
转自:https://mp.weixin.qq.com/s/d7Ab9u1_OAGLF76V1ymHmg
什么是热词
热词 其实是一个特别容易引起歧义的说法,尤其是在语音领域,比如唤醒次/命令词/新词都有人称之为热词,本文中要讨论的热词识别是在语音识别语境下的“上下文词语偏置”对应的英文为 contextual biasing。热词识别到底是做什么的呢?举一个例子就非常清楚了,比如:“今天河南省教育厅有关领导参观了南阳理工大学” 这样一句话,很多的语音识别系统应该会识别成 “今天河南省教育厅有关领导参观了南洋理工大学”,“南阳理工大学”和“南洋理工大学”音同字不同,训练语料中“南洋理工大学”又大概率多于“南阳理工大学”,所以模型非常倾向于输出“南洋理工大学”。热词识别要实现的就是,给定一些外部条件,让系统了解我们当前想要说的是“南阳理工大学”而不是“南洋理工大学”。
热词的实现方法
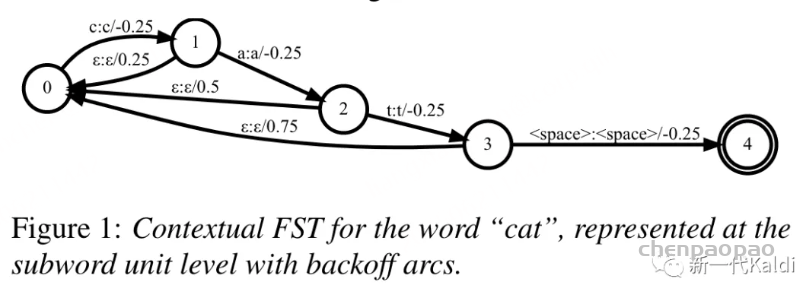
热词的实现方法大致可以分为两大类,一类是纯字符串匹配方法,一类是NN 神经网络 方法。顾名思义,纯字符串匹配的方法就是将解码过程中的所有可能路径都一一去匹配热词列表,如果匹配上热词就给对应的路径加上分数奖励,这样该路径就更有可能在 beam 剪枝中胜出,从而实现识别热词的功能。这种方法一般是在解码阶段实现,对声学部分是透明的,而且可以随意调整奖励的分数,比较灵活。需要解决的核心问题是高效的查找,一般都是基于自动机来实现,在解码器中附带一个类似于下图的热词图。
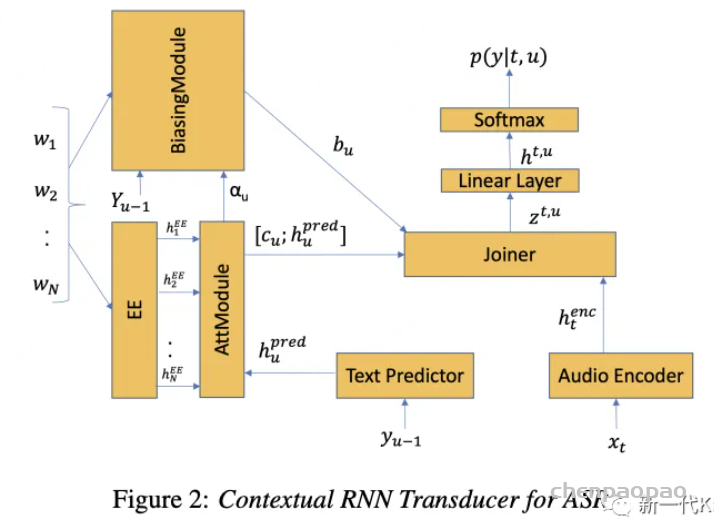
NN 方法其实非常多,近年也是大家发论文的热点(贴一个 awesome https://github.com/stevenhillis/awesome-asr-contextualization,有兴趣的同学可以去看论文),但总的来说就是将热词列表作为神经网络的其中一个输入,以此改变神经网络输出的分布,这样神经网络就能更大概率识别出热词。此种方法的使用需要在训练模型时进行干预,也就是说如果你需要一个带热词识别功能的模型,你就得重新训一个模型,最起码得在不带热词识别功能模型的基础上做 finetune。下图是一种可能的实现方式,通过热词列表来对 transducer 的 predictor 网络进行偏置。
实际的使用中也常常将两者一起配合使用,本文讨论的是第一种纯字符串匹配的热词实现方法。
基于 Aho-corasick 的热词实现
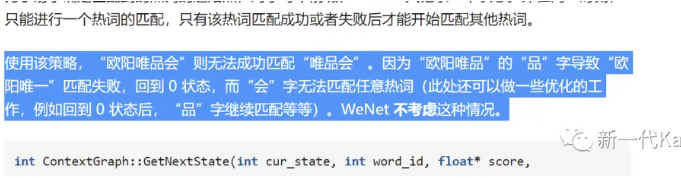
上文提到基于匹配的热词识别主要解决的是匹配效率问题,所以基本都使用自动机来实现,openfst 作为一个高效的自动机实现受到绝大部分人的青睐,但对于热词识别,还是有一些欠缺。比如,如果不进行较复杂的状态管理,则一次只能进行一个热词的匹配,这个问题 wenet 在其实现中有举例说明。如下所示,“唯品会”和“欧阳唯一”都是热词,但“欧阳唯品会”这条路径却无法匹配到“唯品会”。(openfst 当然可以实现这些功能,但会增加复杂度以及影响效率。)
