
https://arxiv.org/pdf/2405.07992
GitHub – yuweihao/MambaOut: MambaOut: Do We Really Need Mamba for Vision?
作者的主要观点可以概括如下:
- Mamba架构的适用性:作者认为Mamba架构,具有类似于RNN的token混合器状态空间模型(SSM),最适合处理具有长序列和自回归特性的任务。
- Mamba在视觉任务中的表现:尽管Mamba被引入以解决注意力机制的二次复杂性问题,并应用于视觉任务,但在图像分类等任务中,其性能通常不如卷积神经网络和基于注意力的模型。
- Mamba在图像分类任务中的不必要性:作者提出,由于图像分类任务既不符合长序列也不符合自回归特性,因此引入Mamba是不必要的。
- Mamba在检测和分割任务中的潜力:尽管检测和分割任务不是自回归的,但它们符合长序列特性,因此作者认为探索Mamba在这些任务中的潜力是有价值的。
- MambaOut模型的构建与验证:为了验证上述假设,作者构建了一系列名为MambaOut的模型,这些模型在不使用Mamba核心token混合器SSM的情况下堆叠Mamba块。实验结果强烈支持作者的假设。
- MambaOut模型的性能:MambaOut模型在ImageNet图像分类任务上超越了所有视觉Mamba模型,表明Mamba对于图像分类任务确实不是必需的。然而,在检测和分割任务上,MambaOut未能达到最先进的视觉Mamba模型的性能,显示了Mamba在长序列视觉任务中的潜力。
-
未来研究方向:由于计算资源的限制,本文仅验证了Mamba在视觉任务上的概念。作者提出,将来可能会进一步探索Mamba和RNN概念,以及RNN和Transformers在大型语言模型(LLMs)和大型多模态模型(LMMs)中的集成。
结论:本文从概念上讨论了Mamba机制,并得出结论认为它非常适合具有长序列和自回归特性的任务。我们根据这些标准分析了常见的视觉任务,并认为在ImageNet图像分类中引入Mamba是不必要的,因为它不符合这两个特性。然而,对于与长序列特性相符合的视觉检测和分割任务,Mamba的潜力值得进一步探索。为了实证支持我们的观点,我们开发了MambaOut模型,这些模型采用了没有核心标记混合器SSM的Mamba块。MambaOut在ImageNet上超越了所有视觉Mamba模型,然而与最先进的视觉Mamba模型相比,它表现出明显的性能差距,从而验证了我们的主张。由于计算资源的限制,本文仅验证了视觉任务中的Mamba概念。将来,我们可能会进一步探索Mamba和RNN概念,以及将RNN和Transformers集成到大型语言模型(LLMs)和大型多模态模型(LMMs)中。
一、Mamba 到底 OUT 了没?
文章首页展示方式非常赞的:
首先标题开宗明义,强调讨论点其实是 Mamba对 Vision 的应用?NLP 排除了,因为那就是纯纯的序列问题,Mamba 还是非常值得继续深入研究,还有很大水文的空间哈。其次,非常显著的给出了 github 代码连接,一句对科比的致敬也让技术型文章多了点人文色彩。它来自于科比 2016年4月 14日最后一场比赛后,为了感谢全场球迷有感而发脱口说的告别词。Mamba 原意是毒蛇,象征着科比在球场上的攻击性和坚韧不拔。后来几乎成了互联网上的一个梗。从 Transformer开始,AI界写论文都兴起玩梗了,既是为了宣传,也是为了突出与众不同,在万千文章中让人记住,用心良苦着实让人感动。但是不是Mamba 真的 OUT,咱们讲完就知道了。
第三,图1一目了然的给出了与 Mamba 模块的主要区别,就是干脆做减法去掉了 SSM 结构,右图体现了性能上的差别,注意这仅在ImageNet的分类任务上。没有 NLP 数据集,没有其他视觉任务,仅仅图像分类!
