

Abstract:
自动描述图像的内容是连接计算机视觉和自然语言处理的人工智能的基本问题。在本文中,我们提出了一个基于深度递归体系结构的生成模型,该模型结合了计算机视觉和机器翻译的最新进展,可用于生成描述图像的自然句子。训练模型以在给定训练图像的情况下最大化目标描述语句的可能性。在多个数据集上进行的实验表明,该模型的准确性以及仅从图像描述中学习的语言的流畅性。我们的模型通常非常准确,我们可以在定性和定量上进行验证。例如,在Pascal数据集上,当前最先进的BLEU-1得分(越高越好)是25,而我们的方法得出的结果是59,与人类表现在69左右相比。我们还显示了BLEU-1 Flickr30k的得分从56提升到66,SBU的得分从19提升到28。最后,在新发布的COCO数据集上,我们的BLEU-4为27.7,这是当前的最新水平。
Introduction:
能够使用格式正确的英语句子自动描述图像的内容是一项非常具有挑战性的任务,但它可能会产生巨大的影响,例如,通过帮助视力障碍的人们更好地理解网络上的图像内容。例如,此任务比经过充分研究的图像分类或对象识别任务要困难得多,而这些任务已成为计算机视觉领域的主要关注点[27]。实际上,描述不仅必须捕获图像中包含的对象,而且还必须表达这些对象如何相互关联以及它们的属性和它们所涉及的活动。此外,必须表达上述语义知识以自然语言(例如英语)表示,这意味着除了视觉理解外还需要一种语言模型。
以前的大多数尝试都是将上述子问题的现有解决方案组合在一起,以便从图像进行描述[6,16]。相反,我们在这项工作中提出一个联合模型,该模型以图像 I 作为输入,并经过训练以最大化产生目标单词序列 S = S 1 , S 2 , . . . 的可能性 p ( S∣I ) ,其中每个单词 S t 来自给定的字典,即充分描述图像。
我们工作的主要灵感来自机器翻译的最新进展,其中的任务是通过最大化 p ( T∣S) ,将以源语言编写的句子 S 转换为目标语言的译文 T 。多年以来,机器翻译还通过一系列单独的任务来实现(分别翻译单词,对齐单词,重新排序等),但是最近的工作表明,使用递归神经网络(RNN)可以以更简单的方式完成翻译。 [3,2,30]并仍达到最先进的性能。 “编码器” RNN读取源语句并将其转换为丰富的固定长度向量表示形式,然后将其用作生成目标语句的“解码器” RNN的初始隐藏状态。
在这里,我们建议遵循这种优雅的方法,用深度卷积神经网络(CNN)代替编码器RNN。在过去的几年中,令人信服的表明,CNN可以通过将输入图像嵌入到固定长度的向量中来生成输入图像的丰富表示,从而这种表示可以用于各种视觉任务[28]。因此,自然是将CNN用作图像“编码器”,方法是先对其进行预训练以进行图像分类任务,然后将最后一个隐藏层用作生成语句的RNN解码器的输入(请参见图1)。我们将此模型称为神经图像标题或NIC。
我们的贡献如下。首先,我们提出了一个解决问题的端到端系统。它是一种神经网络,可以使用随机梯度下降训练。其次,我们的模型结合了用于视觉和语言模型的最新网络。这些可以在较大的语料库上进行预训练,因此可以利用其他数据。最后,与最先进的方法相比,它的性能显着提高。 例如,在Pascal数据集上,NIC的BLEU得分为59,与当前的最新水平25相比,而人类的性能达到69。在Flickr30k上,我们的得分从56提高到66,在SBU,从19到28。
Related Work:
从视觉数据中生成自然语言描述的问题已经在计算机视觉中进行了长期研究,但主要针对视频[7,32]。这导致了由视觉原始识别器与结构化形式语言(例如, And-Or图形或逻辑系统,它们通过基于规则的系统进一步转换为自然语言。这样的系统是手工设计的,相对较脆,并且仅在有限的领域(例如,图1)中被证明。例如,交通场景或运动描述。
带有自然文本的静止图像描述问题最近引起了人们的关注。借助对象,属性和位置识别方面的最新进展,尽管这些语言的表达能力受到限制,但我们仍可以驱动自然语言生成系统。 Farhadi等。 [6]使用检测来推断场景元素的三元组,并使用模板将其转换为文本。同样,李等。 [19]从检测开始,并使用包含检测到的对象和关系的短语拼凑出最终描述。 Kulkani等人使用了一个更复杂的检测图(三重态除外)。 [16],但具有基于模板的文本生成。也使用了基于语言解析的更强大的语言模型[23,1,17,18,5]。上面的方法已经能够“in the wild”描述图像,但是在文本生成方面,它们是经过大量手工设计和严格设计的。
