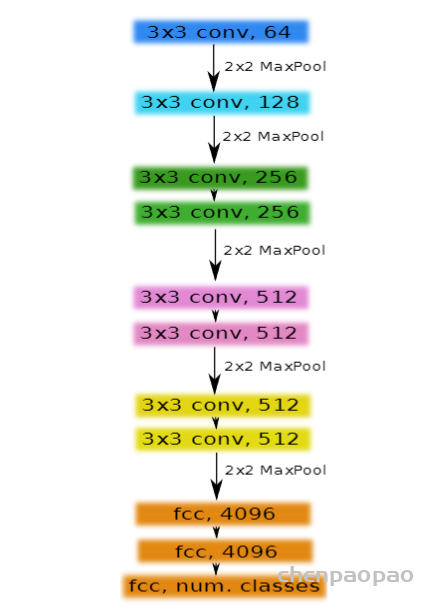
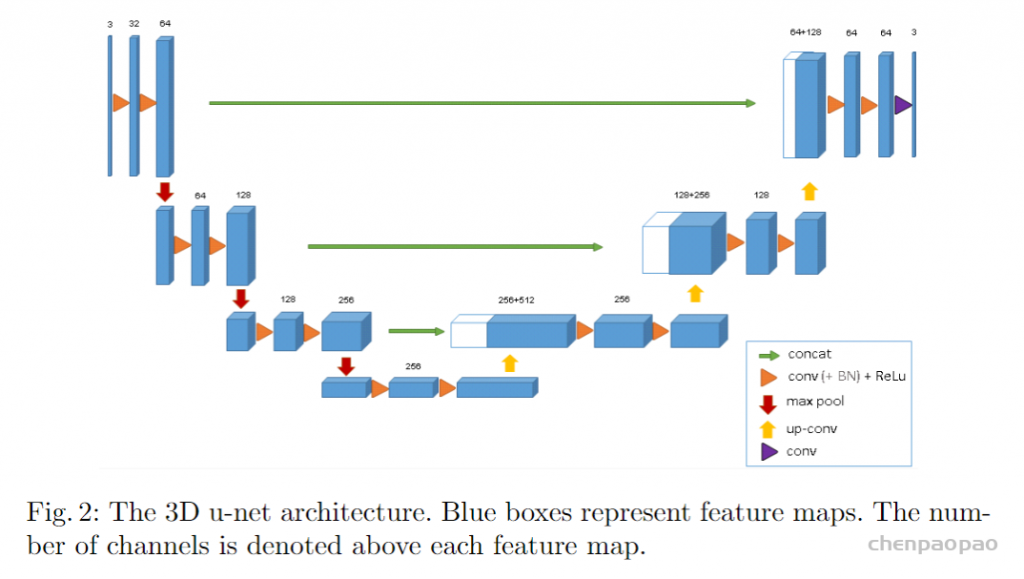
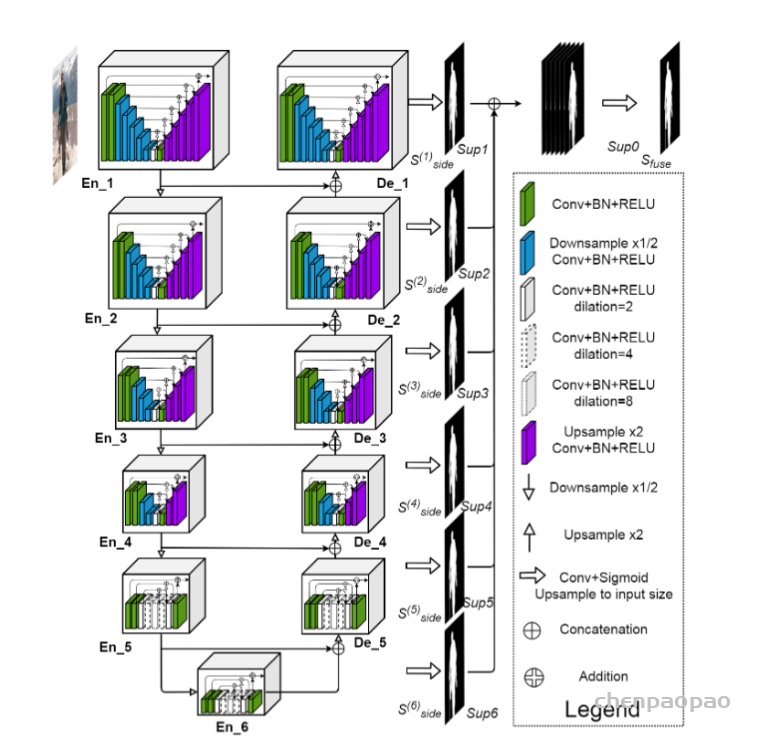
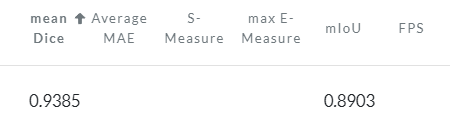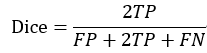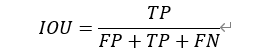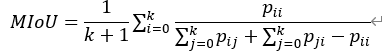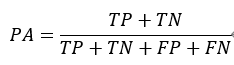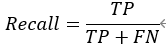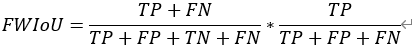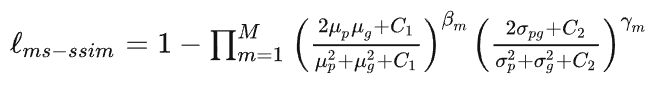整体的一个网络结构如下图所示,其实可以看出来跟2D结构的U-Net是基本一样,唯一不同的就是全部2D操作换成了3D,这样子做了之后,对于volumetric image就不需要单独输入每个切片进行训练,而是可以采取图片整张作为输入到模型中(PS:但是当图像太大的时候,此时需要运用random crop的技巧将图片随机裁切成固定大小模块的图片放入搭建的模型进行训练,当然这是后话,之后将会在其他文章中进行介绍)。除此之外,论文中提到的一个亮点就是,3D U-Net使用了weighted softmax loss function将未标记的像素点设置为0以至于可以让网络可以更多地仅仅学习标注到的像素点,从而达到普适性地特点。
训练细节(Training)
3D U-Net同样采用了数据增强(data augmentation)地手段,主要由rotation、scaling和将图像设置为gray,于此同时在训练数据上和真实标注的数据上运用平滑的密集变形场(smooth dense deformation field),主要是通过从一个正态分布的随机向量样本中选取标准偏差为4的网格,在每个方向上具有32个体素的间距,然后应用B样条插值(B-Spline Interpolation,不知道什么是B样条插值法的可以点连接进行查看,在深度学习模型的创建中有时候也不需要那么复杂,所以这里仅限了解,除非本身数学底子很好已经有所了解),B样条插值法比较笼统地说法就是在原本地形状上找到一个类似地形状来近似(approximation)。