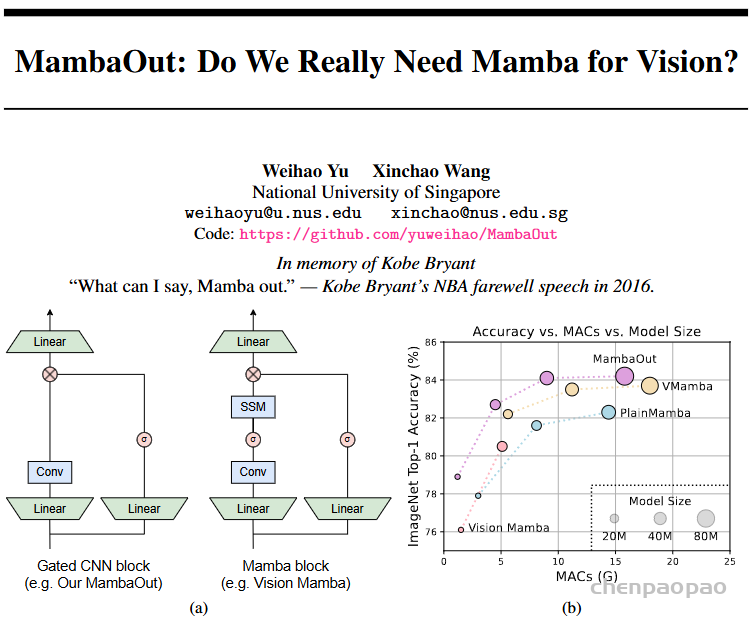
整个摘要的重点,也是结论性的东西,作者其实用斜体给你标出来了
1.long-sequence and autoregressive 这方面 Mamba 依然擅长,承认优点。
2.图像分类不是 autoregressive 自回归任务,也不是long-sequence,因此用不着 Mamba所以 MambaOut。比如在ImageNet 分类任务上
3还有第三个结论也很有意思,即使是视觉领域,目标检测和实例分割任务上 Mamba还OUT不了,依然有潜力。明白了吗?
二、如今该爱谁:Transformer、Mamba和MambaOUT
虽然标题大胆而耸人听闻,但引言部分还是很旗帜鲜明的给足了Mamba Credit。简单的说就Transformer 有硬伤,面对长序列时自注意力机制计算的复杂度会出现随窗口长度二次方增加的问题。
Mamba 模型的出现引起了 A1 社区的广泛兴趣,因为具有可并行训练和高效长序列推理的能力。除了 Mamba 外,很类似的还有 RWKV 模型大家也可以关注一下。最近这半年出来了一批模型。简单的说都是“RNN+注意力机制”相结合的产物,区别在于适用任务和架构设计上的差异,有的更专注于 NLP 任务,有的尝试用在视觉上。
整篇文章的研究重点其实就是前言中几行斜体字:
Do we really need Mamba for Vision? 视觉问题真得需要Mamba 模型吗Hypothesis 1:SSM 对于图像分类没有必要,因为该任务既不具有长序列特征也不具有自回归特征。
Hypothesis 2:sSM 可能对对象检测和实例分割有潜在好处,因为这些任务具有长序列特征,但不具有自回归特征。
重要的是三个问题:怎么分析的,模型怎么实现的,以及怎么用实验证明的。
第二部分相关工作简要小结了 Transformer 典型模型 BERT和 GPT系列,以及 ViT 强调了Transformer 中的注意力模块会随序列长度增加而扩展,带来显著的计算挑战。许多研究探索了各种策略来缓解这一问题,如低秩方法、内核化、token 混合范围限制和历史记忆压缩。这都是水文章的号方向。最近,RNN-like方法(特别是 RWKV和Mamba)因其在大规模语言模型中的出色表现而受到关注,这点到目前为止还是毋庸置疑的。
