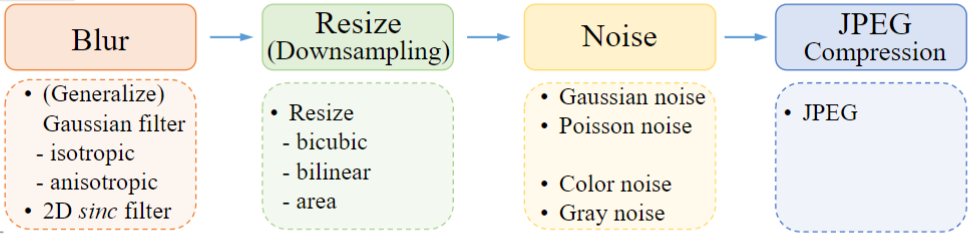
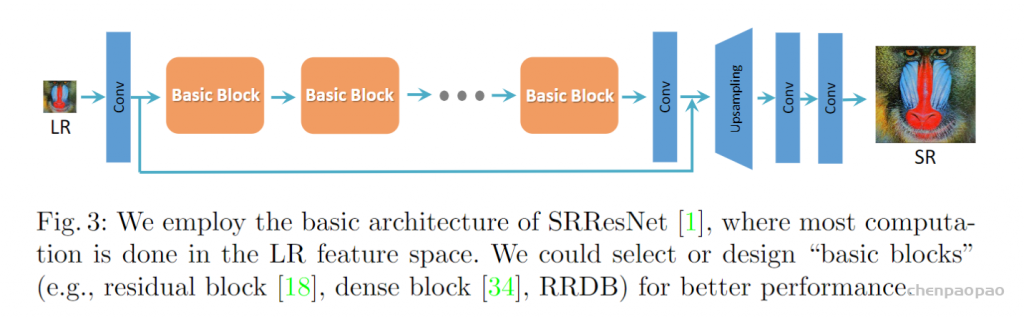
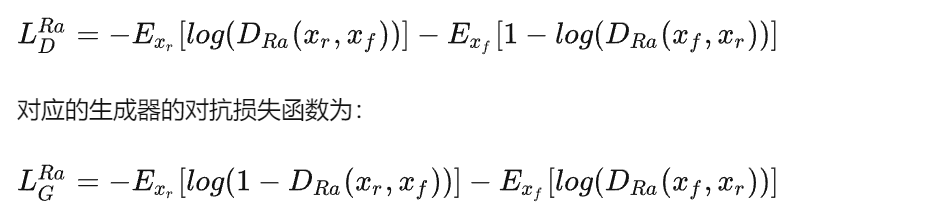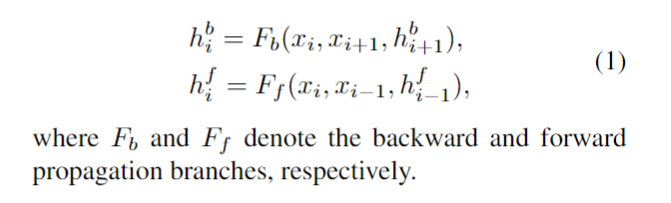For example, when we take a photo with our cellphones, the photos may have several degradations, such as camera blur, sensor noise, sharpening artifacts, and JPEG compression. We then do some editing and upload to a social media APP, which introduces further compression and unpredictable noises.
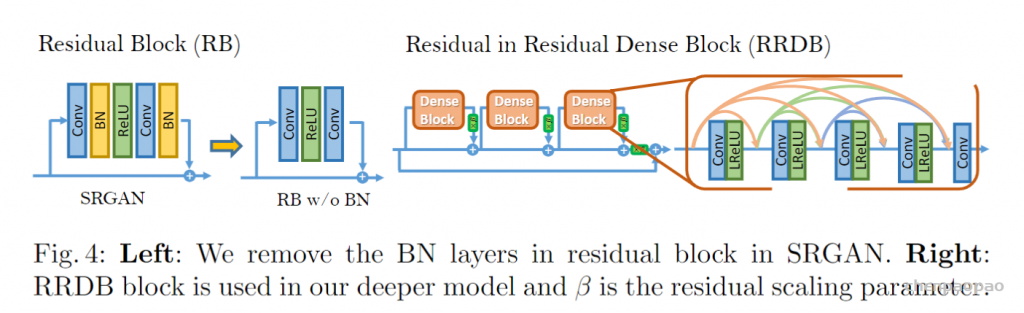
文章对这三点做出改进:1.网络的基本单元从基本的残差单元变为Residual-in-Residual Dense Block (RRDB);2.GAN网络改进为Relativistic average GAN (RaGAN);3.改进感知域损失函数,使用激活前的VGG特征,这个改进会提供更尖锐的边缘和更符合视觉的结果。
class MINCNet(nn.Module):
def __init__(self):
super(MINCNet, self).__init__()
self.ReLU = nn.ReLU(True)
self.conv11 = nn.Conv2d(3, 64, 3, 1, 1)
self.conv12 = nn.Conv2d(64, 64, 3, 1, 1)
self.maxpool1 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv21 = nn.Conv2d(64, 128, 3, 1, 1)
self.conv22 = nn.Conv2d(128, 128, 3, 1, 1)
self.maxpool2 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv31 = nn.Conv2d(128, 256, 3, 1, 1)
self.conv32 = nn.Conv2d(256, 256, 3, 1, 1)
self.conv33 = nn.Conv2d(256, 256, 3, 1, 1)
self.maxpool3 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv41 = nn.Conv2d(256, 512, 3, 1, 1)
self.conv42 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv43 = nn.Conv2d(512, 512, 3, 1, 1)
self.maxpool4 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv51 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv52 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv53 = nn.Conv2d(512, 512, 3, 1, 1)
