GitHub:https://github.com/facebookresearch/encodec
Paper:https://arxiv.org/abs/2210.13438
高保真神经网络音频编码器:
本文介绍了meta推出的音频AI Codec,其整体风格深受Google的SoundStream的影响。在其影响下改进了原有的鉴别器,引入语言模型进一步降低码率,并提出了一种提升稳定性的训练策略。
- 与之前的AI Codec的动机相同,本文同样希望借助深度学习设计一款端到端多码率、立体声音频编码器,实现对语音和音乐的低码率压缩并高质量还原。
- 神经网络天然的抽象特征提取能力使其具有相比传统编码器更强的信号表征压缩能力,低码率的问题相对并不困难;
- 难点主要有两点:1. 音频的动态范围过大;2. 模型效率问题(计算复杂度和参数量)
本文贡献:
- 为解决音频动态范围过大的问题,使用庞大多样的训练集以及用鉴别器作为感知损失(这点似乎相比SoundStream)也并未见有什么突破;
- 限制在单核CPU上实时运行,并采用残差矢量量化(Residual Vector Quantization, RVQ)提高编码效率;
- 提出了语言模型进一步降低码率;
- 鉴别器采用多分辨率复数谱STFT鉴别器;
- 提出了一种balancer以保证GAN训练的稳定性
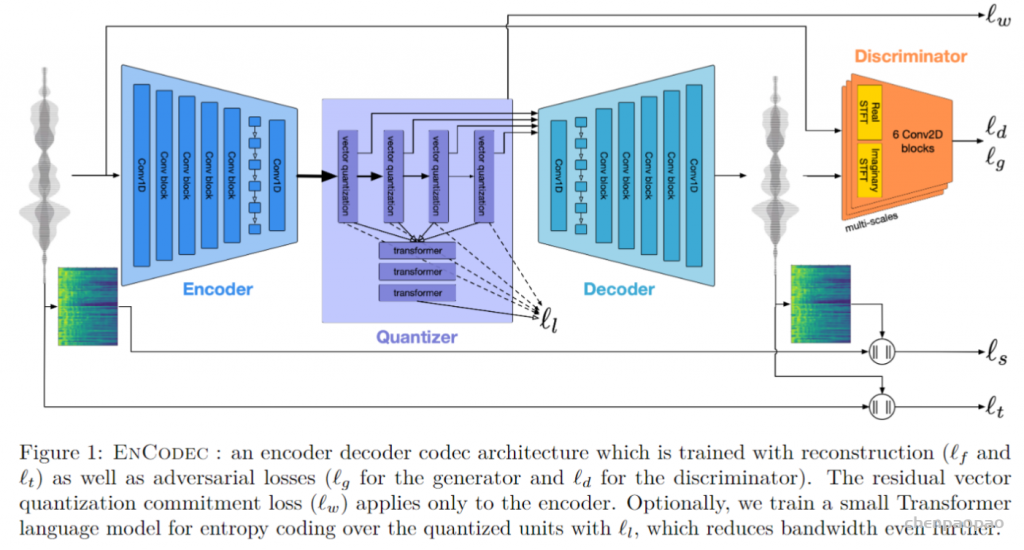
模型采用的基于GAN的模型,生成器采用时域编码器-量化器-解码器结构,鉴别器采用多分辨率的STFT鉴别器。
编解码器:编解码器采用SEANET,编码器由一层一维卷积对时域波形进行特征提取后经过B个用于降采样的残差单元(即convolurion blocks),而后加入了两层LSTM用于序列建模,最后经过一层卷积得到音频的潜在表征。解码器则是编码器的镜像,其中残差单元的卷积被替换为反卷积用于上采样。根据文中采用的下采样因子(通过卷积的stride实现){2,4,5,8},其编码器将音频下采样320倍(2x4x5x8=320),即传输的一帧中压缩了320倍采样点,因此在采样率为24kHz时1s的音频经编码器输出的时间维数为24000/320=75,48kHz时为48000/320=150。通过卷积的Padding和调整Nomalization去设置模型是否流式。
量化器:量化器采用残差矢量量化RVQ,关于RVQ的详细介绍参看[1]和[2]。每个码书包含1024个向量(entries),对于采样率为24kHz的音频,最多使用32个码书,即最大码率为32xlog_2(1024)/13.3=24kbps。为了支持多码率,训练过程中码书数量被设置为{2,4,8,16,32},分别对应1.5kbps,3kbps,6kbps,12kbps,24kbps;且每个码率在训练时所使用的鉴别器是不同的。
语言模型和熵编码:此部分可选,使用Transormer语音模型对RVQ得到的索引映射到新隐藏空间的概率分布,对对应概率密度函数的累积分布函数进行Range Coder熵编码,从而进一步降低码率。
鉴别器:短时傅立叶变换(STFT)。采用多分辨率复数STFT鉴别器,而非TTS中常见的多分辨率Mel谱鉴别器,也没加Multiple-period 鉴别器MPD(消融实验显示多分辨率复数STFT鉴别器性能更优,额外引入MPD有少量性能提升,但考虑训练时长舍弃)。每个分辨率的鉴别器有二维卷积组成,结构如图所示(注意:其中正文和图中的卷积核尺寸不一致,3×8 v.s. 3×9)。
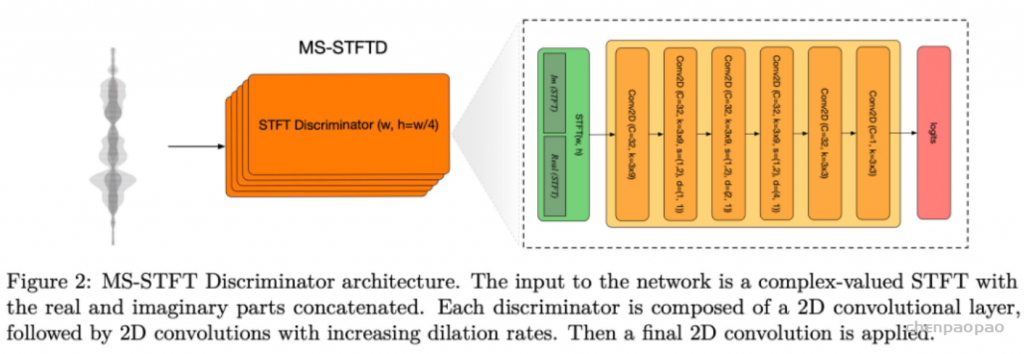
鉴别器采用hinge loss训练,为保证生成器和鉴别器训练平衡稳定,鉴别器以2/3的概率更新其参数
生成器的损失函数:包括重构损失、感知损失(实为对抗损失)以及RVQ的commitment loss三部分,重构损失包括时域和频域两部分,时域损失是波形的L1损失,,频域损失是多时间尺度的Mel谱损失,对抗损失采用hinge loss和特征匹配损失。commitment loss用于使VQ选择的向量满足量化后的变量与未量化的变量间最相近,采用欧式距离度量
数据增广策略:多数据源混合;加混响;音量标准化并随机化增益-10~6 dB;无clip