之后就对数据开始进行训练,训练采用的是加权交叉熵损失(weighted cross-entropy loss function)以至于减少背景的权重并增加标注到的图像数据部分的权重以达到平衡的影响小管和背景体素上的损失。
实验的结果是用IoU(intersection over union)进行衡量的,即比较生成图像与真实被标注部分的重叠部分。
class RCUBlock(nn.Module):
def __init__(self, in_planes, out_planes, n_blocks, n_stages):
super(RCUBlock, self).__init__()
for i in range(n_blocks):
for j in range(n_stages):
setattr(self, '{}{}'.format(i + 1, stages_suffixes[j]),
conv3x3(in_planes if (i == 0) and (j == 0) else out_planes,
out_planes, stride=1,
bias=(j == 0)))
self.stride = 1
self.n_blocks = n_blocks
self.n_stages = n_stages
def forward(self, x):
for i in range(self.n_blocks):
residual = x
for j in range(self.n_stages):
x = F.relu(x)
x = getattr(self, '{}{}'.format(i + 1, stages_suffixes[j]))(x)
x += residual
return
class CRPBlock(nn.Module):
def __init__(self, in_planes, out_planes, n_stages):
super(CRPBlock, self).__init__()
for i in range(n_stages):
setattr(self, '{}_{}'.format(i + 1, 'outvar_dimred'),
conv3x3(in_planes if (i == 0) else out_planes,
out_planes, stride=1,
bias=False))
self.stride = 1
self.n_stages = n_stages
self.maxpool = nn.MaxPool2d(kernel_size=5, stride=1, padding=2)
def forward(self, x):
top = x
for i in range(self.n_stages):
top = self.maxpool(top)
top = getattr(self, '{}_{}'.format(i + 1, 'outvar_dimred'))(top)
x = top + x
return x
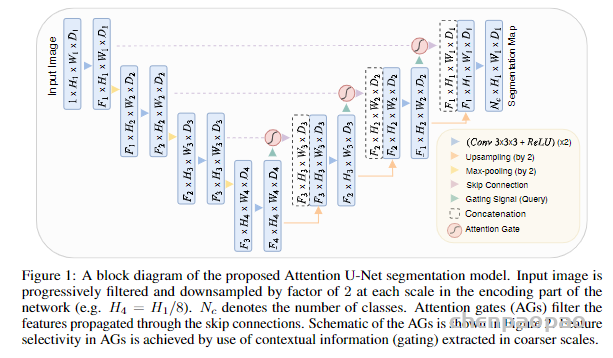
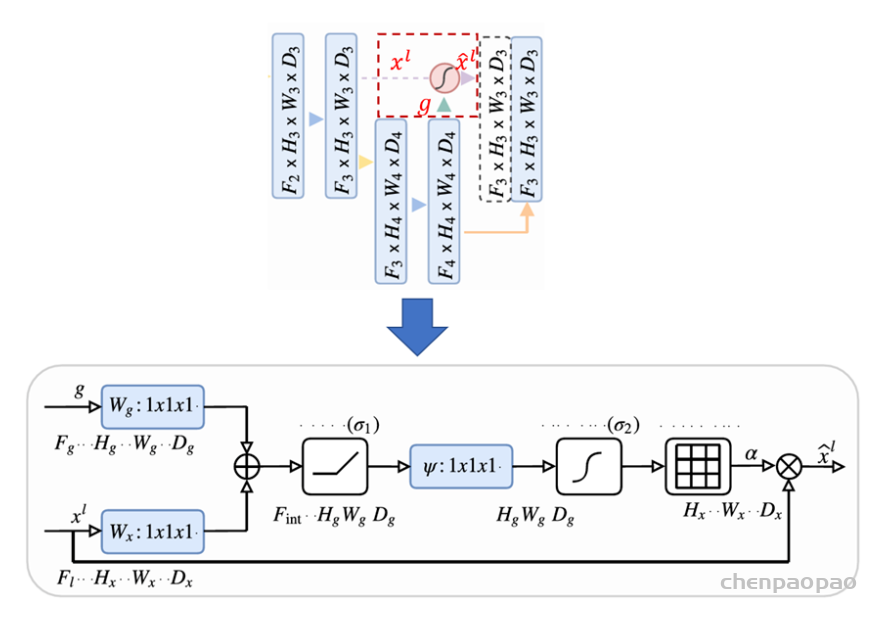
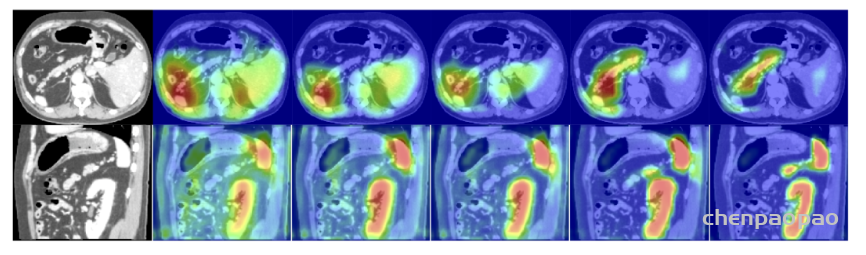
以CNN为基础的编解码结构在图像分割上展现出了卓越的效果,尤其是医学图像的自动分割上。但一些研究认为以往的FCN和UNet等分割网络存在计算资源和模型参数的过度和重复使用,例如相似的低层次特征被级联内的所有网络重复提取。针对这类普遍性的问题,相关研究提出了给UNet添加注意力门控(Attention Gates, AGs)的方法,形成一个新的图像分割网络结构:Attention UNet。提出Attention UNet的论文为Attention U-Net: Learning Where to Look for the Pancreas,发表在2018年CVPR上。注意力机制原先是在自然语言处理领域被提出并逐渐得到广泛应用的一种新型结构,旨在模仿人的注意力机制,有针对性的聚焦数据中的突出特征,能够使得模型更加高效。