浙大三维视觉团队提出ENeRF,首次实现动态场景的实时照片级渲染 (SIGGRAPH Asia 2022)
论文链接:https://arxiv.org/abs/2112.01517
论文代码:https://github.com/zju3dv/ENeRF
论文主页:https://zju3dv.github.io/enerf/
摘自: https://zhuanlan.zhihu.com/p/586595657
1.1 论文的问题描述
输入是多个相机在固定机位拍摄的某个动态场景的多目视频,论文希望能生成该动态场景的自由视点视频。该问题有许多应用,例如虚拟呈现,电影游戏制作等。

1.2 当前方法在这个问题上的局限性
为了支持自由视点视频的应用,自由视点视频的渲染效果需要足够逼真,生成制作需要足够快,生成后在用户端的渲染也需要足够快。
最近一些方法基于隐式神经表示,利用体渲染技术优化场景表示,从而制作自由视点视频。D-NeRF[Pumarola et al., CVPR 2021] 利用隐式神经表示恢复了动态场景的motions,实现了照片级别的真实渲染。但是,这一类方法很难恢复复杂场景的motions,他们训练一个模型需要从几小时到几天不等的时间。此外,渲染一张图片通常需要分钟级的时间。
基于图像的渲染技术克服了以上方法的一些问题。第一,对于动态场景,IBRNet[Wang et al., CVPR 2021]能够把每一帧图像都当作单独的场景处理,从而不需要恢复场景的motions。第二,基于图像的渲染技术可以通过预训练模型避免每一时刻的重新训练。但是,IBRNet渲染一张图片仍然需要分钟级的时间。
