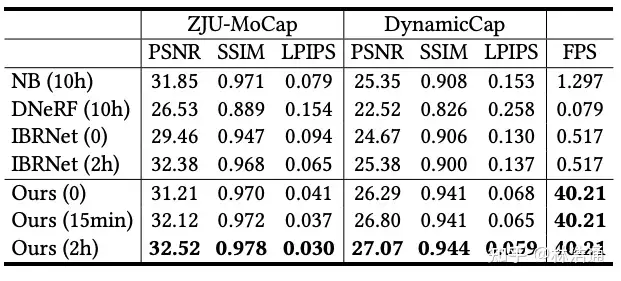
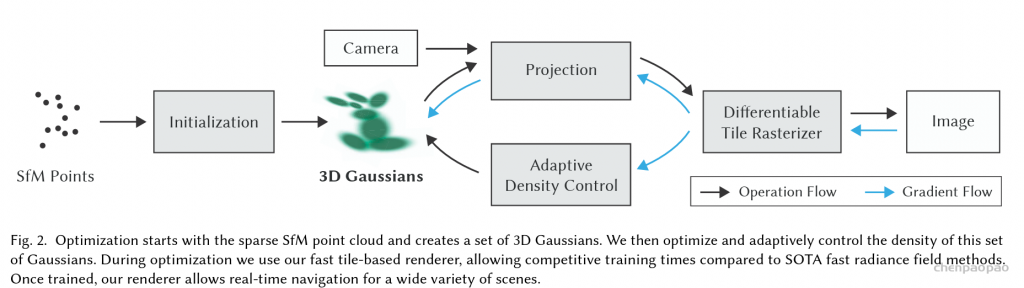
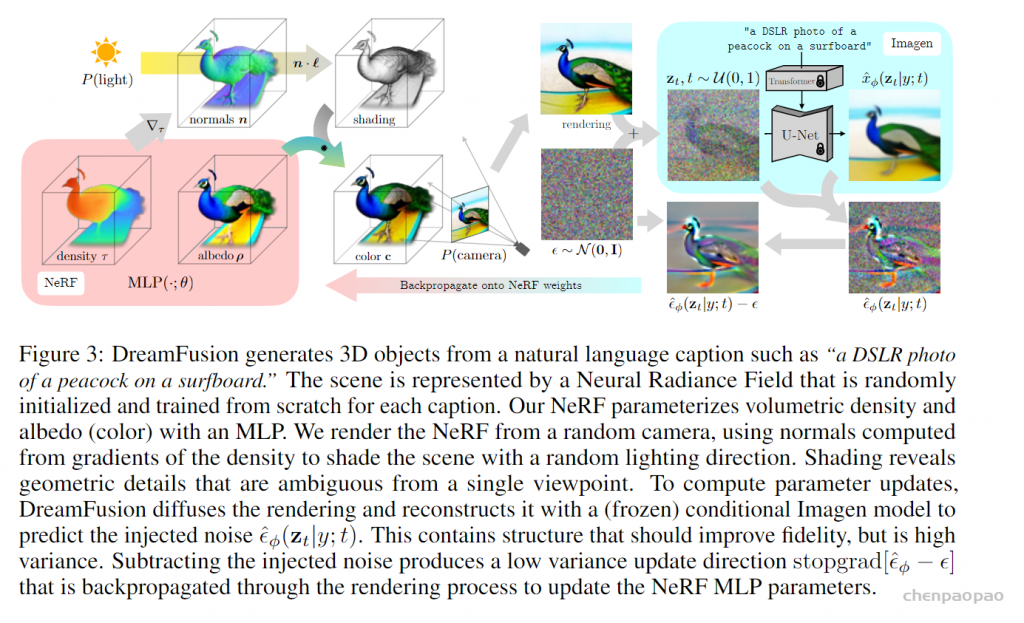
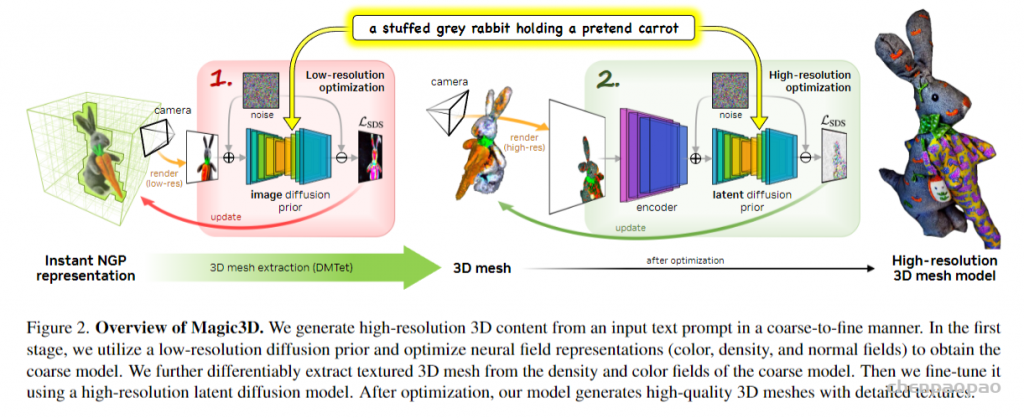
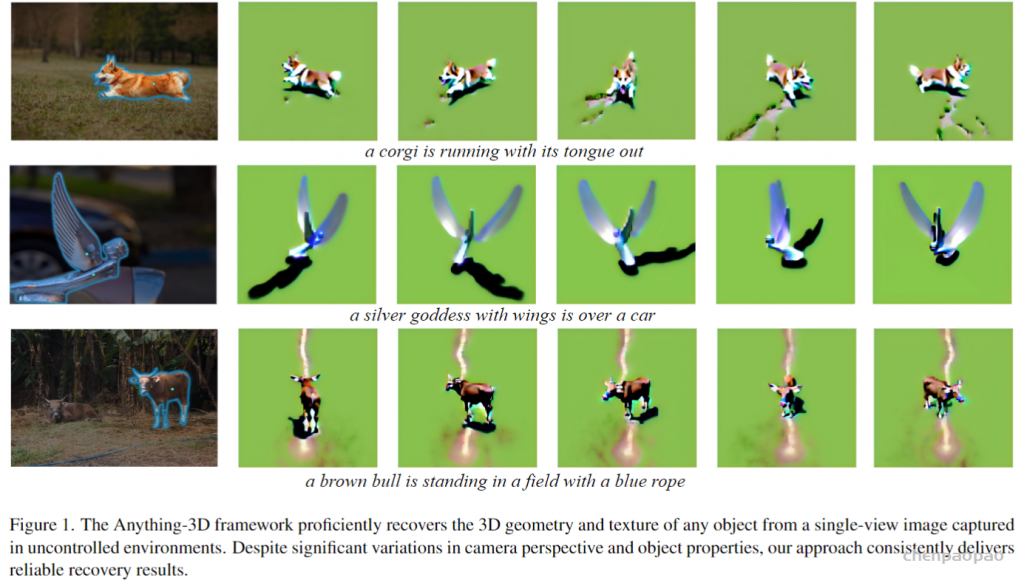
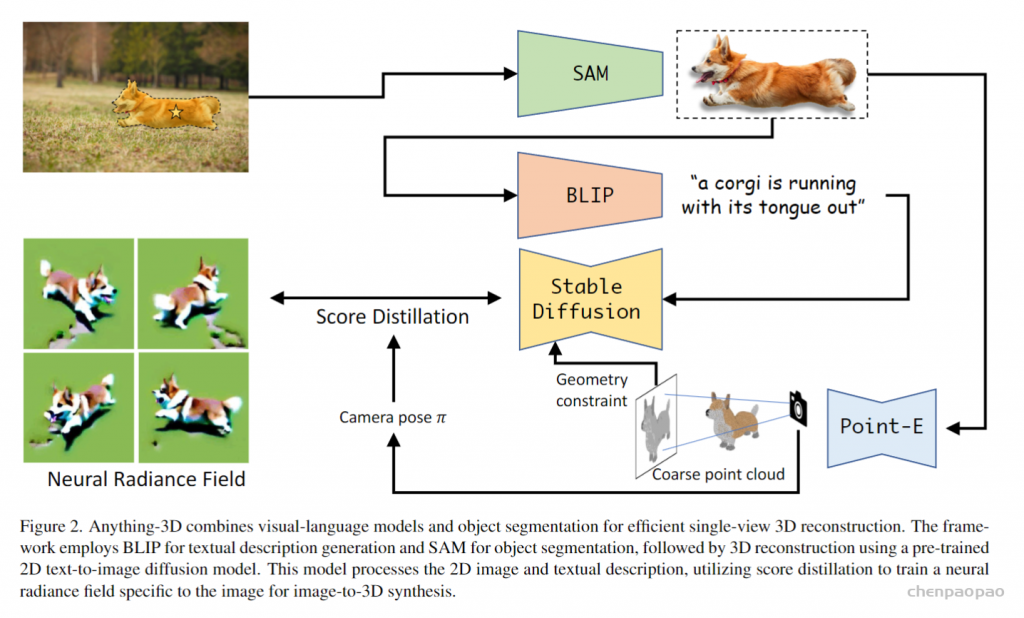
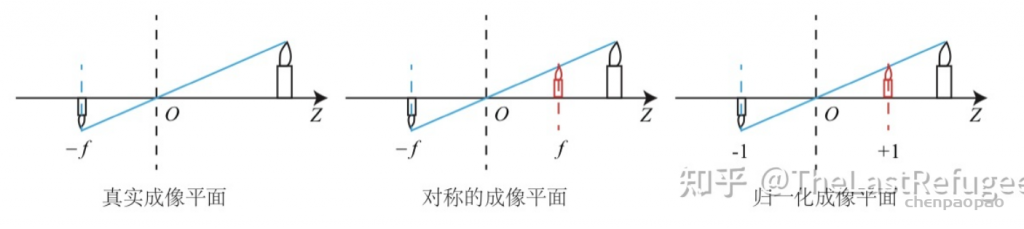
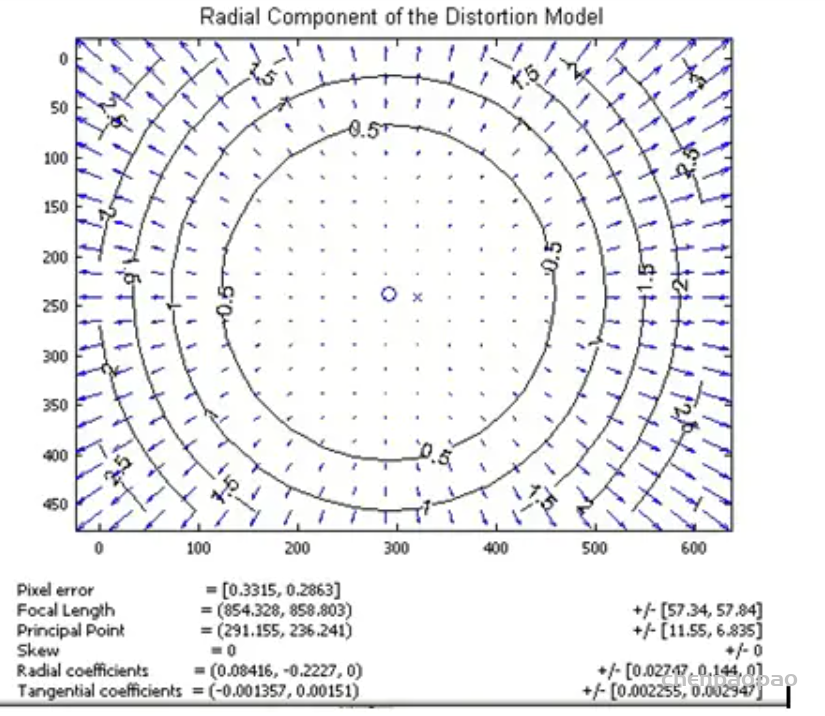
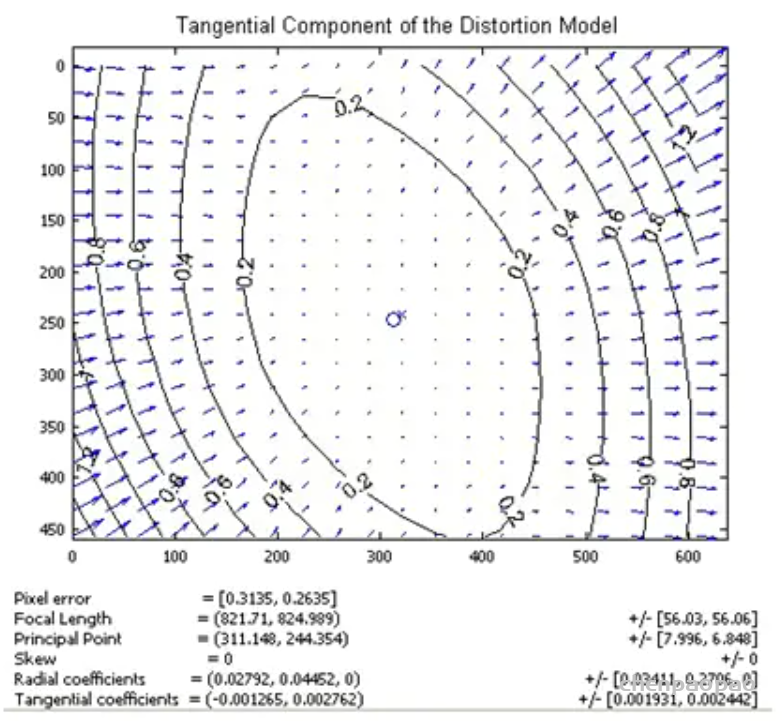
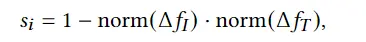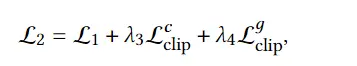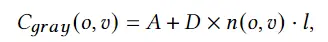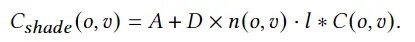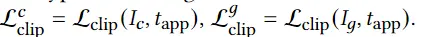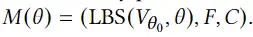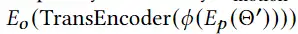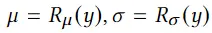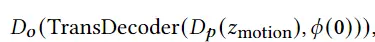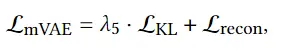