def forward(self, x):
out = self.ReLU(self.conv11(x))
out = self.ReLU(self.conv12(out))
out = self.maxpool1(out)
out = self.ReLU(self.conv21(out))
out = self.ReLU(self.conv22(out))
out = self.maxpool2(out)
out = self.ReLU(self.conv31(out))
out = self.ReLU(self.conv32(out))
out = self.ReLU(self.conv33(out))
out = self.maxpool3(out)
out = self.ReLU(self.conv41(out))
out = self.ReLU(self.conv42(out))
out = self.ReLU(self.conv43(out))
out = self.maxpool4(out)
out = self.ReLU(self.conv51(out))
out = self.ReLU(self.conv52(out))
out = self.conv53(out)
return out
再引入预训练参数,就可以进行特征提取:
class MINCFeatureExtractor(nn.Module):
def __init__(self, feature_layer=34, use_bn=False, use_input_norm=True, \
device=torch.device('cpu')):
super(MINCFeatureExtractor, self).__init__()
self.features = MINCNet()
self.features.load_state_dict(
torch.load('../experiments/pretrained_models/VGG16minc_53.pth'), strict=True)
self.features.eval()
# No need to BP to variable
for k, v in self.features.named_parameters():
v.requires_grad = False
def forward(self, x):
output = self.features(x)
return output
近日,New Trends in Image Restoration and Enhancement (以下简称:NTIRE) 比赛结果揭晓,旷视研究院荣获双目图像超分辨率赛道的冠军。NTIRE 即“图像恢复与增强的新趋势”,是近年来计算机图像恢复领域最具影响力的一场全球性赛事,由苏黎世联邦理工学院计算机视觉实验室(Computer Vision Laboratory, ETH Zurich)主办,每年都会吸引大量的关注者和参赛者。
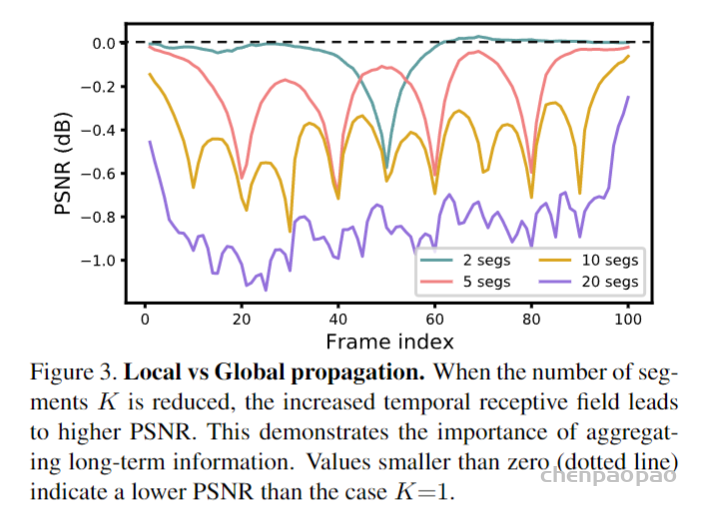
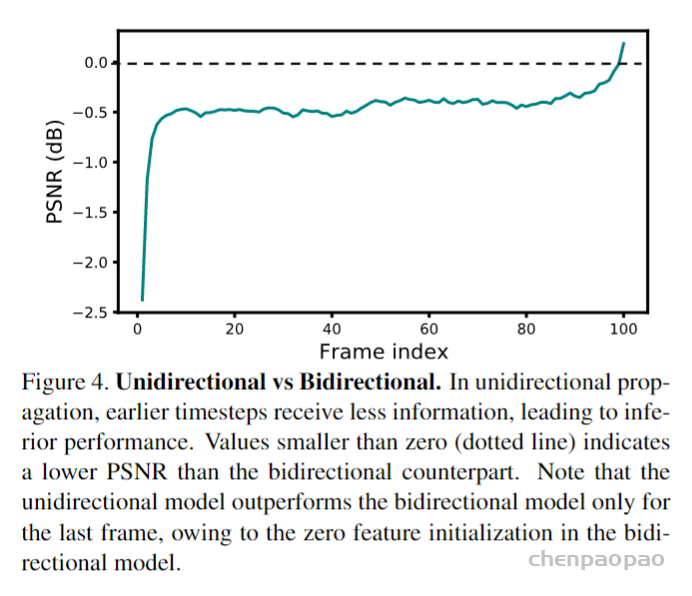
Local Propagation: 滑动窗口的方法(比如RBPN,TGA,EDVR)采用局部窗口内的多帧LR图像作为输入并进行中间帧的重建。这种设计方式约束了信息范围,进而影响了模型的性能。下图给出了不同信息范围下的模型性能对比,可以看到:(1)全局信息的利用具有更佳性能;(2) 片段的两端性能差异非常大,说明了长序列累积信息(即全局信息)的重要性。