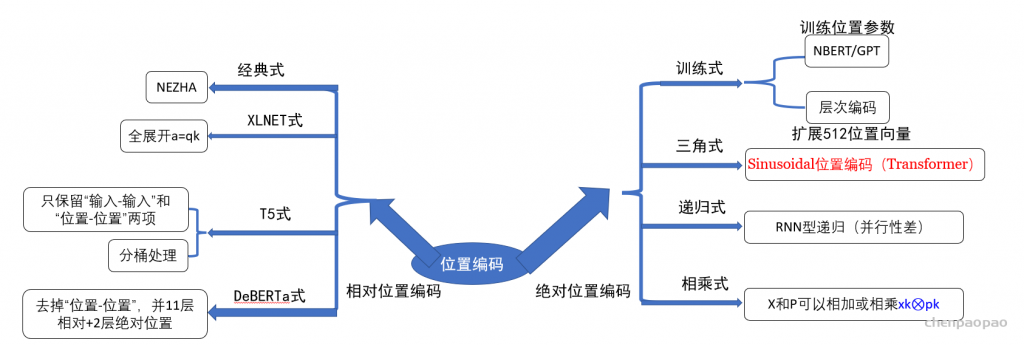
很显然,绝对位置编码的一个最朴素方案是不特意去设计什么,而是直接将位置编码当作可训练参数,比如最大长度为512,编码维度为768,那么就初始化一个512×768的矩阵作为位置向量,让它随着训练过程更新。现在的BERT、GPT等模型所用的就是这种位置编码,事实上它还可以追溯得更早,比如2017年Facebook的《Convolutional Sequence to Sequence Learning》就已经用到了它。
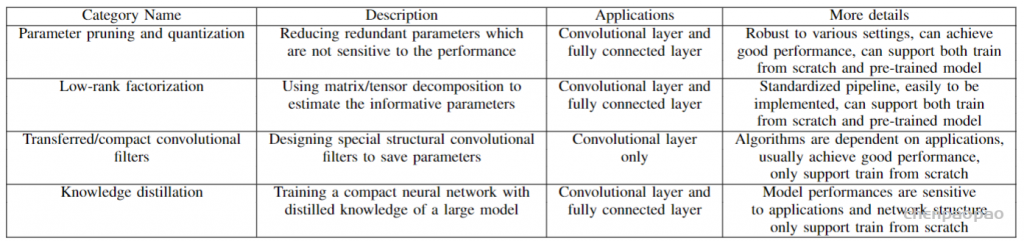
早期的研究表明,对构建的网络进行剪枝和量化在降低网络复杂性以及解决过拟合问题方面是有效的(Gong et al. 2014)。同剪枝与量化有关的方法可以进一步分为三个子类:量化与二值化(quantization and binarization)、网络剪枝(network pruning)、结构矩阵(structural matrix)。
1.量化与二值化(quantization and binarization)
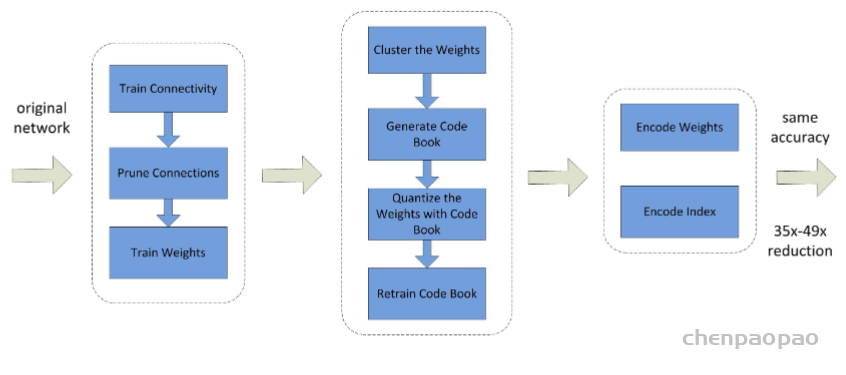
在DNN中,权重通常是以32位浮点数的形式(即32-bit)进行存储,量化法则是通过减少表示每个权重需要的比特数(the number of bits)来压缩原始网络。此时权重可以量化为16-bit、8-bit、4-bit甚至是1-bit(这是量化的一种特殊情况,权重仅用二进制表示,称为权重二值化)。8-bit的参数量化已经可以在损失小部分准确率的同时实现大幅度加速(Vanhoucke et al. 2011)。图2展示了基于修剪、量化和编码三个过程的压缩法:首先修剪小权重的连接,然后使用权重共享来量化权重,最后将哈夫曼编码应用于量化后的权重和码本上。
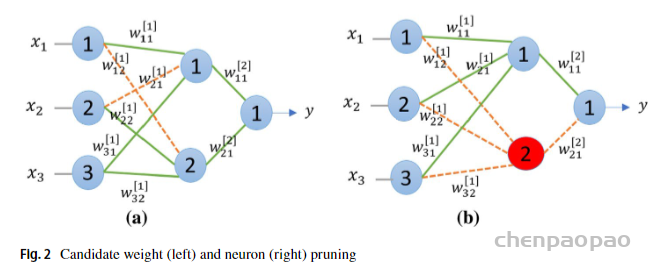
其中, x1、x2、x3 是网络的输入, wijl 是从当前层中节点 i 的层 l 到下一层中的节点 j 的权重。从图3(a)可以清楚地看出,目前总共有8个连接权重,如果删除两个橙色(虚线)的连接,那么总连接权重将减少到6个。类似地,从图3(b)中,如果移除红色神经元,那么其所有相关的连接权重(虚线)也将被移除,导致总连接权重减少到4个(参数数量减少50%)。
在卷积层上剪枝: 在卷积神经网络中, 卷积核 W∈Rh×w×ic×f 应用于每个输入的图像 I,I∈Rm×n×ic, 并且经过卷积操作后输出特征映射 T,T∈Rp×q×f 。其中, h 和 w 是卷积核的尺寸, ic 是输入图像中输入通道的数量, f 是应用的卷积核 的数量, m 和 n 是输入图像的尺寸, p 和 q 是结果特征映射的输出尺寸。输出特征映射的形状计算如下:
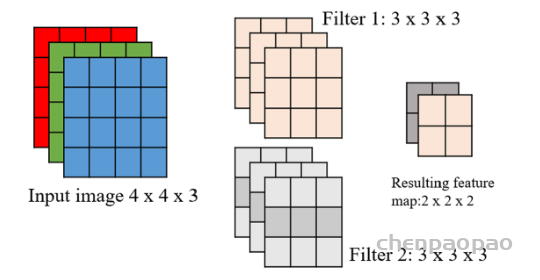
其中, s 为步长 (stride), p 为填充(padding)。图4显示了最简单的CNN形式,其 中输入图像的大小为 4×4×3, 应用的卷积核大小为 3×3×3×2 (2是卷积核的数 量)。
受到早期剪枝方法和神经网络过度参数化问题的启发,Han et al.(2015)提出了三步法来进行剪枝。其思想是,首先修剪激活小于某个预定义阈值的所有连接权重(不重要的连接),随后再识别那些重要的连接权重。最后,为了补偿由于修剪连接权重而导致的精度损失,再次微调/重新训练剪枝模型。这样的剪枝和再训练过程将重复数次,以减小模型的大小,将密集网络转换为稀疏网络。这种方法能够对全连接层和卷积层进行修剪,而且卷积层比全连接层对修剪更加敏感。
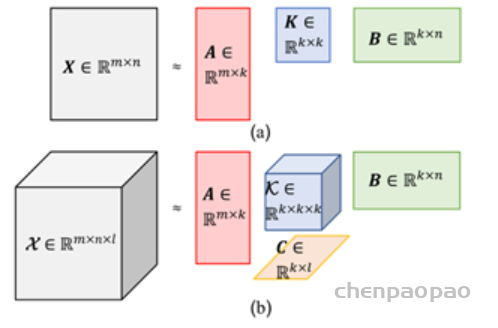
CP分解。该分解是Tucker分解的一种特殊形式。如果Tucker分解中的每个 ri 等于正 整数 rC, 并且核张量 K 满足, 除了 K(x1,x2,…,xd),x1=x2=⋯=xd 之外 的所有元素都是 0 , 此时Tucker分解就成为了CP分解。与Tucker分解相比, CP分解 常用于解释数据的组成成分, 而前者主要用于数据压缩。图7展示了三阶张量 x∈R(I×J×K) 被 R 个组成部分分解的过程, 这个过程也可以用如下的公式来表示, 其中, ar∈RI,br∈RJ,cr∈RK (Marcella Astrid and Seung- and Ik Lee 2018)。
Cohen and Welling (2016) 提出了使用卷积滤波器压缩CNN模型的想法, 并在 研究中引入了等变群理论 (the equivariant group theory)。让 x 作为输入, Φ(⋅) 作为 一个神经网络或者网络层, Γ(⋅) 作为迁移矩阵, 则等价的概念定义如下:Γ′(Φ(x))=Φ(Γ(x))
在现有的KD方法中,学生模型的学习依赖于教师模型,是一个两阶段的过程。Lan et al.(2018)提出了实时本地集成(On-the-fly Native Ensemble,ONE),这是一种高效的单阶段在线蒸馏学习方法。在训练期间,ONE添加辅助分支以创建目标网络的多分支变体,然后从所有分支中创建本地集成教师模型。对于相同的目标标签约束,可以同时学习学生和每个分支。每个分支使用两个损失项进行训练,其中最常用的就是最大交叉熵损失(softmax cross-entropy loss)和蒸馏损失(distillation loss)。