大量工作解决了对给定图像[11、8、24]进行描述排名的问题。这样的方法基于在相同向量空间中共同嵌入图像和文本的想法。对于图像查询,将获取接近嵌入空间中图像的描述。最紧密地,神经网络用于共同嵌入图像和句子[29],甚至嵌入图像作物和句子[13],但并未尝试生成新颖的描述。通常,即使可能已经在训练数据中观察到了单个对象,上述方法也无法描述以前看不见的对象组成。而且,它们避免了解决评估所生成的描述的良好程度的问题。
在这项工作中,我们将用于图像分类的深层卷积网络[12]与用于序列建模的循环网络[10]相结合,以创建一个生成图像描述的单一网络。在这个单一的“端到端”网络的背景下对RNN进行了训练。该模型的灵感来自机器翻译中序列生成的最新成功[3,2,30],区别在于我们提供的不是卷积句子,而是提供了由卷积网络处理的图像。最近的著作是基洛斯等人。 [15]他们使用神经网络,但使用前馈神经网络,根据图像和前一个单词来预测下一个单词。毛等人的最新著作。 [21]使用递归神经网络进行相同的预测任务。这与当前建议非常相似,但是有许多重要的区别:我们使用功能更强大的RNN模型,并直接向RNN模型提供可视输入,这使得RNN可以跟踪那些由文字解释。由于这些看似微不足道的差异,我们的系统在已建立的基准上取得了明显更好的结果。最后,基洛斯等。 [14]提出通过使用功能强大的计算机视觉模型和对文本进行编码的LSTM来构建联合多峰嵌入空间。与我们的方法相反,它们使用两个单独的路径(一个用于图像,一个用于文本)来定义联合嵌入,并且即使它们可以生成文本,也对其方法进行了高度调整以进行排名。
Model:
在本文中,我们提出了一种神经和概率框架来从图像生成描述。统计机器翻译的最新进展表明,给定强大的序列模型,可以通过在“端到端”的方式中给定输入句子的情况下,直接最大化正确翻译的概率来获得最新的结果–既用于训练又用于推理。这些模型使用循环神经网络,该网络将可变长度输入编码为固定维向量,并使用此表示形式将其“解码”为所需的输出语句。 因此,很自然地使用相同的方法,即在给定图像(而不是源语言中的输入句子)的情况下,应用相同的原理将其“翻译”成其描述。
Thus, we propose to directly maximize the probability of the correct description given the image by using the following formulation:

where θ are the parameters of our model, I is an image, and S its correct transcription. Since S represents any sentence, its length is unbounded(无限的). Thus, it is common to apply the chain rule to model the joint probability over S 0 , . . . , S N , where N is the length of this particular example as

where we dropped the dependency on θfor convenience. At training time, ( S , I ) is a training example pair, and we optimize the sum of the log probabilities as described in (2) over the whole training set using stochastic gradient descent (further training details are given in Section 4).
