
摘自:https://zhuanlan.zhihu.com/p/19744278380
Github: https://github.com/deepseek-ai/DeepSeek-R1

R1训练流程:
•冷启动 •基于推理的强化学习 •Rejection Sampling •SFT •全场景强化学习
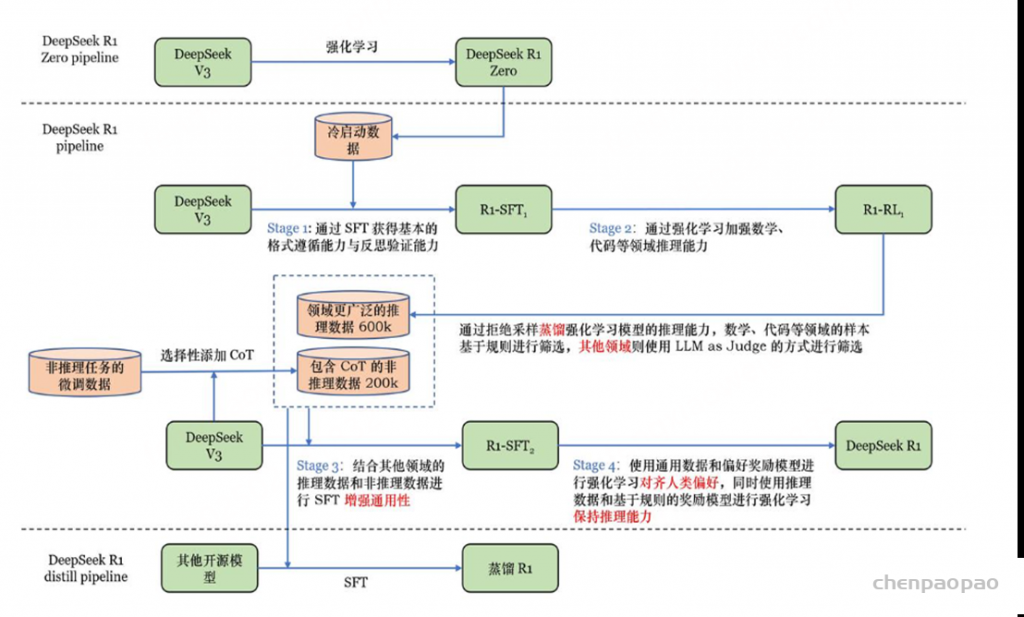
DeepSeek-R1-Zero 采用大规模强化学习(RL)进行训练,无需预先进行监督微调(SFT),表现出显著的推理能力。在强化学习过程中,DeepSeek-R1-Zero 展现出多种卓越且新颖的推理特性。但该模型仍面临可读性不足、语言混杂等问题。
为解决这些问题并进一步增强推理性能,研究团队开发了 DeepSeek-R1,该模型在进行强化学习前引入了多阶段训练和冷启动数据。
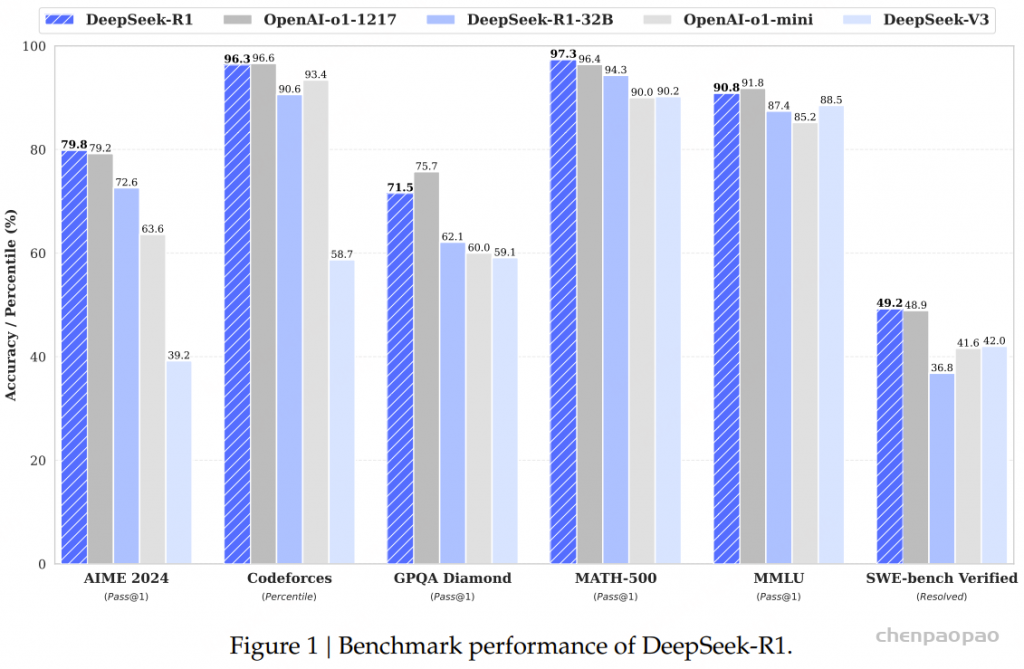
DeepSeek-R1 在推理任务上实现了与 OpenAI-o1-1217 相当的性能水平。
为促进学术研究发展,研究团队开源了 DeepSeek-R1-Zero、DeepSeek-R1,以及基于 Qwen 和 Llama 架构从 DeepSeek-R1 知识蒸馏获得的六个稠密模型(1.5B、7B、8B、14B、32B、70B)。
引言
近年来,LLM技术发展迅速,不断缩小与AGI的差距。后训练技术已成为完整训练流程中的关键环节,证实能够提升推理任务准确率,实现社会价值观对齐,适应用户偏好,同时相较于预训练所需计算资源较少。在推理能力方面,OpenAI的o1系列模型首次通过延长Chain-of-Thought(CoT)推理过程引入了推理时扩展机制,在数学、编程和科学推理等多个推理任务中取得显著进展。
然而,如何实现有效的测试时扩展仍是学术界面临的重要课题。前期研究探索了多种方法,包括过程型奖励模型、强化学习以及蒙特卡洛树搜索和束搜索等算法。但这些方法均未能达到与OpenAI的o1系列模型相当的通用推理水平。
本研究采用纯RL方法提升语言模型的推理能力。研究旨在探索LLM在无监督数据条件下通过纯RL过程实现自我进化的推理能力潜力。
具体而言,研究选用DeepSeek-V3-Base作为基础模型,采用群组相对策略优化(GRPO)作为RL框架提升模型推理性能。在训练过程中,DeepSeek-R1-Zero自然形成了多种高效且创新的推理特征。经过数千轮RL迭代,DeepSeek-R1-Zero在推理基准测试中展现出优异性能。例如,在AIME 2024测试中,pass@1得分从15.6%提升至71.0%,采用majority voting机制后,得分进一步提高到86.7%,达到OpenAI-o1-0912的性能水平。