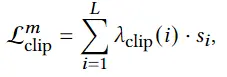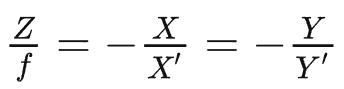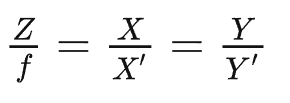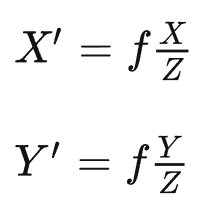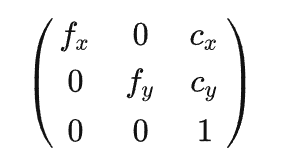最近一些方法基于隐式神经表示,利用体渲染技术优化场景表示,从而制作自由视点视频。D-NeRF[Pumarola et al., CVPR 2021] 利用隐式神经表示恢复了动态场景的motions,实现了照片级别的真实渲染。但是,这一类方法很难恢复复杂场景的motions,他们训练一个模型需要从几小时到几天不等的时间。此外,渲染一张图片通常需要分钟级的时间。
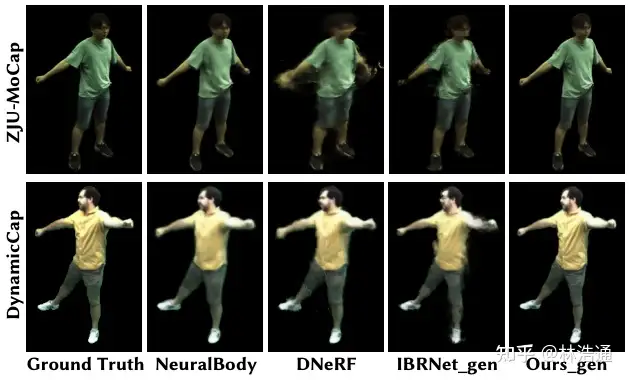
基于图像的渲染技术克服了以上方法的一些问题。第一,对于动态场景,IBRNet[Wang et al., CVPR 2021]能够把每一帧图像都当作单独的场景处理,从而不需要恢复场景的motions。第二,基于图像的渲染技术可以通过预训练模型避免每一时刻的重新训练。但是,IBRNet渲染一张图片仍然需要分钟级的时间。
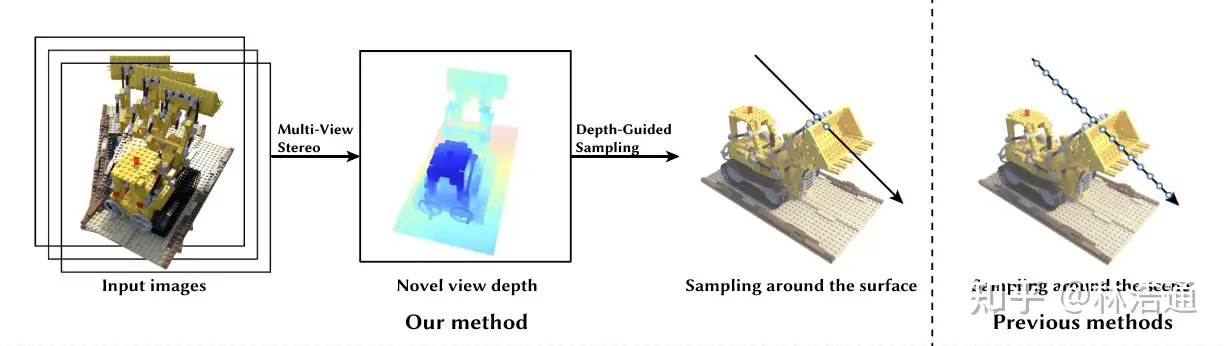
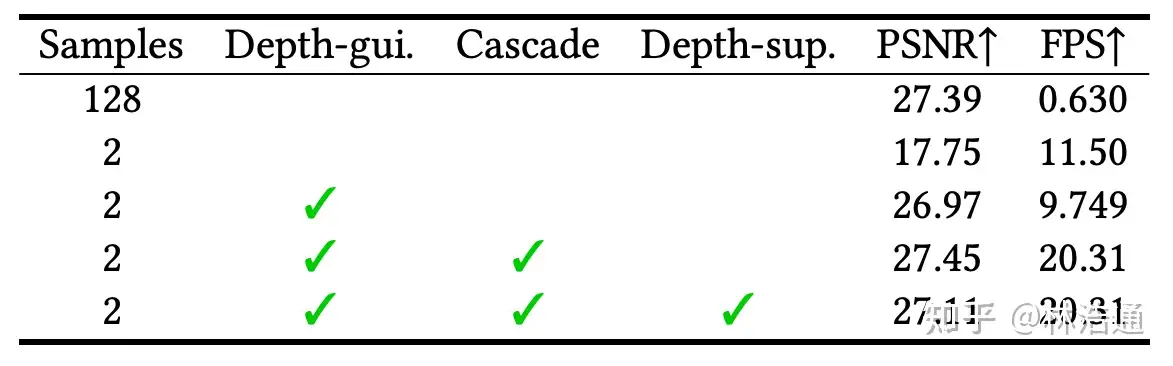
第一行展示了基线方法(与MVSNeRF[Chen et al., ICCV 2021]相似),每条光线采样128个点,这样有着好的渲染结果,但是渲染速度比较慢。直接降低采样点的数量后,会导致渲染质量显著下降。使用论文提出的采样方法(Depth-gui.)后,能提升渲染质量,同时基本保持比较快的渲染速度。
