
王树森大佬又开了一门公开课:推荐系统,抱着学习的心态来学习下王老师的课。并做个笔记。
github课件:https://github.com/wangshusen/Recomme…
基本概念:
曝光:类似系统给你的推荐的内容
点击:用户点击推荐的内容
阅读:用户点击后在页面停留一段时间
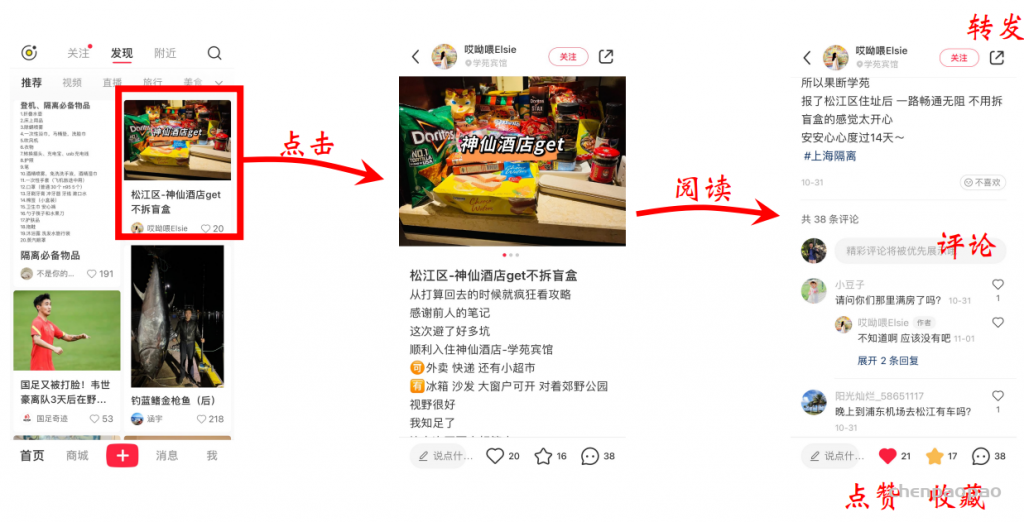
转化流程:
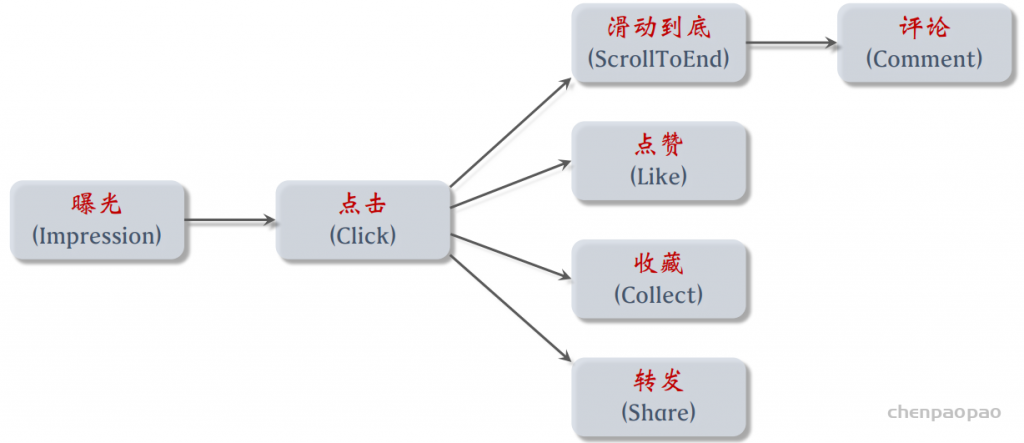
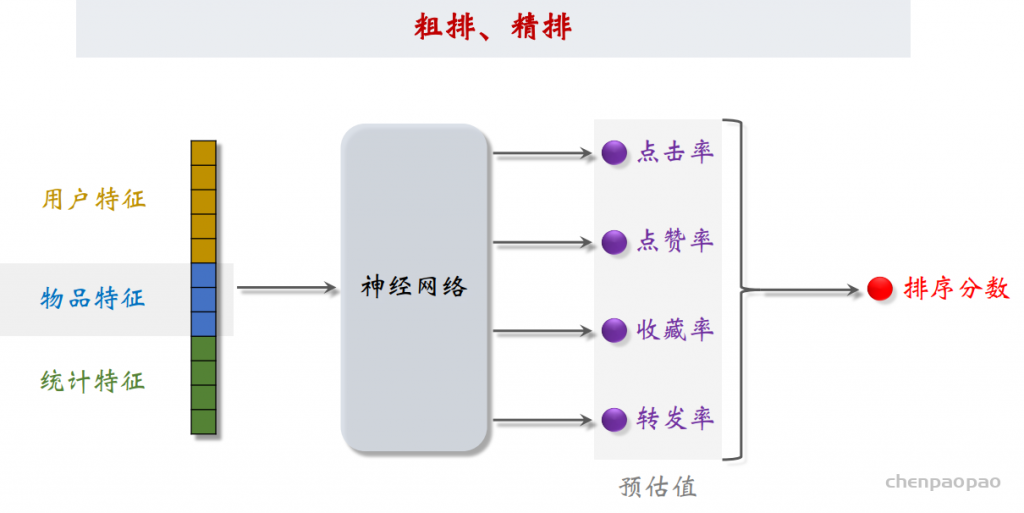
用户行为:点击、点赞、收藏、转发
消费指标:用于反应消费侧对推荐系统的满意程度(非最重要)