热词的实现本质是一个多模匹配问题,它需要在 hypothesis 中搜索是否包含给定的热词列表,而多模匹配的最佳数据结构就是 Aho-corasick 自动机。关于 Aho-corasick 的构建细节本文不做过多叙述,感兴趣的同学可以阅读 (https://en.wikipedia.org/wiki/Aho%E2%80%93Corasick_algorithm)。
下面将一步一步叙述其怎样用于热词识别,下图是一个包含了热词 { "S", "HE", "SHE", "SHELL", "HIS", "HERS", "HELLO", "THIS", "THEM"} 的状态图(图要有一定复杂度才能够说明问题,爱学习的你一定会认真看的),Aho-corasick 图中主要有三种类型的边,goto 边(黑箭头),failure 边(红箭头) 和 output 边(绿箭头),简单地说,匹配走 goto 边,匹配失败则走 failure 边直到匹配为止或者回到 ROOT 节点,而只要 output 边存在即表示命中热词 (理论上每一个终止节点都有一个指向自己的 output 边,下图中未体现)而且得沿着 output 边的路径一直回溯到没有 output 边为止。
图中每条 goto 边都有一个分数,每个节点含有两个分数(node_score, local_node_score),node_score 为全局节点的分数即从 ROOT 节点到目前的路径分数和,local_node_score为局部节点分数即从上一个中止节点[匹配到热词的节点]到目前的路径分数和,匹配 failure 的分数为 dest.node_score - src.local_node_score(图中未画出,因为 dest 可能需要回溯几条 failure 边才能到达)。我们想在热词局部命中时就给予一定分数奖励,防止 beam search 过程将可能的热词路径剪掉,所以会有如此复杂的分数设计,部分命中给予奖励需要在匹配失败时对已施加的分数进行补偿或消除。奖励分数究竟应该在完全命中后才施加还是局部命中就预先给予,每个人有不同的看法,笔者未进行过严格的性能对比,k2 中目前的实现参照 Deep context (https://arxiv.org/pdf/1808.02480.pdf) 中 on the fly rescoring 一节所述,每匹配一个 token 都会施加分数奖励。
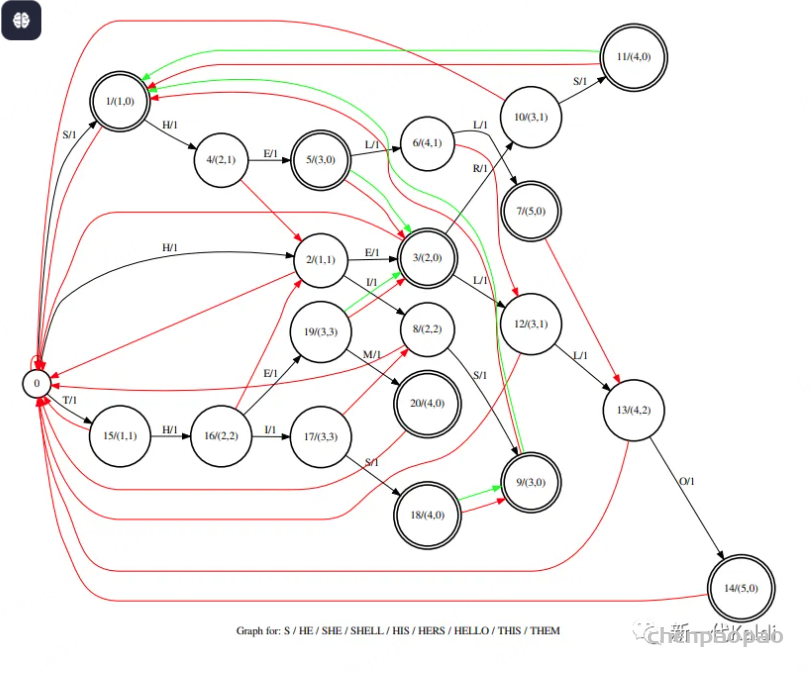