然而,DeepSeek-R1-Zero仍面临可读性不足、语言混杂等挑战。
为解决这些问题并进一步提升推理性能,研究团队开发了DeepSeek-R1模型,该模型整合了初始训练数据和多阶段训练流程。具体实施步骤包括:首先收集数千条初始训练数据用于DeepSeek-V3-Base模型的微调;随后进行推理强化学习训练;在RL过程接近收敛时,通过拒绝采样(rejection sampling)方法从RL检查点生成新的SFT数据,并结合DeepSeek-V3在写作、事实QA和自我认知等领域的监督数据重新训练DeepSeek-V3-Base模型;最后,使用新数据完成微调后的检查点进行额外的RL训练,综合考虑各类场景的提示词。
经过上述步骤,最终获得的DeepSeek-R1模型达到了与OpenAI-o1-1217相当的性能水平。
研究进一步探索了从DeepSeek-R1到较小dense模型的知识蒸馏。以Qwen2.5 32B为基础模型,直接从DeepSeek-R1进行知识蒸馏的效果优于直接应用RL训练,表明大型基础模型所发现的推理模式对提升推理能力具有关键作用。研究团队已开源蒸馏后的Qwen和Llama系列模型。
值得注意的是,14B蒸馏模型的性能显著超越了当前最先进的开源模型QwQ-32B-Preview,而32B和70B蒸馏模型则在稠密模型推理基准测试中创造了新的记录。
主要贡献
后训练:基础模型的大规模强化学习应用
- 本研究直接将RL应用于基础模型,无需将SFT作为前置步骤。这种方法使模型能够通过CoT探索复杂问题的解决方案,最终开发出DeepSeek-R1-Zero模型。DeepSeek-R1-Zero具备自我验证、反思和生成长CoT等能力,为学术界提供了重要研究成果。这是首个验证LLM推理能力可纯粹通过RL提升而无需SFT的开放研究,为该领域未来发展奠定基础。
- 研究提出了DeepSeek-R1的开发流程,包含两个RL阶段用于优化推理模式和人类偏好对齐,以及两个SFT阶段用于构建模型的推理和非推理基础能力。该流程将有助于行业开发更高性能的模型。
知识蒸馏:小型模型的性能提升
- 研究表明大型模型的推理模式可通过知识蒸馏迁移至小型模型,其效果优于直接对小型模型进行RL训练。开源的DeepSeek-R1及其API将支持学术界开发更优秀的小型模型。
- 利用DeepSeek-R1生成的推理数据,研究团队对学术界广泛使用的多个稠密模型进行了微调。评估结果显示,经过知识蒸馏的小型dense模型在基准测试中表现优异。DeepSeek-R1-Distill-Qwen-7B在AIME 2024上达到55.5%的性能,超越QwQ-32B-Preview。DeepSeek-R1-Distill-Qwen-32B在AIME 2024、MATH-500和LiveCodeBench上分别达到72.6%、94.3%和57.2%的成绩,显著优于现有开源模型,达到与o1-mini相当的水平。研究团队已向学术界开源基于Qwen2.5和Llama3系列的1.5B、7B、8B、14B、32B和70B蒸馏检查点。
