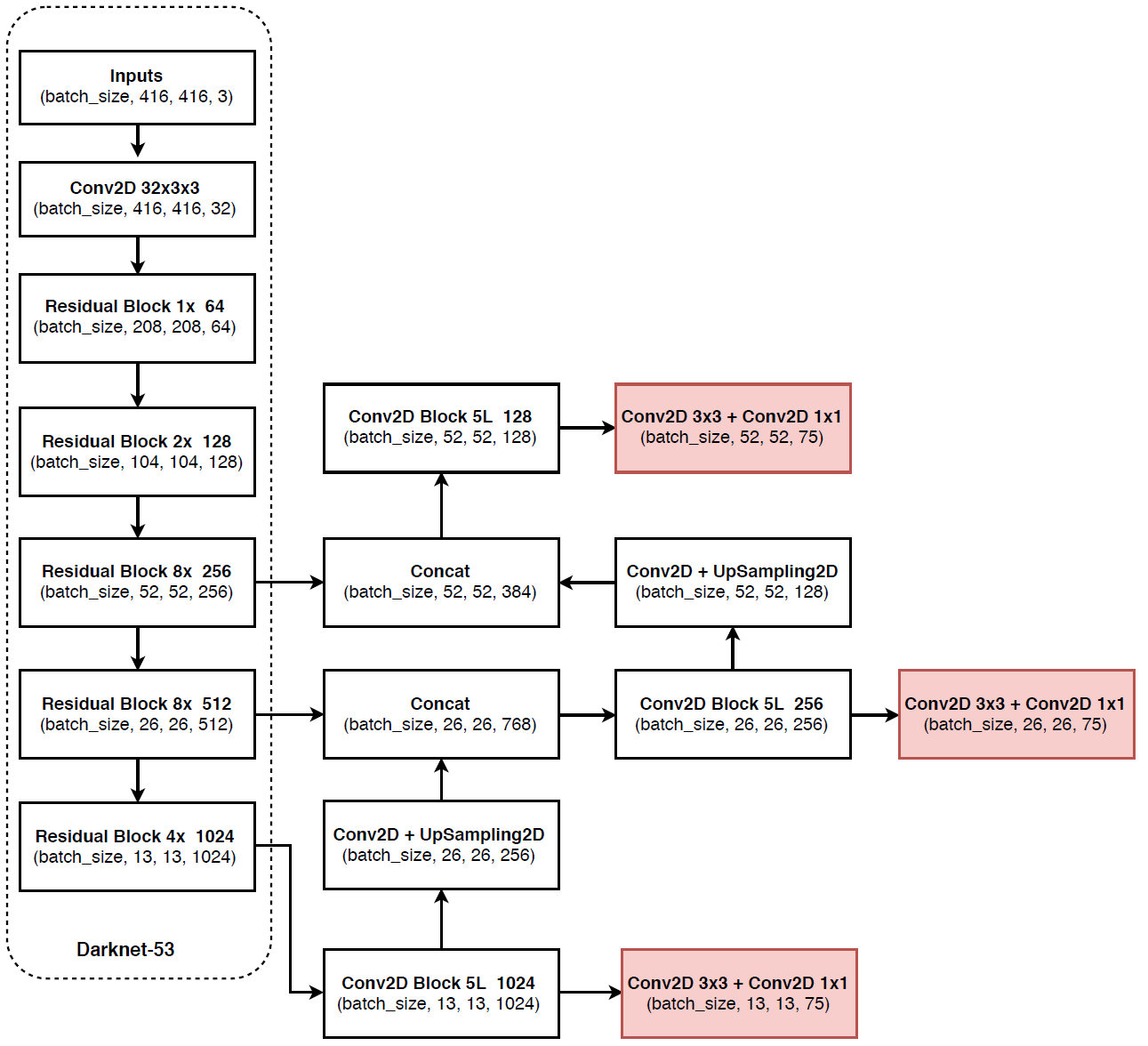
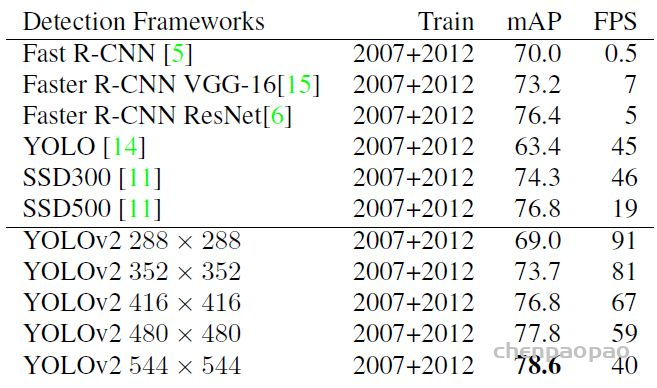
YOLOv2的论文全名为YOLO9000: Better, Faster, Stronger,它斩获了CVPR 2017 Best Paper Honorable Mention。在这篇文章中,作者首先在YOLOv1的基础上提出了改进的YOLOv2,然后提出了一种检测与分类联合训练方法,使用这种联合训练方法在COCO检测数据集和ImageNet分类数据集上训练出了YOLO9000模型,其可以检测超过9000多类物体。所以,这篇文章其实包含两个模型:YOLOv2和YOLO9000,不过后者是在前者基础上提出的,两者模型主体结构是一致的。YOLOv2相比YOLOv1做了很多方面的改进,这也使得YOLOv2的mAP有显着的提升,并且YOLOv2的速度依然很快,保持着自己作为one-stage方法的优势.
