
参考文章:支持向量机通俗导论
https://blog.csdn.net/v_july_v/article/details/7624837

线性分类
在训练数据中,每个数据都有n个的属性和一个二类类别标志,我们可以认为这些数据在一个n维空间里。我们的目标是找到一个n-1维的超平面(hyperplane),这个超平面可以将数据分成两部分,每部分数据都属于同一个类别。其实这样的超平面有很多,我们要找到一个最佳的。因此,增加一个约束条件:这个超平面到每边最近数据点的距离是最大的。也成为最大间隔超平面(maximum-margin hyperplane)。这个分类器也成为最大间隔分类器(maximum-margin classifier)。支持向量机是一个二类分类器。
非线性分类
SVM的一个优势是支持非线性分类。它结合使用拉格朗日乘子法和KKT条件,以及核函数可以产生非线性分类器。
以下摘自 支持向量机通俗导论 https://blog.csdn.net/v_july_v/article/details/7624837
支持向量机,因其英文名为 Support Vector Machine,故一般简称 SVM,通俗
来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线
性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
凸二次优化:https://zhuanlan.zhihu.com/p/100041443
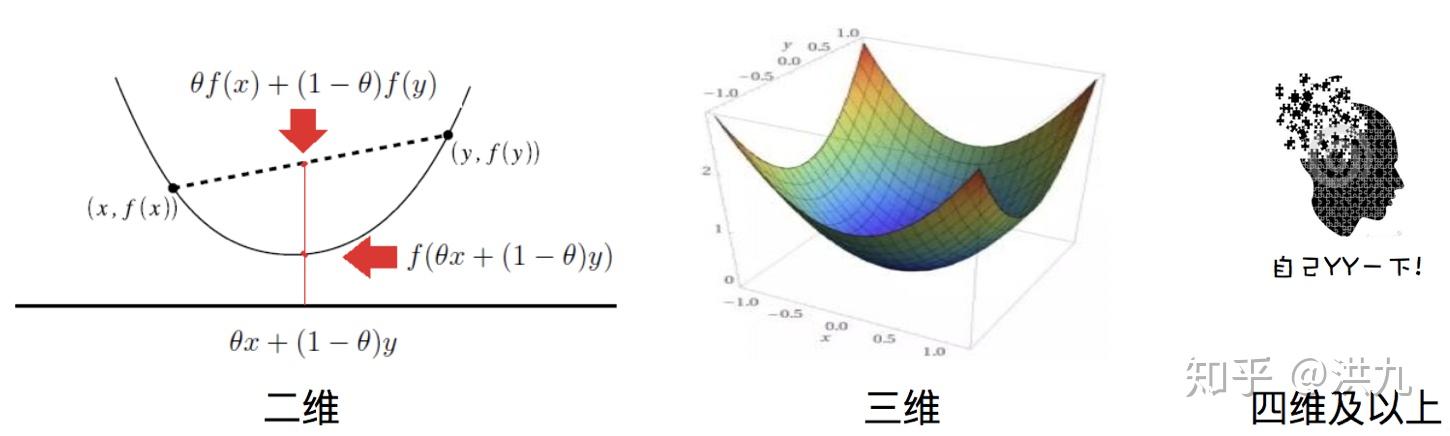
凸函数:直观来讲就是形状看上去“凹”下去的函数,注意可不是看上去“凸”的函数
凸优化的形式化定义:
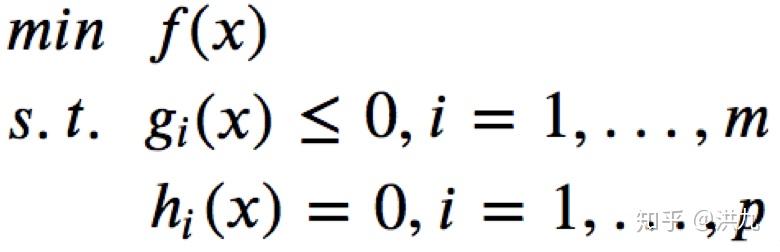
其中, x 为决策变量, f和g 均为凸函数, h为仿射(线性)函数。