It is natural to model p ( S t ∣ I , S 0 , . . . , S t − 1 )with a Recurrent Neural Network (RNN), where the variable number of words we condition upon up to t − 1 is expressed by a fixed length hidden state or memory h t This memory is updated after seeing a new input xtby using a non-linear function f :
ht+1=f(ht;xt)
为了使上述RNN更具体,需要做出两个关键的设计选择:f的确切形式是什么以及如何将图像和单词作为输入xt输入。对于 f,我们使用长时记忆(LSTM)网络,该网络已显示出诸如翻译之类的序列任务的最新性能。下一节将概述此模型。
对于图像的表示,我们使用卷积神经网络(CNN)。它们已被广泛地用于图像任务并已被研究,并且目前是物体识别和检测的最新技术。我们对CNN的特定选择使用一种新颖的方法对批处理进行归一化,并在ILSVRC 2014分类竞赛中获得当前的最佳表现[12]。此外,它们已被证明可以通过转移学习推广到其他任务,例如场景分类[4]。单词用嵌入模型表示。
LSTM-based Sentence Generator
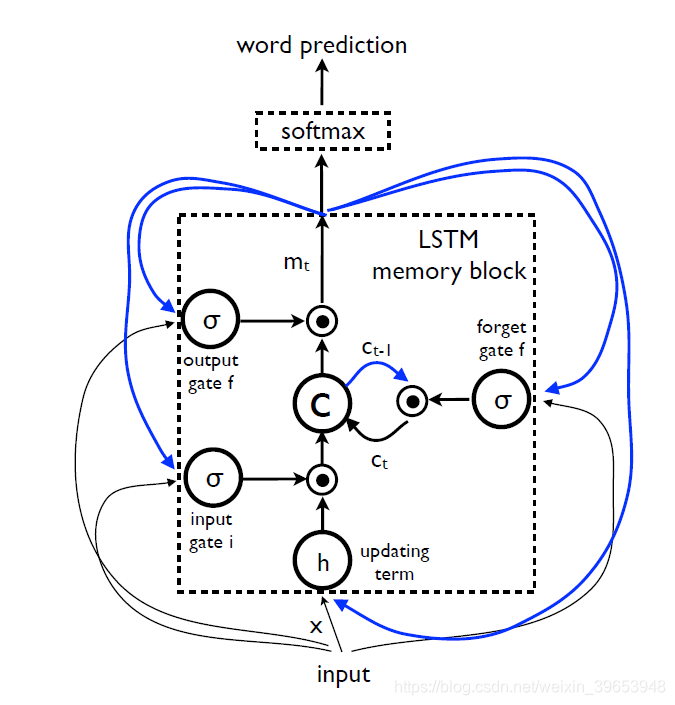
在(3)中f的选择取决于它处理消失和爆炸梯度的能力[10],这是设计和训练RNN时最常见的挑战。为了解决这一挑战,引入了一种称为LSTM的特殊形式的递归网络[10],并成功应用于翻译[3,30]和序列生成[9]。 LSTM模型的核心是存储单元 c ,它在每个时间步上编码知识,直到该步为止都观察到了哪些输入(参见图2)。单元的行为由“门”控制,“门”是相乘的层,因此如果门为1则可以保留门控层的值,如果门为0则可以保持此值为零。特别是,正在使用三个门用于控制是否忘记当前单元格值(忘记门 f),是否应读取其输入(输入门 i)以及是否输出新单元格值(输出门 o )。门的定义以及单元更新和输出如下:
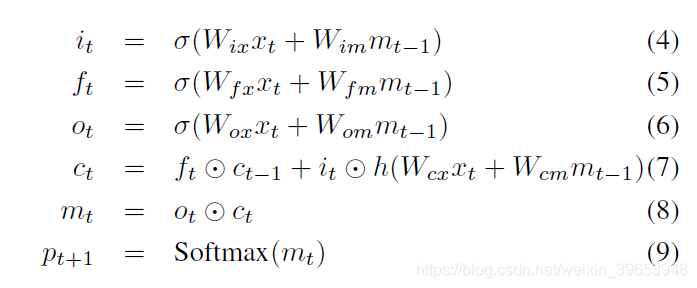
其中 ⊙表示门值的乘积,而各种 W矩阵都是经过训练的参数。这样的乘法门使训练鲁棒的LSTM成为可能,因为这些门很好地处理了爆炸和消失的梯度[10]。非线性为S型σ(⋅)和双曲正切 h ( ⋅ ) 。最后一个方程 mt是输入给Softmax的方程,它将产生所有单词上的概率分布。
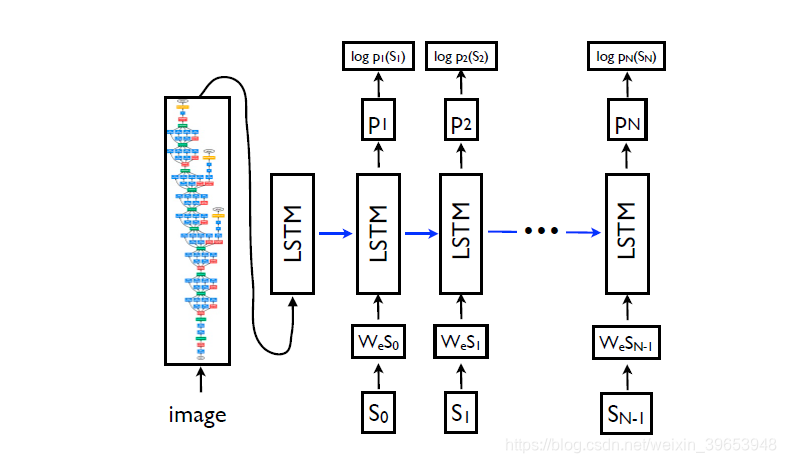
LSTM模型经过训练,可以在看到图像后预测句子中的每个单词以及通过 p ( S t ∣ I , S 0 , . . . , S t − 1 ) ) 预测所有先前单词。为此,以展开形式考虑LSTM是有启发性的–为图像和每个句子单词创建LSTM存储器的副本,以便所有LSTM在时间t共享相同的参数和LSTM的输出 mt-1
在时间 t 将馈送到LSTM(见图3)。在展开版本中,所有经常性连接都将转换为前馈连接。更详细地讲,如果我们用I表示输入图像,而用 S = ( S 0 , . . . , S N ) 表示描述该图像的真实句子,则展开过程为:

在这里,我们将每个单词表示为一维向量 S t ,其维数等于字典的大小。注意,我们用 S 0 表示一个特殊的开始词,用 S N 表示一个特殊的停止词,它指定句子的开头和结尾。特别是通过发出停用词,LSTM发出信号,表明已生成完整的句子。图像和单词都映射到相同的空间,使用视觉CNN映射图像,使用单词嵌入 W e映射到单词。图像 I 仅在 t = − 1 时输入一次,以通知LSTM有关图像内容。我们凭经验验证了,由于网络可以显式利用图像中的噪声并更容易过度拟合,因此在每个时间步幅上作为额外的输入来馈送图像会产生较差的结果
Our loss is the sum of the negative log likelihood of the correct word at each step as follows:
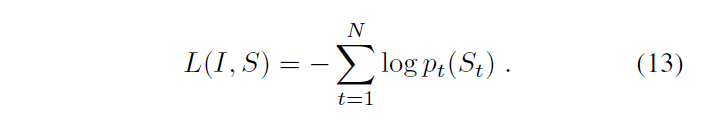
The above loss is minimized w.r.t. all the parameters of the LSTM, the top layer of the image embedder CNN and word embeddings We
使用NIC,有多种方法可以用于生成给定图像的句子。第一个是抽样,我们只是根据p1对第一个单词进行抽样,然后提供相应的嵌入作为输入,然后对p2进行抽样,这样一直进行下去,直到我们对特殊的语句结束标记或某个最大长度进行抽样。第二种方法是BeamSearch:迭代地考虑k个最好的句子,直到时间t,作为候选,生成大小为t + 1的句子,并只保留其中最好的k个。这更接近于S = arg maxS0 p(S0|I)。在接下来的实验中,我们使用了波束搜索方法,波束大小为20。使用光束大小为1(即(贪婪搜索)降低了平均2个BELU点。
结构整体结构:
包括Encoder、decoder 、Attention、 Beam Search(束搜索)

Generation Results
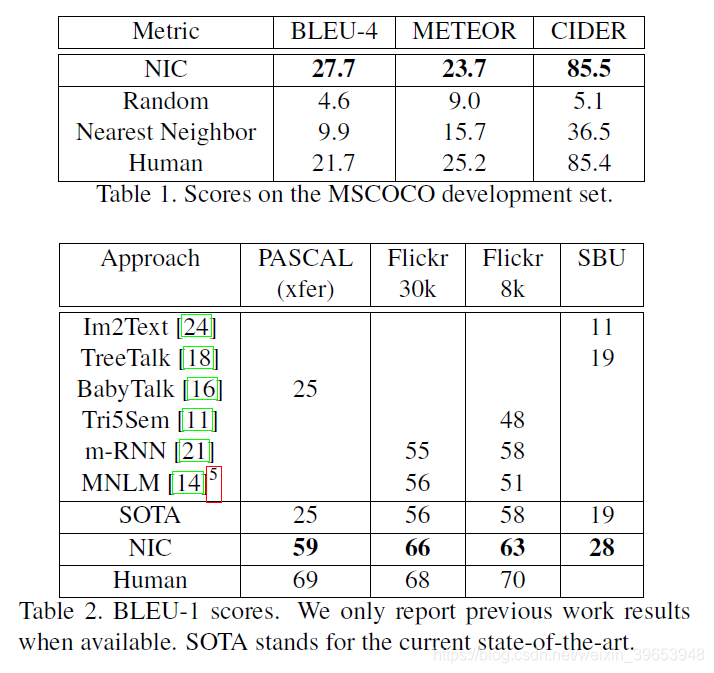
我们在表1和表2中报告了所有相关数据集的主要结果。由于PASCAL没有训练集,所以我们使用使用MSCOCO训练的系统(对于这个任务来说,MSCOCO可能是最大和最高质量的数据集)。PASCAL和SBU的最新研究结果并没有使用基于深度学习的图像特征,因此可以说,这些分数上的一个巨大进步仅仅来自于这种改变。Flickr数据集最近才被使用[11,21,14],但大多数是在检索框架中评估的。一个值得注意的例外是[21],它们在其中进行检索和生成,并且在Flickr数据集上产生了迄今为止最好的性能。
表2中的人类评分是通过比较其中一个人类字幕和另外四个字幕计算出来的。我们为五个打分者中的每一个打分,并对他们的BLEU分数进行平均。由于这给我们的系统带来了一点优势,考虑到BLEU分数是根据5个参考句计算的,而不是4个,我们将5个参考句而不是4个参考句的平均差异加回人类分数。
鉴于该领域在过去几年中取得了重大进展,我们认为报告BLEU-4更有意义,这是机器翻译向前发展的标准。此外,我们还报告了表14中显示的与人工评估关联更好的度量标准。尽管最近在更好的评价指标[31]的努力,我们的模型与人类评分者相比表现良好。然而,当使用人工评分员来评估我们的字幕时(见4.3.6节),我们的模型表现得更差,这表明我们需要做更多的工作来获得更好的指标。在官方测试集上,我们的标签只能通过官方网站获得,我们的型号有27.2的BLEU-4。
