
论文地址 : https://arxiv.org/abs/1809.02983
github:https://github.com/junfu1115/DANet (CVPR2019)
为了有效地完成场景分割的任务,我们需要区分一些混淆的类别,并考虑不同外观的对象。例如,草原与牧场有时候是很难区分的,公路上的车也存在尺度、视角、遮挡与亮度等的变化。因此,像素级识别需要提高特征表示的识别能力。
创新点:
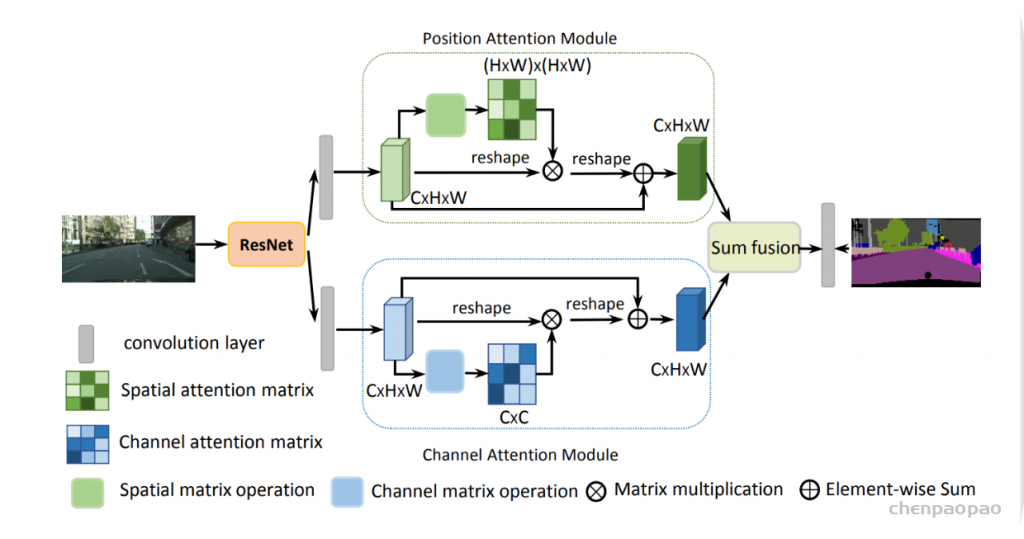
通过基于Self Attention mechanism来捕获上下文依赖,并提出了Dual Attention Networks (DANet)来自适应地整合局部特征和全局依赖。该方法能够自适应地聚合长期上下文信息,从而提高了场景分割的特征表示。
- 提出了Dual Attention Networks (DANet)在spatial和channle维度来捕获全局特征依赖。
- 提出position attention module去学习空间特征的相关性,提出channel attention module去建模channle的相关性。
在一贯的dilated FCN中加入两种类型地attention module。其中position attention module选择性地通过所有位置的加权求和聚集每个位置的特征,channel attention module通过所有channle的feature map中的特征选择性地强调某个特征图。最后将两种attention module的output 求和得到最后的特征表达。
Position Attention Module
捕获特征图的任意两个位置之间的空间依赖,对于某个特定的特征,被所有位置上的特征加权和更新。权重为相应的两个位置之间的特征相似性。因此,任何两个现有相似特征的位置可以相互贡献提升,而不管它们之间的距离。
- 特征图A(C×H×W)首先分别通过3个卷积层(BN和ReLU)得到3个特征图{B,C,D}.shape∈(CxHxW),然后reshape为C×N,其中N=H×W。
- 矩阵C和B的转置相乘,再通过softmax得到spatial attention map S(N×N)。
- 矩阵D和S的转置相乘,reshape result到(CxHxW)再乘以尺度系数 α 再reshape为原来形状,,最后与A相加得到最后的输出E 其中α初始化为0,并逐渐的学习分配到更大的权重。可以看出E的每个位置的值是原始特征每个位置的加权求和得到的。
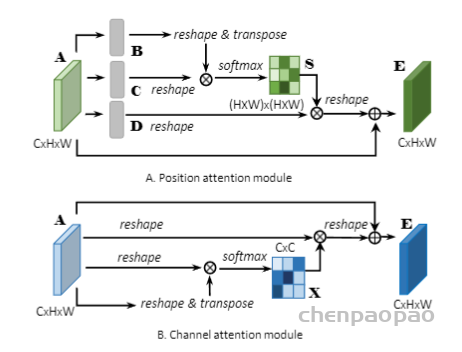
Channel Attention Module
每个高层次特征的通道映射都可以看作是一个特定于类的响应,不同的语义响应相互关联。通过探索通道映射之间的相互依赖关系,可以强调相互依赖的特征映射,提高特定语义的特征表示。