在网络压缩这一步,可以使用深度神经网络方法来解决这个问题。Romero et al.(2015)提出了一种训练薄而深的网络的方法,称为FitNets,用以压缩宽且相对较浅(但实际上仍然很深)的网络。该方法扩展了原来的思想,允许得到更薄、更深的学生模型。为了学习教师网络的中间表示,FitNet让学生模仿老师的完全特征图。然而,这样的假设太过于严格,因为教师和学生的能力可能会有很大的差别。
>>> from transformers import pipeline
# 使用情绪分析流水线
>>> classifier = pipeline('sentiment-analysis')
>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
>>> from transformers import pipeline
# 使用问答流水线
>>> question_answerer = pipeline('question-answering')
>>> question_answerer({
... 'question': 'What is the name of the repository ?',
... 'context': 'Pipeline has been included in the huggingface/transformers repository'
... })
{'score': 0.30970096588134766, 'start': 34, 'end': 58, 'answer': 'huggingface/transformers'}
from transformers import pipeline
classifier = pipeline("sentiment-analysis") # 情感分析
classifier("I've been waiting for a HuggingFace course my whole life.")
# 输出# [{'label': 'POSITIVE', 'score': 0.9598047137260437}]
也可以传几句话:
classifier(
["I've been waiting for a HuggingFace course my whole life.", "I hate this so much!"]
)
# 输出
'''
[{'label': 'POSITIVE', 'score': 0.9598047137260437},
{'label': 'NEGATIVE', 'score': 0.9994558095932007}]
'''
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
from transformers import BertConfig, BertModel
# Building the config
config = BertConfig()
