
Geometry-Free View Synthesis: Transformers and no 3D Priors
引入一种基于 transformers 的概率方法,用于从具有大视角变化的单一源图像中进行新视图合成。作者对transformers 的各种显式和隐式 3D 感应偏置进行比较,结果表明,在架构中显式使用 3D 变换对其性能没有帮助。此外,即使没有深度信息作为输入,模型也能学会在其内部表示中推断深度。这两种隐式 transformer 方法在视觉质量和保真度上都比目前的技术状态有显着的改进。
将开源:https://github.com/CompVis/geometry-free-view-synthesis
论文:https://arxiv.org/abs/2104.07652
自回归transformer模型
问题:大角度变换,CNNs需要几何模型。
解决:不需要任何手工设计的三维偏差:(i)一种隐式学习源视图和目标视图之间的远程三维对应关系的全局注意机制来实现。 (ii)捕捉从单个图像预测新视图所固有的歧义所必需的概率公式,从而克服了以前局限于相对较小的视角变化的方法的局限性。(iii)发现以显式深度图的形式提供它们几何信息的好处相对较小,并研究了从transformer的层中恢复显式深度表示的能力,它已经学会了隐式地表示几何变换,而无需任何深度监督,甚至可以学习以无监督的方式预测深度。
相关工作:本文从GPT-2架构构建自适应transformer,即,多块多头自注意,层规范和位置向MLP。自回归两阶段方法:是基于在神经离散表示学习(VQVAE)中的工作,它旨在通过向量量化或离散分配的软松弛来学习一个离散的压缩表示。这种训练范式提供了一个合适的空间来训练潜在表示上的自回归似然模型,并已被用于训练生成模型来训练分层,类条件图像合成、文本控制图像合成和音乐生成。最近,证明了VQVAE的对抗性训练在保持高保真度重建的同时提高了压缩性能,随后,我们能够在学习的潜在空间上有效地训练自回归transformer模型,(产生一个所谓的VQGAN)。我们直接在这项工作的基础上,使用VQGANs来表示源视图和目标视图,并在需要时表示深度图。
方法:由于不确定性,我们遵循一种概率方法,并从以下分布中采样新视角。
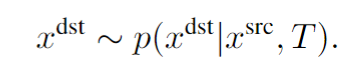
潜在空间中的概率视图合成:
为了学习上式中分布,需要捕获源视图和目标视图之间的远程交互的模型,以隐式地表示几何变换。由于基于相似的模型已经被证明直接在像素空间中建模图像时,在像素的短程交互上花费了太多的容量,我们遵循VQGAN并采用了两个阶段训练。第一阶段执行反向(对抗性)引导的离散表示学习(VQGAN),获得一个抽象的潜在空间,已被证明非常适合有效地训练生成式transformer。
建模条件图像模型:
VQGAN包括一个编码器E,解码器G和一个离散表征zi(dz)的codebook Z。训练后的VQGAN允许编码任意x(HxWx3)到离散隐空间E(x)(h x w x dz)。以栅格扫描的顺序展开,这个潜在的表示形式对应于一个序列s(h x w x dz),可以等价地表示为一个整数序列,索引已学习的码本。按照通常的名称,我们将序列元素称为“tokens”。一个嵌入函数g=g(s) (hw x de)将每个tokens映射到transformer的嵌入空间中,并添加了可学习的位置编码。类似地,为了编码输入视图xsrc和照相机转换T,两者都由一个函数f映射到嵌入空间中:
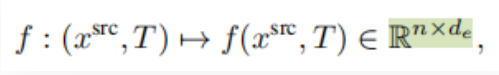
其中,n表示条件处理序列的长度。通过使用不同的函数不同的归纳偏差被纳入架构。然后,transformer T处理所连接的序列[f(xsrc,T),g(sdst)]去学习以xsrc和T为条件的合理的新观点的分布。
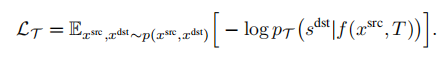
编码Inductive Biases:比较几何变换的方法被显式地构建到条件函数f中,和没有使用这种转换的方法。
几何图像扭曲:这一部分说明显式几何变换怎么运用。我们假设有一个针孔照相机模型,这样三维点到齐次像素坐标的投影通过相机固有矩阵K确定。源坐标和目标坐标之间的转换是由旋转R和平移t组成的刚性运动给出的。这些参数一起指定了对要生成的新视图的所需控制,如T=(K,R,T)。
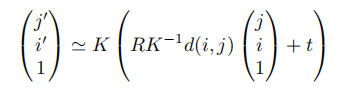
此关系定义了一个从源到目标的前向流场作为深度和相机参数的函数。然后,流场可以通过扭曲操作S将源图像xsrc扭曲到目标视图中。由于从流中获得的目标像素不一定是整数值,因此我们遵循,并通过跨越四个最近的目标像素的双线性溅射特征来实现S。当多个源像素映射到相同的目标像素时,我们使用它们的相对深度给予离相机更近的点权重——这是z缓冲的软变体。
在最简单的情况下,我们现在可以描述显式方法和隐式方法在接收关于源图像和期望的目标视图的信息的方式之间的区别。此处,显式方法接收使用相机参数扭曲的源信息,而隐式方法接收原始源图像和相机参数本身,如:
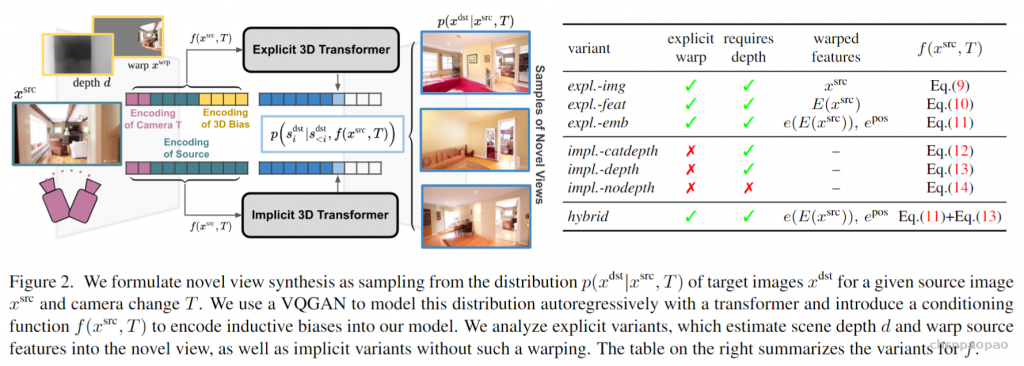
显式几何变换:
在下面,我们用transformer的条件函数f来描述所有被考虑的变体。此外,e还表示一个可学习的嵌入映射离散的VQGAN代码E(x)到转换器的嵌入空间。相似地,e pos(n x de)指一个可学习的位置编码。流场F总是从xsrc计算,以提高可读性,我们从扭曲操作的参数中忽略它,S(.)=S(Fsrc->dst(K,R,t,d)).