研究方法
概述
传统研究主要依赖大规模监督数据提升模型性能。本研究证实,即使在无需监督微调(SFT)作为初始训练的情况下,通过大规模强化学习(RL)也能显著提升推理能力。此外,引入适量初始训练数据可进一步优化性能。后续章节将介绍:(1)DeepSeek-R1-Zero:直接对基础模型应用RL,无需任何SFT数据;(2)DeepSeek-R1:基于经数千个长CoT样例微调的检查点进行RL训练;(3)将DeepSeek-R1的推理能力通过知识蒸馏迁移至小型稠密模型。
DeepSeek-R1-Zero:基础模型的强化学习应用
前期相关研究表明强化学习在推理任务中具有显著效果。然而,这些研究高度依赖耗时的监督数据采集。本节探索LLM在无监督数据条件下通过纯强化学习实现推理能力自我进化的潜力。研究首先概述强化学习算法,随后展示实验结果,以期为学术界提供研究参考。
强化学习算法
群组相对策略优化(GRPO): 为优化RL训练成本,研究采用GRPO算法,摒弃了通常与策略模型规模相当的评论家模型,转而通过群组评分估计基线。具体而言,对每个问题 q ,GRPO从旧策略 πθold 采样输出组{ o1,o2,…,oG },通过最大化以下目标优化策略模型 πθ :
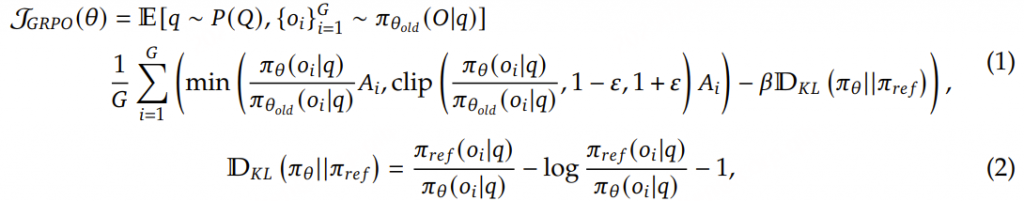
其中 ε 和 β 是超参数, Ai 是优势函数,使用组内每个输出对应的奖励组{ r1,r2,…,rG }计算得到:
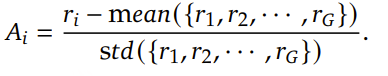
奖励建模
奖励机制作为训练信号来源,决定RL的优化方向。DeepSeek-R1-Zero采用基于规则的双重奖励系统:
- 准确性奖励:评估响应正确性。如对确定性数学问题,要求模型以特定格式(如方框内)提供最终答案,实现基于规则的可靠验证。对LeetCode问题,则通过编译器基于预设测试用例生成反馈。
- 格式奖励:要求模型将推理过程置于指定标签对内。研究未采用结果或过程神经奖励模型,原因在于神经奖励模型可能在大规模RL过程中产生奖励欺骗问题,且重训奖励模型需额外资源,增加训练流程复杂度。
训练模板
DeepSeek-R1-Zero的训练始于简洁指令模板的设计。

如表1所示,模板要求模型首先生成推理过程,随后给出最终答案。研究刻意将约束限定于结构格式,避免引入内容偏见(如强制反思推理或特定问题解决策略),以准确观测模型在RL过程中的自然演化。
DeepSeek-R1-Zero的性能分析、演化过程及关键突破
性能分析 图2记录了DeepSeek-R1-Zero在RL训练过程中AIME 2024基准测试的性能变化轨迹。
