论文题目:Sequence-to-Sequence Neural Diarization with Automatic Speaker Detection and Representation
论文:https://arxiv.org/abs/2411.13849
摘自:https://mp.weixin.qq.com/s/s1JuYq5S2v2bfGnXPE0Qnw
研究动机
“谁在什么时候说话”是多说话人语音理解中的核心任务。然而,传统的说话人日志系统普遍依赖从完整音频提取说话人嵌入、聚类匹配或端到端建模等方法,往往只能离线运行,难以适应实时对话、会议转写等对系统延迟要求极高的实际场景。
为突破这些限制,武汉大学与昆山杜克大学研究团队提出了全新框架—— S2SND(Sequence-to-Sequence Neural Diarization,序列到序列的神经日志)。该方法基于序列到序列架构,创新性地融合了“说话人自动检测”与“嵌入动态提取”机制,无需聚类与先验的说话人嵌入,即可以在线推理的形式逐个识别新加入的未知说话人,并同步完成语音活动检测与说话人表示建模。
S2SND 无需聚类或排列不变训练(PIT),并具备统一支持在线推理与离线重解码等特性,在多个评估数据集的多种评测条件下均取得了领先性能,相关成果已发表于语音领域权威期刊 IEEE Transactions on Audio, Speech and Language Processing。
方法介绍
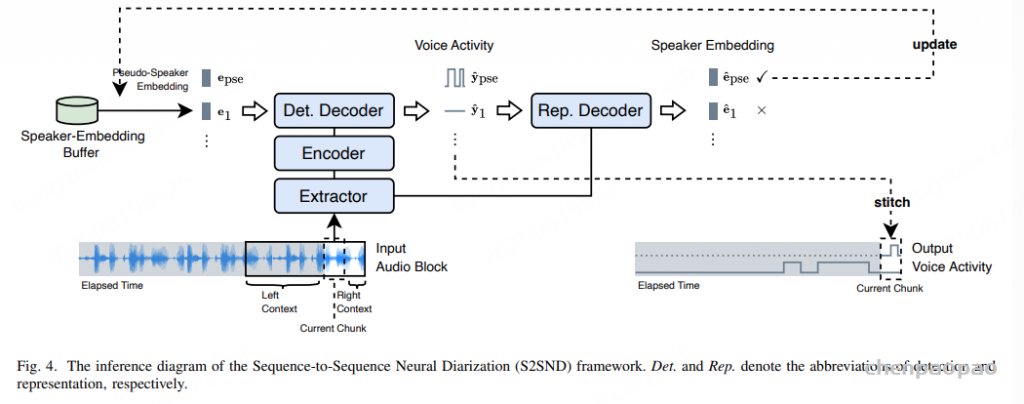
如图1所示,S2SND 框架采用序列到序列架构,主要包含三部分模块:基于ResNet-34的特征提取器(Extractor),基于Conformer的编码器(Encoder),和创新性设计的检测解码器(Detection Decoder)和表征解码器(Representation Decoder)两个部分,实现了说话人检测与嵌入提取的双向协同。首先,输入音频经过 ResNet 结构的帧级提取器生成时序说话人特征序列。随后送入基于 Conformer 架构的编码器建模长时依赖关系,输出作为下游解码器的主特征输入。在解码阶段,模型并行使用两个功能互补的解码器:检测解码器利用编码器的输出特征与目标说话人声纹嵌入作为参考信息,预测多个说话人的语音活动。反之,表征解码器则利用提取器的输出特征与目标说话人语音活动作为参考信息,提取多个说话人的声纹嵌入。
为了打通两条路径的协同优化,S2SND 引入一个可学习的全体说话人嵌入矩阵(Embedding Matrix),每一个行向量对应训练集中一个说话人的声纹嵌入。训练时,语音活动标签由标注数据提供,而目标说话人嵌入通过该矩阵查表获得(one-hot 标签与嵌入矩阵相乘),作为检测解码器的辅助查询;同时,该矩阵也作为表征解码器的监督目标,用于对其预测出的嵌入执行 ArcFace Loss监督。检测解码器输入的声纹嵌入和表征解码器输出的声纹嵌入为同个特征空间内联合优化所得。