人们只需要输入一段文字比如「一只坐在睡莲上的蓝色箭毒蛙」,AI 就能给你生成个纹理造型俱全的 3D 模型出来。Magic3D 还可以执行基于提示的 3D 网格编辑:给定低分辨率 3D 模型和基本提示,可以更改文本从而修改生成的模型内容。此外,作者还展示了保持画风,以及将 2D 图像样式应用于 3D 模型的能力。
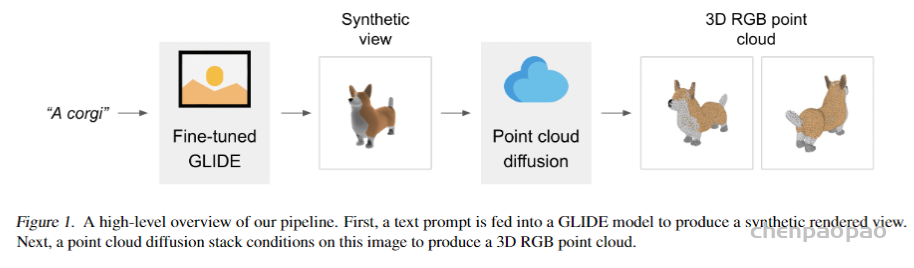
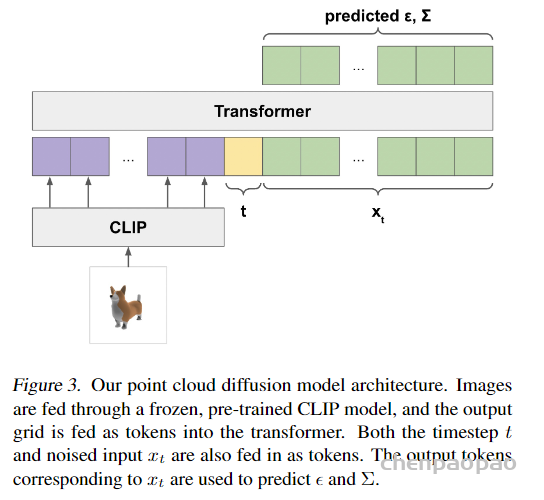
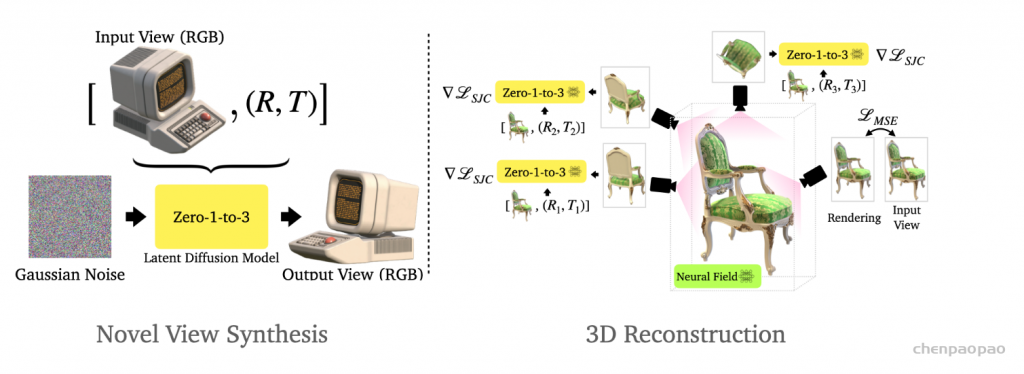
We learn a view-conditioned diffusion model that can subsequently control the viewpoint of an image containing a novel object (left). Such diffusion model can also be used to train a NeRF for 3D reconstruction (right). Please refer to our paper for more details or checkout our code for implementation.
Text to Image to Novel Views
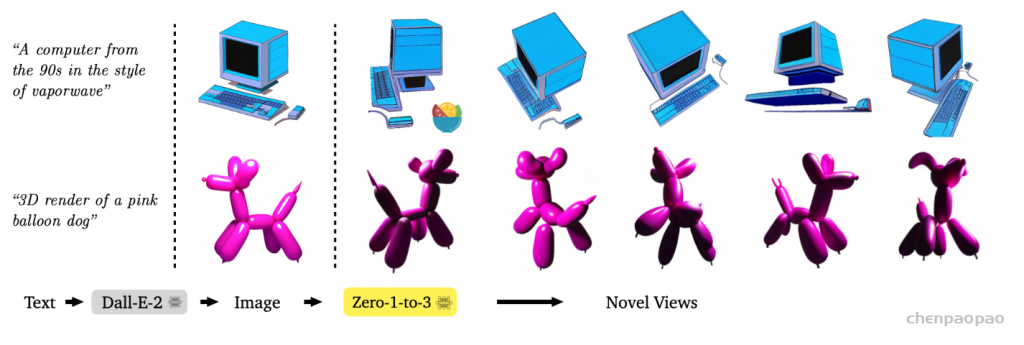
Here are results of applying Zero-1-to-3 to images generated by Dall-E-2.