我们以 “DID_HE_WANT_HERS_SHELF” (注意空格 _ 也是字符),来说明整个过程是如何匹配的,以及奖励分数如何作用到路径。“DID_” 几个字符未匹配任何热词的前缀,状态一直停留在 ROOT (ROOT 的 failure 是它自己)。“H” 匹配 state 0 到 state 2 的边获得奖励 1,“E” 匹配 state 2 到 state 3 的边获得奖励 1(total 为2),此时命中 “HE” 获获得奖励 2 (total 为 4),“_” 未匹配上沿着 state 3 的 failure 边回到 ROOT 减去奖励 2 (total 为2),“WAN” 未匹配任何前缀状态一直停留在 ROOT,“T” 匹配 state 0 到 state 15 的边获得奖励 1 (total 为 3),“_” 未匹配上沿着 state 15 的 failure 边回到 ROOT 减去奖励 1 (total 为2),“H” 匹配 state 0 到 state 2 的边获得奖励 1 (total 为3),“E” 匹配 state 2 到 state 3 的边获得奖励 1(total 为4),此时命中 “HE” 获得奖励 2 (total 为 6),“R” 匹配 state 3 到 state 10 的边获得奖励 1(total 为7),“S” 匹配 state 10 到 state 11 的边获得奖励 1(total 为8),此时命中 “HERS” 获得奖励 4 (total 为 12),state 11 包含 output 边指向 state 1 即命中 “S”获得奖励 1 (total 为13), “_” 未匹配上沿着 state 11 的 failure 边回到 ROOT 减去奖励 4 (total 为9),“S” 匹配 state 0 到 state 1 的边获得奖励 1 (total 为 10),此时命中 “S” 获得奖励 1 (total 为11),“H” 匹配 state 1 到 state 4 的边获得奖励 1 (total 为 12),“E” 匹配 state 4 到 state 5 的边获得奖励 1 (total 为 13),此时命中 “SHE” 获得奖励 3 (total 为 16),state 5 还有 output 边指向 state 3 即命中 “HE” 获得奖励 2 (total 为 18),“L” 匹配 state 5 到 state 6 的边获得奖励1 (total 为 19),“F” 为匹配上沿着 state 6 的 failure 边到达 state 12, state 12 依然没能匹配 “F” 沿着 state 12 的 failure 边回到 ROOT 减去奖励 4 (state 6 的 node_score)(total 15),匹配结束。“DID_HE_WANT_HERS_SHELF” 命中 “HE”,“HE”,“HERS” ,“S”,“S”,“SHE”, “HE” 获得 15 的分数奖励。下面还有一些测试样例,可以帮助理解整个匹配过程,实际的热词识别匹配不会这么复杂,能命中一两个热词就已经足够在 beam search 胜出了。
queries = {
"HEHERSHE": 14, # "HE", "HE", "HERS", "S", "SHE", "HE"
"HERSHE": 12, # "HE", "HERS", "S", "SHE", "HE"
