
论文:Real-ESRGAN: TrainingReal-World Blind Super-Resolution with Pure Synthetic Data
代码:https://github.com/xinntao/Real-ESRGAN

Real-ESRGAN 的目标是开发出实用的图像/视频修复算法。
在 ESRGAN 的基础上使用纯合成的数据来进行训练,以使其能被应用于实际的图片修复的场景(顾名思义:Real-ESRGAN)。
- 目标:解决真实场景下的图像模糊问题。
- 数据集的构建:模糊核、噪声、尺寸缩小、压缩四种操作的随机顺序。
- 超分网络backbone:ESRGAN的生成网络+U-Net discriminator判别器。
- 损失函数:L1 loss,perceptual loss,生成对抗损失。
- 主要对比方法是:RealSR、ESRGAN、BSRGAN、DAN、CDC。
创新点
- 提出了新的构建数据集的方法,用高阶处理,增强降阶图像的复杂度。
- 构造数据集时引入sinc filter,解决了图像中的振铃和过冲现象。
- 替换原始ESRGAN中的VGG-discriminator,使用U-Net discriminator,以增强图像的对细节上的对抗学习。
- 引入spectral normalization以稳定由于复杂数据集和U-Net discriminator带来的训练不稳定情况。

数据集构建
在讨论数据集的构建前,作者详细讨论了造成图像模糊的原因,例如:年代久远的手机、传感器噪声、相机模糊、图像编辑、图像在网络中的传输、JPEG压缩以及其它噪声。原文如下:
For example, when we take a photo with our cellphones, the photos may have several degradations, such as camera blur, sensor noise, sharpening artifacts, and JPEG compression. We then do some editing and upload to a social media APP, which introduces further compression and unpredictable noises.
所以作者针对以上问题,提出了High-order降级模型。先面我们先介绍first-order降级模型,然后就很好理解High-order降级模型了。
First-order

First-order降级模型其实就是常规的降级模型,如上式所示,按顺序执行上述操作。
x代表降级后的图像,D代表降级函数,y代表原始图像;
k代表模糊核,r代表缩小比例,n代表加入的噪声,JPEG代表进行压缩。
每一种降级方法又有多种降级方案可以选择,如下图所示:
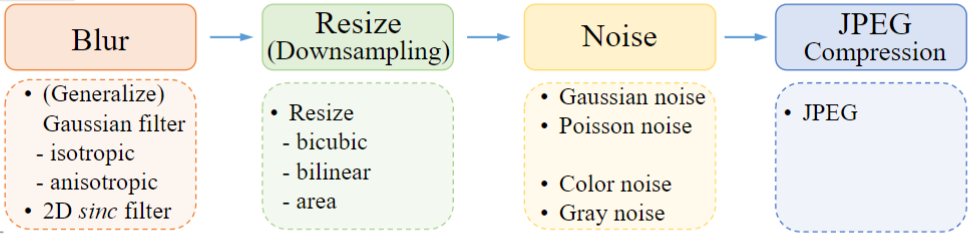
对于模糊核k,本方法使用各项同性(isotropic)和各向异性(anisotropic)的高斯模糊核。关于sinc filter会在下文中提到。
对于缩小操作r,常用的方法又双三次插值、双线性插值、区域插值—由于最近邻插值需要考虑对齐问题,所以不予以考虑。在执行缩小操作时,本方法从提到的3种插值方式中随机选择一种。
对于加入噪声操作n,本方法同时加入高斯噪声和服从泊松分布的噪声。同时,根据待超分图像的通道数,加入噪声的操作可以分为对彩色图像添加噪声和对灰度图像添加噪声。
JPEG压缩,本方法通过从[0, 100]范围中选择压缩质量,对图像进行JPEG压缩,其中0表示压缩后的质量最差,100表示压缩后的质量最好。JPEG压缩方法点此处。
- High-order
First-order由于使用相对单调的降级方法,其实很难模仿真实世界中的图像低分辨模糊情况。因此,作者提出的High-order其实是为了使用更复杂的降级方法,更好的模拟真实世界中的低分辨模糊情况,从而达到更好的学习效果。一阶降级模型构建的数据集训练结果如下:

高阶降级模型公式如下:

上式,其实就是对First-order进行多次重复操作,也就是每一个D都是执行一次完整的First-order降级。作者通过实验得出,当执行2次First-order时生成的数据集训练效果最好。所以,High-order的pipeline如下:

- sinc filter
为了解决超分图像的振铃和过冲现象(振铃和过冲在图像处理中很常见,此处不过多介绍),作者提出了在构建降级模型中增加sinc filter的操作。先来看一下振铃和过冲伪影的效果:

上图表示实际中的振铃和过冲伪影现象,下图表示通过对sinc filter设置不同的因子人工模仿的振铃和过冲伪影现象。过于如何构造sinc filter,详细细节建议看原文。
sinc filter在两个位置进行设置,一是在每一阶的模糊核k的处理中,也就是在各项同性和各项异性的高斯模糊之后,设置sinc filter;二是在最后一阶的JPEG压缩时,设置sinc filter,其中最后一阶的JPEG和sinc filter执行先后顺序是随机的。
网络结构
- 生成网络
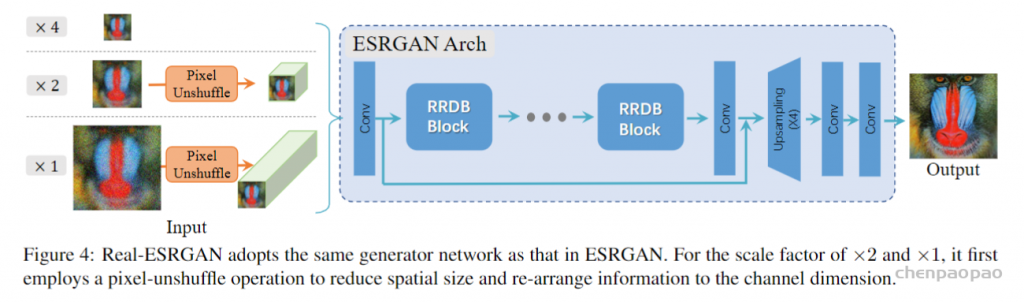
生成网络是ESRGAN的生成网络,基本没变,只是在功能上增加了对x2和x1倍的图像清晰度提升。对于x4倍的超分辨,网络完全按照ESRGAN的生成器执行;而对于X2和X1倍的超分辨,网络先进行pixel-unshuffle(pixel-shuffl的反操作,pixel-shuffle可理解为通过压缩图像通道而对图像尺寸进行放大),以降低图像分辨率为前提,对图像通道数进行扩充,然后将处理后的图像输入网络进行超分辨重建。举个例子:对于一幅图像,若只想进行x2倍放大变清晰,需先通过pixel-unshuffle进行2倍缩小,然后通过网络进行4倍放大。
对抗网络
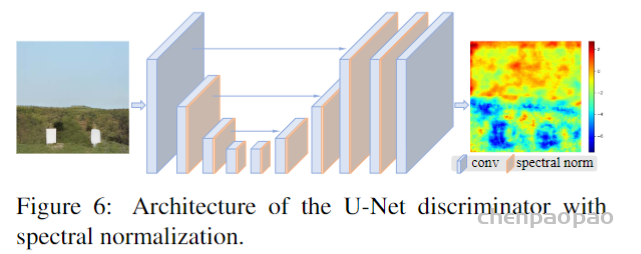
由于使用的复杂的构建数据集的方式,所以需要使用更先进的判别器对生成图像进行判别。之前的ESRGAN的判别器更多的集中在图像的整体角度判别真伪,而使用U-Net 判别器可以在像素角度,对单个生成的像素进行真假判断,这能够在保证生成图像整体真实的情况下,注重生成图像细节。
- 光谱标准正则化
通过加入这一操作,可以缓和由于复杂数据集合复杂网络带来的训练不稳定问题。
训练
分为两步:
- 先通过L1 loss,训练以PSRN为导向的网络,获得的模型称为Real-ESRNet。
- 以Real-ESRNet的网络参数进行网络初始化,损失函数设置为 L1 loss、perceptual loss、 GAN loss,训练最终的网络Real-ESRGAN。