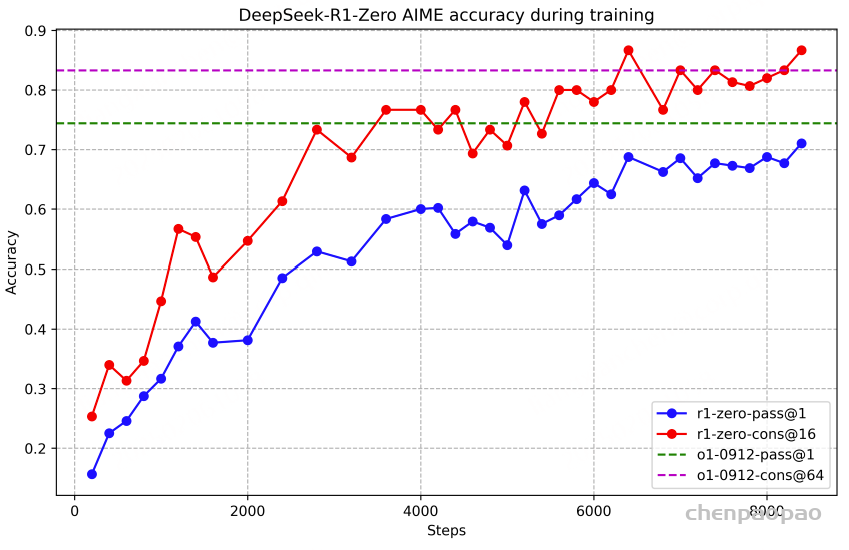
数据显示,随着RL训练的深入,模型性能呈现稳定上升趋势。在AIME 2024测试中,平均pass@1得分从初始的15.6%显著提升至71.0%,达到OpenAI-o1-0912的性能水平,充分证实了RL算法在模型性能优化方面的有效性。
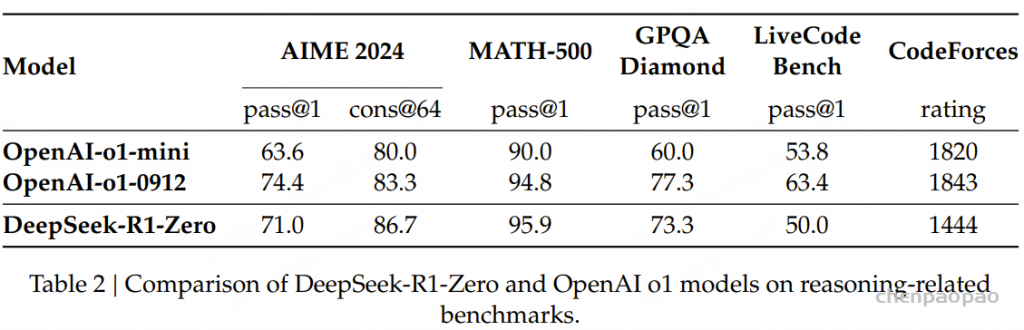
表2详细对比了DeepSeek-R1-Zero与OpenAI o1-0912模型在各类推理基准测试上的表现。结果表明,纯RL训练使DeepSeek-R1-Zero获得了出色的推理能力,无需借助监督微调数据,这证实了模型通过单一RL机制实现有效学习和泛化的能力。通过引入majority voting机制,模型性能得到进一步提升。例如,在AIME基准测试中,采用majority voting后性能从71.0%提升至86.7%,超越OpenAI-o1-0912。这种优异表现凸显了模型的基础能力和推理潜力。
演化过程分析 DeepSeek-R1-Zero的演化过程展示了RL在推理能力自主优化方面的显著效果。通过直接对基础模型实施RL训练,研究得以在无监督微调影响下观测模型进展。
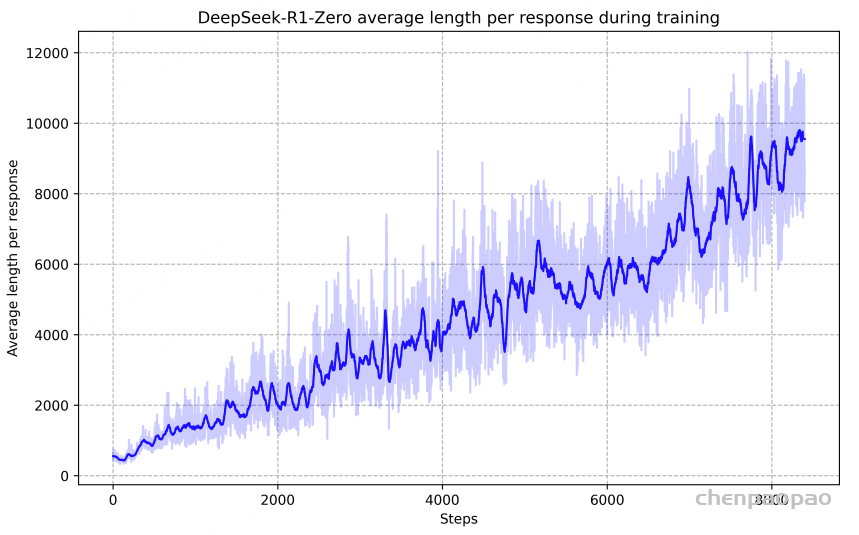
如图3所示,模型的推理时长在训练过程中持续优化,这种进展源于模型的内生发展而非外部干预。DeepSeek-R1-Zero通过扩展测试计算时间,自然形成了解决复杂推理任务的能力。其计算规模从数百到数千个推理token不等,实现了深度的思维探索和优化。随着测试计算时间的延长,模型展现出复杂的行为特征,包括反思机制(重新评估先前推理步骤)和多元问题解决策略的探索。这些行为模式并非预设,而是源于模型与RL环境的交互作用,显著增强了其处理高难度任务的效率和准确性。
关键突破与局限性 研究过程中观察到模型出现重要突破,如表3所示,体现在中期版本中。

此阶段,DeepSeek-R1-Zero习得了重新评估初始方法并延长思考时间的能力。这一进展不仅体现了模型推理能力的提升,也展示了RL在实现复杂学习成果方面的潜力。这种现象验证了RL的核心优势:通过适当的激励机制,促使模型自主发展高级问题解决策略。
然而,DeepSeek-R1-Zero仍存在若干局限性。尽管具备强大的推理能力和创新的推理行为,但在可读性和语言一致性方面仍面临挑战。为提高推理过程的可读性并促进开放社区交流,研究团队开发了DeepSeek-R1模型,该模型结合了RL和用户友好的初始训练数据。
DeepSeek-R1:基于冷启动的强化学习方法
基于DeepSeek-R1-Zero的成功实践,研究聚焦两个核心问题:
- 通过引入少量高质量数据作为冷启动,是否能够进一步提升推理性能或加速收敛?