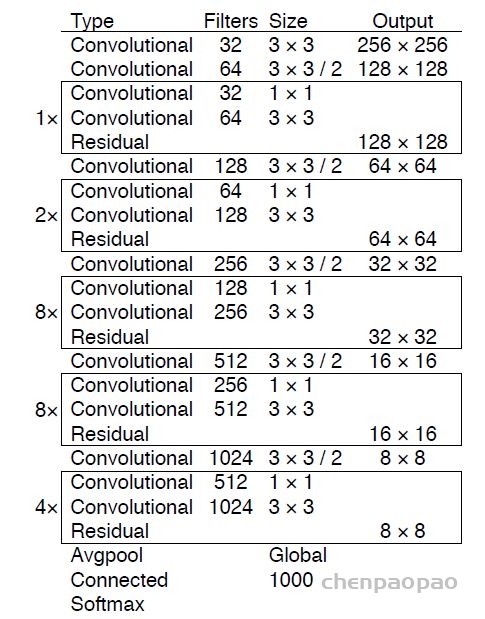
YOLOv2采用了一个新的基础模型(特征提取器),称为Darknet-19,包括19个卷积层和5个maxpooling层,如图4所示。Darknet-19与VGG16模型设计原则是一致的,主要采用3*3卷积,采用2*2的maxpooling层之后,特征图维度降低2倍,而同时将特征图的channles增加两倍。与NIN(Network in Network)类似,Darknet-19最终采用global avgpooling做预测,并且在3*3卷积之间使用1*1卷积来压缩特征图channles以降低模型计算量和参数。Darknet-19每个卷积层后面同样使用了batch norm层以加快收敛速度,降低模型过拟合。在ImageNet分类数据集上,Darknet-19的top-1准确度为72.9%,top-5准确度为91.2%,但是模型参数相对小一些。使用Darknet-19之后,YOLOv2的mAP值没有显着提升,但是计算量却可以减少约33%。
现在我们可以为每个锚框标记分类和偏移量了。假设⼀个锚框 A 被分配了⼀个真实边界框 B。⼀⽅⾯,锚框A 的类将被标记为与 B 相同。另⼀⽅⾯,锚框 A 的偏移量将根据 B 和 A 中⼼坐标的相对位置、以及这两个框的相对⼤小进⾏标记。鉴于数据集内不同的框的位置和⼤小不同,我们可以对那些相对位置和⼤小应⽤变换,使其获得更均匀分布、易于适应的偏移量。在这⾥,我们介绍⼀种常⻅的变换。给定框 A 和 B,中⼼坐标分别为 (xa, ya) 和 (xb, yb),宽度分别为 wa 和 wb,⾼度分别为 ha 和 hb。我们可以将 A 的偏移量标记为
在预测期间,我们先为图像⽣成多个锚框,再为这些锚框⼀⼀预测类别和偏移量。⼀个“预测好的边界框”则根据其中某个带有预测偏移量的锚框而⽣成。当有许多锚框时,可能会输出许多相似的具有明显重叠的预测边界框,都围绕着同⼀⽬标。为了简化输出,我们可以使⽤ ⾮极⼤值抑制 (non-maximum suppression,NMS)合并属于同⼀⽬标的类似的预测边界框。以下是⾮极⼤值抑制的⼯作原理。