对于Transformer 的改进或者说平替,现在学界的一种典型思路就是回归传统模型,从故纸堆里找灵感。这篇文章的作者显然也认同这种观点,而且直接露骨的把它们称作 RNN-like 方法,其实最新的还有 xLSTM。但这种视角还是浅了,仅仅是从模型结构视角来看,做一种时序回归而已。第二段小结了 Mamba 最新的各种变体,包括 Vision Mamba 整合了 SSM 来开发类似ViT 的等向性视觉模型;VMamba 则利用 Mamba 构建类似 AlexNet和 ResNet 的分层视觉模型;LocalMamba 通过引入局部归纳偏置来增强视觉 Mamba 模型;
PlainMamba 旨在进一步提升等向性 Mamba 模型的性能,还有 EfficientVMamba等等。你看事实上大家这半年来以及像吸血鬼一样迅速扑上去搞 Mamba 了,把它作为Transformer 的平替。而这篇文章试图把自己打扮成“半血猎人“来拯救世界。你说它是Mamba吧,它说自己不是,你说它就是CNN吧,它非要把自己和Mamba比,还起了这么个名。有意思,也很拧巴。
三、核心原理
论文第三部分正式开始分析 Mamba优缺点,适合什么任务。直接看公式容易迷迷瞪瞪,不明觉厉:

1.Mamba 的本质回顾
文章中提到 Mamba 是个 token 混合器 mixer,这和我上期给大家讲的如出一辙,咱们当时是说“掺和”,看下图,B掺和了三次,C掺和了两次。
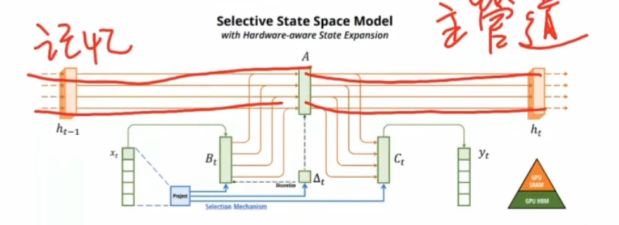
其实用流体力学视角 看 Mamba 更透彻,本质上就是当成一个记忆流淌的管道系统而 selective SSM 就是个带着总开关 delta + 两个阀门 BC + 主管道A的系统。因为A 与时间无关,因此隐藏状态 h可以视为固定大小的记忆,存储所有历史信息。固定大小意味着记忆不可避免地丢失,但保证了与当前输入集成的计算复杂性保持不变而通过总开关 delta + 两个阀门 BC 门控机制实现了一种选择性注意力机制。这种设计更加的高效,从更抽象的数学角度理解,是用李指数隐射拟合数据,替换了原有的牛顿力学运动方程。
2.自注意力机制的类别
相比之下,Transformer 中的自注意力机制更加复杂,如下图有两种:一种叫因果模式,其实就是只能看过去,不能看未来,只有记忆没有未卜先知;另一种是全可见模式,左右都知道。Transformer 本质上两种都可以,因果模式的比如 GPT,全可见的比如 BERT,前者适合自回归用来生成和预测,以史为鉴,后者适合理解,左顾右看瞻前顾后。
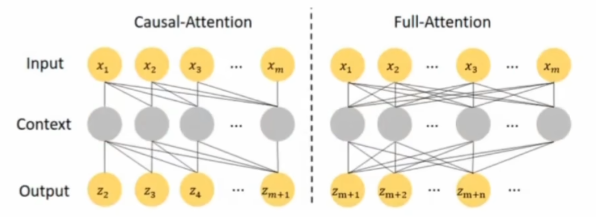
按照这种分类,Mamba的选择性机制算那种呢?显然不是全可见模式,看公式就知道是因果模式,但和 Transformer 的有什么不同呢?