- 如何开发既能生成清晰连贯的CoT,又具备强大通用能力的用户友好型模型?
为解决上述问题,研究团队设计了四阶段训练流程。
冷启动机制
区别于DeepSeek-R1-Zero,DeepSeek-R1采用少量长CoT数据对模型进行预微调,作为初始RL策略网络,以避免基础模型RL训练早期的不稳定性。数据收集采用多种方法:
- 基于长CoT示例的少样本提示
- 直接提示生成包含反思验证的详细答案
- 整理DeepSeek-R1-Zero的规范化输出
- 人工标注后处理优化
研究收集数千条冷启动数据用于DeepSeek-V3-Base的预训练。相较于DeepSeek-R1-Zero,冷启动数据具有以下优势:
- 可读性增强:克服了DeepSeek-R1-Zero输出内容可读性差的局限。通过设计标准化输出模式,包括响应末尾的总结性内容,并筛除不符合阅读友好性要求的输出。输出采用|special_token|<reasoning_process>|special_token|<summary>格式,包含查询的推理过程和结果摘要。
- 性能提升:基于人类认知模式优化的冷启动数据设计,展现出优于DeepSeek-R1-Zero的性能表现,验证了迭代训练对推理模型的优越性。
推理强化学习优化
完成冷启动数据预训练后,采用与DeepSeek-R1-Zero类似的大规模RL训练流程,重点提升模型在编码、数学、科学和逻辑等明确定义问题域的推理能力。在训练过程中发现Chain-of-Thought存在语言混杂现象,尤其是多语言提示场景下。为此引入语言一致性奖励机制,基于目标语言词占比计算。尽管消融实验显示该机制略微影响模型性能,但提升了人类使用体验。最终将任务准确率和语言一致性奖励合并计算总体奖励,持续RL训练直至模型在推理任务上收敛。
拒绝采样与监督微调
推理RL收敛后,利用检查点生成后续SFT数据。不同于专注推理的冷启动阶段,此阶段整合多领域数据以增强模型的写作、角色扮演等通用能力。具体实施如下:
推理数据构建 通过对RL训练检查点执行拒绝采样生成推理轨迹。扩展了评估机制,除规则型奖励外,引入基于DeepSeek-V3判断的生成式奖励模型。优化输出质量,过滤混杂语言、冗长段落和代码块。对每个提示词进行多样本采样,保留正确结果。最终获得约60万条推理训练样本。
非推理数据整合 在写作、事实QA、自我认知和翻译等领域,采用DeepSeek-V3流程和部分SFT数据。对复杂非推理任务,通过提示DeepSeek-V3生成前置CoT;对简单查询则直接响应。累计获取约20万条非推理训练样本。使用总计约80万样本数据对DeepSeek-V3-Base执行两轮微调。
全场景强化学习
为优化人类偏好对齐,实施第二阶段RL训练,着重提升模型实用性、安全性和推理能力。采用多元奖励信号和多样化提示分布:
- 推理数据:延续DeepSeek-R1-Zero方法,在数理逻辑领域应用规则型奖励
- 通用数据:采用奖励模型捕捉复杂场景下的人类偏好
- 实用性评估:专注于响应摘要,确保输出的实用性和相关性
- 安全性保障:全面评估推理过程和摘要,识别并降低潜在风险
通过奖励信号和数据分布的系统整合,实现了推理能力和用户体验的均衡发展。
知识蒸馏:增强小型模型的推理能力