Conclusion
我们提出了NIC,一个端到端的神经网络系统,可以自动查看图像并生成合理的描述。NIC基于卷积神经网络,将图像编码成紧凑的表示形式,然后是递归神经网络,生成相应的句子。该模型经过训练以最大化给定图像的句子的可能性。在多个数据集上的实验表明,NIC在定性结果(生成的句子非常合理)和定量评估方面具有鲁棒性,可以使用排名指标,也可以使用机器翻译中用来评估生成句子质量的BLEU指标。从这些实验中可以清楚地看到,随着用于图像描述的可用数据集的大小的增加,NIC等方法的性能也会提高。此外,观察如何使用非监督数据(单独来自图像和单独来自文本)来改进图像描述方法也很有趣。
github实现:https://github.com/sgrvinod/Deep-Tutorials-for-PyTorch
References
[1] A. Aker and R. Gaizauskas. Generating image descriptions using dependency relational patterns. In ACL, 2010.
[2] D. Bahdanau, K. Cho, and Y . Bengio. Neural machine translation by jointly learning to align and translate. arXiv:1409.0473, 2014.
[3] K. Cho, B. van Merrienboer, C. Gulcehre, F. Bougares, H. Schwenk, and Y . Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In EMNLP, 2014.
[4] J. Donahue, Y . Jia, O. Vinyals, J. Hoffman, N. Zhang, E. Tzeng, and T. Darrell. Decaf: A deep convolutional activation feature for generic visual recognition. In ICML, 2014.
[5] D. Elliott and F. Keller. Image description using visual dependency representations. In EMNLP, 2013.
[6] A. Farhadi, M. Hejrati, M. A. Sadeghi, P . Y oung, C. Rashtchian, J. Hockenmaier, and D. Forsyth. Every picture tells a story: Generating sentences from images. In ECCV, 2010.
[7] R. Gerber and H.-H. Nagel. Knowledge representation for the generation of quantified natural language descriptions of vehicle traffic in image sequences. In ICIP. IEEE, 1996.