下图展示了 Transformer 因果注意力与 Mamba 中因果注意力的区别,前者是组合(叠加)之前所有的记忆,记忆无损但复杂度增加,越累越长,计算复杂度同样为0(L^2):后者融合之前的记忆到新的隐藏状态,记忆有损但复杂度恒定
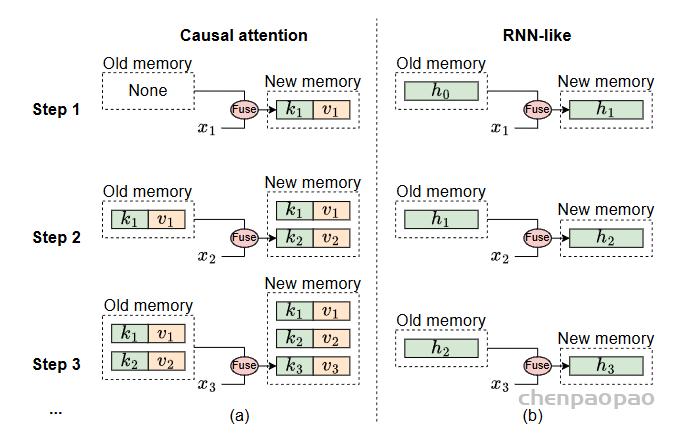
基于 Mamba 的这种特性,显然它适用于以下特征的任务
·特征 1:任务涉及处理长序列,因为复杂度低,更高效
·特征 2:任务需要因果 token 混合模式。
但这样以来还怎么 OUT 呀!于是他们反向思考:首先,什么时候不需要长序列呢?视觉作为空间数据,那种最不需要呢?你说是鸡蛋里挑骨头也好,逆向思维也好。既然逻辑上它擅长长序列,那就说明短序列一般,那咱们就摁着短序列搞不就成了。
其次,什么时候不需要因果注意力呢?什么问题需要全局可见注意力呢?着这个方向搞,不也能证明 Mamba不行吗?这种创新的思维方式确实聪明,典型的田忌赛马思路,你打你的,我打我的,拉到我擅长的地方打,你还打得过吗?
3.视觉任务的特点分析
在视觉识别任务中,感觉上图像分类就不属于长序列任务,因为主要关注整体特征空间特征就够了,目标也只是粗犷的类别标号,因此不涉及什么序列信息,而且需要全局信息。但是目标检测和语义分割则不一定,比如要考虑边缘的连贯性,因此可能有序列问题。但是,这种假设或者感觉怎么证明呢?首先,文章针对图像分类任务,做了全可见模式和因果模式性能的分析实验。如图所示:
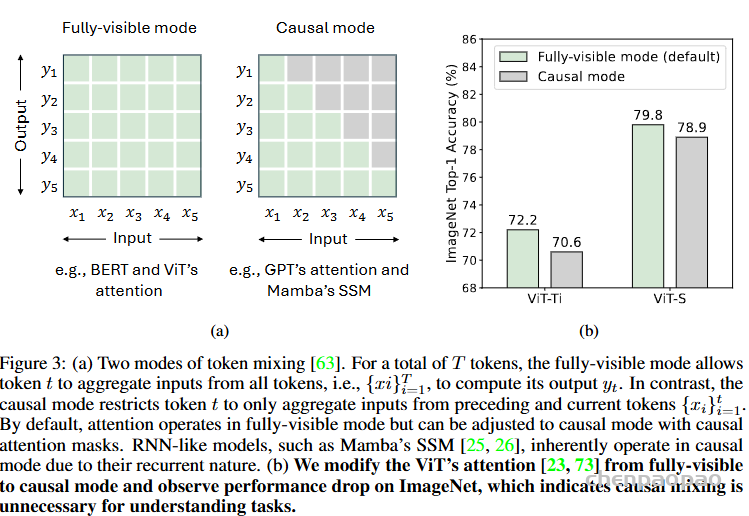
左图是全可见模式,横纵轴互相都能看,BERT和ViT 的自注意力机制都是这种。中间图是因果模式,GPT的自注意力机制和 Mamba的 SSM 是这种,比如y3 只能看到x1-x3,看不见 x4-x5。右图显示以 ViT 为例,将自注意力机制从全可见模式切换到因果模式后,性能有所下降,说明对于图像分类问题,用因果模式没必要。
既然注意力机制的类型明确了,在图像分类这一亩三分地上干掉 Mamba 的可能性暴增。但老问题又回来了,怎么确定它是不是长序列任务呢?整篇文章最有点数学理论含量,也是最有看点的就是32关于图像处理任务是否属于长序列问题的分析。
分析的切入点选择了 Transformer 的浮点运算次数公式,也就是一个Transformer 块的
计算量:
FLOPs = 24D2L + 4DL2
其中 L是 token 长度(即输入序列的长度),D 是通道维度(即特征维度),加号前后分别代表线性复杂度和二次复杂度。为什么要看这个,因为Transformer的硬伤不就是长序列运算量随着窗口长度暴涨吗?针对具体任务,如果我们能知道它们的计算量是不是对L敏感,那不就知道它是不是需要长序列建模了吗?