为增强模型对新说话人的检测能力,训练中采用Masked Speaker Prediction机制:每个训练样本中会随机屏蔽一个已知说话人嵌入,使用一个可学习的“伪说话人嵌入”代替,并将其语音活动标签对应输出位置,促使模型学会发现“未注册说话人”的语音。另一方面,S2SND设计了Target-Voice Embedding Extraction机制:利用表征解码器从从多说话人混合音频中反向提取嵌入,实现检测与表征的闭环优化。整个框架端到端训练,联合优化语音活动预测的 BCE 损失与嵌入空间的 ArcFace 损失。

图1. 序列到序列神经说话人日志(S2SND)框架示意图。其中,Det. 和 Rep. 分别表示检测(Detection)与表征(Representation)的缩写。
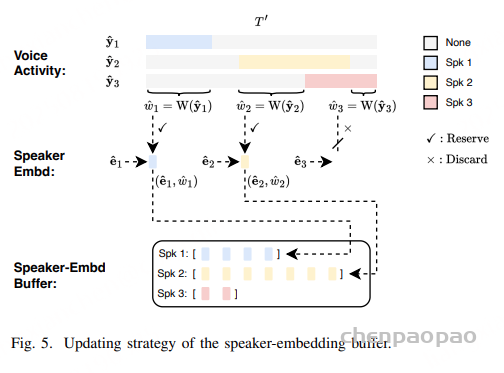
如图2所示,S2SND 支持低延迟的在线推理,采用块式(Blockwise)输入方式处理长音频。每次输入一个音频块,包含三部分:左上下文、当前块与右上下文,分别用于建模历史依赖、输出当前结果与提供未来参考。整个音频以滑动窗口方式逐块推进,当前块的结果实时输出,保证因果性。推理过程中,系统维护一个说话人嵌入缓冲区(Speaker-Embedding Buffer),用于存储当前已知说话人的嵌入表示。每一轮推理的输入说话人嵌入由三部分拼接组成:
- 固定在首位的训练过程中使用的伪说话人嵌入,用于检测是否有新说话人出现;
- 从缓冲区按顺序读取的已知说话人嵌入,用作特定人身份的参考信息;
- 用训练过程中使用的非语音嵌入作为填充,确保一个数据批次(Batch)的说话人数维度一致。
检测解码器以当前编码特征与上述嵌入序列为输入,预测每个说话人的语音活动(包括伪说话人);随后,表征解码器再以提取器特征与预测的语音活动作为输入,反向提取所有目标说话人的嵌入表示。模型通过评估每个预测出的语音活动的非重叠语音时长作为嵌入质量权重,对应生成的嵌入只有在超过设定阈值时才会写入缓冲区:
- 若伪说话人的语音活动质量满足阈值,说明存在新的未注册说话人,其嵌入将以新身份编号写入缓冲区;
- 若已有说话人的语音活动质量满足阈值,则对应嵌入将追加到该说话人的缓冲列表;
- 低质量嵌入则被舍弃,以避免污染已缓存的嵌入。
每次推理仅采用当前块对应的时间范围内的预测结果拼接到历史结果,确保输出的时间因果性。此外,当整个音频推理完成后,系统可利用缓冲区中聚集的高质量说话人嵌入,对全段音频进行一次离线重解码(Re-Decoding),进一步提升整体识别精度。由于模型结构在在线与离线模式下完全一致,无需额外转换或重新建模。
Det. 和 Rep. 分别表示检测(Detection)与表征(Representation)的缩写。
流式推理伪代码:
Algorithm 1 Pseudocode of online inference in the Python-like style.