https://www.cnblogs.com/90zeng/p/Lagrange_duality.html
KKT条件
同时包含等式约束和不等式约束:
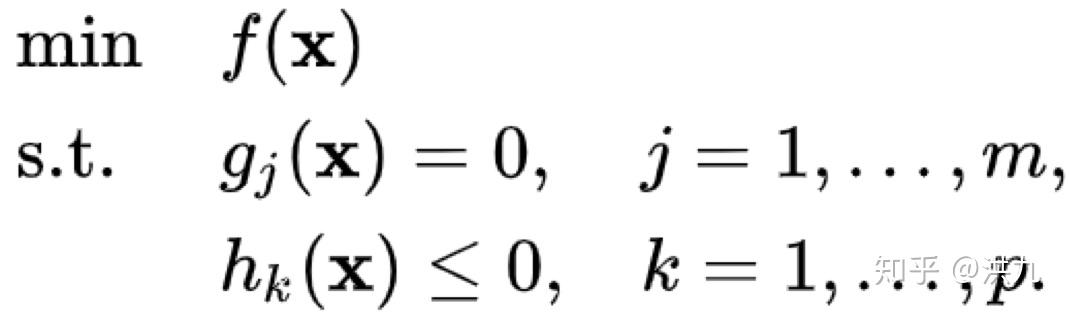
定义Lagrange函数:
此时
满足的必要条件为:
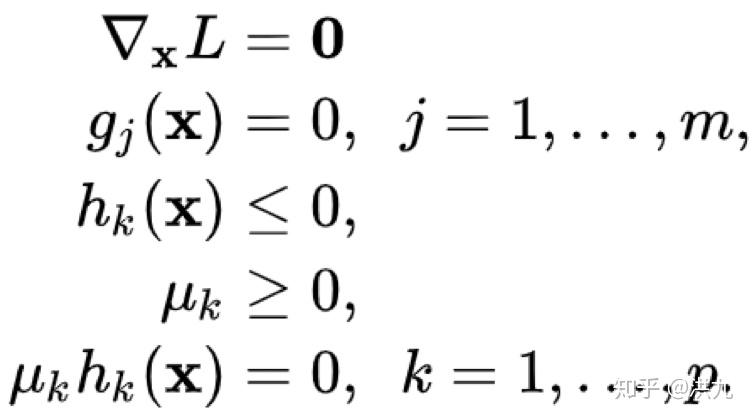
大名鼎鼎的SVM算法。机器学习发展历史上一颗璀璨的明珠。相信很多接触机器学习的同学都是从SVM开始的。
SVM是为小样本学习设计的,而工业界(尤其是互联网领域)不缺少数据,同时SVM训练效率较低且不容易调试,同时不如LR模型可解释行强。所以SVM常见于实验室而在互联网领域鲜有应用。不过SVM将问题建模为“有约束凸二次优化问题”,其求解过程非常具有代表性。

上述过程将原有问题通过拉格朗日乘子法转换为对偶问题。
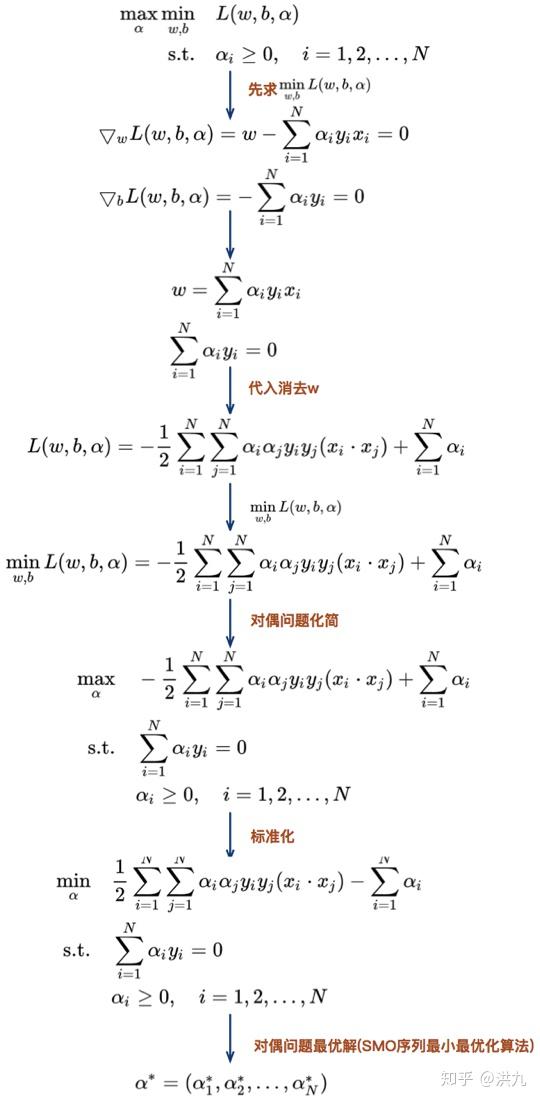
上述过程通过各种消元trick将问题转换成只有一类对偶变量 的形式,减小了求解难度。在实际SVM工具包中通常采用SMO算法。
如果所有变量的解都满足此最优化问题的KKT条件(Karush-Kuhn-Tucker conditions),那么这个最优化问题的解就得到了。因为KKT条件是该最优化问题的充分必要条件。否则,选择两个变量,固定其他变量,针对这两个变量构建一个二次规划问题。这个二次规划问题关于这两个变量的解应该更接近原始二次规划问题的解,因为这会使得原始二次规划问题的目标函数值变得更小。重要的是,这时子问题可以通过解析方法求解,这样就可以大大提高整个算法的计算速度。子问题有两个变量,一个是违反KKT条件最严重的那一个,另一个由约束条件自动确定。如此,SMO算法将原问题不断分解为子问题并对子问题求解,进而达到求解原问题的目的。