这个公式可能没几个人熟悉,也不知道怎么来的呢?我们来拆解下加深理解,因为它对理解这篇文章的核心思想非常关键。
在 Transformer 模型中,自注意力机制是计算量最大的部分。为了估算 Transformer 块的计算量(即浮点运算次数,FLOPS),需要考虑自注意力机制和前馈神经网络(FFN)的计算。



在 ViT 中图像首先被分割成多个固定大小的 patches,每个的大小通常为 16×16 像素
Token 数:假设输入图像大小为 224 x 224,则生成的 token 数为(器)=14×14 =196.
每个这样的 patch 通道被展平成一个长向量,RGB 三通道就是 16163=768,然后通过一个线性投影层(粉色的)映射到高维空间,也就是通道维度D,它是个指定的超参数。
对于 ViT-S,常见的通道维度 D为 384。对图像分类任务L=196,远小于6D=6384=2304,因此不涉及长序列建模。
目标检测和实例分割问题:在COCO 数据集上推理图像大小为800×1280,生成的token 数约为 4000,大于 6D=6384=2304,因此涉及长序列建模。
这个结论和我们先前的直觉分析是一致的:图像分类模型不需要处理非常长的序列来捕捉远距离的依赖关系,序列长度L相对较短,模型的注意力窗口不需要很大。
在实例分割和目标检测任务中,虽然图像同样被分割成 patches,并作为序列输入到模型中,但不仅需要识别图像中的对象,还需要确定对象的位置和边界。由于输入图像通常更大,生成的 tokens 数量(序列长度L)也更多。需要捕捉远距离的依赖关系,例如物体的边缘和不同部分之间的关系。模型需要处理较长的序列,自注意力机制的窗口需要更大,以捕捉这些复杂的依赖关系。
3.3 和 3.4 进一步讨论了视觉识别任务是否需要因果注意力以及 SSM 机制的必要性。其实结论已经很明显了,既然它和长序列没有关系,那就是理解任务,当然需要全可见型注意力机制,不需要时序记忆,而需要空间全局可见的高屋建瓴。
