野和分辨率。
第二就是获取多尺度上下文信息。当多个带有不同空洞率的空洞卷积核叠加时,不同的感受野会带来多尺度信息,这对于分割任务是非常重要的。
第三就是可以降低计算量,不需要引入额外的参数,如图4-13所示,实际卷积时只有带有红点的元素真正进行计算。
针对第二个问题,Deeplab v1通过引入全连接的CRF来对CNN的粗分割结果进行优化。CRF作为一种经典的概率图模型,可用于图像像素之间的关系描述,在传统图像处理中主要用于图像平滑处理。但对于CNN分割问题来说,使用短程的CRFs可能会于事无补,因为分割问题的目标是恢复图像的局部细节信息,而不是对图像做平滑处理。所以Deeplab v1提出的解决方案叫做全连接CRF(Fully Connected CRF)。
条件随机场可以优化物体的边界,平滑带噪声的分割结果,去掉物体中间的预测的孔洞,使得分割结果更加准确。
CRF是一种经典的概率图模型,简单而言就是给定一组输入序列的条件下,求另一组输出序列的条件概率分布模型,CRF在自然语言处理领域有着广泛应用。CRF在语义分割后处理中用法的基本思路如下:对于FCN或者其他分割网络的粗粒度分割结果而言,每个像素点i具有对应的类别标签x_i和观测值y_i,以每个像素为节点,以像素与像素之间的关系作为边即可构建一个CRF模型。在这个CRF模型中,我们通过观测变量y_i来预测像素i对应的标签值x_i。CRF用于像素预测的结构如下图所示。

全连接CRF使用的能量函数为:

Deeplab v1模型流程如下图所示。输入图像经过深度卷积网络(DCNN)后生成浓缩的、粗粒度的语义特征图,再经过双线性插值上采样后形成粗分割结果,最后经全连接的CRF后处理生成最终的分割结果图。
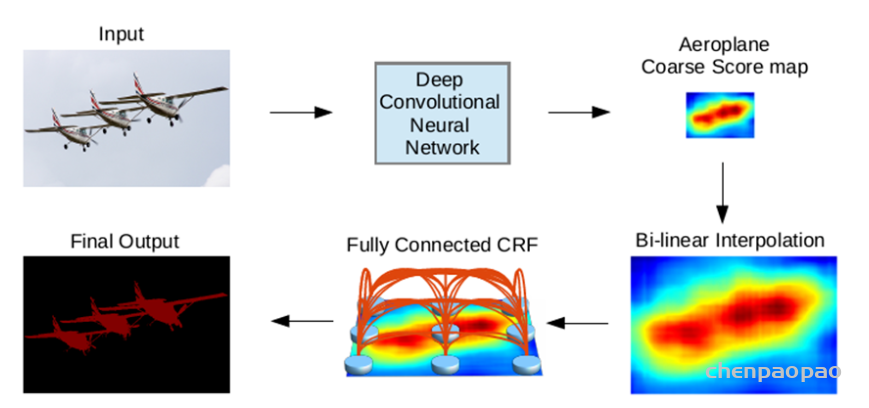
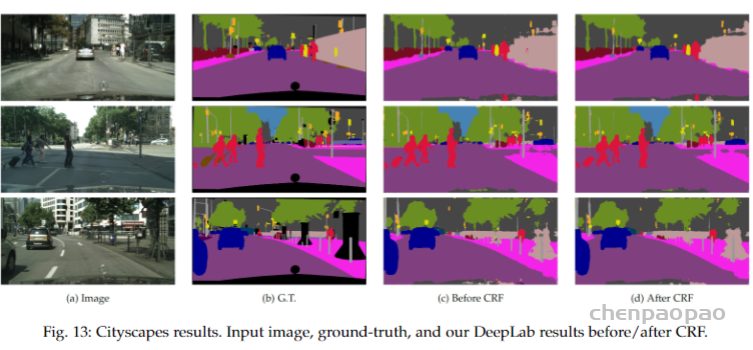
下图是Deeplab v1在无CRF和有CRF后处理的分割效果图:

总的来看,Deeplab v1有如下几个有点:
(1)速度快。基于空洞卷积的CNN分割网络,能够保证8秒每帧(Frame Per Second,FPS)的推理速度,后处理的全连接CRF也仅需要0.5秒。
(2)精度高。Deeplab v1在当时取得了在PASCAL VOC数据集上SOTA的分割模型表现,准确率超过此前SOTA的7.2%。
(3)简易性。DCNN和CRF均为成熟的算法模块,将其进行简单的级联即可在当前的语义分割模型上取得好的效果。
Deeplab v1 PyTorch参考实现代码如下:
原文地址:https://arxiv.org/pdf/1612.01105.pdf
论文代码:https://github.com/hszhao/PSPNet
解读:
本文的主要创新点在于提出了空间金字塔池化模块,简单来说就是在encoder之后得到feature map X,使用不同尺寸的kernel进行池化(avepooling)操作,之后对得到的feature map进行上采样,使得尺寸和X大小一样,然后进行级联,进而经过卷积操作得到map。和经典的FCN的区别是在encoder和decoder之间加入了PSP模块。

场景解析(scene parsing)是语义分割的一个重要应用方向,区别于一般的语义分割任务,场景解析需要在复杂的自然图像场景下对更庞大的物体类别的每一个像素进行分类,场景解析在自动驾驶和机器人感知等方向应用广泛。但由于自然场景的复杂性、语义标签的多样性以及目标物体的多变性,对于场景解析问题的研究一直存在诸多困难。
场景解析一般基于FCN和空洞卷积网络来进行结构设计,后续的改进方案主要有两个方向,一种是多尺度特征集成,学界普遍的观点认为深层特征能够提取图像的语义信息但缺乏定位信息,将多尺度的特征集成起来能够显著提升模型效果。另一个则是结合图模型的结构预测,比如说使用CRF进行后处理来优化图像分割结果,这些改进方案虽然在一定程度上都能缓解像素定位问题,但对于更为复杂的图像场景仍然效果有限。将全局信息加入到语义分割网络中的设计也有很多研究提到,比如ParseNet,通过给FCN补充全局平均池化来提升分割效果。但这种全局信息不足以在一些复杂的场景解析数据集上体现效果,比如包括150个语义类别的ADE20K数据集。总结来看,FCN对于复杂的场景解析存在如下三个问题:
(1)像素上下文关系不匹配。在语义分割中,图像上下文信息非常重要,不同的像素类别之间往往存在着共现的视觉模式,比如说飞机通常只会出现在跑道上或者空中,而不会出现在马路上,所以飞机和跑道以及天空这三个对象之间存在着共现模式。
(2)语义标签的混淆。ADE20K数据集中有大量语义相近的类别,比如高山与丘陵、建筑与摩天大楼等。FCN在这种容易混淆的类别上很难做出准确的判断。
(3)小目标类别预测困难。在场景解析中,目标物体可以是任意大小,所以有时候对于小目标物体预测效果就很差,比如说对路灯和广告牌的识别,FCN表现就非常不好。
针对上述问题,相关学者基于空间金字塔池化(Spatial Pyramid Pooling, SPP)提出了一种更为广泛的、基于不同图像区域的全局上下文信息集成结构:PSPNet,提出PSPNet的论文为Pyramid Scene Parsing Network,是多尺度上下文结构方向的一个重要的网络设计。PSPNet网络结构如图1所示。
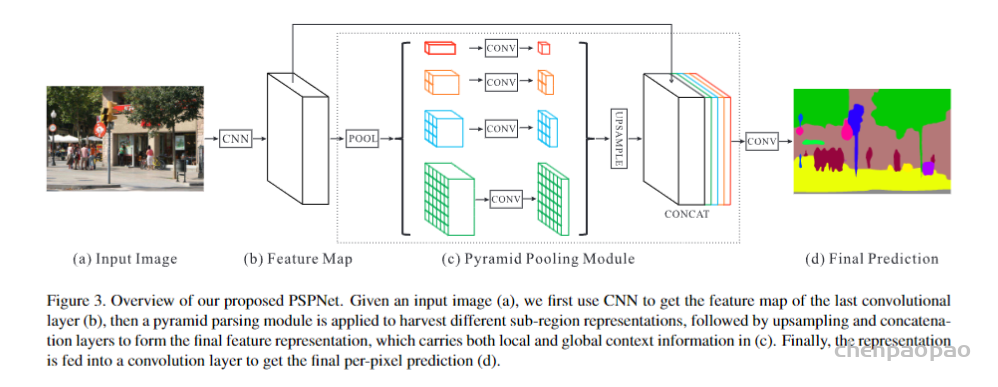
可以看到,将输入图像(a)经过CNN网络提取之后的特征图(b)送入到一个金字塔池化模块(Pyramid Pooling Module,PPM),在该模块中(c),使用四种不同尺度的全局池化(1*1、2*2、3*3和6*6)进行下采样并结合1*1卷积来生成降维后的上下文信息表征。然后直接使用双线性插值对低分辨率的特征图进行上采样,并与阶段(b)的特征图进行连接,形成最终的全局金字塔池化特征,最后再进行一组卷积后形成最终的语义分割预测结果(d)。基于上述结构,PSPNet对于场景解析任务能够提供有效的全局上下文先验信息,PPM相较于直接的全局池化,能够收集多尺度的信息表征,并且在计算开销上相比于FCN也增加不多。此外PSPNet训练时为防止梯度消失还添加了辅助损失函数作为一种深监督机制。
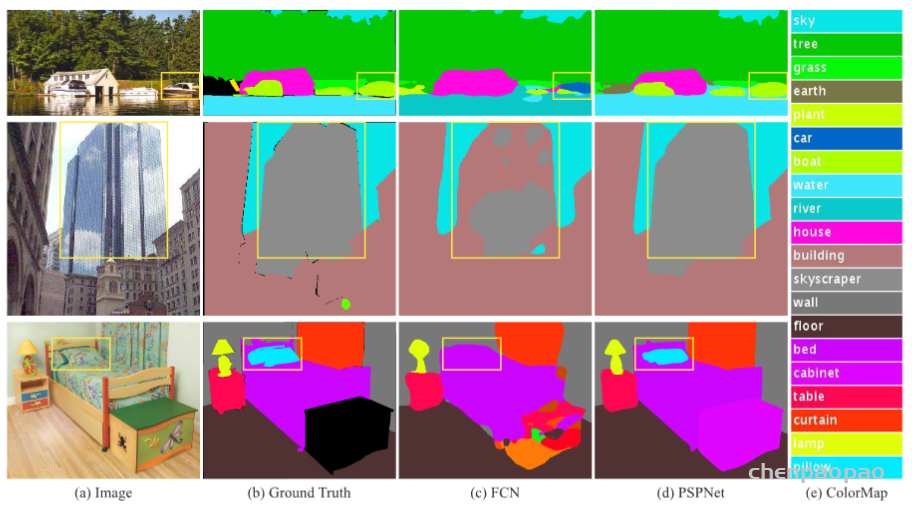
PSPNet在ADE20K、PASCAL VOC 2012以及Cityscapes数据集上分别进行了测试,均能达到当时SOTA的分割水平。另外也在辅助损失函数和预训练模型等方面做了充分的消融实验(ablation study)。PSPNet在ADE20K数据集上的一组测试效果如图2所示。在三张测试图像上,FCN不能够捕捉图像上下文关系(将第一张图像中水面上的船只识别为汽车),但PSPNet均能够得到很好的分割效果。
网络结构
在encoder之后,使用了金字塔池化模块,使用了四种尺寸的金字塔,池化所用的kerne分别1×1, 2×2, 3×3 and 6×6。池化之后上采样,然后将得到的feature map,包括池化之前的做一个级联(concatenate),后面接一个卷积层得到最终的预测图像。作者提到,和全局池化相比,金字塔池化能提取多尺度的信息。
下述代码给出了PSPNet网络结构的一个简单实现流程。
### 定义PPM模块类
class _PyramidPoolingModule(nn.Module):
def __init__(self, in_dim, reduction_dim, setting):
super(_PyramidPoolingModule, self).__init__()
self.features = []
for s in setting:
self.features.append(nn.Sequential(
nn.AdaptiveAvgPool2d(s),
nn.Conv2d(in_dim, reduction_dim, kernel_size=1, bias=False),