# Building the model from the config
model = BertModel(config)
2)不同的加载方式
from transformers import BertModel
model = BertModel.from_pretrained("bert-base-cased")
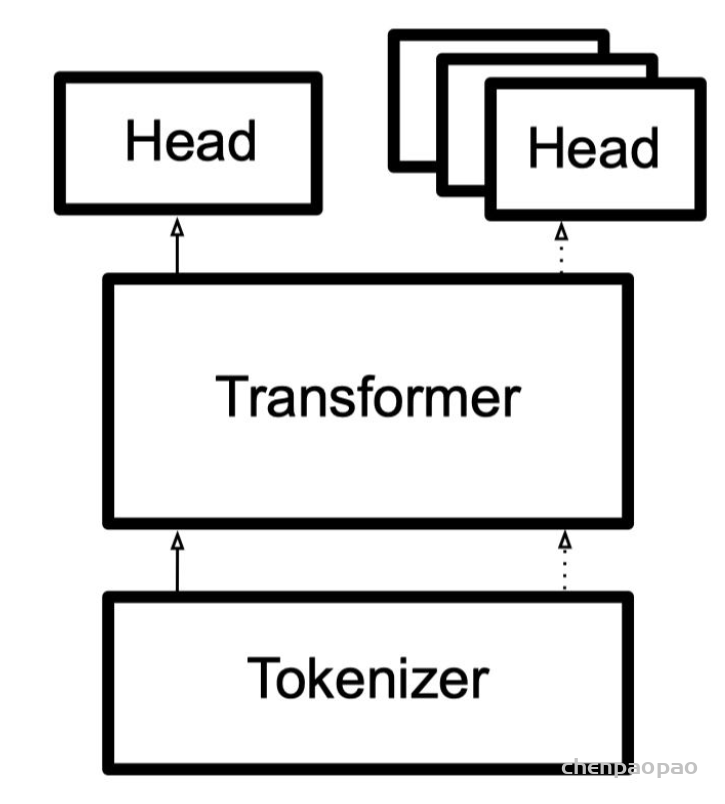
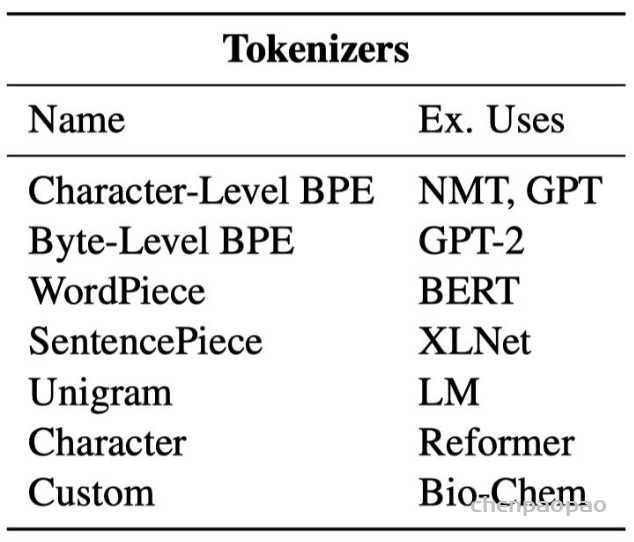
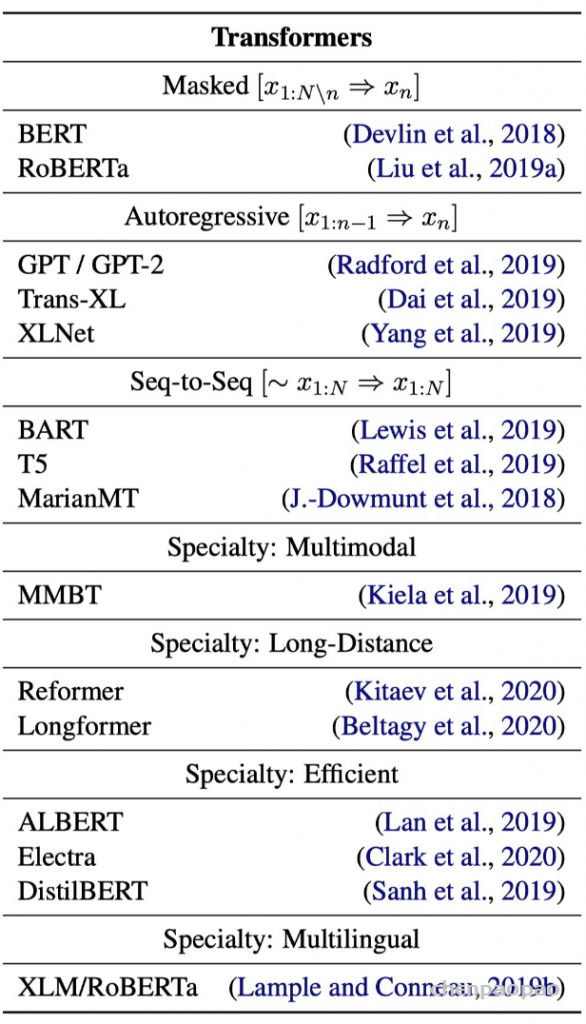
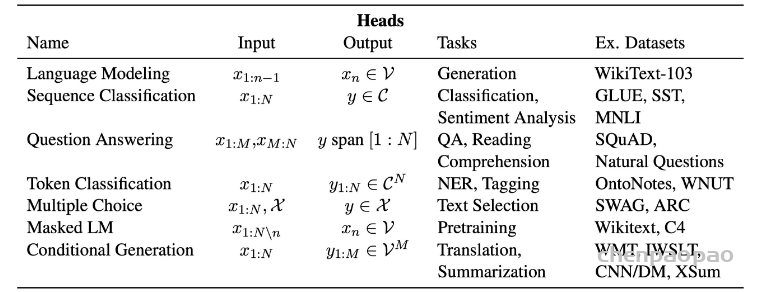
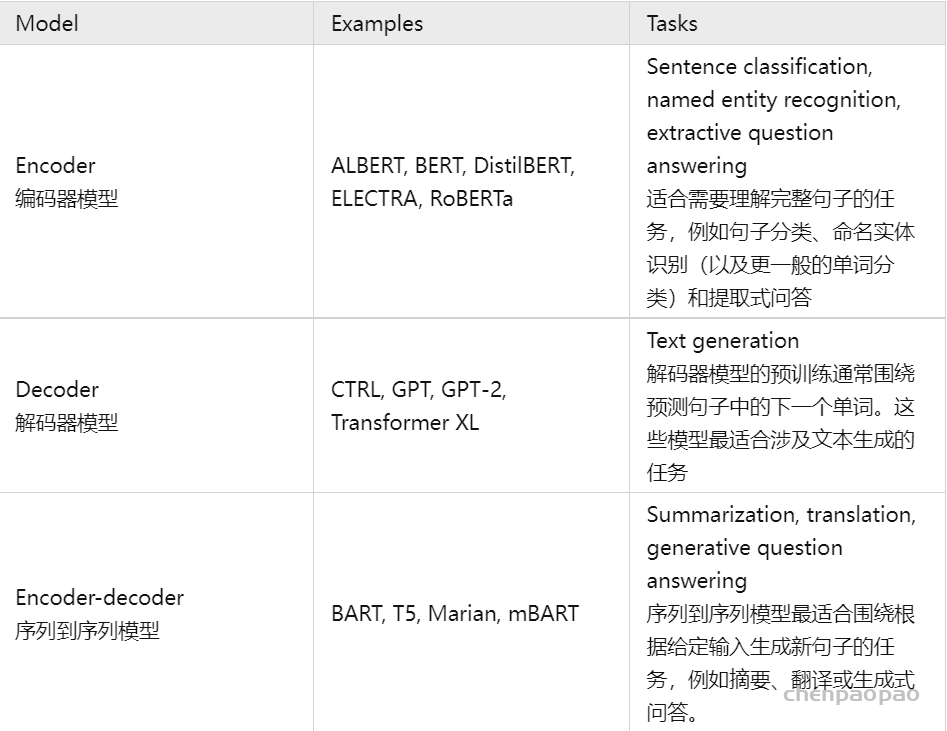
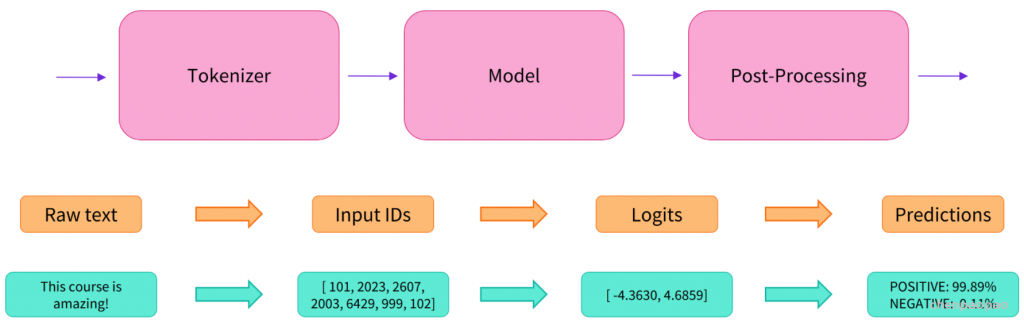
我们已经探索了分词器的工作原理,并研究了分词 tokenizers、转换为输入 ID conversion to input IDs、填充 padding、截断 truncation和注意力掩码 attention masks。Transformers API 可以通过高级函数为我们处理所有这些。
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
# 可以标记单个序列
sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
# 还可以一次处理多个序列
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
model_inputs = tokenizer(sequences)
# 可以根据几个目标进行填充# Will pad the sequences up to the maximum sequence length
model_inputs = tokenizer(sequences, padding="longest")
# Will pad the sequences up to the model max length# (512 for BERT or DistilBERT)
model_inputs = tokenizer(sequences, padding="max_length")
# Will pad the sequences up to the specified max length
model_inputs = tokenizer(sequences, padding="max_length", max_length=8)
# 还可以截断序列
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
# Will truncate the sequences that are longer than the model max length# (512 for BERT or DistilBERT)
model_inputs = tokenizer(sequences, truncation=True)
# Will truncate the sequences that are longer than the specified max length
model_inputs = tokenizer(sequences, max_length=8, truncation=True)
# 可以处理到特定框架张量的转换,然后可以将其直接发送到模型。
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
# Returns PyTorch tensors
model_inputs = tokenizer(sequences, padding=True, return_tensors="pt")
# Returns TensorFlow tensors
model_inputs = tokenizer(sequences, padding=True, return_tensors="tf")
# Returns NumPy arrays
model_inputs = tokenizer(sequences, padding=True, return_tensors="np")
Special tokens
分词器在开头添加特殊词[CLS],在结尾添加特殊词[SEP]。
sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
print(model_inputs["input_ids"])
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
# 输出
'''
[101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102]
[1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012]
'''
print(tokenizer.decode(model_inputs["input_ids"]))
print(tokenizer.decode(ids))
# 输出
'''
"[CLS] i've been waiting for a huggingface course my whole life. [SEP]"
"i've been waiting for a huggingface course my whole life."