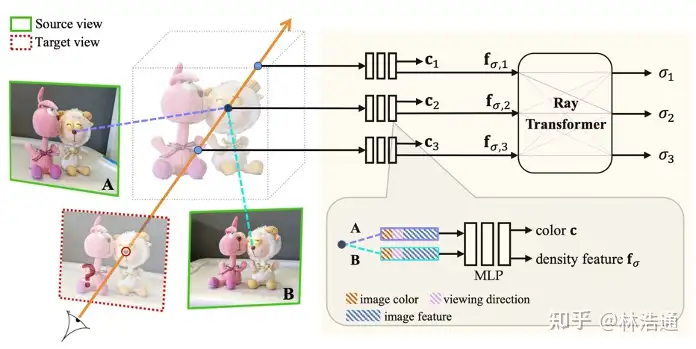
1.3 我们的观察和对问题的解决
为了解决基于图像的渲染技术渲染过慢的问题,论文提出结合显式表示和隐式表示两者的优点。具体而言,我们观察到通过MVS方法预测显式表示,例如深度图像,通常是很快的。利用此显式表示去引导隐式表示的体渲染过程中的采样,能够大幅降低此前方法在空间内密集采样点(包括空地方的点和被遮挡的点)造成的计算开销,从而实现加速。
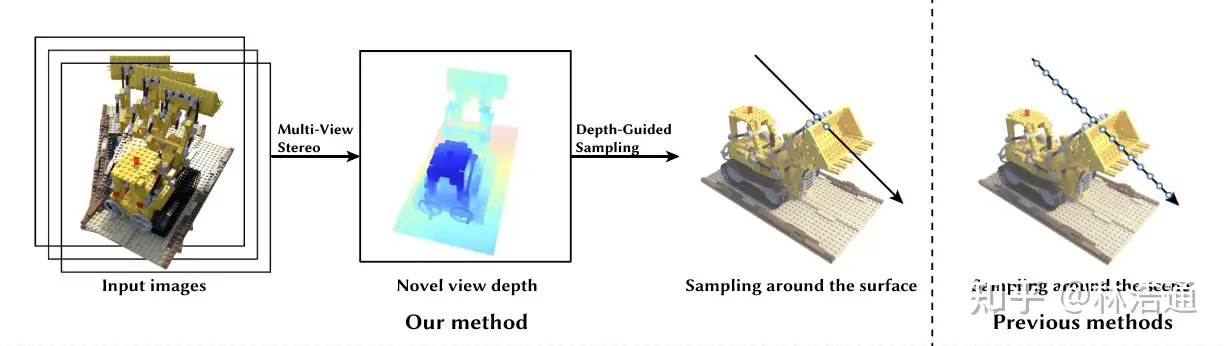
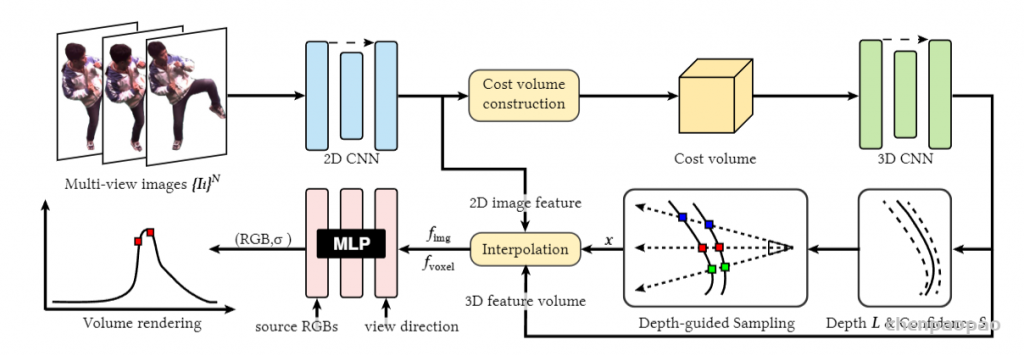
2. 论文方法
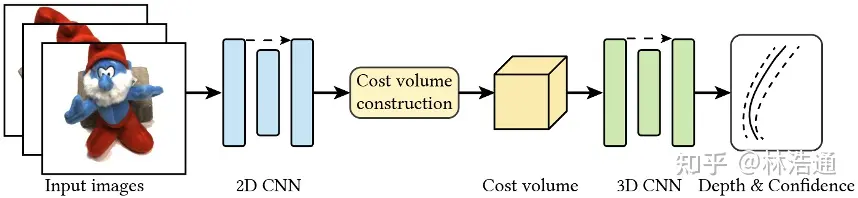
2.1 基于MVS方法预测新视角的深度图像
我们首先使用MVS方法预测新视角的深度图像。给定标定好的相机姿态,我们利用待渲染的视角空间上临近的图像建立级联代价体,使用3D卷积网络处理代价体获得深度图像以及置信区间。
2.2 在场景的表面附近预测辐射场
给定上一步预测的深度置信区间,我们在此区间内采样若干点,通过图像特征和3D卷积网络得到的3D特征体,泛化的预测这些采样点的辐射场和密度。

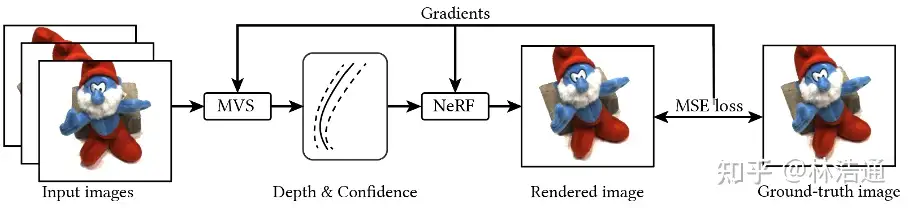
2.3 使用RGB图像优化ENeRF
在得到渲染结果后,我们使用图像的均方差损失函数端到端的优化网络参数。我们实验发现仅使用RGB图像优化网络参数即可获得高质量的渲染结果。