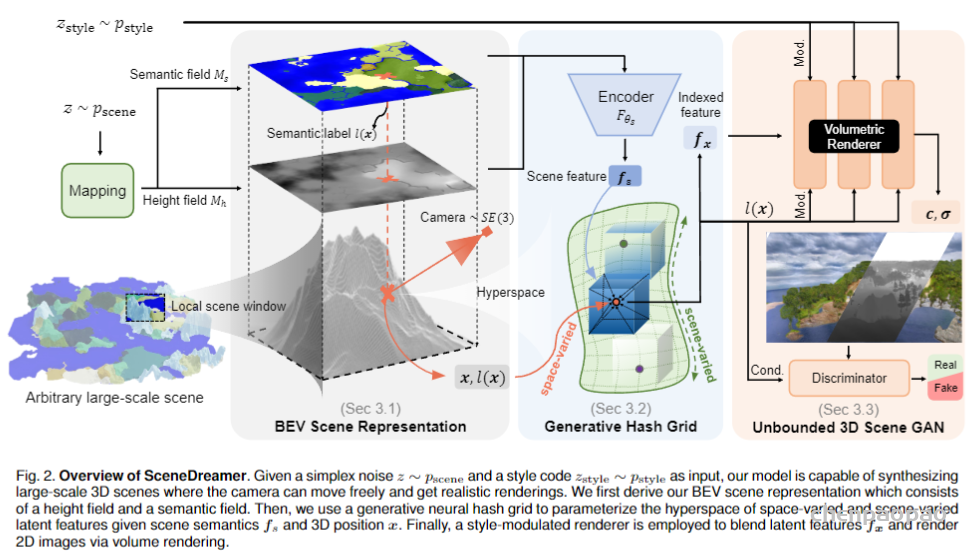
为满足元宇宙中对 3D 创意工具不断增长的需求,三维场景生成最近受到了相当多的关注。3D 内容创作的核心是逆向图形学,旨在从 2D 观测中恢复 3D 表征。考虑到创建 3D 资产所需的成本和劳动力,3D 内容创作的最终目标将是从海量的互联网二维图像中学习三维生成模型。最近关于三维感知生成模型的工作在一定程度上解决了这个问题,多数工作利用 2D 图像数据生成以物体为中心的内容(例如人脸、人体或物体)。然而,这类生成任务的观测空间处于有限域中,生成的目标占据了三维空间的有限区域。这就产生了一个问题,我们是否能从海量互联网 2D 图像中学习到无界场景的 3D 生成模型?比如能够覆盖任意大区域,且无限拓展的生动自然景观
我们先来看一下生成效果。与根据文字生成图像类似,Shap・E 生成的 3D 物体模型主打一个「天马行空」。
本文提出的 Shap・E 是一种在 3D 隐式函数空间上的潜扩散模型,可以渲染成 NeRF 和纹理网格。在给定相同的数据集、模型架构和训练计算的情况下,Shap・E 更优于同类显式生成模型。研究者发现纯文本条件模型可以生成多样化、有趣的物体,更彰显了生成隐式表征的潜力。
不同于 3D 生成模型上产生单一输出表示的工作,Shap-E 能够直接生成隐式函数的参数。训练 Shap-E 分为两个阶段:首先训练编码器,该编码器将 3D 资产确定性地映射到隐式函数的参数中;其次在编码器的输出上训练条件扩散模型。当在配对 3D 和文本数据的大型数据集上进行训练时, 该模型能够在几秒钟内生成复杂而多样的 3D 资产。与点云显式生成模型 Point・E 相比,Shap-E 建模了高维、多表示的输出空间,收敛更快,并且达到了相当或更好的样本质量。
研究者首先训练编码器产生隐式表示,然后在编码器产生的潜在表示上训练扩散模型,主要分为以下两步完成: 1. 训练一个编码器,在给定已知 3D 资产的密集显式表示的情况下,产生隐式函数的参数。编码器产生 3D 资产的潜在表示后线性投影,以获得多层感知器(MLP)的权重;
2. 将编码器应用于数据集,然后在潜在数据集上训练扩散先验。该模型以图像或文本描述为条件。 研究者在一个大型的 3D 资产数据集上使用相应的渲染、点云和文本标题训练所有模型。
清华大学 TSAIL 团队最新提出的文生 3D 新算法 ProlificDreamer,在无需任何 3D 数据的前提下能够生成超高质量的 3D 内容。ProlificDreamer 算法为文生 3D 领域带来重大进展。利用 ProlificDreamer,输入文本 “一个菠萝”,就能生成非常逼真且高清的 3D 菠萝:
将 Imagen 生成的照片(下图静态图)和 ProlificDreamer(基于 Stable-Diffusion)生成的 3D(下图动态图)进行对比。有网友感慨:短短一年时间,高质量的生成已经能够从 2D 图像领域扩展到 3D 领域了
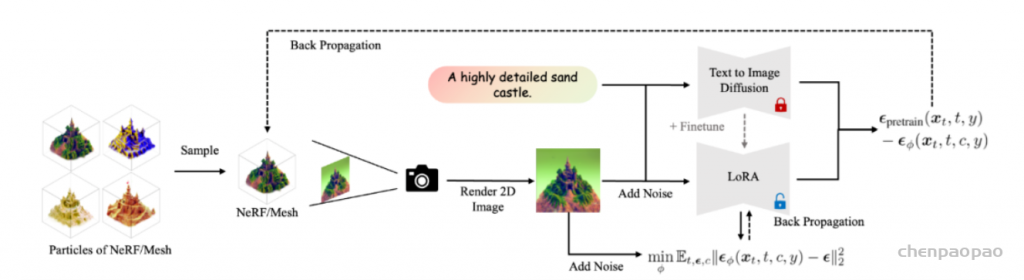
在数字创作和虚拟现实等领域,从文本到三维模型(Text-to-3D)的技术具有重要的价值和广泛的应用潜力。这种技术可以从简单的文本描述中生成具体的 3D 模型,为设计师、游戏开发者和数字艺术家提供强大的工具。然而,为了根据文本生成准确的 3D 模型,传统方法需要大量的标记 3D 模型数据集。这些数据集需要包含多种不同类型和风格的 3D 模型,并且每个模型都需要与相应的文本描述相关联。创建这样的数据集需要大量的时间和人力资源,目前还没有现成的大规模数据集可供使用。由谷歌提出的 DreamFusion [1] 利用预训练的 2D 文本到图像扩散模型,首次在无需 3D 数据的情况下完成开放域的文本到 3D 的合成。但是 DreamFusion 提出的 Score Distillation Sampling (SDS) [1] 算法生成结果面临严重的过饱和、过平滑、缺少细节等问题。高质量 3D 内容生成目前仍然是非常困难的前沿问题之一。ProlificDreamer 论文提出了 Variational Score Distillation(VSD)算法,从贝叶斯建模和变分推断(variational inference)的角度重新形式化了 text-to-3D 问题。具体而言,VSD 把 3D 参数建模为一个概率分布,并优化其渲染的二维图片的分布和预训练 2D 扩散模型的分布间的距离。可以证明,VSD 算法中的 3D 参数近似了从 3D 分布中采样的过程,解决了 DreamFusion 所提 SDS 算法的过饱和、过平滑、缺少多样性等问题。此外,SDS 往往需要很大的监督权重(CFG=100),而 VSD 是首个可以用正常 CFG(=7.5)的算法。
与以往方法不同,ProlificDreamer 并不单纯优化单个 3D 物体,而是优化 3D 物体对应的概率分布。通常而言,给定一个有效的文本输入,存在一个概率分布包含了该文本描述下所有可能的 3D 物体。基于该 3D 概率分布,我们可以进一步诱导出一个 2D 概率分布。具体而言,只需要对每一个 3D 物体经过相机渲染到 2D,即可得到一个 2D 图像的概率分布。因此,优化 3D 分布可以被等效地转换为优化 2D 渲染图片的概率分布与 2D 扩散模型定义的概率分布之间的距离(由 KL 散度定义)。这是一个经典的变分推断(variational inference)任务,因此 ProlificDreamer 文中将该任务及对应的算法称为变分得分蒸馏(Variational Score Distillation,VSD)。具体而言,VSD 的算法流程图如下所示。其中,3D 物体的迭代更新需要使用两个模型:一个是预训练的 2D 扩散模型(例如 Stable-Diffusion),另一个是基于该预训练模型的 LoRA(low-rank adaptation)。该 LoRA 估计了当前 3D 物体诱导的 2D 图片分布的得分函数(score function),并进一步用于更新 3D 物体。该算法实际上在模拟 Wasserstein 梯度流,并可以保证收敛得到的分布满足与预训练的 2D 扩散模型的 KL 散度最小。
Here we present a project where we combine Segment Anything with a series of 3D models to create a very interesting demo. This is currently a small project, but we plan to continue improving it and creating more exciting demos.