"HISHE": 9, # "HIS", "S", "SHE", "HE"
"SHED": 6, # "S", "SHE", "HE"
"HELL": 2, # "HE"
"HELLO": 7, # "HE", "HELLO"
"DHRHISQ": 4, # "HIS", "S"
"THEN": 2, # "HE"
}
for query, expected_score in queries.items():
total_scores = 0
state = context_graph.root
for q in query:
score, state = context_graph.forward_one_step(state, ord(q))
total_scores += score
score, state = context_graph.finalize(state)
assert state.token == -1, state.token
total_scores += score
assert total_scores == expected_score, (
total_scores,
expected_score,
query,
)Wenet 中也有基于 Aho-corasick 实现的热词,但暂时还没有合并,可以在 wenet 仓库的 pull requests 里查找。
一些实验结果
热词的实验结果跟测试集关系很大,下面放的是早期的一些测试结果,具体效果怎样,请在自己的测试集上实验。下面测试中的热词均为测试集对应 transcript 文本上用 NER 工具提取的短语,并做了适当筛选去除特别容易识别的短语。
Aishell 测试集(包含 1073 条热词):
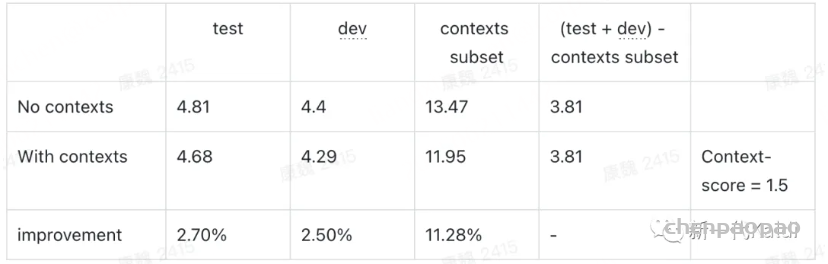
Librispeech 测试集 (包含 487 条热词):
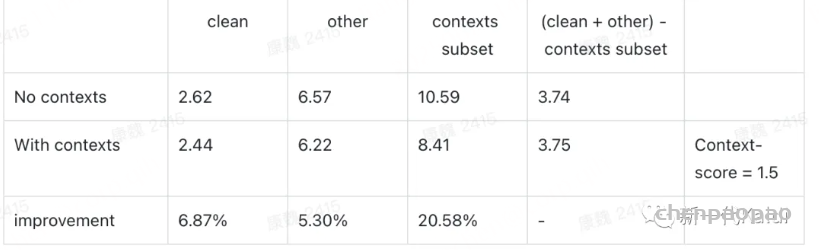
可以看出,该实现对 contexts 子集有较明显的提升,而对其他测试集基本没有影响。
k2 热词功能现状
k2 的热词功能实现已经有一段时间了,由于作者比较懒忙一直没有全面支持,目前 icefall 中的 librispeech pruned_transducer_stateless4 recipe 和 wenetspeech pruned_transducer_stateless5 recipe 已经支持,zipformer 模型正在 PR 中(很快合并)。sherpa 和 sherpa-onnx 中已经实现了核心功能,并且封装了 python 的 API,因为已经有很好的样例,所以我们当然非常希望社区的小伙伴能一起帮忙完善,但如果你们也很懒忙,也可以在微信群告诉我们或者在 github 仓库提 issue,我们会根据需要来安排优先级,目前我们收到的两个提议是支持 sherpa-onnx android 平台 和 sherpa-ncnn。