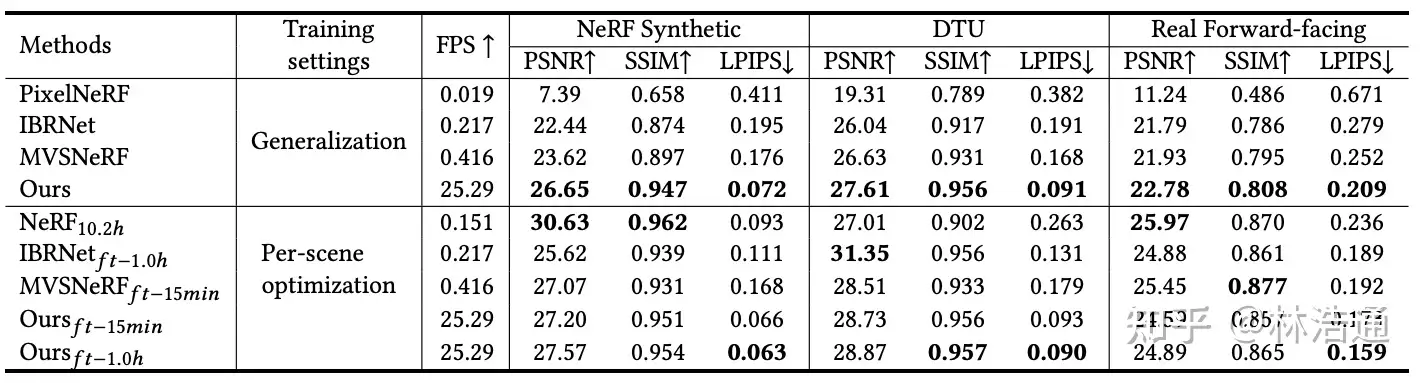
3. 实验分析
3.1 消融实验分析
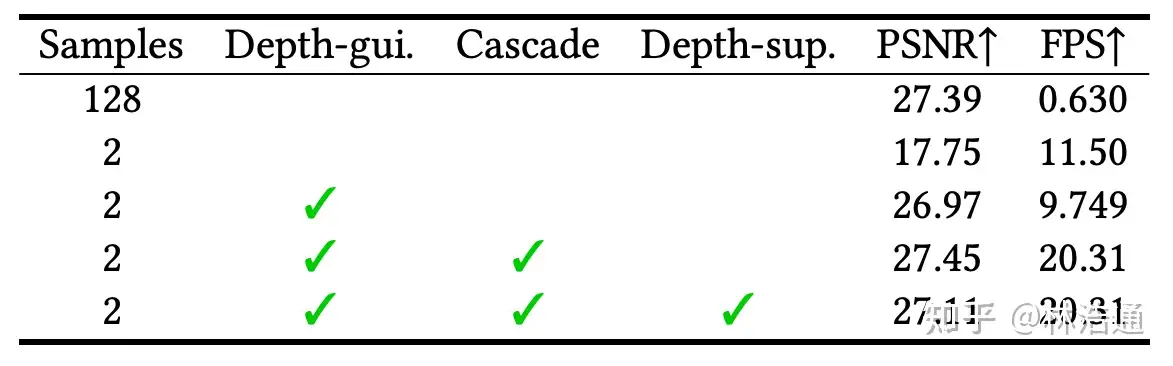
我们提供了消融实验分析去研究论文方法的每一步带来的影响。
第一行展示了基线方法(与MVSNeRF[Chen et al., ICCV 2021]相似),每条光线采样128个点,这样有着好的渲染结果,但是渲染速度比较慢。直接降低采样点的数量后,会导致渲染质量显著下降。使用论文提出的采样方法(Depth-gui.)后,能提升渲染质量,同时基本保持比较快的渲染速度。
为了进一步提高渲染速度,论文使用了级联的设计(Cascade Cost Volume),通过我们仔细的设计,我们将速度从9.7FPS提升到20.31FPS。
此外我们研究了额外使用地面真值深度图像来监督网络学习,我们发现它对最后的渲染质量不会有很大的影响,这说明了论文方法使用RGB图像端到端优化的鲁棒性。
3.2 与SOTA方法的对比
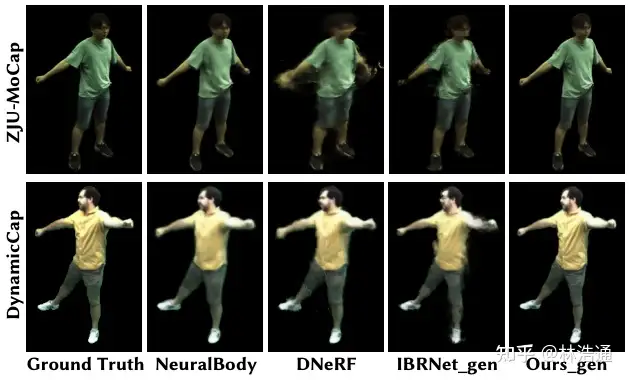
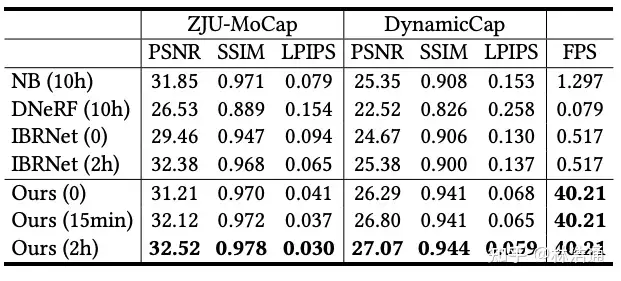
我们在DTU,NeRF Synthetic以及Real Forward-facing静态场景数据集以及ZJUMoCap和DynamicCap动态场景数据集上进行了和之前方法的比较,我们在渲染速度上实现了较大的提升,并且在渲染质量上取得了有竞争力的结果。