因此本文主要 IDEA 在于验证了两个假设假设 1:在 ImageNet 上的图像分类任务中引入 SSM 没有必要,因为这个任务不需要长序列建模或自回归特性。
假设 2:尽管目标检测和分割任务不需要自回归特性,但由于这些任务涉及长序列建模,因此值得探索 SSM 在这些任务中的应用潜力。
明白了分析的过程,咱们看看模型架构。
- 模型架构
下图展示了 MambaOut 模型的总体框架以及 Gated CNN 块的具体结构。整体框架类似于 ResNet,通过降采样逐步减少特征图的尺寸,同时增加特征的抽象层次。
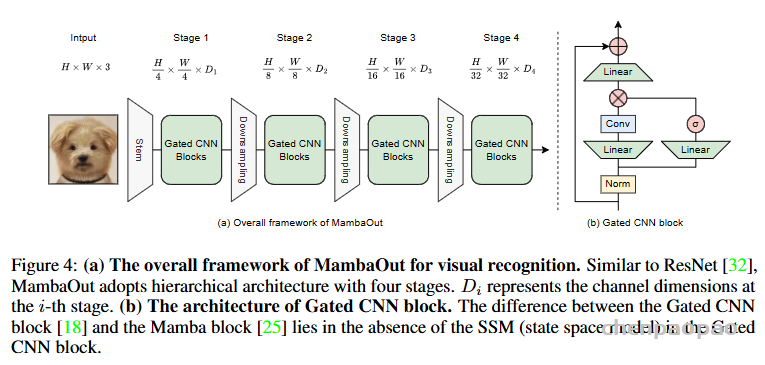
输入图像大小为 HxWx3,表示图像的高度、宽度和 RGB 三个颜色通道。采用了分层架构,共有四个阶段,每个阶段进行特征提取和降采样。每个阶段包含若干个 GatedCNN 块,用于特征提取。每个阶段之间有降采样操作,将特征图的大小逐渐减小,从而增加特征的抽象层次。通道维度为D1,D2,D3,D4。
右侧是基本组件,Gated CNN块包含两个线性层、中间夹一个卷积层和归一化层,通过残差连接实现输入和输出的融合。和 Mamba块的区别在于前者没有 SSM(状态空间模型)。
MambaOut 的架构与 Swin Transformer 和 DenseNet 在分层结构和降采样方面有相似之处,但在特征提取和信息混合机制上有所不同。MambaOut使用 GatedCNN块而 Swin Transformer 使用窗口注意力机制的 Transformer块,DenseNet 则使用密集连接的卷积层。这些差异决定了它们在处理不同任务时的特性和优势。
这么看,MambaOut 实际上就是在 Gated CNN 基础上的优化版本,通过结构简化和实验验证。更准确的说主要就是和 Mamba 做针对性的对比而已,在视觉识别任务中进行了优化和验证。