nn.BatchNorm2d(reduction_dim, momentum=.95),
nn.ReLU(inplace=True)
))
self.features = nn.ModuleList(self.features)
# PPM前向计算流程
def forward(self, x):
x_size = x.size()
out = [x]
for f in self.features:
out.append(F.upsample(f(x), x_size[2:], mode='bilinear'))
out = torch.cat(out, 1)
return out
### 定义PSPNet类
class PSPNet(nn.Module):
def __init__(self, num_classes, use_aux=True):
super(PSPNet, self).__init__()
self.use_aux = use_aux
# 使用ResNet101作为预训练模型
resnet = models.resnet101()
self.layer0 = nn.Sequential(resnet.conv1, resnet.bn1, resnet.relu, resnet.maxpool)
self.layer1, self.layer2, self.layer3, self.layer4 = resnet.layer1, resnet.layer2, resnet.layer3, resnet.layer4
for n, m in self.layer3.named_modules():
if 'conv2' in n:
m.dilation, m.padding, m.stride = (2, 2), (2, 2), (1,1)
elif 'downsample.0' in n:
m.stride = (1, 1)
for n, m in self.layer4.named_modules():
if 'conv2' in n:
m.dilation, m.padding, m.stride = (4, 4), (4, 4), (1,1)
elif 'downsample.0' in n:
m.stride = (1, 1)
self.ppm = _PyramidPoolingModule(2048, 512, (1, 2, 3, 6))
self.final = nn.Sequential(
nn.Conv2d(4096, 512, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(512, momentum=.95),
nn.ReLU(inplace=True),
nn.Dropout(0.1),
nn.Conv2d(512, num_classes, kernel_size=1)
)
# 深监督辅助损失
if use_aux:
self.aux_logits = nn.Conv2d(1024, num_classes, kernel_size=1)
initialize_weights(self.aux_logits)
initialize_weights(self.ppm, self.final)
### PSPNet前向计算流程
def forward(self, x):
x_size = x.size()
x = self.layer0(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
if self.training and self.use_aux:
aux = self.aux_logits(x)
x = self.layer4(x)
x = self.ppm(x)
x = self.final(x)
if self.training and self.use_aux:
return F.upsample(x, x_size[2:], mode='bilinear'), F.upsample(aux, x_size[2:], mode='bilinear')
return F.upsample(x, x_size[2:], mode='bilinear')代码:https://github.com/4uiiurz1/pytorch-nested-unet/blob/master/archs.py
论文:https://arxiv.org/abs/1807.10165
论文作者的知乎讲解:https://zhuanlan.zhihu.com/p/44958351

UNet的编解码结构一经提出以来,大有统一深度学习图像分割之势,后续基于UNet的改进方案也经久不衰,一些研究者也在从网络结构本身来思考UNet的有效性。比如说编解码网络应该取几层,跳跃连接是否能够有更多的变化以及什么样的结构训练起来更加有效等问题。UNet本身是针对医学图像分割任务而提出来的网络结构,该任务不像自然图像分割,对分割精度要求并不是十分严格。但对于医学图像而言,器官和病灶的分割则要求极高的精确性,因为很多时候分割效果的好坏直接关系到对应的临床诊断决策。出于上述两个方面的动机,即设计更好的UNet结构和提升医学图像分割的精度,相关研究者提出了一种嵌套的UNet结构(Nested UNet),也叫UNet++,提出UNet++的论文为UNet++: A Nested U-Net Architecture for Medical Image Segmentation,发表于2018年的医学图像计算和计算机辅助干预(Medical Image Computing and Computer Assisted Intervention,MICCAI)会议上。
UNet++取名为嵌套的UNet,就在于其整体编解码网络结构中还嵌套了编解码的子网络(sub-networks),在此基础上重新设计UNet中间的跳跃连接,并补充了深监督机制加速网络训练收敛。完整的UNet++结构如下图所示。
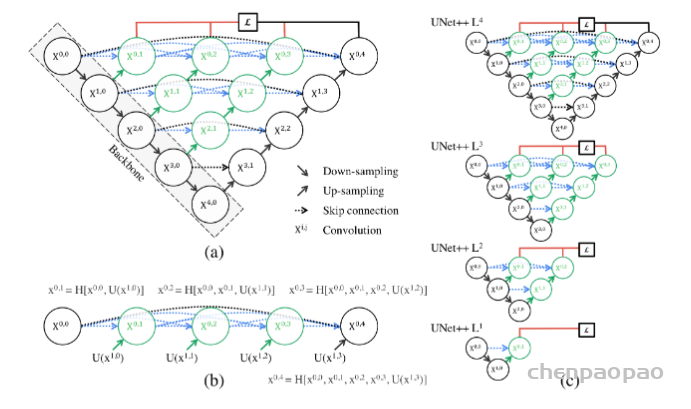
图中黑色部分为原始的UNet结构,包括编码器下采样、解码器上采样和黑色虚线的跳跃连接三个部分;绿色部分即嵌套的UNet子网络,包括卷积和上采样两部分,而蓝色虚线部分就是UNet++重新设计后的跳跃连接,这部分跟DenseNet的密集连接类似,这里是为子网络提供跳跃连接;最上面红黑连线则是UNet++补充的深监督机制,目的是为了网络能够顺利得到训练。
下面我们从结构设计的角度来对UNet++进行解读。关于UNet结构,最首要的问题就是网络应该有几层,原始的UNet结构用了4层下采样和4层上采样,那么是不是4层就足以满足所有的分割任务需要?答案是否定的。通过本节之前的网络结构分析,我们已经知道,浅层网络能够提取图像粗粒度特征,获取图像基本形态;深层网络能够提取图像的抽象特征,获取图像语义信息,总之浅有浅的侧重,深有深的好处。同之前RefineNet的观点一样,UNet++的作者认为,不管是浅层、深层还是中层,所有层次的特征对于最后的分割都是重要的。有的数据分割任务简单,图像信息单一,可能浅层网络就足以达到很好的效果,而有的数据任务复杂,图像信息丰富,可能需要更深层的网络结构才能达到不错的效果,之前的UNet结构设计很难同时照顾到这种普适性。而UNet++通过设计不同深度的嵌套UNet子网络来实现这种普适性,所以UNet的深度到这里就解决了。
第二个问题则是加入不同深度的嵌套网络后,跳跃连接部分该如何调整。在UNet中,跳跃连接由同层编码器直连到编码器上采样对应层。但加入嵌套子网络后,UNet中原先的长连接就不复存在了,取而代之的是各子网络中的短连接。UNet++的作者们认为,长连接在UNet中是有必要的,能够将图像中前后信息联系起来,对于下采样造成的信息损失有很好的补充作用。所以,UNet++又参考DenseNet的密集连接设计,给嵌套网络补充了长连接,如上图所示。