'''
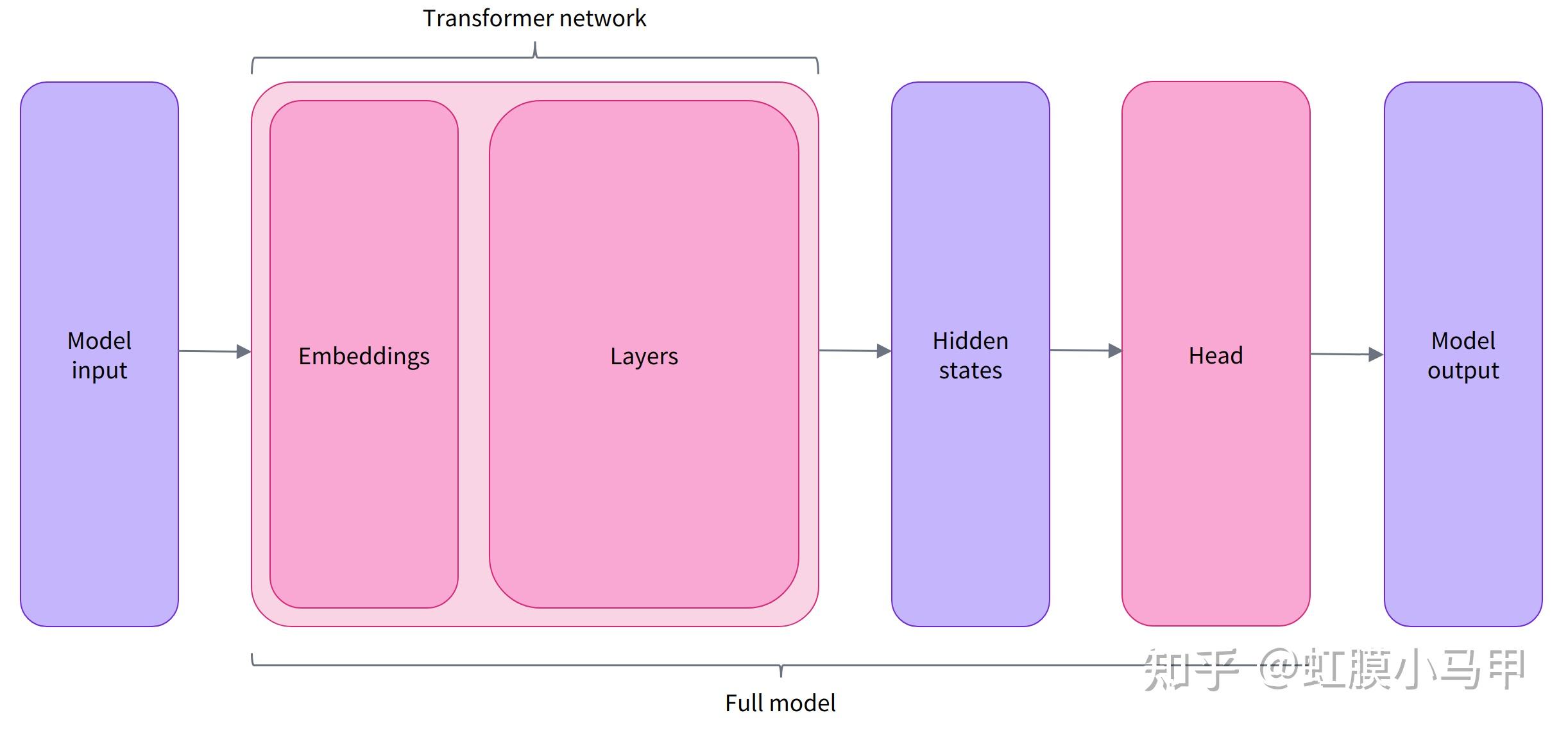
# 总结:从分词器到模型
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
tokens = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
output = model(**tokens)
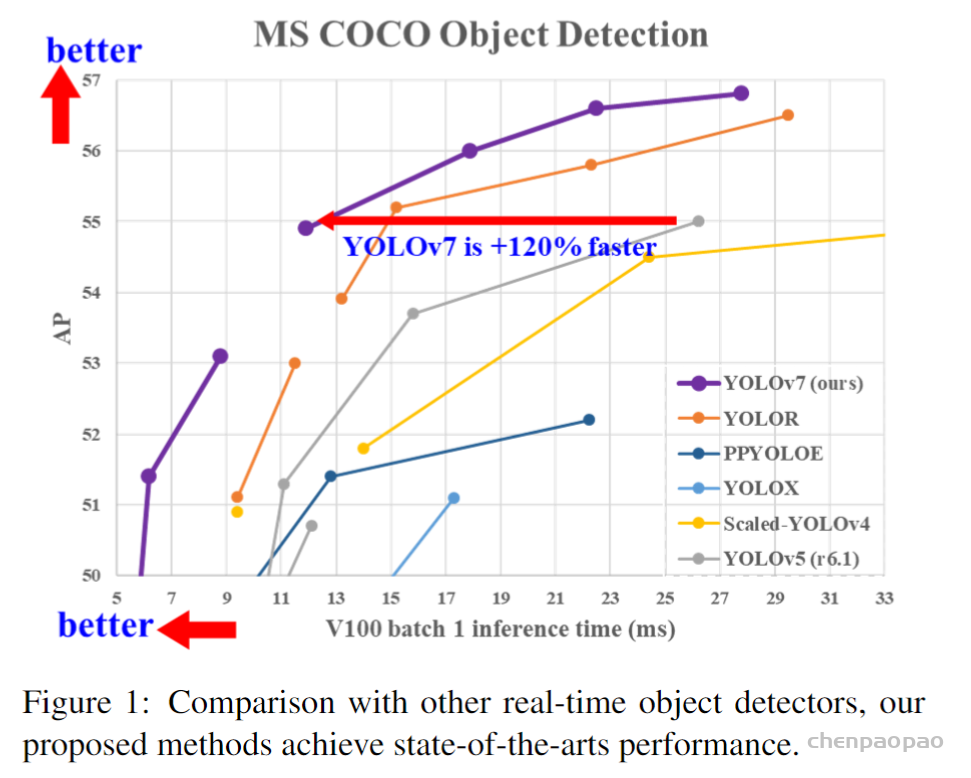
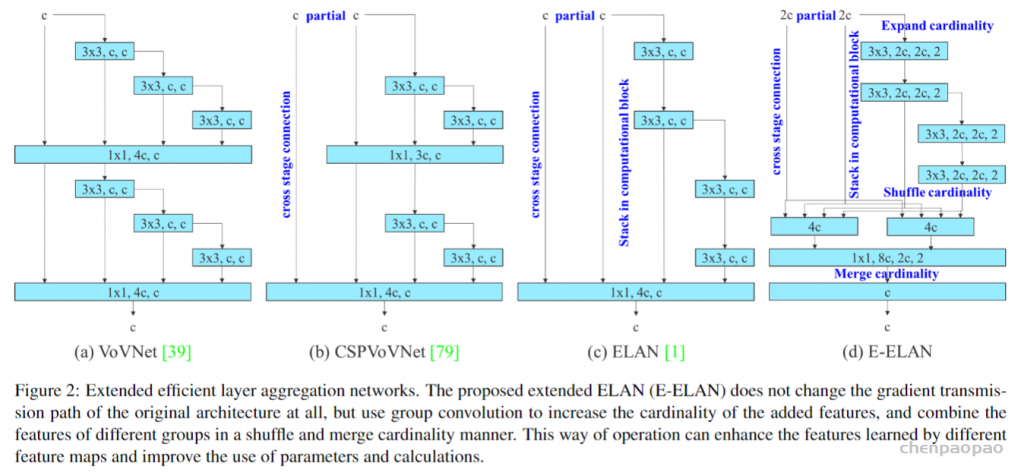
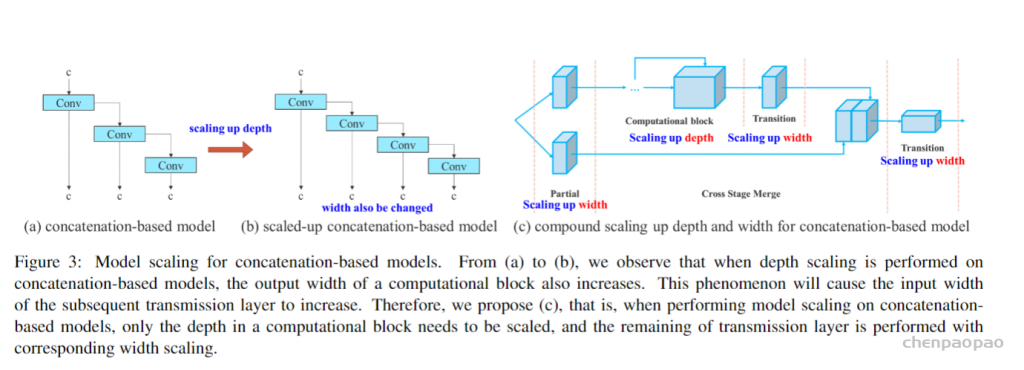
作者为实时探测器提出了“扩展”和“复合缩放”(extend” and “compound scaling”)方法,可以更加高效地利用参数和计算量,同时,作者提出的方法可以有效地减少实时探测器50%的参数,并且具备更快的推理速度和更高的检测精度。(这个其实和YOLOv5或者Scale YOLOv4的baseline使用不同规格分化成几种模型类似,既可以是width和depth的缩放,也可以是module的缩放)
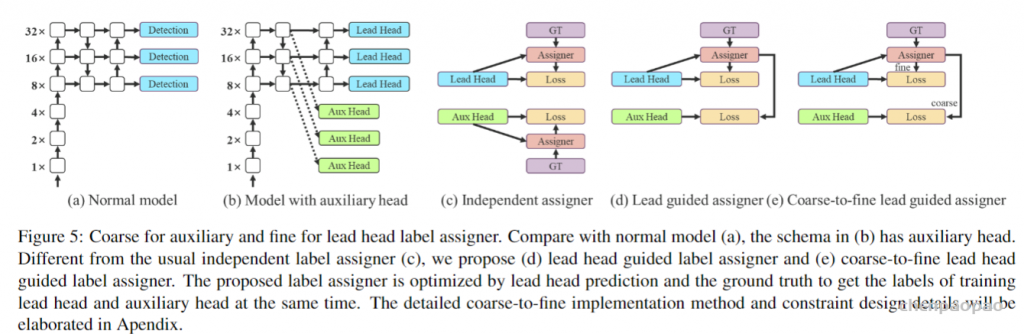
Lead head guided label assigner: 引导头引导“标签分配器”预测结果和ground truth进行计算,并通过优化(在utils/loss.py的SigmoidBin()函数中,传送门:https://github.com/WongKinYiu/yolov7/blob/main/utils/loss.py 生成软标签。这组软标签将作为辅助头和引导头的目标来训练模型。