"""
- Extractor(), Encoder(), Det_Decoder(), Rep_Decoder(): neural network modules in S2SND models
- W(): calculating embedding weight
Inputs
- blocks: a sequence of input audio blocks
- e_pse/e_non: pseudo-speaker/non-speech embedding
- tau_1/tau_2: threshold for pseudo-speaker/enrolled-speaker embedding weight
- lc/lr: number of output VAD frames belonging to the current chunk / right context
- N: speaker capacity
- S: embedding dimension
Outputs
- dia_result: predicted target-speaker voice activities
- emb_buffer: extracted speaker embeddings
"""
dia_result = {} # 初始化分离结果:字典,key=spk_id,value=拼接好的VAD帧序列
emb_buffer = {} # 初始化“说话人嵌入缓冲区”:key=spk_id, value=[(embedding, weight), ...]
num_frames = 0 # 已经输出(拼接)的VAD帧计数,用于新出现的说话人补零对齐
for audio_block in blocks: # 块式滑窗读取下一段音频(含左/当前/右三部分)
# 流式:逐块处理,保持低延迟与因果性。
emb_list = [e_pse] # 输入给解码器的“说话人嵌入序列”首位固定放伪说话人嵌入
spk_list = [len(emb_buffer) + 1] # 并为它占一个新ID(“潜在新说话人”的候选ID)
# 伪说话人(pseudo-speaker):用于探测是否有新说话人。
# spk_list[0] 提前预留一个“新ID”,如果这次块里真的检测到新说话人且质量达阈值,就用这个 ID。
# 将每个“已知说话人”的汇总参考嵌入拼到 emb_list,与 spk_list 一一对应。这样解码器就能对“伪说话人 + 已知说话人们”同时进行语音活动预测。
for spk_id in emb_buffer.keys(): # 遍历已知/已注册的说话人
e_sum = torch.zeros(S) # 为该说话人累积权重和
w_sum = 0
for e_i, w_i in emb_buffer[spk_id]:
e_sum += w_i * e_i # 质量加权的嵌入加和
w_sum += w_i
emb_list.append(e_sum / w_sum) # 得到该说话人的“参考嵌入”(加权平均)
spk_list.append(spk_id) # 记录其对应的说话人ID(顺序与emb_list对应)
# 确保这次前向中,说话人维(batch)长度固定为 N,便于张量化与并行。
while len(emb_list) < N: # 若说话人槽位不够,用非语音嵌入 e_non 填满(batch 维度对齐)
emb_list.append(e_non)