但是这样又带来了第三个问题:反向传播的时候中间部分可能会收不到由损失函数反传回来的梯度。所以见招拆招,UNet++又通过深监督的方法来强行加梯度,帮助网络正常进行训练。但深监督对于UNet++的好处绝不仅仅限于此,通过不同深监督损失函数,UNet++可以通过网络剪枝来实现可伸缩性。所以,总结来说UNet++相较于原始的UNet,有如下两个优势:
(1)通过嵌套子网络和长短连接来整合不同层次的图像特征,使得网络分割精度更高;
(2)灵活的网络结构配合深监督机制,让参数量巨大的深度网络在可接受的精度范围内能够大幅度的缩减参数量。
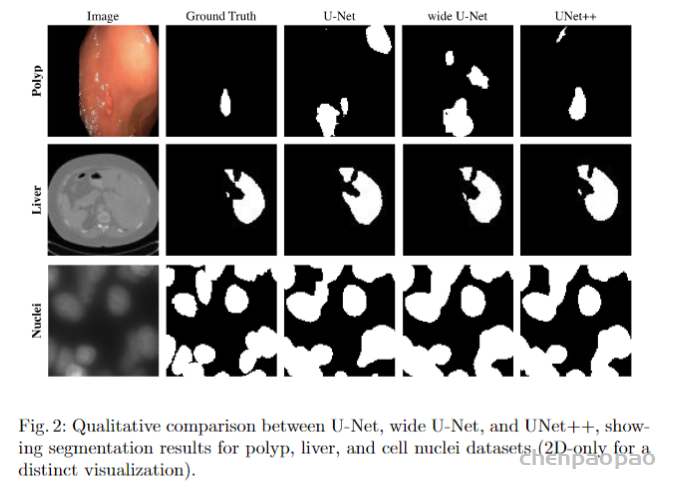
UNet++与UNet等网络分割效果对比如下图所示。
UNet++也进一步壮大了UNet家族网络,后续基于其的改进版本也有很多,比如Attention UNet++、UNet 3+等。下述代码给出了UNet++的一个实现参考。
class NestedUNet(nn.Module):
def __init__(self, num_classes, input_channels=3, deep_supervision=False, **kwargs):
super().__init__()
nb_filter = [32, 64, 128, 256, 512]
self.deep_supervision = deep_supervision
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])
self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])
self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])
self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])
self.conv0_1 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_1 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_1 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3])
self.conv0_2 = VGGBlock(nb_filter[0]*2+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_2 = VGGBlock(nb_filter[1]*2+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_2 = VGGBlock(nb_filter[2]*2+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv0_3 = VGGBlock(nb_filter[0]*3+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_3 = VGGBlock(nb_filter[1]*3+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv0_4 = VGGBlock(nb_filter[0]*4+nb_filter[1], nb_filter[0], nb_filter[0])
if self.deep_supervision:
self.final1 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final2 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final3 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final4 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
else:
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def forward(self, input):
x0_0 = self.conv0_0(input)
x1_0 = self.conv1_0(self.pool(x0_0))
x0_1 = self.conv0_1(torch.cat([x0_0, self.up(x1_0)], 1))
x2_0 = self.conv2_0(self.pool(x1_0))
x1_1 = self.conv1_1(torch.cat([x1_0, self.up(x2_0)], 1))
x0_2 = self.conv0_2(torch.cat([x0_0, x0_1, self.up(x1_1)], 1))
x3_0 = self.conv3_0(self.pool(x2_0))
x2_1 = self.conv2_1(torch.cat([x2_0, self.up(x3_0)], 1))
x1_2 = self.conv1_2(torch.cat([x1_0, x1_1, self.up(x2_1)], 1))
x0_3 = self.conv0_3(torch.cat([x0_0, x0_1, x0_2, self.up(x1_2)], 1))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)], 1))
x2_2 = self.conv2_2(torch.cat([x2_0, x2_1, self.up(x3_1)], 1))
x1_3 = self.conv1_3(torch.cat([x1_0, x1_1, x1_2, self.up(x2_2)], 1))
x0_4 = self.conv0_4(torch.cat([x0_0, x0_1, x0_2, x0_3, self.up(x1_3)], 1))
if self.deep_supervision:
output1 = self.final1(x0_1)
output2 = self.final2(x0_2)
output3 = self.final3(x0_3)
output4 = self.final4(x0_4)
return [output1, output2, output3, output4]
else:
output = self.final(x0_4)
return output最后,给出作者在知乎上的一段总结:
回顾一下这次分享,我问了好多问题,也提供了其中一些我个人给出的解释。
一顿听下来,热心的网友可能会懵了,就这么个分割网络,都能说这么久,要我说就放个结构图,说这个网络很牛逼,再告知一下代码在哪儿,谢谢大家就完事儿了。
其实搞学术做研究不是这样子的,UNet++肯定马上就会被更强的结构所代替,但是要设计出更强的结构,你得首先明白这个结构,甚至它的原型U-Net设计背后的心路历程。与其和大家分享一个苍白的分割网络,我更愿意分享的是这个项目背后从开始认识U-Net,到分析它的组成,到批判性的解读,再到改进思路的形成,实验设计,像刚刚分享过程中一次次尴尬的自问自答,中间那些非常饱满的心路历程。这也是我在博士的两年中学到的做研究的范式。
说句题外话,就跟玩狼人杀一样,你一上来就说自己预言家,验了谁谁谁,那没人信的呀,你得说清楚为什么要验他,警徽怎么留,把这些心路历程都盘盘清楚,身份才能做实。
我在微博上也看到有人说,也想到了非常类似的结构,实验也快做完了,看到了我这篇论文心就凉了。其实网络结构怎么样真的不重要,重要的是你怎么能把故事给讲清楚,要是讲完以后还能够引起更多的思考和讨论那就更好了。我在分享中提到了很多我们论文中的不足之处,也非常欢迎大家可以批评指正。