本研究采用DeepSeek-R1生成的80万训练样本,对Qwen和Llama等开源模型进行直接SFT微调,旨在将DeekSeek-R1的推理能力迁移至计算效率更高的小型模型。
实验结果表明,这种直接知识蒸馏方法能显著提升小型模型的推理性能。
研究选用的基础模型包括:Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B和Llama-3.3-70B-Instruct
选择Llama-3.3的原因在于其推理能力较Llama-3.1略有优势。
蒸馏过程中仅采用SFT,未纳入RL阶段,尽管引入RL可能带来显著的性能提升。研究重点在于验证知识蒸馏技术的有效性,为后续学术界对RL优化的深入研究奠定基础。
实验设计与评估
研究采用多维度基准测试体系评估模型性能:
标准评估基准 8类16个评估标准如下所示:
- 知识理解类:MMLU、MMLU-Redux、MMLU-Pro
- 跨语言评估:C-Eval、CMMLU
- 格式理解:IFEval
- 长文本处理:FRAMES
- 专业知识:GPQA Diamond
- 事实问答:SimpleQA、C-SimpleQA
- 编程能力评估: SWE-Bench Verified、Aider、LiveCodeBench、Codeforces
- 数学能力测试: CNMO 2024、AIME 2024
除标准基准测试外,研究还使用LLM作为评估器评估模型在开放式生成任务上的表现。具体而言,遵循AlpacaEval 2.0和Arena-Hard的原始配置,使用GPT-4-Turbo-1106作为成对比较的评估器。评估时仅输入最终摘要以避免长度偏差。对于蒸馏模型,报告其在AIME 2024、MATH-500、GPQA Diamond、Codeforces和LiveCodeBench上的代表性结果。
评估用prompt 不同的评估标准采用不同的prompt,具体如下所示:
- 基础评估:采用simple evals框架标准prompt评估MMLU、DROP、GPQA Diamond和SimpleQA
- 特殊处理: MMLU-Redux采用Zero-Eval prompt格式实现零样本评估,MMLU-Pro、C-Eval、CLUE-WSC将原少样本prompt改造为零样本形式
- 编程评估: HumanEval-Mul覆盖8种主流编程语言,LiveCodeBench采用CoT格式,Codeforces基于10个Div.2竞赛题目与专家测试用例,SWE-Bench通过无代理框架验证
值得注意的是,DeepSeek-R1的输出在每个基准测试上限制为最多32,768个token。
基准模型 研究与多个强基准模型进行全面对比,包括DeepSeek-V3、Claude-Sonnet-3.5-1022、GPT-4o-0513、OpenAI-o1-mini和OpenAI-o1-1217。鉴于在中国大陆访问OpenAI-o1-1217 API的限制,其性能数据来源于官方报告。对于蒸馏模型,额外与开源模型QwQ-32B-Preview进行比较。
生成配置 所有模型的最大生成长度设置为32K token。对需要采样的基准测试,采用0.6的temperature参数、0.95的top-p值,并为每个查询生成64个响应以估算pass@1。
DeepSeek-R1评估结果
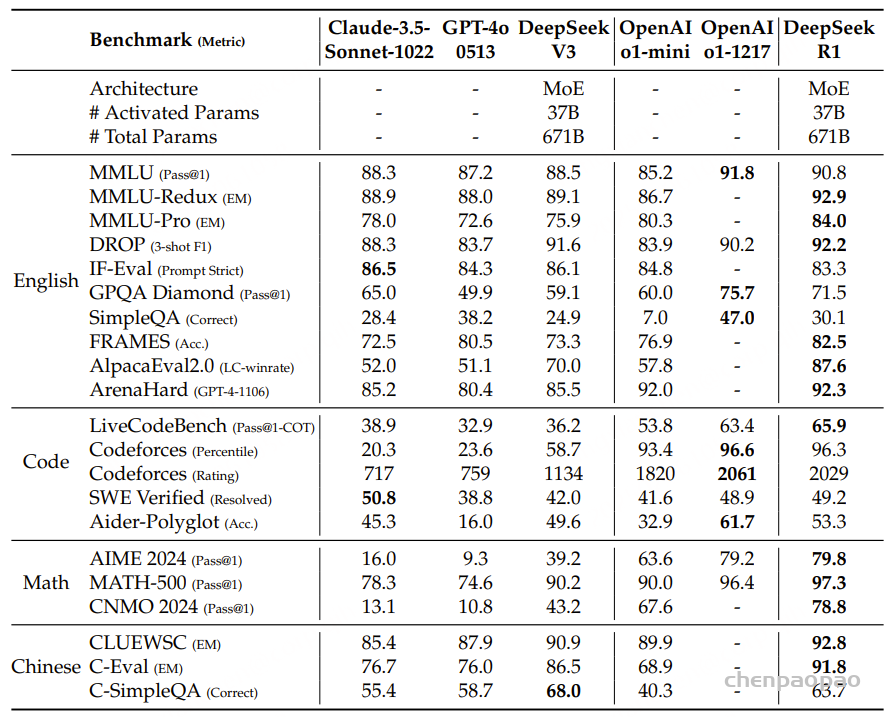