(之前写过一篇博客,【浅谈计算机视觉中的知识蒸馏】]https://zhuanlan.zhihu.com/p/497067556)详细讲过soft label的好处)这样做的目的是使引导头具有较强的学习能力,由此产生的软标签更能代表源数据与目标之间的分布差异和相关性。此外,作者还可以将这种学习看作是一种广义上的余量学习。通过让较浅的辅助头直接学习引导头已经学习到的信息,引导头能更加专注于尚未学习到的残余信息。
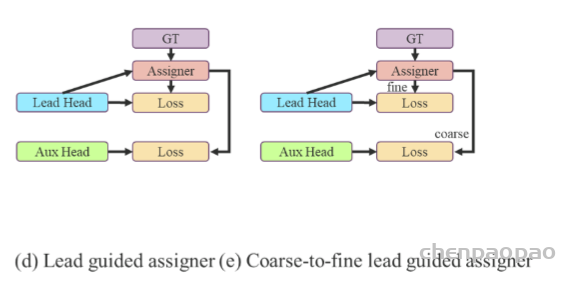
Coarse-to-fine lead head guided label assigner: Coarse-to-fine引导头使用到了自身的prediction和ground truth来生成软标签,引导标签进行分配。然而,在这个过程中,作者生成了两组不同的软标签,即粗标签和细标签,其中细标签与引导头在标签分配器上生成的软标签相同,粗标签是通过降低正样本分配的约束,允许更多的网格作为正目标(可以看下FastestDet的label assigner,不单单只把gt中心点所在的网格当成候选目标,还把附近的三个也算进行去,增加正样本候选框的数量)。原因是一个辅助头的学习能力并不需要强大的引导头,为了避免丢失信息,作者将专注于优化样本召回的辅助头。对于引导头的输出,可以从查准率中过滤出高精度值的结果作为最终输出。然而,值得注意的是,如果粗标签的附加权重接近细标签的附加权重,则可能会在最终预测时产生错误的先验结果。
EMA Model:EMA 是一种在mean teacher中使用的技术,作者使用 EMA 模型作为最终的推理模型。
五、实验
5.1 实验环境