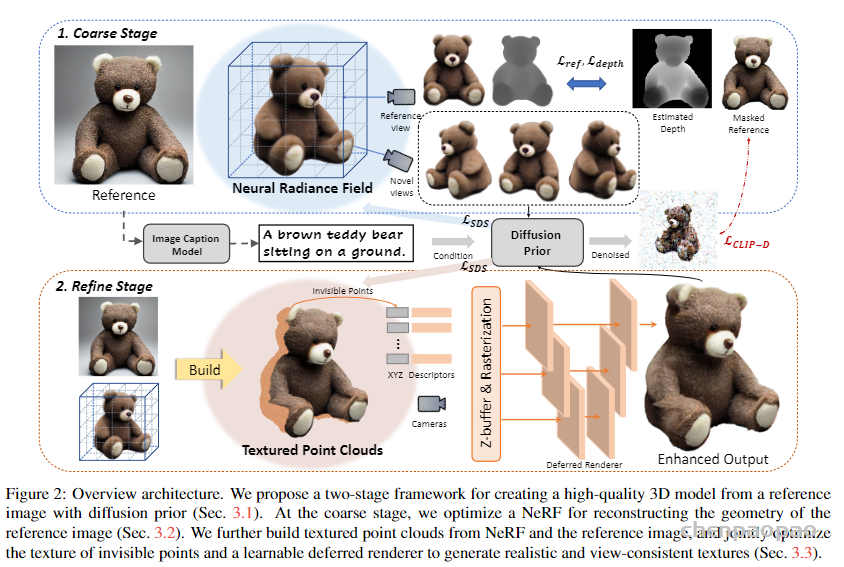
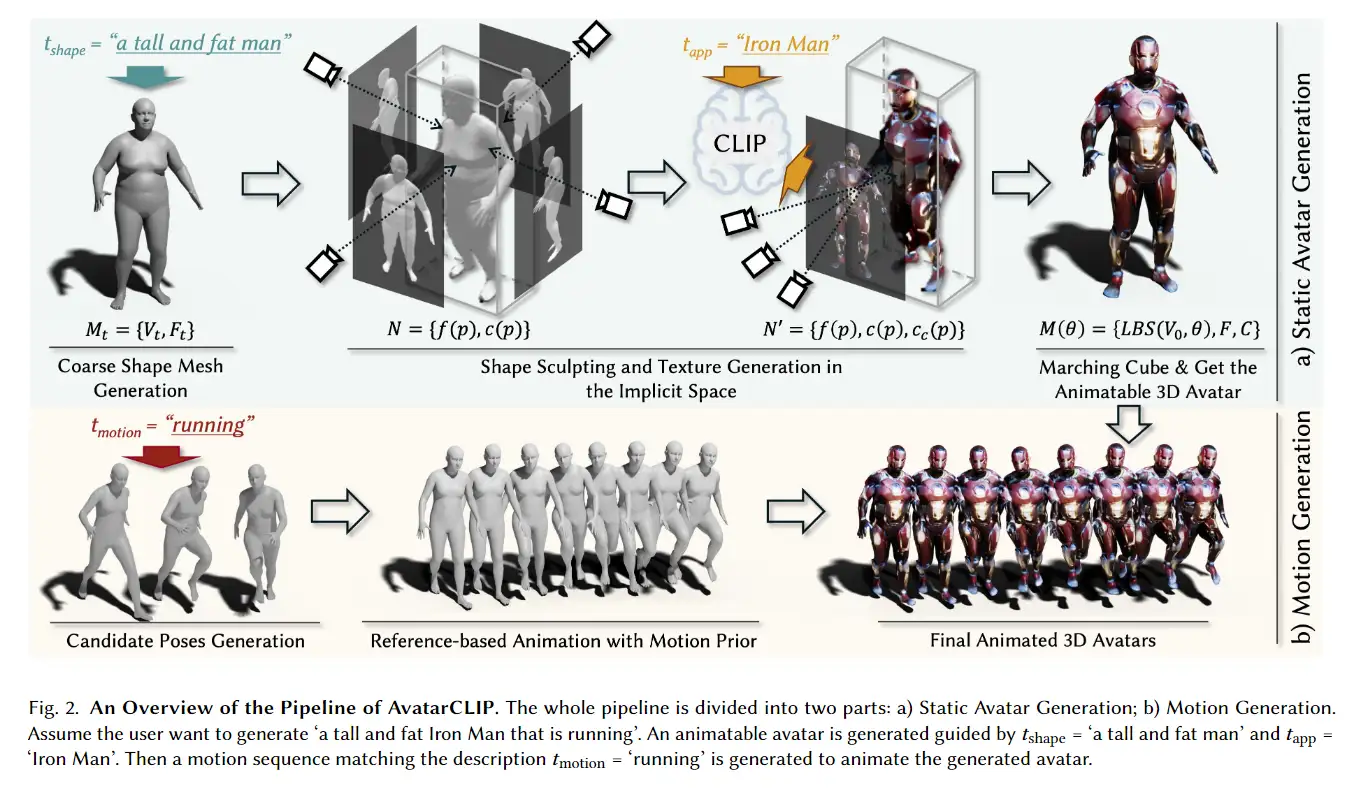
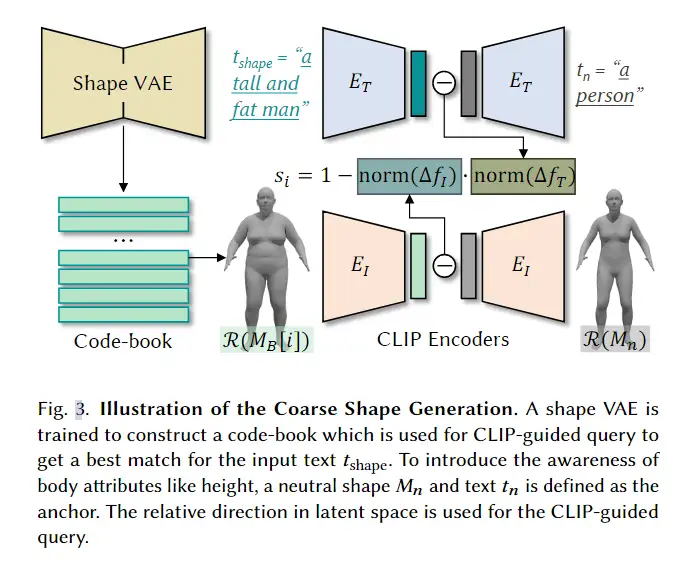
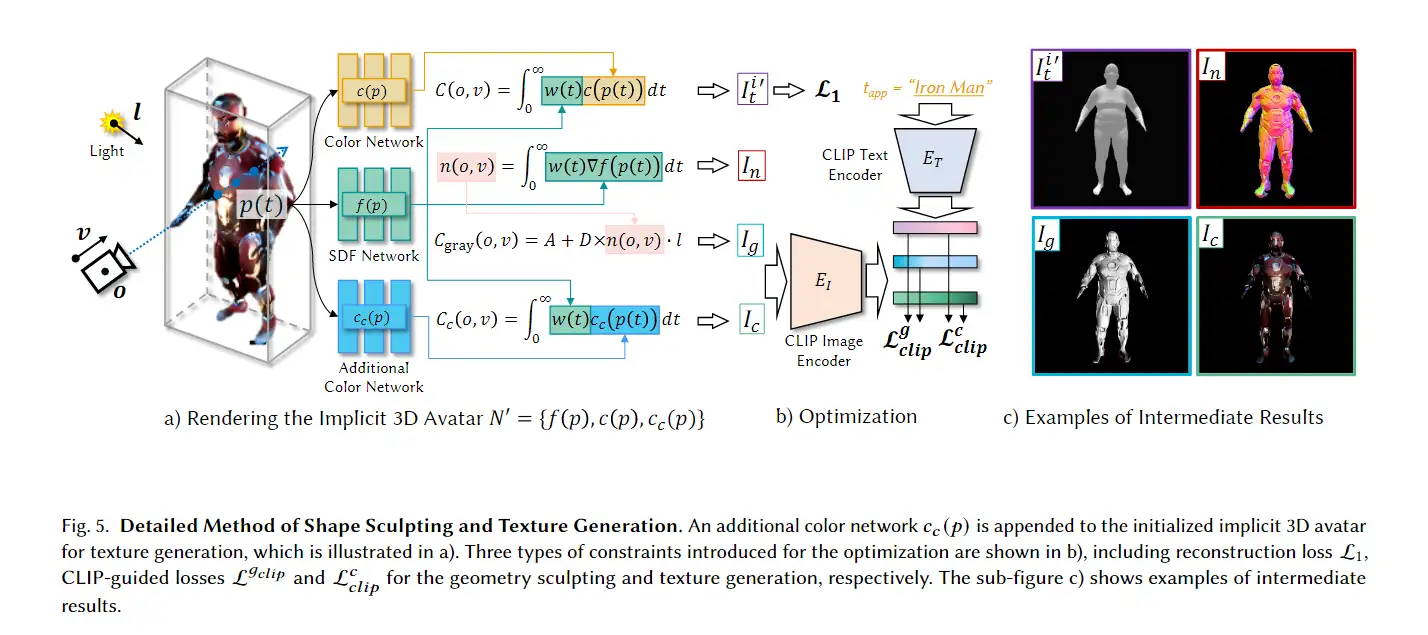
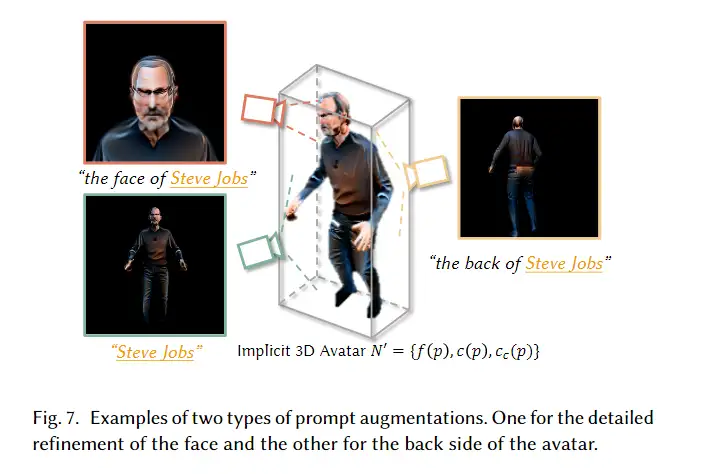
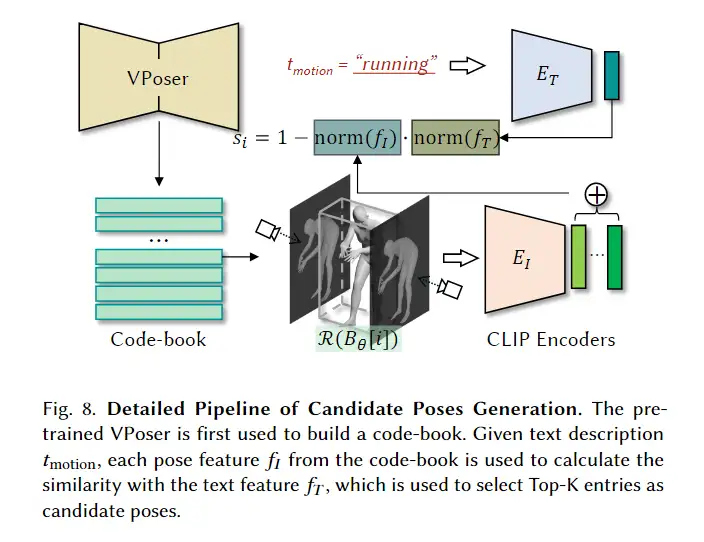
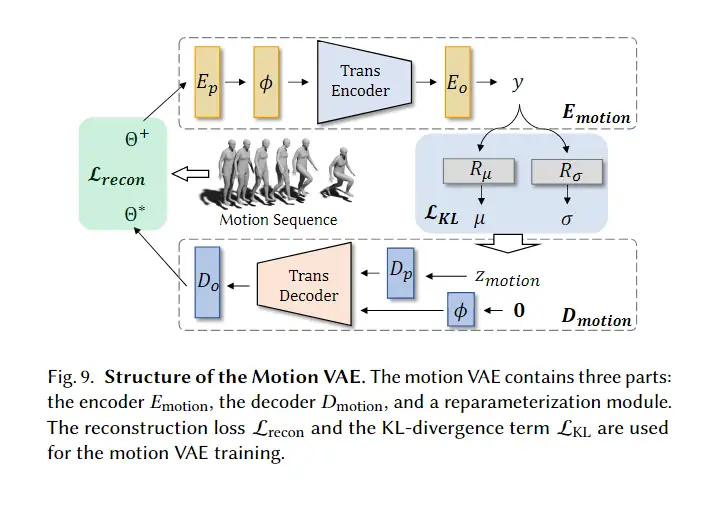
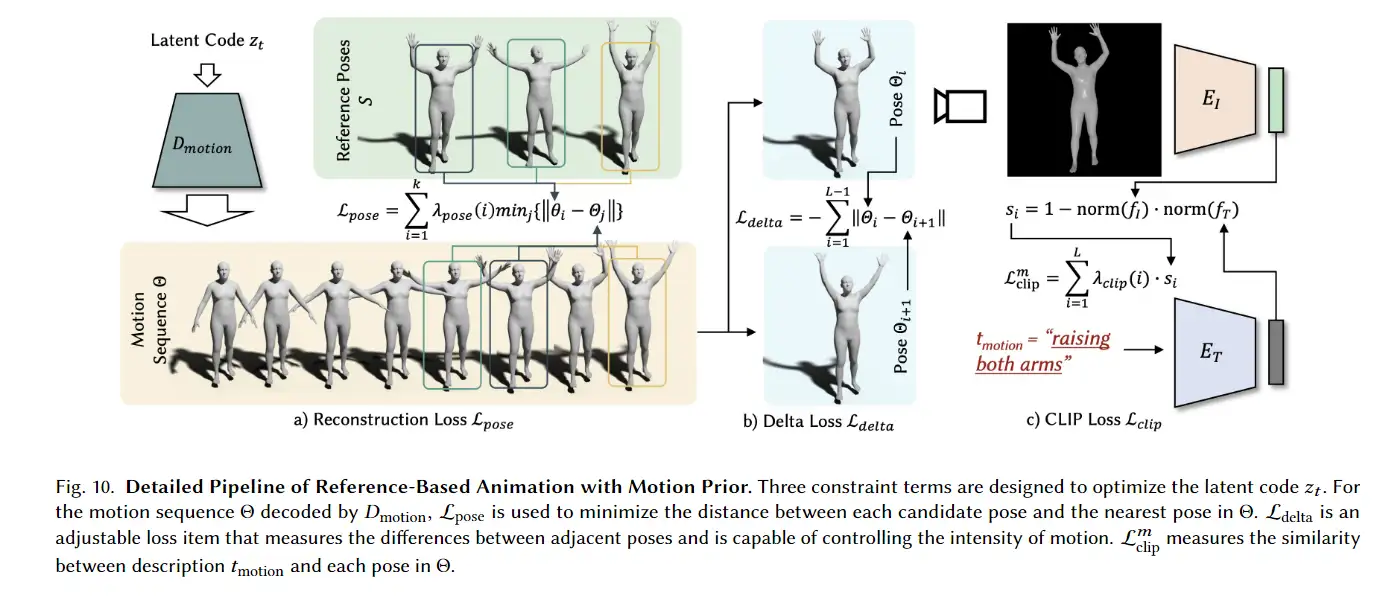
3D avatar生成在数字时代有至关重要的作用,一般而言,创建一个3Davatar需要创建一个人物形象、绘制纹理、建立骨架并使用捕捉到的动作对其进行驱动。无论哪一个步骤都需要专业人才、大量时间和昂贵的设备,为了让这项技术面向大众,本文提出了AvatarCLIP,一个zero-shot文本驱动的3Davatar生成和动画化的框架。与专业的制作软件不同,这个模型不需要专业知识,仅仅通过自然语言就可以生成想要的avatar。本文主要是利用了大规模的视觉语言预训练模型CLIP来监督人体的生成,包括几何形状、纹理和动画。使用shapeVAE来初始化人类几何形状,进一步进行体渲染,接着进行几何雕刻和纹理生成,利用motionVAE得到运动先验来生成三维动画
