官网:https://www.cityscapes-dataset.com/
这个大型数据集包含了来自50个不同城市的街景场景中记录的多样化的双目视频序列,除了20000个弱注释帧以外,还有5000帧的高质量像素级注释。
主要参考如下:
下载前3个文件即可。其中3文件代表训练使用的原图,1文件代表精细标注label,2文件代表非精细标注label。有的同学要问了,那我下载1、3不就行了吗?我要这2有何用?其实Cityscapes数据集提供了34种分类,但有时我们不需要那么多,比如仅需要19分类(默认的)或任意多个分类,进行图像语意分割的神经网络训练,我们就需要用到他Cityscapes提供的自带工具进行label的转换,若缺少2文件,转换代码会报错无法进行。

该数据集由gtFine和leftImg8bit这两个目录组成,结构如下所示,其中aachen等表示拍摄场景的城市名:
├── gtFine
│ ├── train
│ │ ├── aachen
│ │ ├── bochum
│ │ └── bremen
│ └── val
│ └── frankfurt
└── leftImg8bit
├── train
│ ├── aachen
│ ├── bochum
│ └── bremen
└── val
└── frankfurt
原图存放在leftImg8bit文件夹中,精细标注的数据存放在gtFine (gt : ground truth) 文件夹中 。其中训练集共2975张(train),验证集500张(val),都是有相应的标签的。但测试集(test)只给了原图,没有给标签,官方用于线上评估大家提交的代码(防止有人用test集训练刷指标)。因此,实际使用中可以用validation集做test使用。
标签文件中每张图像对应4个文件,其中_gtFine_polygons.json存储的是各个类和相应的区域(用多边形顶点的位置表示区域的边界);_gtFine_labelIds.png的值是0-33,不同的值代表不同的类,值和类的对应关系在代码中cityscapesscripts/helpers/labels.py中定义;_gtFine_instaceIds.png是示例分割的; _gtFine_color.png是给大家可视化的,不同颜色与类别的对应关系也在labels.py文件中说明。
可以使用Cityscapes的coarse标签做初步训练然后再用精细标签训练这个数据集包含语义分割,实例分割,深度估计等标签数据,对应的训练标签如下所示:
cd $CITYSCAPES_ROOT
# 训练和校准对应的数据集
ls leftImg8bit/train/*/*.png > trainImages.txt
ls leftImg8bit/val/*/*.png > valImages.txt
# 训练和校准标签对应的数据集
ls gtFine/train/*/*labelIds.png > trainLabels.txt
ls gtFine/val/*/*labelIds.png.png > valLabels.txt
# 训练和校准实例标签对应的数据集
ls gtFine/train/*/*instanceIds.png > trainInstances.txt
ls gtFine/val/*/*instanceIds.png.png > valInstances.txt
# 训练和校准深度标签对应的数据集
ls disparity/train/*/*.png > trainDepth.txt
ls disparity/val/*/*.png.png > valDepth.txt另外,torchvision支持很多现成数据集:

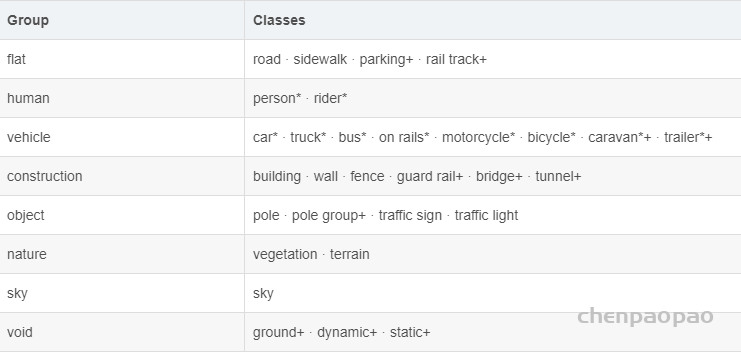
Class Definitions:
cityscapesscripts 脚本工具:

cityscapes scripts公开以下工具:
csDownload: 命令行下载cityscapes包csViewer: 查看图像并覆盖批注(overlay the annotations)。csLabelTool: 标注工具.csEvalPixelLevelSemanticLabeling: Evaluate pixel-level semantic labeling results on the validation set. This tool is also used to evaluate the results on the test set.像素级评估csEvalInstanceLevelSemanticLabeling: Evaluate instance-level semantic labeling results on the validation set. This tool is also used to evaluate the results on the test set.实例级评估csEvalPanopticSemanticLabeling: Evaluate panoptic segmentation results on the validation set. This tool is also used to evaluate the results on the test set.全景分割评估csCreateTrainIdLabelImgs: Convert annotations in polygonal format to png images with label IDs, where pixels encode “train IDs” that you can define inlabels.py.将多边形格式的注释转换为带标签ID的png图像,其中像素编码“序列ID”,可以在labels.py中定义。csCreateTrainIdInstanceImgs: Convert annotations in polygonal format to png images with instance IDs, where pixels encode instance IDs composed of “train IDs”.将多边形格式的注释转换为具有实例ID的png图像,其中像素对由“序列ID”组成的实例ID进行编码。csCreatePanopticImgs: Convert annotations in standard png format to COCO panoptic segmentation format.将标准png格式的注释转换为COCO全景分割格式。
cityscapes scripts文件夹
文件夹内容如下:
helpers: 被其他脚本文件调用的帮助文件viewer: 用于查看图像和标注的脚本preparation: 用于将GroundTruth注释转换为适合您的方法的格式的脚本evaluation: 评价你的方法的脚本annotation: 被用来标注数据集的标注工具download: 下载Cityscapes packages
请注意,所有文件顶部都有一个小型documentation。 非常重要
helpers/labels.py: 定义所有语义类ID的中心文件,并提供各种类属性之间的映射。helpers/labels_cityPersons.py: 文件定义所有CityPersons行人类的ID并提供各种类属性之间的映射。viewer/cityscapesViewer.py查看图像并覆盖注释。preparation/createTrainIdLabelImgs.py将多边形格式的注释转换为带有标签ID的png图像,其中像素编码可以在“labels.py”中定义的“训练ID”。preparation/createTrainIdInstanceImgs.py将多边形格式的注释转换为带有实例ID的png图像,其中像素编码由“train ID”组成的实例ID。evaluation/evalPixelLevelSemanticLabeling.py该脚本来评估验证集上的像素级语义标签结果。该脚本还用于评估测试集的结果。evaluation/evalInstanceLevelSemanticLabeling.py该脚本来评估验证集上的实例级语义标签结果。该脚本还用于评估测试集的结果。setup.py运行setup.py build_ext --inplace启用cython插件以进行更快速的评估。仅针对Ubuntu进行了测试。