emb_tensor = torch.stack(emb_list) # 形状:N x S
# 提取器/编码器是声学前端,抽取时序表示。
X = Extractor(audio_block) # 提取器:原波形 -> 帧级特征,形状 T x F
X_hat = Encoder(X) # 编码器:进一步编码,形状 T x D
# Y_hat[n]:第 n 个槽位(伪/已知/填充)的语音活动(帧级概率/0-1)。
#E_hat[n]:第 n 个槽位对应的说话人嵌入。
#两者联动:先“检测哪里在说话”,再“在这些区域提代表征”。
Y_hat = Det_Decoder(X_hat, emb_tensor) # 检测解码器:对每个“说话人槽位”预测VAD,形状 N x T'
E_hat = Rep_Decoder(X, Y_hat) # 表征解码器:反向提取每个槽位的嵌入,形状 N x S
y_pse = Y_hat[0] # 伪说话人的 VAD(T')
e_pse = E_hat[0] # 伪说话人的嵌入(S)
w_pse = W(y_pse) # 基于非重叠语音时长等指标计算质量权重(标量)
# 关键点:只拼当前块对应的 lc 帧,保证因果输出;右上下文只作参考不输出。
# 新说话人第一次出现,需要在历史时间线前边补零对齐
if w_pse > tau_1: # 若伪说话人质量过阈,判定:出现新说话人
elapsed_y = torch.zeros(num_frames) # 为新ID补齐历史帧的0(过去都未说话)
current_y = y_pse[-(lc+lr) : -lr] # 只取当前块的有效帧(去掉右上下文)
new_id = spk_list[0] # 取预留的新说话人ID
dia_result[new_id] = torch.cat([elapsed_y, current_y]) # 拼成全局时间线
emb_buffer[new_id] = [(e_pse, w_pse)] # 把该新人的嵌入写入缓冲区
# 更正:循环上界不应是 len(S)(那是嵌入维),应该是 N 或 Y_hat.size(0)。
#已知说话人的 dia_result[spk_id] 直接在已有时间线上拼接本块的 lc 帧。
#当质量好时,往该说话人的 emb_buffer 追加一条 (embedding, weight),后续会参与加权平均,越滚越稳。
for n in range(1, len(S)): # 【这里有 Bug】应为 range(1, N) 或 Y_hat.shape[0]
y_n = Y_hat[n] # 第 n 槽位的 VAD
e_n = E_hat[n] # 第 n 槽位的嵌入
w_n = W(y_n) # 质量
spk_id = spk_list[n] # 槽位对应的说话人 ID(已知)
dia_result[spk_id] = torch.cat([dia_result[spk_id], y_n[-(lc+lr) : -lr]]) # 拼接本块有效帧
if w_n > tau_2: # 若质量好,把新嵌入追加到该说话人的缓冲列表
emb_buffer[spk_id].append((e_n, w_n))
num_frames += lc # 全局时间线向前推进 lc 帧
#每处理完一个块,就“确认输出”了 lc 帧,时间线前移。实验结果与性能分析