为了生成高质量的 3D avatar,形状和纹理需要进一步塑造和生成以匹配外观 app 的描述。如前所述,我们选择使用隐式表示,即 Neus,作为此步骤中的基本 3D 表示,因为它在几何和颜色上都具有优势。为了加速优化和控制形状生成,更方便生成动画,所以需要先将生成的粗糙mesh shape转化为隐式表示。
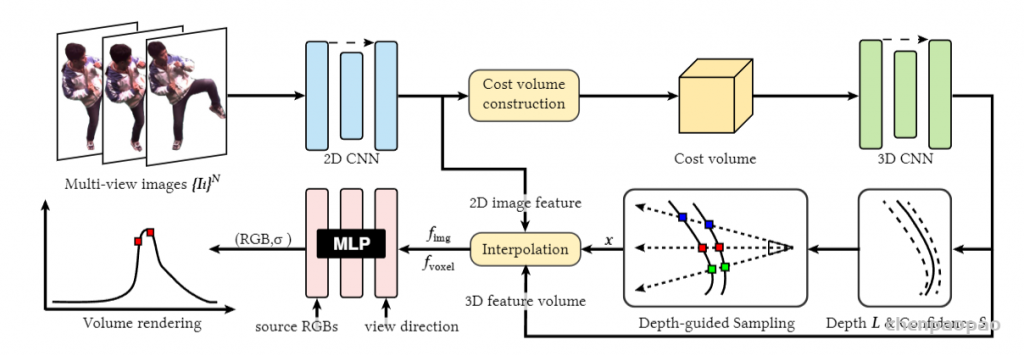
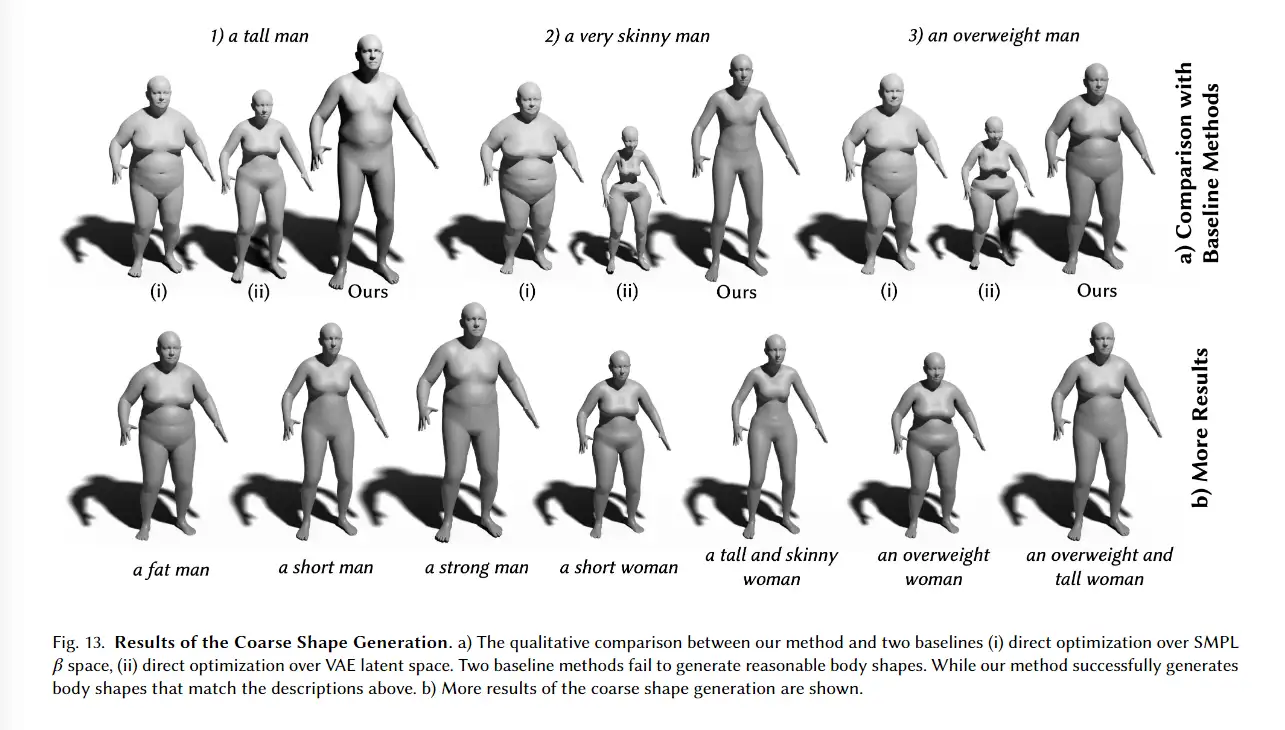
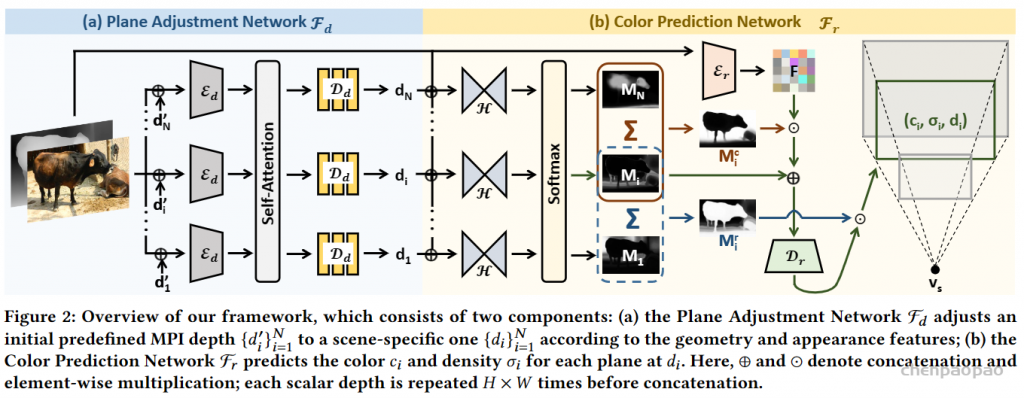
该网络旨在从输入图像和其深度图中预测N个平面,每个平面都有颜色通道ci、密度通道σi和深度di。该网络由两个子网络组成:平面调整网络Fd和颜色预测网络Fr。首先,使用现成的单目深度估计网络[Ranftl et al. 2021]获取深度图。然后,将Fd应用于推断平面深度{di}N_i=1,并将Fr应用于预测每个di处的颜色和密度{ci, σi}N_i=1。因此,该网络可以生成多平面图像,其中每个平面都具有不同的颜色、密度和深度值。
In recent years, tremendous amount of progress is being made in the field of 3D Machine Learning, which is an interdisciplinary field that fuses computer vision, computer graphics and machine learning. This repo is derived from my study notes and will be used as a place for triaging new research papers.
I’ll use the following icons to differentiate 3D representations:
📷 Multi-view Images
👾 Volumetric
🎲 Point Cloud
💎 Polygonal Mesh
💊 Primitive-based
To find related papers and their relationships, check out Connected Papers, which provides a neat way to visualize the academic field in a graph representation.