结论:如果说 Mamba是回归RNN+新型注意力机制,那 Mamba0ut 其实是回归CNN+新型注意力机制。
既然如此,读到这里时其实产生了很大的困惑,这不就是纯纯的CNN吗?不就是 ResNet 吗?它怎么还好意思叫 MambaOUT呢?这个 Gated CNN 神奇到哪里了呢?确实,网络结构上的改进比较小,但人家起作用了啊。魔鬼在细节:
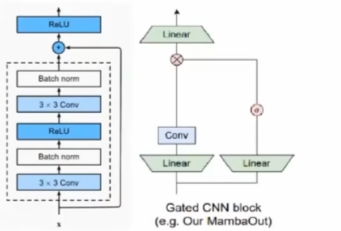
对比左边的 ResNet,两大微小的区别:
一是使用线性层进行升维操作,使得 Gated CNN 块能够在特征空间中进行更灵活的变换,这与传统的 ResNet 中主要使用卷积操作进行特征提取有所不同。
二是跳线增加了非线性激活函数可以被看作一种简单的门控机制,根据输入值调整输出信息量。增加了模型的非线性能力,使得模型能够学习更复杂的特征。
5.代码实现
第 4.1 节更侧重于解释模型设计和架构上的区别,为后续章节的实验结果分析提供背景和依据。
来看代码实现,Gated CNN块通过线性变换、卷积操作和残差连接,实现了对输入特征的扩展、局部特征提取和信息保留。结合了深度卷积网络和残差网络的优点,同时通过门控机制(如激活函数)来控制信息流。

外部结构是个四级堆叠,具体看 Github。重点看这段代码,整体比较简单,因为去掉了 SSM。需要注意的事只对部分通道进行深度卷积,看看是怎么实现的。这里的conv_channels 定义了要进行深度卷积的通道数,conv_ratio 是一个控制参与卷积的通道比例的参数。这意味着卷积操作只在部分通道上进行,而不是所有通道。
四、 实验效果
1、图像分类比较
4.2 汇报了在 ImageNet 上图像分类的比较。太细节实现的我们跳过,可以看原文。着重结果分析,比较了MambaOut,VMamba及其他基于卷积和注意力机制的模型在ImageNet 上的表现如表1所示。
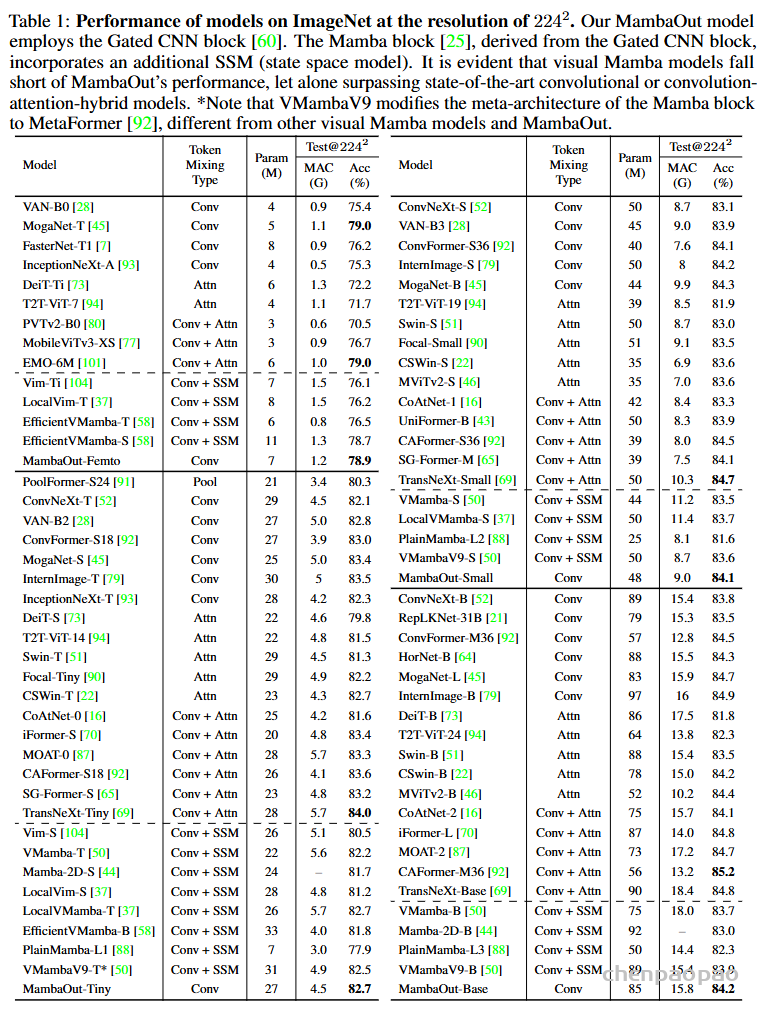