github: https://github.com/MIC-DKFZ/nnUNet
论文地址: https://arxiv.org/abs/1809.10486

相较于常规的自然图像,以UNet为代表的编解码网络在医学图像分割中应用更为广泛。常见的各类医学成像方式,包括计算机断层扫描(Computed Tomography, CT)、核磁共振成像(Magnetic Resonance Imaging, MRI)、超声成像(Ultrasound Imaging)、X光成像(X-ray Imaging)和光学相干断层扫描(Optical Coherence Tomography, OCT)等。对于临床而言,影像学的检查是一项非常重要的诊断方式。在各类模态的影像检查中,精准地对各种器官和病灶进行分割是影像分析的关键步骤,目前深度学习图像分割在各类影像检测和分割中大放异彩。比如基于胸部CT的肺结节检测、基于颅内MR影像的脑胶质瘤分割、基于心脏CT的左心室分割、基于甲状腺超声的结节检测和基于X光的胸片肺部器官分割等。
虽然基于UNet的系列编解码分割网络在各类医学图像分割上取得了长足的进展,并且部分基于相关模型的应用设计已经广泛用于临床分析中。但医学影像本身的复杂性和差异性也极度影响着分割模型的泛化性和通用性,主要体现在以下几个方面:
(1)各类模态的医学影像之间差异大,如研究队列的大小、图像尺寸和维度、分辨率和体素(voxel)强度等。
(2)分割的语义标签的极度不平衡。相较于影像中的正常组织,病变区域一般都只占极少部分,这就造成了正常组织的体素标签与病灶组织的体素标签之间极度的类不平常。
(3)不同影像数据之间的专家标注差异大,并且一些图像的标注结果会存在模棱两可的情况。
(4)一些数据集在图像几何和形状等属性上差异明显,切片不对齐和各向异性的问题也非常严重。
提出一种鲁棒的基于2D UNet和3D UNet的自适应框架nnUMet。作者在各种任务上拿这个框架和目前的STOA方法进行了比较,且该方法不需要手动调参。最终nnUNet得到了最高的平均dice。
当前的医学图像分割被CNN的方法主导,但是在不同的任务上需要不同的结构和不同的调参策略才达到了各自任务的最佳,这些在某个任务上拿到第一的方法,在其他任务上却不行。
The Medical Segmentation Decathlon计划通过这种方式解决这个问题:希望参赛者设计一种算法,在10种数据集上进行测试,都能够达到很好的效果,而算法不能够针对某种数据集进行人为的调整,只能自动的去适应。
比赛分为两个阶段:(1)开发阶段参与者拿到7个数据集用于优化算法;(2)冻结代码后公开剩余的3个数据集,用于评估。
作者认为过多的人为调整网络结构,会导致对于特定数据集的过拟合。非网络结构方面的影响可能对于分割任务影响更大。
作者提出一种nnUNet(no-new-Net)框架,基于原始的UNet(很小的修改),不去采用哪些新的结构,如相残差连接、dense连接、注意力机制等花里胡哨的东西。相反的,把重心放在:预处理(resampling和normalization)、训练(loss,optimizer设置、数据增广)、推理(patch-based策略、test-time-augmentations集成和模型集成等)、后处理(如增强单连通域等)。
基础版UNet:2D UNet,3D UNet,UNet级联(第一级对下采样低分辨率图像进行粗分割,第二级结合第一级的结果进行微调,两级都用3DUNet)
微小修改:
(1)ReLU换 leaky ReLU(neg.slope 1e-2);
(2)Batch Norm换Instance Norm
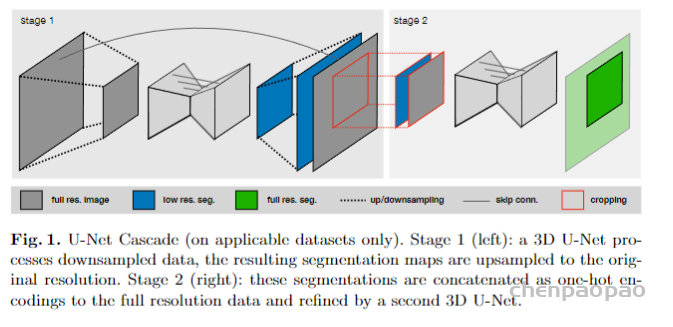
网络拓扑自适应:输入图像尺寸会有不同,而硬件的资源是有限的,因此需要在网络容量和Batch-size上做到权衡。