在面向教育的知识基准测试(如MMLU、MMLU-Pro和GPQA Diamond)中,DeepSeek-R1相较于DeepSeek-V3展现出优越性能。这一进步主要归因于STEM相关问题准确率的提升,这得益于大规模RL带来的显著进步。
此外,DeepSeek-R1在依赖长文本理解的问答任务FRAMES上表现卓越,展示了其强大的文档分析能力。这凸显了推理模型在AI驱动的搜索和数据分析任务中的潜力。
在事实性基准测试SimpleQA上,DeepSeek-R1的表现优于DeepSeek-V3,证明了其处理基于事实查询的能力。类似地,在该基准测试中也观察到OpenAI-o1超越GPT-4o的趋势。
然而,DeepSeek-R1在中文SimpleQA基准测试中的表现不如DeepSeek-V3,主要是由于安全性RL后倾向于拒绝回答某些查询。若不考虑安全性RL,DeepSeek-R1可以达到超过70%的准确率。
DeepSeek-R1在IF-Eval(一个用于评估模型遵循格式指令能力的基准测试)上也取得了令人瞩目的成果。这些改进可归因于在最终阶段的SFT和RL训练中引入了指令遵循数据。
此外,在AlpacaEval 2.0和ArenaHard上的出色表现表明DeepSeek-R1在写作任务和开放域问答方面具有优势。其显著优于DeepSeek-V3的表现凸显了大规模RL的泛化效益,不仅提升了推理能力,还改善了各个领域的性能。
而且DeepSeek-R1生成的摘要长度简洁,在ArenaHard上平均为689个token,在AlpacaEval 2.0上平均为2,218个字符。这表明DeepSeek-R1在基于GPT的评估中避免了引入长度偏差,进一步证实了其在多任务场景下的稳健性。
在数学任务上,DeepSeek-R1展现出与OpenAI-o1-1217相当的性能,大幅超越其他模型。在LiveCodeBench和Codeforces等编码算法任务上也观察到类似趋势,其中注重推理的模型在这些基准测试中占据主导地位。
在面向工程的编码任务上,OpenAI-o1-1217在Aider上优于DeepSeek-R1,但在SWE Verified上表现相当。考虑到目前相关RL训练数据量仍然非常有限,研究团队认为DeepSeek-R1的工程性能将在下一版本中得到改善。
蒸馏模型评估
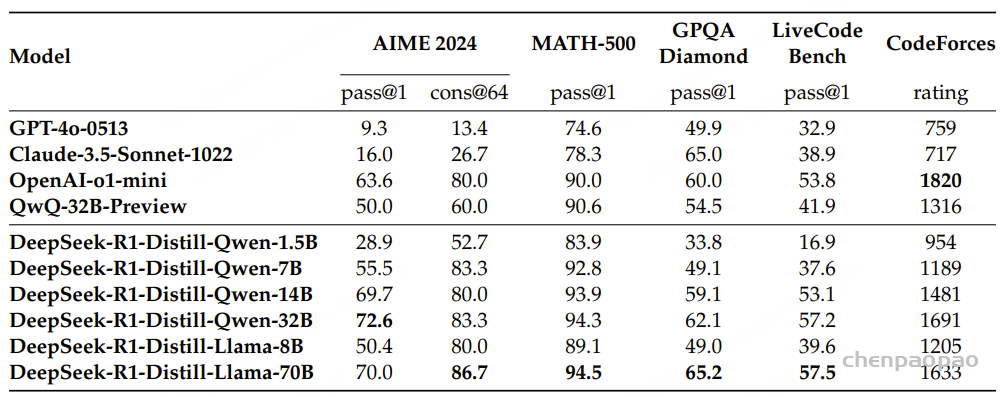
如表5所示,仅通过蒸馏DeepSeek-R1的输出,高效的DeepSeek-R1-7B(即DeepSeek-R1-Distill-Qwen-7B,以下类似缩写)就能在各方面超越GPT-4o-0513等非推理模型。
DeepSeek-R1-14B在所有评估指标上超越QwQ-32B-Preview,而DeepSeek-R1-32B和DeepSeek-R1-70B在大多数基准测试中显著超越o1-mini。这些结果展示了知识蒸馏的巨大潜力。
此外,研究发现对这些蒸馏模型应用RL能带来显著的进一步提升。考虑到这值得进一步探索,此处仅呈现简单SFT蒸馏模型的结果。
讨论
蒸馏与强化学习对比
通过蒸馏DeepSeek-R1,小型模型能够取得出色的结果。然而,仍有一个问题待解答:
模型是否可以通过本文讨论的大规模RL训练而不依赖蒸馏来达到相当的性能?
