
https://arxiv.org/abs/1408.5882
github实现
https://github.com/yoonkim/CNN_sentence
https://github.com/Cheneng/TextCNN
对于文本分类,我们能不能用CNN来做,用某种模型初始化,进而做fine-tune呢?答案是肯定的,用于文本分析的CNN—TextCNN。
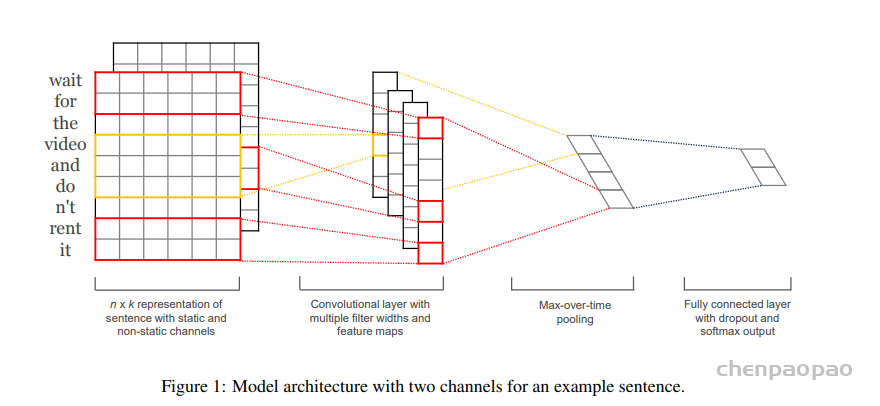
text-cnn用于情感分类:
与二维卷积层一样,一维卷积层使用一维的互相关运算。在一维互相关运算中,卷积窗口从输入数组的最左方开始,按从左往右的顺序,依次在输入数组上滑动。当卷积窗口滑动到某一位置时,窗口中的输入子数组与核数组按元素相乘并求和,得到输出数组中相应位置的元素。

多输入通道的一维互相关运算也与多输入通道的二维互相关运算类似:在每个通道上,将核与相应的输入做一维互相关运算,并将通道之间的结果相加得到输出结果。

由二维互相关运算的定义可知,多输入通道的一维互相关运算可以看作单输入通道的二维互相关运算。

类似地,我们有一维池化层。textCNN中使用的时序最大池化(max-over-time pooling)层实际上对应一维全局最大池化层:假设输入包含多个通道,各通道由不同时间步上的数值组成,各通道的输出即该通道所有时间步中最大的数值。因此,时序最大池化层的输入在各个通道上的时间步数可以不同。
简单来说,时序最大池化层就是沿着时序方向进行最大池化。
textCNN模型主要使用了一维卷积层和时序最大池化层。假设输入的文本序列由n个词组成,每个词用d维的词向量表示。那么输入样本的宽为n,高为1,输入通道数为d。textCNN的计算主要分为以下几步。(输入通道就是每个词的d为维度表示,宽就是时序长度)
词用d维的词向量表示 :一般使用词嵌入模型word2vec.
- 定义多个一维卷积核,并使用这些卷积核对输入分别做卷积计算。宽度不同的卷积核可能会捕捉到不同个数的相邻词的相关性。
- 对输出的所有通道分别做时序最大池化,再将这些通道的池化输出值连结为向量。
- 通过全连接层将连结后的向量变换为有关各类别的输出。这一步可以使用丢弃层应对过拟合。
下图用一个例子解释了textCNN的设计。这里的输入是一个有11个词的句子,每个词用6维词向量表示。因此输入序列的宽为11,输入通道数为6。给定2个一维卷积核,核宽分别为2和4,输出通道数分别设为4和5。因此,一维卷积计算后,4个输出通道的宽为11−2+1=10,而其他5个通道的宽为11−4+1=8。尽管每个通道的宽不同,我们依然可以对各个通道做时序最大池化,并将9个通道的池化输出连结成一个9维向量。最终,使用全连接将9维向量变换为2维输出,即正面情感和负面情感的预测。

pytorch代码实现:
https://github.com/chenpaopao/TextCNN总结:
- 可以使用一维卷积来表征时序数据。
- 多输入通道的一维互相关运算可以看作单输入通道的二维互相关运算。
- 时序最大池化层的输入在各个通道上的时间步数可以不同。
- textCNN主要使用了一维卷积层和时序最大池化层。
