
code:https://github.com/yu-li/TCMonoDepth
在视频估计领域,现有的单眼深度估计方法利用单张图像和差强人意的时间稳定性。这通常意味着需要后处理手段。一些基于深度的视频估计利用重建框架如SFM、序列建模。这些方法在某些方面做了系列假设,因此真实应用时具有一定的局限性。
文章提出一种简单的方法,旨在提高视频深度估计时的时间一致性。没有任何后处理和额外计算成本的情况。
具体:从视频数据中学习了一个先验,这个先验可以直接施加到任何单一图像的单目深度方法。
测试时只是逐帧进行端到端的正向推理,没有任何顺序模块或多帧模块。
此外提出了一个评估指标,定量衡量时间一致性的视频深度预测。它不需要标记深度地面真相,只评估连续帧之间的闪烁。一份主观研究表明,提出的度量标准与用户的视觉感知是一致的,一致性得分较高的结果确实是首选。
这些特点使文章方法成为一种实用的视频深度估计器,可以预测真实场景的密集深度,并支持多种基于视频深度的应用。
作者介绍了一种简单而有效的方法来加强视频深度估计的时间一致性。一个基本假设:如果连续帧中对应的像素漂移很多,闪烁就会出现。通过对这种对应下的预测进行约束和对齐,引导模型在单帧推理下产生具有强一致性的深度估计。同时,定义了一个度量来公平地评估深度估计结果随时间的稳定性,其不需要标记的地面真值进行处理。
一种新的评估指标,测量视频深度估计结果的稳定性。实验表明,该指标是OK的,并与人类视觉判断深度一致。提出了一种有效的方法在训练过程中施加时间限制。然后学习该模型,只有单一帧输入的情况下,产生稳定的深度预测。将该方法扩展到没有深度地面真值的动态视频。展示了可以很容易地使用未标记的视频强制约束和规范模型。主观研究表明,作者方法提供了更好的一致性值和可察觉的较少闪烁的结果。
时间一致性度量:
强制一致的模型应该在整个周期内,得到不包含明显闪烁的深度估计结果。两个连续的深度图的变化通常来自几个方面:
1、场景中物体的移动
2、镜头的变换和旋转
3、同一区域意外频繁的漂移
对于高帧率的视频,帧与帧之间的变化较小,连续两帧之间的深度值在对应像素上应该几乎相同。基于单图像的方法通常对帧间的这种变化没有任何限制,因此会出现闪烁现象,使得在三维坐标中属于同一单位的像素深度值在时间轴上发生频繁而随机的漂移。
为了测量连续深度结果的稳定性,需要在每对连续帧中识别相应的像素,并确定这些像素在整个视频中如何波动。在前人对语义分割一致性评估的基础上,很容易提出用光流搜索对应像素点的思想。
度量指标:
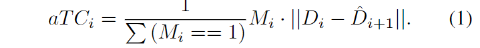
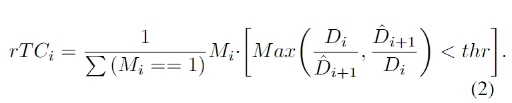
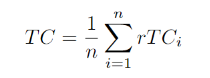

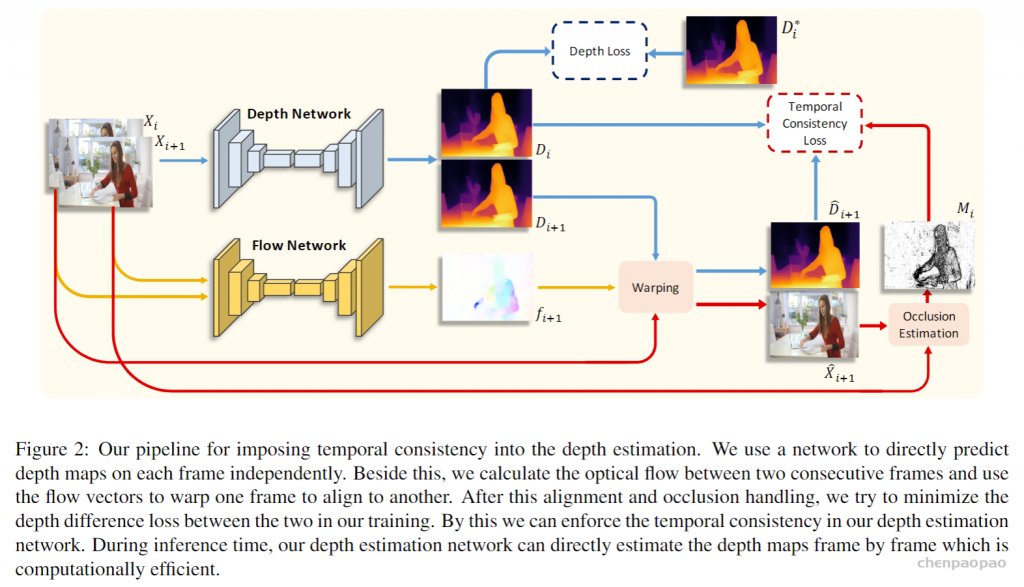
本文模型建立在单张图像深度估计,旨在将学习时间一致性强加到原始深度网络上。
训练阶段:
将两个相邻帧,分别进行相应的深度估计,遵循单张图像深度估计方法,可以测量深度估计与地面真实深度的差,这只是传统的深度预测精度的损失,在训练中被最小化。前向传递、损失计算和后向传递分别适用于两帧。

时间一致性损失-目的:减少两个连续帧之间的深度偏移。 由于两个坐标系之间存在运动,需要在测量距离之前对其进行补偿。

关于数据集的标签:
数据集:难以捕获大尺度、多样化的视频深度数据集。作者建议使用从最先进的单眼深度方法中提取的监督。具体来说,使用MiDaS网络作为教师,对来自多个数据集的大量数据进行预训练。MiDaS已被证明具有良好的泛化能力,适合一般深度估计目标。在这种情况下,前面描述的管道仍然适用,但只是将MiDaS网络的输出作为监督信号Dt *。
实验结果:

第二行:使用BTS生成的深度估计图。
第三行:使用CLSTM生成的深度估计映射。
最后一行:作者方法生成的深度估计图。
为了更好地可视化视频稳定性,将不同帧和深度估计的相同区域放大并拼接在最后一列上。

最先进的基于单图像的方法MiDaS[32]可以产生帧级高质量的深度图,
但随着时间的推移会有明显的闪烁。
将时间一致性引入深度估计模型后,作者方法可以预测时间上更稳定的深度预测。
总结:
在这项工作中,作者介绍了一种简单而有效的方法来提高单帧深度估计下视频深度估计的时间一致性。同时还提出了一种时间一致性度量,该度量与人类对视频稳定性的感知相一致。实验表明,作者方法可以表现出更稳定的深度估计,并且可以推广到动态真实世界的视频中,而不需要相应的深度地面真值。