
最近任务需求跟图像inpainting相关,因此调研使用了多个较新的开源模型,例如crfill、RePaint、Lama等。综合比较之下Lama的速度、效果都是最佳的,并且支持自定义输入尺寸进行推理(而非必须固定输入尺寸)。因此结合Lama论文进行实操,记录如下。

一、总体方法 & 创新点
1、总体方法流程:
对于输入原图 x ,使用一个二进制掩膜 m 进行遮罩 x ⊙ m ,形成一个四通道的输入tensor :
x′ = stack(x ⊙ m, m)
再使用一个前向infer网络fθ(·)(也是一个生成器),以全卷积方式修复获得一个三通道彩色图像。
训练过程也是基于“图像与掩膜”这样的pair数据进行的。
2、创新点:
1)旧有方法都不具备足够广泛的感受野,因此对于大分辨率的图像或是大范围的inpainting而言,很容易会被局部附近的细节或干脆是mask所影响导致效果差。因此Lama考虑让模型在网络初始阶段就拥有更大的感受野,提出了基于快速傅立叶卷积(FFC)构造的网络结构。
2)损失函数:利用预训练分割网络进行特征提取实现损失函数构建,服务于大感受野和大掩膜
3)mask生成方法:动态的生成大掩膜,实现类似数据增强的效果
二、具体方法
1、Baseline:
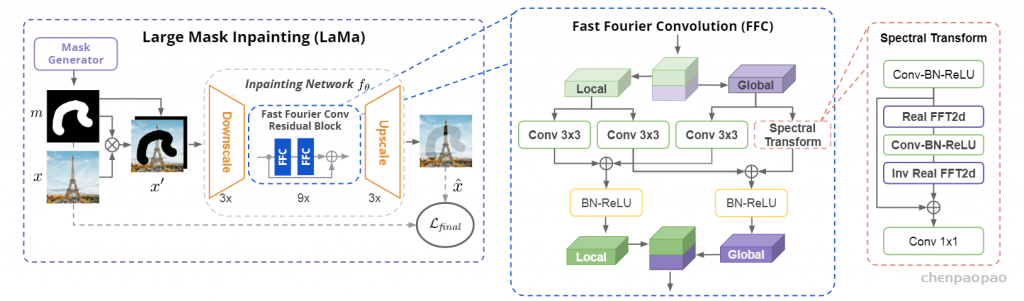
图像与掩膜组成pair对输入网络并经过下采样后,进入FFC残差块。
在FFC块中,输入tensor被划分为两个分支进行运算。Local分支使用常规卷积;Global分支使用Real FFT进行全局上下文关注。其中在Global分支中经历了Real FFT2d和Inverse Real FFT2d的操作,实现了图像重建,具体张量变化看见论文2.1中的a)、 b)、c)。在FFC的输出中两分支进行结果合并。
2、损失函数
首先需要明确的是,对一个被掩膜遮盖的区域其实可以有多种合理的填充结果,就像口罩下的长相谁也无法准确预测。所以一旦掩膜变大,那么loss就必须被更加合理地设置以避免不符合事物逻辑的生成。
1)高感受野知觉损失 HRFPL
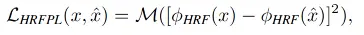
HRFPL是通过预训练的基础网络对输入图像x和生成图像x尖进行特征相似的计算。具体来说是使用空洞卷积或傅立叶卷积构建的HRF进行逐像素计算,然后M代表两阶段均值操作,即先取同层均值再取层间均值。
作者认为选取一个合适的预训练网络对于 HRFPL的效果至关重要。例如分类网络更关注局部的细节纹理,而难以理解全局的结构信息,缺乏对整体的认知。而分割模型则相反,具有更好的效果。
2)对抗损失
作者定义了一个在局部补丁级别上工作的鉴别器Dξ(·),用于区分“真实”和“虚假”补丁。对于输入pair对中的原图和掩膜图片,将原图上被掩膜覆盖的区域标记为“real”标签,将生成图片上对应区域标记为“fake”标签。

3)总体损失
在总体损失中,作者还使用
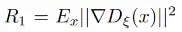
进行梯度惩罚,和基于识别器的感知实际损失或所谓的特征匹配损失-感知鉴别器网络LDiscPL的特征损失。众所周知,LDiscPL可以稳定训练,在某些情况下性能略有提高。
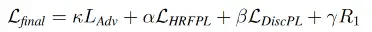
LAdv和LDiscPL负责生成自然外观当地细节,而LHRFPL负责监督全局结构的信号和一致性。
3、训练中的动态掩膜生成
作者认为掩膜的生成类似于数据增强,对模型的效果非常重要。作者采取了多种大掩膜生成方式,但也同时注意避免生成大于原始图像50%的掩膜。

三、实验与数据
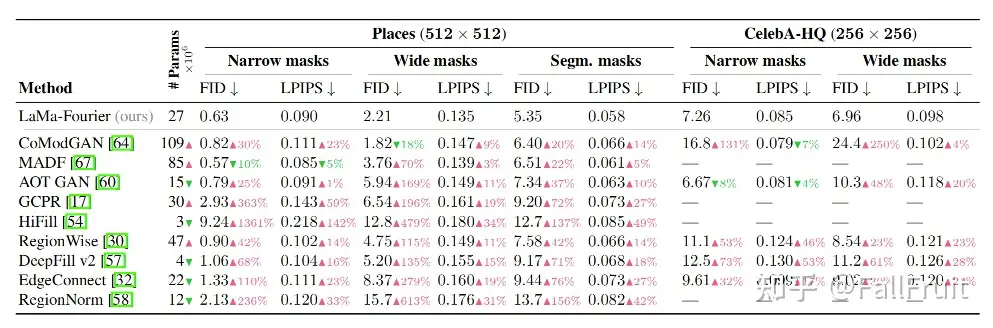
训练使用Places和CelebA进行。下图结果中与其他模型在不同大小的掩膜上进行了对比,红色箭头代表表现逊于Lama,绿色则表示优于Lama。可以看到Lama在少参数量的情况下效果基本达到最优。
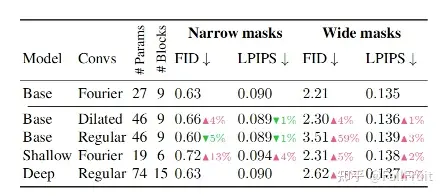
消融实验也证明了FFC在大掩膜上的效果。
论文还提供了大量实验细节,感兴趣的请查看原文。
四、使用记录
官方开源的模型中提供了一个名为Big-Lama的模型权重,效果最优。因为相比普通Lama,其生成器结构更复杂、训练数据规模更大。该模型是根据来自Places Challenge数据集的4.5M张图像的子集进行训练的,在八台NVidia V100 GPU上接受了约240小时的train。

我在Big-Lama上对infer refine的参数、mask生成方式做了反复测试,直观感受是其修复效果在其较快的infer速度上的确已经相当不错。同时我也尝试在训练中修改了mask的动态生成策略,实现了自定义mask生成来贴合我的任务场景,但考虑到训练成本尚未进行大规模训练,欢迎大家交流。