[8] Y . Gong, L. Wang, M. Hodosh, J. Hockenmaier, and S. Lazebnik. Improving image-sentence embeddings using large weakly annotated photo collections. In ECCV, 2014.
[9] A. Graves. Generating sequences with recurrent neural networks. arXiv:1308.0850, 2013.
[10] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural Computation, 9(8), 1997.
[11] M. Hodosh, P . Y oung, and J. Hockenmaier. Framing image description as a ranking task: Data, models and evaluation metrics. JAIR, 47, 2013.
[12] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In arXiv:1502.03167, 2015.
[13] A. Karpathy, A. Joulin, and L. Fei-Fei. Deep fragment embeddings for bidirectional image sentence mapping. NIPS, 2014.
[14] R. Kiros, R. Salakhutdinov, and R. S. Zemel. Unifying visual-semantic embeddings with multimodal neural language models. In arXiv:1411.2539, 2014.
[15] R. Kiros and R. Z. R. Salakhutdinov. Multimodal neural language models. In NIPS Deep Learning Workshop, 2013.
[16] G. Kulkarni, V . Premraj, S. Dhar, S. Li, Y . Choi, A. C. Berg, and T. L. Berg. Baby talk: Understanding and generating simple image descriptions. In CVPR, 2011.
[17] P . Kuznetsova, V . Ordonez, A. C. Berg, T. L. Berg, and Y . Choi. Collective generation of natural image descriptions. In ACL, 2012. [18] P . Kuznetsova, V . Ordonez, T. Berg, and Y . Choi. Treetalk: Composition and compression of trees for image descriptions. ACL, 2(10), 2014.
[19] S. Li, G. Kulkarni, T. L. Berg, A. C. Berg, and Y . Choi. Composing simple image descriptions using web-scale n-grams. In Conference on Computational Natural Language Learning, 2011.
[20] T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P . Perona, D. Ramanan, P . Dollár, and C. L. Zitnick. Microsoft coco: Common objects in context. arXiv:1405.0312, 2014.
[21] J. Mao, W. Xu, Y . Yang, J. Wang, and A. Y uille. Explain images with multimodal recurrent neural networks. In arXiv:1410.1090, 2014. [22] T. Mikolov, K. Chen, G. Corrado, and J. Dean. Efficient estimation of word representations in vector space. In ICLR, 2013.
[23] M. Mitchell, X. Han, J. Dodge, A. Mensch, A. Goyal, A. C. Berg, K. Yamaguchi, T. L. Berg, K. Stratos, and H. D. III. Midge: Generating image descriptions from computer vision detections. In EACL, 2012.
[24] V . Ordonez, G. Kulkarni, and T. L. Berg. Im2text: Describing images using 1 million captioned photographs. In NIPS, 2011.
[25] K. Papineni, S. Roukos, T. Ward, and W. J. Zhu. BLEU: A method for automatic evaluation of machine translation. In ACL, 2002.
[26] C. Rashtchian, P . Y oung, M. Hodosh, and J. Hockenmaier. Collecting image annotations using amazon’s mechanical turk. In NAACL HLT Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk, pages 139– 147, 2010.
[27] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet Large Scale Visual Recognition Challenge, 2014.
[28] P . Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y . LeCun. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv preprint arXiv:1312.6229, 2013.
[29] R. Socher, A. Karpathy, Q. V . Le, C. Manning, and A. Y . Ng. Grounded compositional semantics for finding and describing images with sentences. In ACL, 2014.
[30] I. Sutskever, O. Vinyals, and Q. V . Le. Sequence to sequence learning with neural networks. In NIPS, 2014.
[31] R. V edantam, C. L. Zitnick, and D. Parikh. CIDEr: Consensus-based image description evaluation. In arXiv:1411.5726, 2015.
[32] B. Z. Yao, X. Yang, L. Lin, M. W. Lee, and S.-C. Zhu. I2t: Image parsing to text description. Proceedings of the IEEE, 98(8), 2010.
[33] P . Y oung, A. Lai, M. Hodosh, and J. Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. In ACL, 2014.
[34] W. Zaremba, I. Sutskever, and O. Vinyals. Recurrent neural network regularization. In arXiv:1409.2329, 2014.