默认参数设置:
2D UNet:crop-size<=256×256(中值尺寸小于256时,采用中值尺寸); batch-size<=42; base-channel=30; pooling to size>=8; pooling_num<6
3D UNet: crop-size<=128x128x128(中值尺寸小于128时,采用中值尺寸); batch-size>=2; base_channel=30; pooling to size>=8; poolingnum<6
整体数据Crop:只在非零区域内crop,减少计算消耗
Resample:数据集中存在不同spacing的数据,默认自动归一化到数据集所有数据spacing的中值spacing。原始数据使用三阶spline插值;Mask使用最邻近插值。
UNet Cascade采用特殊的Resample策略:中值尺寸大于显存限制下可处理尺寸的4倍时(batch-size=2),采用级联策略,对数据进行下采样(采样2的倍数,直到满足前面的要求);如果数据分辨率三个轴方向不相等,先降采样高分辨率轴使得三轴相等,再三轴同时降采样直到满足上述要求。
Normalization:
CT:通过统计整个数据集中mask内像素的HU值范围,clip出[0.05,99.5]百分比范围的HU值范围,然后使用z-score方法进行归一化;
MR:对每个患者数据单独执行z-score归一化。
如果crop导致数据集的平均尺寸减小到1/4甚至更小,则只在mask内执行标准化,mask设置为0.
从头训练,使用五折交叉验证,loss函数:结合dice loss和交叉熵loss:

对于在全训练集上训练的3D-UNet(UNet Cascade的第一阶段和非级联的3D UNet,不包括UNet Cascade的第二阶段),对每一个样本单独计算dice loss,然后在batch上去平均。对其他的网络(2D UNet和UNet Cascade的第二阶段),将一个batch内的所有样本当做一个整体的样本计算整个batch上的dice(防止当crop后出现局部区域内不存在某一类时单独计算该类loss导致分母为零的情况,这也要保证batch-size不能太小)。
dice loss形式如下:

其中u为概率输出(softmax output),v为硬编码(one hot encoding)的ground truth。K为多分类类别数。
其他训练参数:
Adam优化器,学习率3e-4;250个batch/epoch;
学习率调整策略:计算训练集和验证集的指数移动平均loss,如果训练集的指数移动平均loss在30个epoch内减少不够5e-3,则学习率衰减5倍;
训练停止条件:当验证集指数移动平均loss在60个epoch内减少不够5e-3,或者学习率小于1e-6,则停止训练。
数据增广:随机旋转、随机缩放、随机弹性变换、伽马校正、镜像。
注意:
1.如果3D UNet的输入patch的尺寸的最大边长是最短边长的两倍以上,那么应用三维数据扩充可能是次优的。这种情况下可以使用2D的数据增广。
2.UNet Cascade的stage 2接收前一阶段的输出作为输入的一部分,为了防止强co-adaptation,我们可以应用随机形态学操作(erode、dilate、open、close),随机的去除掉一些分割结果的连通域。
patch采样:为了增加网络的稳定性,patch采样的时候会保证一个batch的样本中有超过1/3的像素是前景类的像素。这个很关键,否则你的前景dice会收敛的很慢。
所有的推理都是基于patch的。
patch的边界上精度会有损,因此在对patch重叠处的像素进行fuse时,边界的像素权重低,中心的像素权重高;patch重叠的stride为size/2;使用test-data-augmentation(增广方式:绕各个轴的镜像增广);使用了5个训练的模型集成进行推理(5个模型是通过5折交叉验证产生的5个模型)
主要就是使用连通域分析