为回答这个问题,研究团队对Qwen-32B-Base使用数学、代码和STEM数据进行了超过10K步的大规模RL训练,得到DeepSeek-R1-Zero-Qwen-32B。
如表6所示的实验结果表明,32B基础模型经过大规模RL训练后,达到了与QwQ-32B-Preview相当的性能。然而,从DeepSeek-R1蒸馏得到的DeepSeek-R1-Distill-Qwen-32B在所有基准测试中的表现都显著优于DeepSeek-R1-Zero-Qwen-32B。
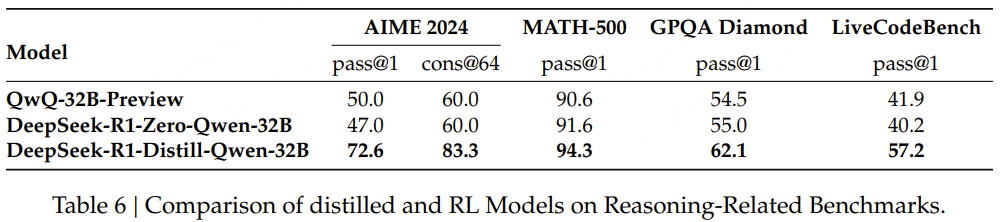
因此,可以得出两个结论:
首先,将更强大的模型蒸馏到较小的模型中可以产生优异的结果,而较小的模型依靠本文提到的大规模RL需要巨大的计算力,甚至可能无法达到蒸馏的性能水平。
其次,虽然蒸馏策略既经济又有效,但要突破智能的边界可能仍需要更强大的基础模型和更大规模的强化学习。
未成功的尝试
在开发DeepSeek-R1的早期阶段,研究也遇到了失败和挫折。在此分享这些失败经验以提供见解,但这并不意味着这些方法无法开发出有效的推理模型。
过程奖励模型(PRM)
PRM是一种合理的方法,可以引导模型采用更好的方法解决推理任务。然而,在实践中,PRM有三个主要限制可能阻碍其最终成功。
首先,在一般推理中明确定义细粒度步骤具有挑战性。其次,确定当前中间步骤是否正确是一项具有挑战性的任务。使用模型的自动标注可能无法产生令人满意的结果,而手动标注不利于规模化。第三,一旦引入基于模型的PRM,必然导致奖励欺骗,重新训练奖励模型需要额外的训练资源,并使整个训练流程变得复杂。
总之,虽然PRM在对模型生成的前N个响应重新排序或辅助引导搜索方面表现良好,但在实验中,相比其在大规模强化学习过程中引入的额外计算开销,其优势有限。
蒙特卡洛树搜索(MCTS)
受AlphaGo和AlphaZero的启发,研究探索使用MCTS来增强测试时计算的可扩展性。这种方法包括将答案分解为更小的部分,使模型能够系统地探索解决方案空间。为此,提示模型生成多个标签,对应搜索所需的具体推理步骤。在训练方面,首先使用收集的提示通过预训练值模型引导的MCTS寻找答案。随后,使用产生的问答对来训练actor模型和值模型,不断改进过程。
然而,这种方法在扩大训练规模时遇到几个挑战。首先,与搜索空间相对明确的象棋不同,token生成呈现指数级更大的搜索空间。为解决这个问题,为每个节点设置最大扩展限制,但这可能导致模型陷入局部最优。其次,值模型直接影响生成质量,因为它指导搜索过程的每个步骤。训练细粒度值模型本质上是困难的,这使得模型难以迭代改进。虽然AlphaGo的核心成功依赖于训练值模型来逐步提升性能,但由于token生成的复杂性,这一原则在团队的设置中难以复制。
总之,虽然MCTS在与预训练值模型配对时可以改善推理性能,但通过自搜索迭代提升模型性能仍然是一个重大挑战。
结论、局限性和未来工作
本文分享了通过RL增强模型推理能力的探索历程。DeepSeek-R1-Zero代表了一种不依赖冷启动数据的纯RL方法,在各种任务中取得了出色的表现。DeepSeek-R1通过结合冷启动数据和迭代RL微调展现出更强的性能,最终在多个任务上达到与OpenAI-o1-1217相当的水平。
研究进一步探索了将推理能力蒸馏到小型稠密模型的可能性。以DeepSeek-R1作为教师模型生成80万条数据,并对多个小型稠密模型进行微调。
结果令人鼓舞:DeepSeek-R1-Distill-Qwen-1.5B在数学基准测试中超越GPT-4o和Claude-3.5-Sonnet,在AIME上达到28.9%,在MATH上达到83.9%的成绩。其他稠密模型也取得了显著成果,大幅超越基于相同基础检查点的其他指令微调模型。
未来,计划在以下方向继续推进DeepSeek-R1的研究:
- 通用能力:目前DeepSeek-R1在函数调用、多轮对话、复杂角色扮演和json输出等任务上的能力仍不及DeepSeek-V3。后续研究将探索如何利用长CoT增强这些领域的任务表现。
- 语言混杂:DeepSeek-R1当前针对中文和英文进行了优化,在处理其他语言的查询时可能出现语言混杂问题。例如,即使查询使用非英文或中文的语言,DeepSeek-R1可能使用英语进行推理和响应。未来更新将着力解决这一限制。
- 提示词工程:在评估DeepSeek-R1时发现,模型对prompt较为敏感。少样本提示会持续降低其性能。因此,建议用户直接描述问题并使用零样本设置指定输出格式以获得最佳结果。
- 软件工程任务:由于评估时间较长影响RL过程效率,大规模RL尚未在软件工程任务中广泛应用。因此,DeepSeek-R1在软件工程基准测试上相比DeepSeek-V3未显示出显著改进。未来版本将通过对软件工程数据实施拒绝采样或在RL过程中引入异步评估来提高效率。