(1)我们的第一个显式变体,expl.-img,会扭曲源图像,并以与目标图像相同的方式对其进行编码:
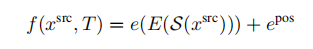
(2)受之前的作品的启发,我们包含了一个expl.-feat变体,它首先编码原始源图像,然后在这些特征之上应用warp。我们再次使用了VQGAN编码器E,以获得:
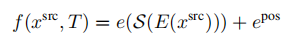
(3)解释上式中扭曲的特征保持固定状态。
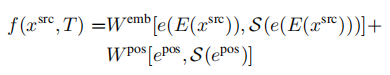
隐式几何变换:接下来,我们描述我们用来分析的隐式变量,transformer能否同样好地处理所有位置,是否需要在模型中内置一个显式的几何转换。我们使用与显式变体相同的符号。
(4)第一个变体impl.-catdepth为transformer提供了显式变体中使用的所有相同组件:相机参数K、R、t、估计深度d和源图像xsrc。相机参数被拉平并连接到T^,通过Wcam(de x 1)映射到嵌入空间。深度和源图像被VQGAN编码器Ed和E编码来获得
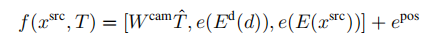
与其他变体相比,这个序列大约长32倍,这是计算成本的两倍。
(5)因此,我们还包括了一个impl.-depth变体,它连接了深度和源图像的离散代码,并用一个矩阵W(de x 2dz)映射它们到嵌入空间以避免序列长度增加:
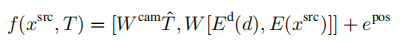
(6)隐式方法提供了一个有趣的可能性:因为它们不需要明确地估计该深度来执行扭曲操作S,所以它们在没有这样的深度估计的情况下具有解决该任务的潜力。因此,输入深度仅使用相机参数和源图像-根据我们的任务描述的最低限度。Impl.nodepth:
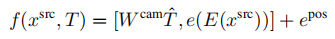
(7)最后,我们分析了显式方法和隐式方法是否提供了互补的优势。因此,我们添加了一个混合变体,其条件函数是方法(3)中expl.-emb和方法(5)中impl.-depth的f的结合。
深度读数输出:为了研究学习不同视图之间几何关系的隐式模型的能力,我们建议从一个训练过的模型中提取一个深度的显式估计。为此,我们使用线性探测,通常用于研究无监督方法的特征质量。更具体地说,我们假设一个由L层和impl.nodepth类型组成的transformer模型,它仅基于源框架和变换参数。接下来,我们指定一个特定的层0≤l≤L(其中l=0表示输入),并提取它的潜在表示el,对应于所提供的源框架xsrc的位置。然后,我们训练一个逐位置线性分类器W来预测深度编码器Ed的离散的、潜在的表示,通过一个来自el的交叉熵目标。请注意,transformer和VQGAN的权重均保持不变。
隐式,显式transformer比较:
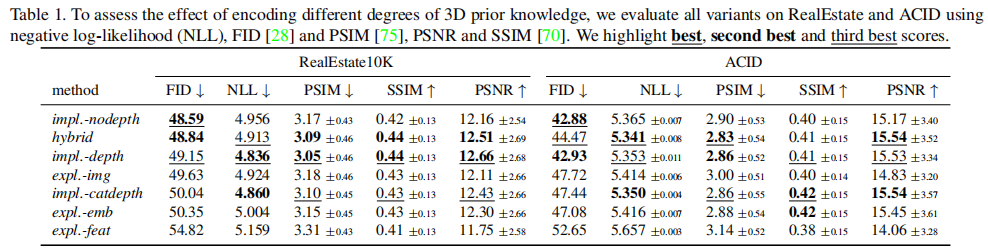
数据集: RealEstate and ACID.
其他实验:比较密度估算的质量,实现预测的可视化熵,测量图像质量和保真度,与以前的方法进行比较,对几何图形的探测