对于⼀个预测边界框 B,⽬标检测模型会计算每个类的预测概率。假设最⼤的预测概率为 p ,则该概率所对应的类别 B 即为预测的类别。具体来说,我们将 p 称为预测边界框 B 的置信度。在同⼀张图像中,所有预测的⾮背景边界框都按置信度降序排序,以⽣成列表 L。然后我们通过以下步骤操作排序列表 L:
从 L 中选取置信度最高的预测边界框 \(B_{1}\) 作为基准,然后将所有与 \(B_{1}\) 的IoU 超过预定阈值\(\epsilon\) 的非基准 预测边界框从 L 中移除。这时, L 保留了置信度最高的预测边界框,去除了与其太过相似的其他预测 边界框。简而言之,那些具有 非极大值置信度的边界框被 抑制了。
从 L 中选取置信度第二高的预测边界框 \(B_{2}\) 作为又一个基准,然后将所有与 \(B_{2}\)的IoU大于 \(\epsilon\)的非基准 预测边界框从 L 中移除。
重复上述过程,直到 L 中的所有预测边界框都曾被用作基准。此时, L中任意一对预测边界框的IoU都 小于阈值 \(\epsilon\); 因此,没有一对边界框过于相似。
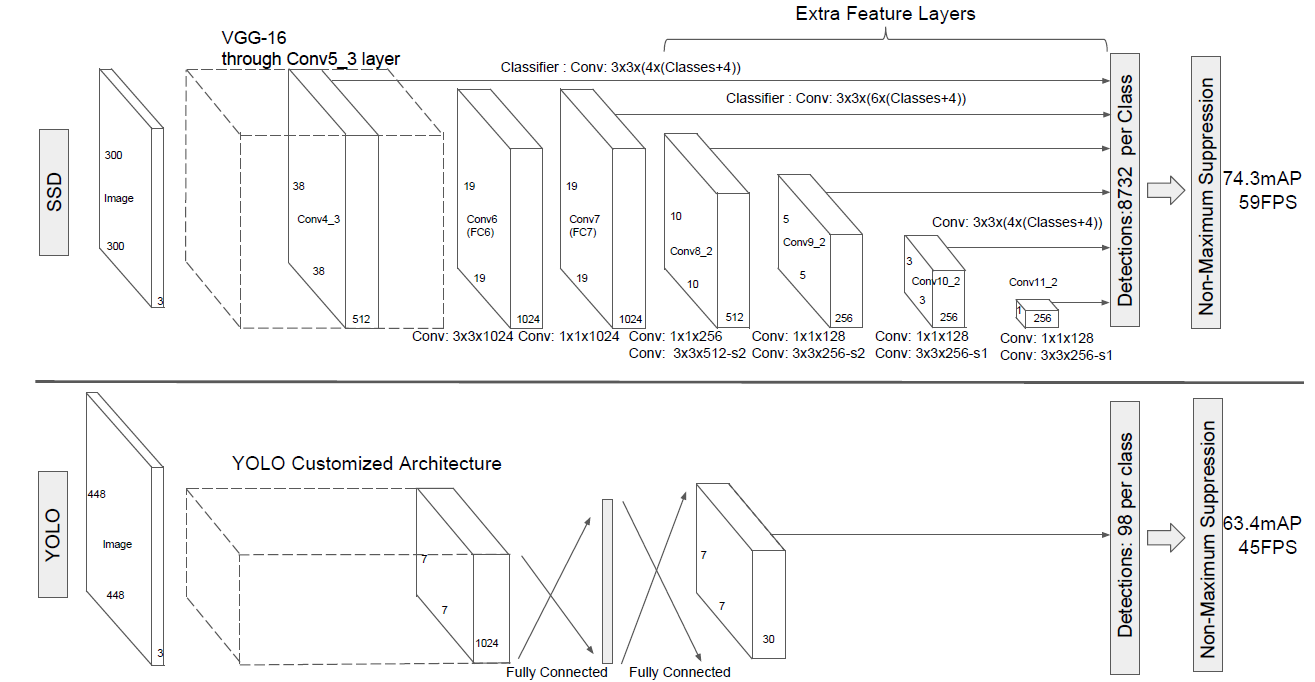
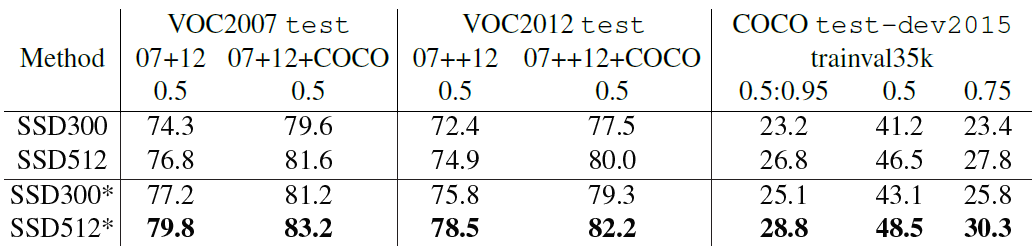
首先整体看一下SSD在VOC2007,VOC2012及COCO数据集上的性能,如表1所示。相比之下,SSD512的性能会更好一些。加*的表示使用了image expansion data augmentation(通过zoom out来创造小的训练样本)技巧来提升SSD在小目标上的检测效果,所以性能会有所提升。

,
为输出特征图格点数,一共3个Anchor框,每个框有4维预测框数值
,1维预测框置信度,80维物体类别数。所以第一层特征图的输出维度为
。
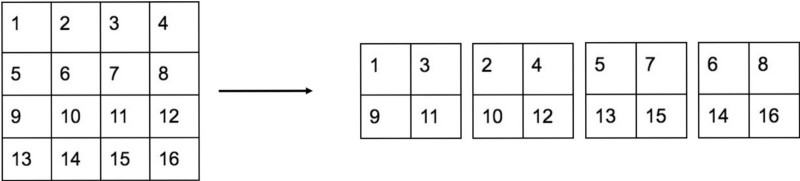
;而concat操作源于DenseNet网络的设计思路,将特征图按照通道维度直接进行拼接,例如8*8*16的特征图与8*8*16的特征图拼接后生成8*8*32的特征图。