MVSNeRF: Fast Generalizable Radiance Field Reconstruction
from Multi-View Stereo
https://github.com/apchenstu/mvsnerf
提出了一种新的神经渲染方法neural rendering approach MVSNeRF,它可以有效地重建用于视图合成的神经辐射场。与先前关于神经辐射场的工作不同,这些工作考虑对密集捕获的图像进行逐场景优化,我们提出了一种通用的深度神经网络,该网络可以通过快速网络推理仅从三个附近的输入视图重建辐射场。我们的方法利用平面扫描成本体plane-swept cost volumes(广泛用于多视图立体multi-view stereo)进行几何感知场景推理,并将其与基于物理的体渲染相结合进行神经辐射场重建。我们在DTU数据集中的真实对象上训练我们的网络,并在三个不同的数据集上测试它以评估它的有效性和可推广性generalizability我们的方法可以跨场景(甚至室内场景,完全不同于我们的对象训练场景)进行推广generalize across scenes,并仅使用三幅输入图像生成逼真的视图合成结果,明显优于目前的广义辐射场重建generalizable radiance field reconstruction工作。此外,如果捕捉到密集图像dense images are captured,我们估计的辐射场表示可以容易地微调easily fine-tuned;这导致快速的逐场景重建fast per-scene reconstruction,比NeRF具有更高的渲染质量和更少的优化时间。
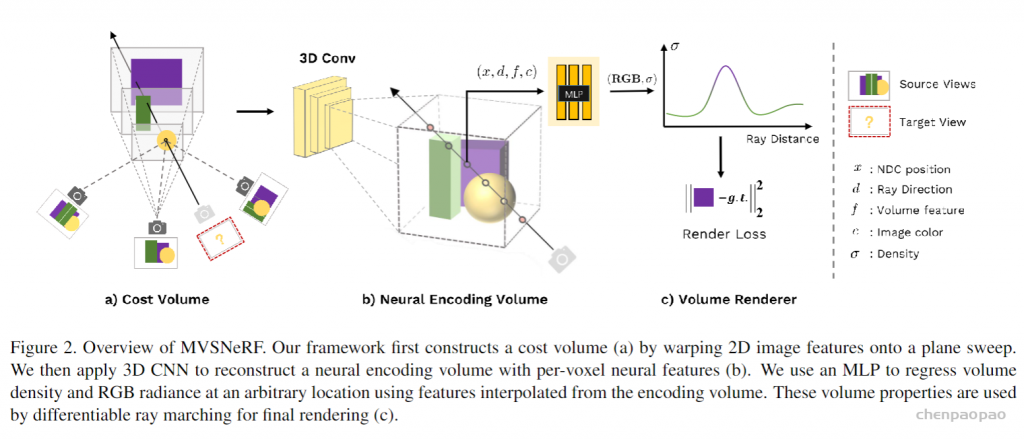
我们利用最近在深度多视图立体(MVS)deep multi- view stereo (MVS)上的成功[50,18,10]。这一系列工作可以通过对成本体积应用3D卷积applying 3D convolutions on cost volumes来训练用于3D重建任务的可概括的神经网络。与[50]类似,我们通过将来自附近输入视图的2D图像特征(由2D CNN推断)扭曲warping到参考视图的平截头体中的扫描平面上sweeping planes in the reference view’s frustrum,在输入参考视图处构建成本体。不像MVS方法[50,10]仅在这样的成本体积上进行深度推断depth inference,我们的网络推理关于场景几何形状和外观reasons about both scene geometry and appearance,并输出神经辐射场(见图2),实现视图合成。具体来说,利用3D CNN,我们重建(从成本体)神经场景编码体neural scene encoding volume,其由 编码关于局部场景几何形状和外观的信息的每个体素神经特征per-voxel neural features 组成。然后,我们利用多层感知器(MLP)在编码体积encoding volume内使用三线性插值神经特征tri-inearly interpolated neural features来解码任意连续位置处的体积密度volume density和辐射度radiance。本质上,编码体是辐射场的局部神经表示;一旦估计,该体积可以直接用于(丢弃3D CNN)通过可微分射线行进differentiable ray marching(如在[34]中)的最终渲染。
我们的方法结合了两个世界的优点,基于学习的MVS和神经渲染。与现有的MVS方法相比,我们实现了可微分神经渲染differentiable neural rendering,允许在没有3D监督和推理时间优化的情况下进行训练,以进一步提高质量。与现有的神经渲染作品相比,我们的类MVS架构可以自然地进行跨视图对应推理cross-view correspondence reasoning,有利于推广到未知的测试场景,也导致更好的神经场景重建和渲染。因此,我们的方法可以明显优于最近的并行可概括NeRF工作concurrent generalizable NeRF work[54,46],该工作主要考虑2D图像特征,而没有明确的几何感知3D结构(参见表。1和图4)。 我们证明,仅使用三个输入图像,我们从DTU数据集训练的网络可以在测试DTU场景上合成照片级逼真的图像,甚至可以在具有非常不同的场景分布的其他数据集上生成合理的结果。此外,我们估计的三个图像辐射场(神经编码体积)可以在新的测试场景上进一步轻松优化,以在捕获更多图像的情况下改善神经重建,从而产生与每个场景过拟合NeRF相当甚至更好的照片级逼真结果,尽管我们的优化时间比NeRF少得多。
该方法利用深度MVS的成功,在成本体上应用3D卷积来训练用于3D重建任务的可泛化神经网络。与MVS方法不同的是,MVS方法仅对这样的成本体进行深度推断,而该网络对场景几何和外观进行推理,并输出神经辐射场,从而实现视图合成。具体而言,利用3D CNN,重建(从成本体)神经场景编码体,由编码局部场景几何和外观信息的体素神经特征组成。然后,多层感知器(MLP)在编码体内用三线性插值的神经特征对任意连续位置处的体密度和辐射度进行解码。本质上,编码体是辐射场的局部神经表征;其一旦估计,可直接用于(丢弃3D CNN)可微分光线行进(ray-marching)进行最终渲染。
与现有的MVS方法相比,MVSNeRF启用可微分神经渲染,在无3D监督的情况下进行训练,并优化推断时间,以进一步提高质量。与现有的神经渲染方法相比,类似MVS的体系结构自然能够进行跨视图的对应推理,有助于对未见测试场景进行泛化,引向更好的神经场景重建和渲染。
如图1是MVSNeRF的概览:(a)基于摄像头参数,首先将2D图像特征warp(单应变换)到一个平面扫描(plane sweep)上,构建成本体;这种基于方差的成本体编码了不同输入视图之间的图像外观变化,解释了由场景几何和视图相关明暗效果引起的外观变化;(b)然后,用3D CNN重建逐体素神经特征的一个神经编码体;3D CNN 是一个3D UNet,可以有效地推断和传播场景外观信息,从而产生有意义的场景编码体;注:该编码体是无监督预测的,并在端到端训练中用体渲染进行推断;另外,还将原图像像素合并到下一个体回归阶段,这样可恢复下采样丢失的高频;(c)用MLP,通过编码体插值的特征,在任意位置回归体密度和RGB辐射度,这些体属性由可微分光线行进做最终的渲染。