本研究构建了两类模型规模的 S2SND 系统:S2SND-Small 和 S2SND-Medium,最终模型参数量分别约为16+M和 46M+。为支撑大规模训练,我们分别采用了两个不同规模的说话人语料作为仿真素材。其中,VoxCeleb2数据库约 100 万条语音,覆盖 6112 名说话人;VoxBlink2数据库约 1000 万条语音,覆盖超过 11 万名说话人。此外,为提升中型模型对大语料的建模能力,本研究引入了以 ResNet-152 提取器作为教师模型的知识蒸馏策略,显著增强了说话人嵌入质量与下游推理性能。模型结构、训练细节与延迟设置等信息详见论文原文。所有实验均基于标准的 DER(Diarization Error Rate) 指标进行评估,不使用 Collar ,严格衡量系统在真实应用条件下的实际表现。同时,分别评测依赖和不依赖 Oracle VAD的情况,以满足和其他现有方法在不同评估标准下的公平对比。
如表1所示,在 DIHARD-II 测试集中,S2SND-Medium 模型结合 VoxBlink2 语料与知识蒸馏训练,在在线推理模式(0.64s 总延迟)下取得了 24.41% DER,刷新当前所有在线系统的最优结果。完成一次离线重解码后,DER 进一步降低至 21.95%,即便不依赖 Oracle VAD,也全面超越现有最强的 EEND-GLA 与 VBx 等方法。相比之下,传统 EEND-EDA + STB 方法的在线DER 仍在 30% 以上,EEND-GLA-Large 系统也仅在离线条件下达到 28.33%。S2SND 实现了更低延迟、更高准确率的双重突破。
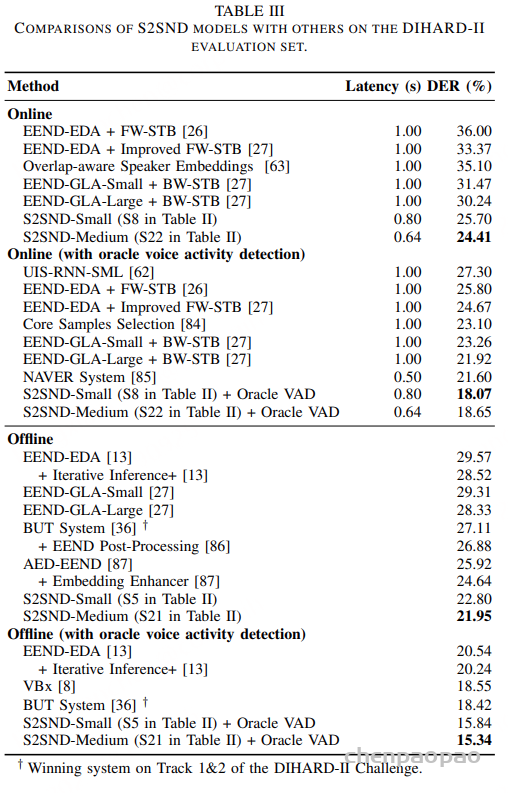
如表2所示,在更新一代的 DIHARD-III 数据集上,S2SND 同样表现出色。在 0.80s 延迟设置下的在线模式,S2SND-Medium 达到 17.12% DER,明显优于各类在线系统。完成离线重解码后,DER 进一步降至 15.13%。值得一提的是,S2SND 的在线 DER 已逼近甚至优于许多离线系统(如 EEND-M2F 的 16.07%),体现出其在新说话人检测与时序建模方面的强大泛化能力。
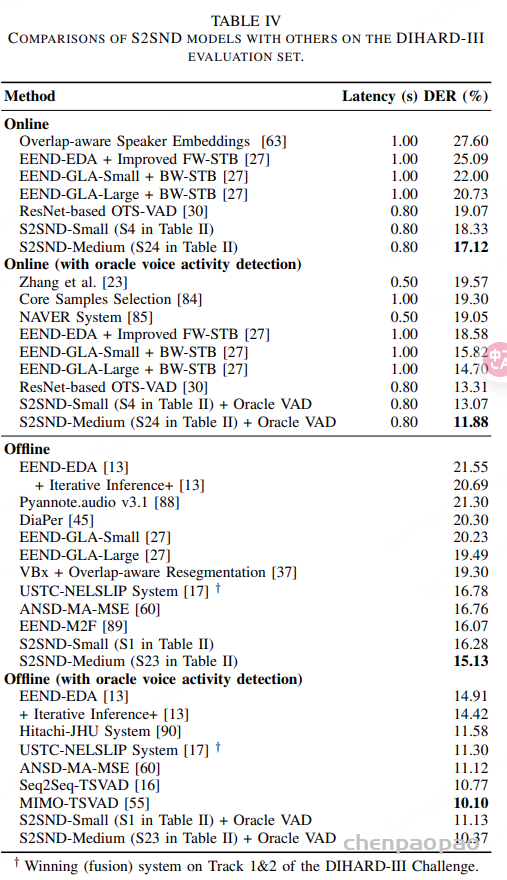
如表2所示,在更新一代的 DIHARD-III 数据集上,S2SND 同样表现出色。在 0.80s 延迟设置下的在线模式,S2SND-Medium 达到 17.12% DER,明显优于各类在线系统。完成离线重解码后,DER 进一步降至 15.13%。值得一提的是,S2SND 的在线 DER 已逼近甚至优于许多离线系统(如 EEND-M2F 的 16.07%),体现出其在新说话人检测与时序建模方面的强大泛化能力。
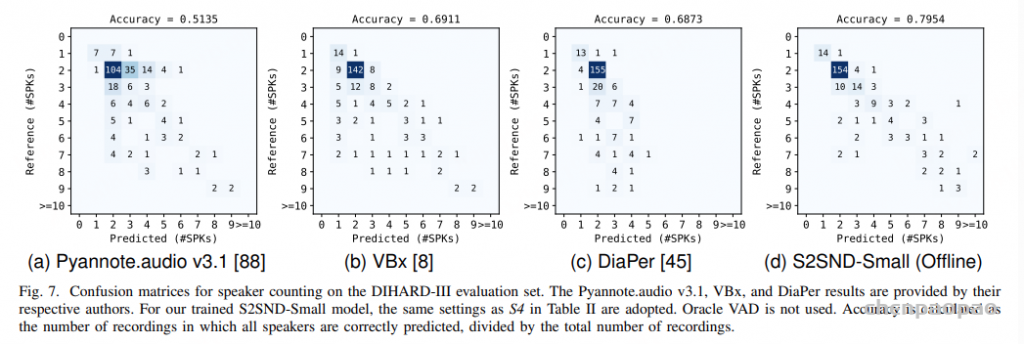
除了识别“谁在什么时候说话”,说话人日志系统还应有效估计音频中“有多少人参与对话”。图3展示了不同系统在 DIHARD-III 测试集上的说话人数量预测混淆矩阵。相比 EEND 和聚类方法,S2SND 的预测结果更集中于主对角线,表明其在不同说话人数场景下具有更强的稳定性和泛化能力。这种能力得益于 S2SND 在训练阶段将说话人检测和表征联合优化的设计,使模型能够在无需先验聚类的情况下,自主发现新说话人的出现并持续跟踪,从而自然完成说话人数量的判断与更新。
图3. DIHARD-III 测试集上的说话人数量预测混淆矩阵。Pyannote.audio v3.1、VBx 和 DiaPer 的结果由各自作者提供。评估过程中未使用 Oracle VAD。