消费指标:点击率 (click rate)、交互率 (engagement rate)
北极星指标(最核心指标):用户规模、消费、发布 (关键指标)
DAU:日活跃用户数,用户本日登入小红书,就算一个DAU(且不重复计数)
MAU: 用户本月登入小红书,就算一个MAU(且不重复计数)

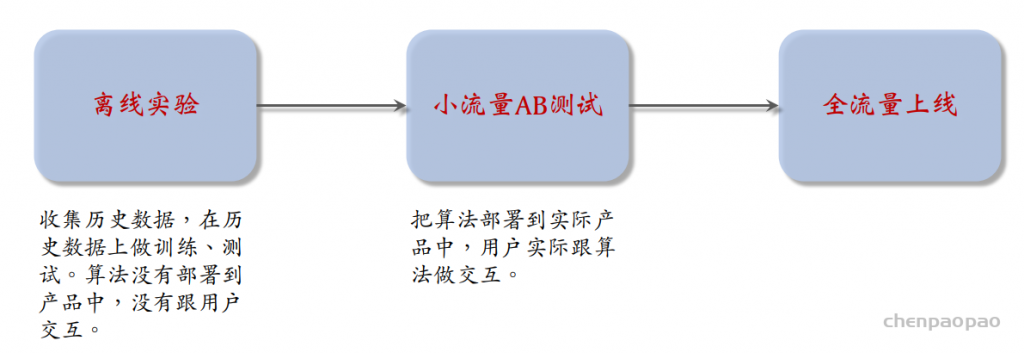
实验流程:离线实验、AB测试、推全
离线实验只能反映部分指标,还需要线上实验。
推荐系统链路
链路包括召回、粗排、精排、重排。
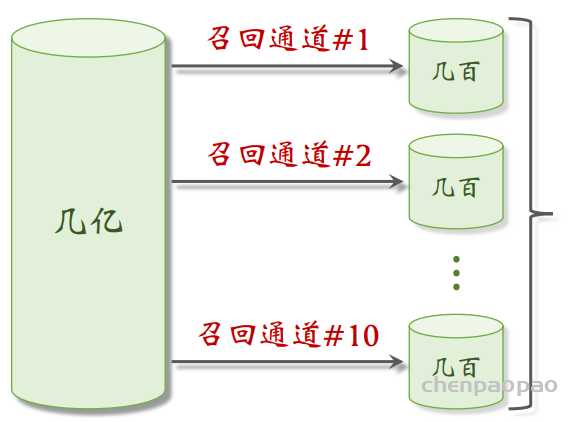
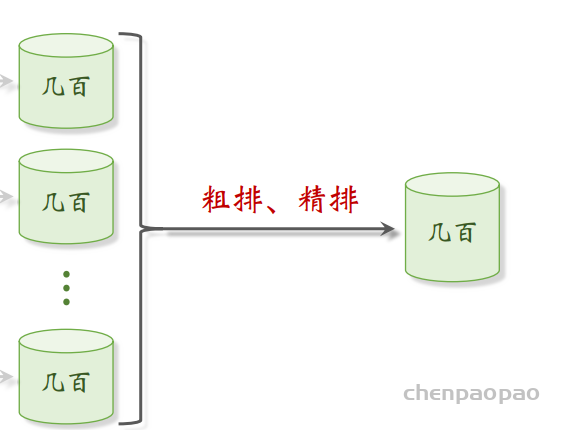
– 召回(retrieval):快速从海量数据中取回几千个用户可能感兴趣的物品。
– 粗排:用小规模的模型的神经网络给召回的物品打分,然后做截断,选出分数最高的几百个物品。
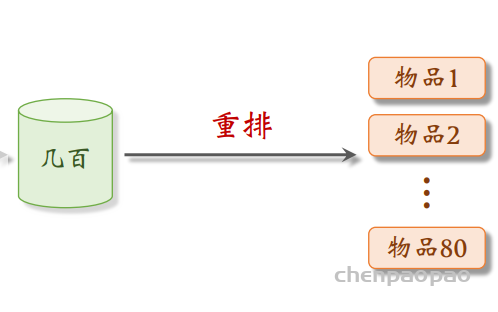
– 精排:用大规模神经网络给粗排选中的几百个物品打分,可以做截断,也可以不做截断。 – 重排:对精排结果做多样性抽样,得到几十个物品,然后用规则调整物品的排序。