Get Involved
To contribute to this Repo, you may add content through pull requests or open an issue to let me know.
⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ We have also created a Slack workplace for people around the globe to ask questions, share knowledge and facilitate collaborations. Together, I’m sure we can advance this field as a collaborative effort. Join the community with this link. ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐
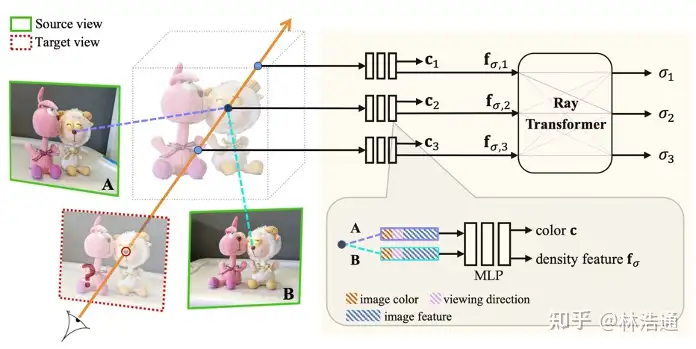
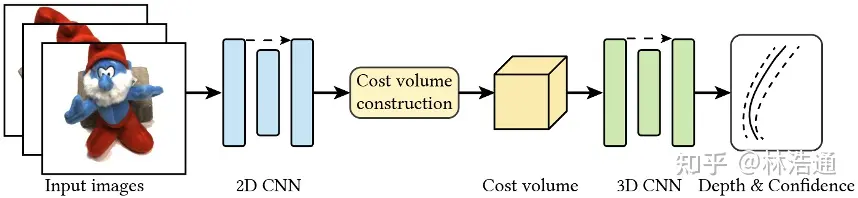
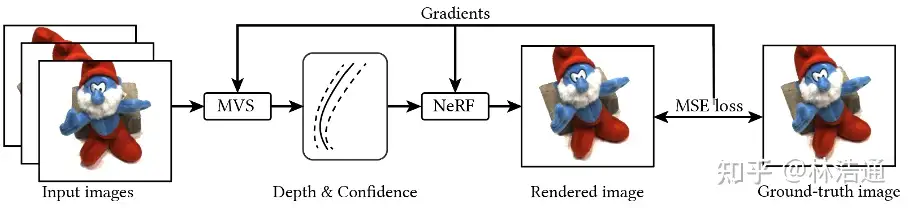
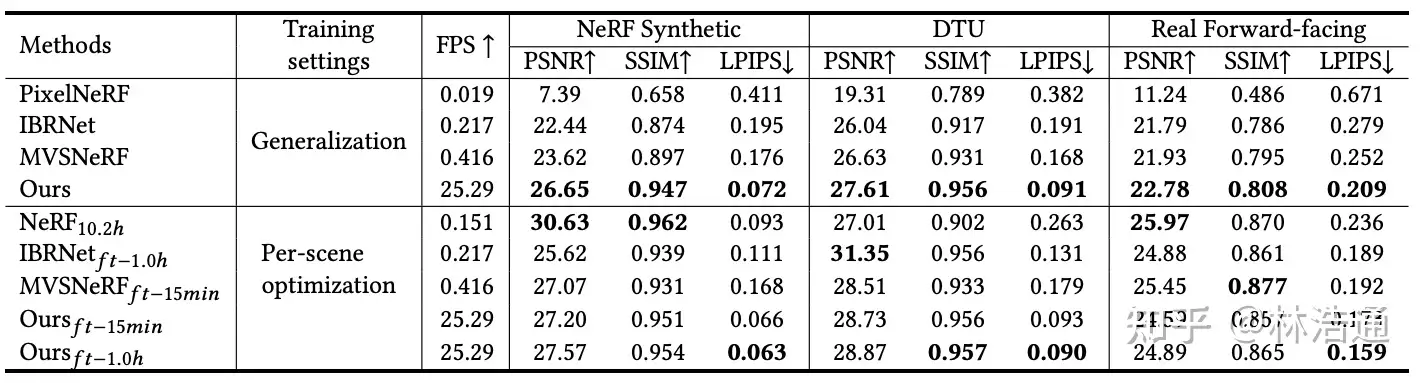
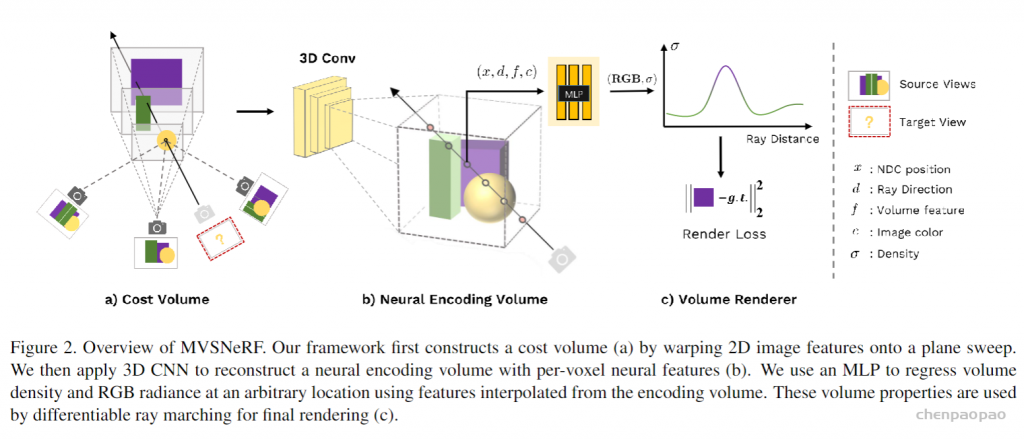
提出了一种新的神经渲染方法neural rendering approach MVSNeRF,它可以有效地重建用于视图合成的神经辐射场。与先前关于神经辐射场的工作不同,这些工作考虑对密集捕获的图像进行逐场景优化,我们提出了一种通用的深度神经网络,该网络可以通过快速网络推理仅从三个附近的输入视图重建辐射场。我们的方法利用平面扫描成本体plane-swept cost volumes(广泛用于多视图立体multi-view stereo)进行几何感知场景推理,并将其与基于物理的体渲染相结合进行神经辐射场重建。我们在DTU数据集中的真实对象上训练我们的网络,并在三个不同的数据集上测试它以评估它的有效性和可推广性generalizability我们的方法可以跨场景(甚至室内场景,完全不同于我们的对象训练场景)进行推广generalize across scenes,并仅使用三幅输入图像生成逼真的视图合成结果,明显优于目前的广义辐射场重建generalizable radiance field reconstruction工作。此外,如果捕捉到密集图像dense images are captured,我们估计的辐射场表示可以容易地微调easily fine-tuned;这导致快速的逐场景重建fast per-scene reconstruction,比NeRF具有更高的渲染质量和更少的优化时间。
我们利用最近在深度多视图立体(MVS)deep multi- view stereo (MVS)上的成功[50,18,10]。这一系列工作可以通过对成本体积应用3D卷积applying 3D convolutions on cost volumes来训练用于3D重建任务的可概括的神经网络。与[50]类似,我们通过将来自附近输入视图的2D图像特征(由2D CNN推断)扭曲warping到参考视图的平截头体中的扫描平面上sweeping planes in the reference view’s frustrum,在输入参考视图处构建成本体。不像MVS方法[50,10]仅在这样的成本体积上进行深度推断depth inference,我们的网络推理关于场景几何形状和外观reasons about both scene geometry and appearance,并输出神经辐射场(见图2),实现视图合成。具体来说,利用3D CNN,我们重建(从成本体)神经场景编码体neural scene encoding volume,其由 编码关于局部场景几何形状和外观的信息的每个体素神经特征per-voxel neural features 组成。然后,我们利用多层感知器(MLP)在编码体积encoding volume内使用三线性插值神经特征tri-inearly interpolated neural features来解码任意连续位置处的体积密度volume density和辐射度radiance。本质上,编码体是辐射场的局部神经表示;一旦估计,该体积可以直接用于(丢弃3D CNN)通过可微分射线行进differentiable ray marching(如在[34]中)的最终渲染。