这个表看着很吓人,比较了几十种模型及其变体的性能,但其实结论并不复杂:
1.SSM 有没有对图像分类意义不大,因为时序关系不重要。
2.不如最新的 CAFormer-M36 使用简单的可分离卷积和原始注意力机制,比所有同等大小的视觉 Mamba 模型高出超过1%的准确率85.2%。人家才是纯种的CNNtransformer 啊。
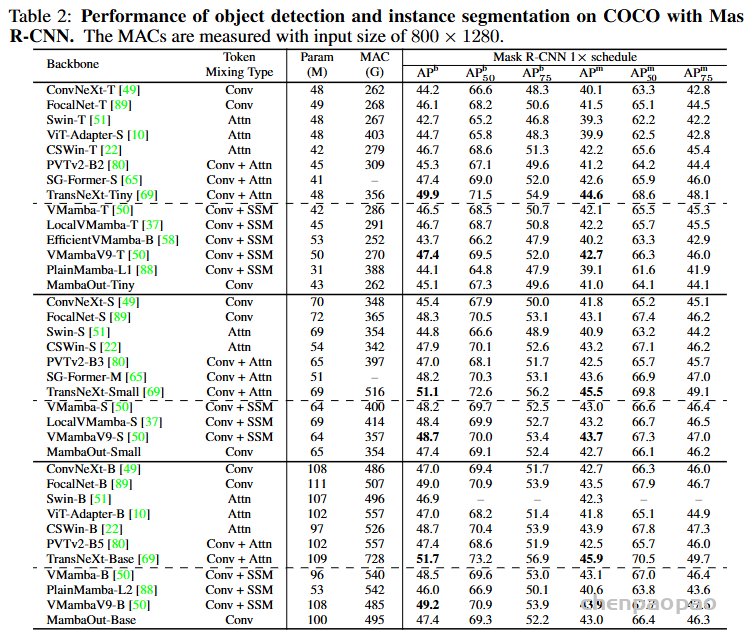
2.目标检测和实例分割
使用标准的 COCO 数据集,Mamba0ut 作为 Mask R-CNN 的主千网络使用,结果尽管 MambaOut 在 COCO 上的目标检测和实例分割任务中可以超越一些视觉 Mamba模型,但它仍然落后于最先进的视觉 Mamba模型,例如 VMamba 和LocalVMamba。这种性能差距强调了在长序列视觉任务中整合 Mamba 的好处。当然,与最先进的卷积-注意力混合模型 TransNeXt相比51.7%%,视觉 Mamba 仍表现出显著的性能差距49.2%。仍然需要努力!这个合理也不合理,两点:
1.Transformer优化了多少年了,Mamba 才多久
2.即使是实例分割问题,所谓的长序列建模,但序列长度并没有 NLP那么长,因此效果有限正常。
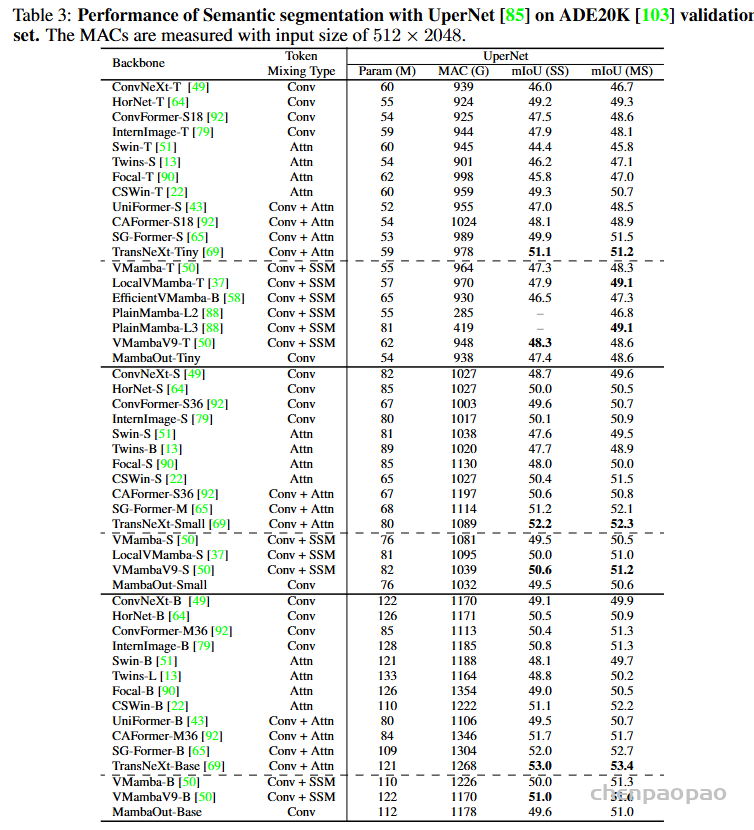
3.语义分割的比较
结论与实例分割类似,SSM 模块在这些任务中的重要性,同时也验证了Mamba0ut在某些情况下的有效性。视觉 Mamba 需要进一步展示其在长序列建模任务中的强大性能,以在语义分割任务中实现更强的性能。
五、小结与探讨:What canlsay!
本文主要的贡献在于:
1.定量分析论证了图像分类任务不是长序列建模问题,而目标检测和实例分割是。前者不需要 RNN 这种机制,因此MambaOut,后者 OUT不了。
2.借鉴 Mamba的 GatedCNN 结构微调了 ResNet,实现了一种新型全局可见注意力机制下的改进版模型。