当用户刷新页面时候,系统就会调用几十条召回通道,每个通道取回几百篇笔记内容,然后使用 用小规模的模型的神经网络给召回的物品打分,然后做截断,选出分数最高的几百个物品。 在下一部精排: 用大规模神经网络给粗排选中的几百个物品打分,可以做截断,也可以不做截断。最后:对精排结果做多样性抽样,得到几十个物品,然后用规则调整物品的排序。

重排
做多样性抽样(⽐如MMR、DPP),从⼏百篇中选出⼏⼗篇。
• ⽤规则打散相似笔记。
• 插⼊广告、运营推广内容,根据⽣态要求调整排序。
总结:

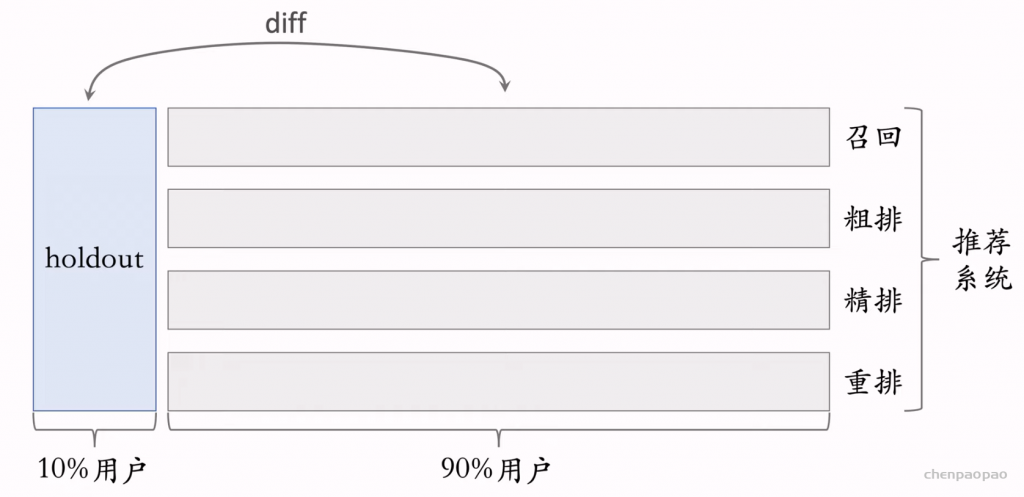
推荐系统的小流量A/B测试 (线上实验)
推荐系统算法工程师的日常工作就是改进模型和策略,目标是提升推荐系统的业务指标。所有对模型和策略的改进,都需要经过线上 AB 测试,用实验数据来验证模型和策略是否有效。
小流量:比如只对10%的用户开放该算法,观测用户的反馈,这样避免大范围的影响。


使用随机分桶测试不同的实验参数效果:
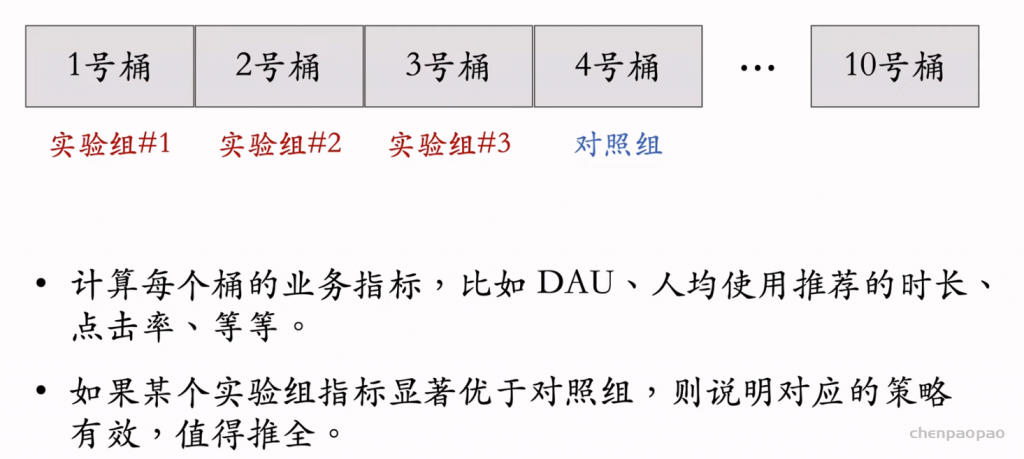
分层实验:解决流量不足的问题(测试的用户不足)


同层互斥,不同层正交:




实验推全和反转实验