作者为边缘GPU、普通GPU和云GPU设计了三种模型,分别被称为YOLOv7-Tiny、YOLOv7和YOLOv7-W6。同时,还使用基本模型针对不同的服务需求进行缩放,并得到不同大小的模型。对于YOLOv7,可进行颈部缩放(module scale),并使用所提出的复合缩放方法对整个模型的深度和宽度进行缩放(depth and width scale),此方式获得了YOLOv7-X。对于YOLOv7-W6,使用提出的缩放方法得到了YOLOv7-E6和YOLOv7-D6。此外,在YOLOv7-E6使用了提出的E-ELAN,从而完成了YOLOv7-E6E。由于YOLOv7-tincy是一个面向边缘GPU架构的模型,因此它将使用ReLU作为激活函数。作为对于其他模型,使用SiLU作为激活函数。
AP % AP at IoU=0.50:0.05:0.95 (primary challenge metric)
APIoU=.50 % AP at IoU=0.50 (PASCAL VOC metric)
APIoU=.75 % AP at IoU=0.75 (strict metric)
AP Across Scales:
APsmall % AP for small objects: area < 322
APmedium % AP for medium objects: 322 < area < 962
APlarge % AP for large objects: area > 962
Average Recall (AR):
ARmax=1 % AR given 1 detection per image
ARmax=10 % AR given 10 detections per image
ARmax=100 % AR given 100 detections per image
AR Across Scales:
ARsmall % AR for small objects: area < 322
ARmedium % AR for medium objects: 322 < area < 962
ARlarge % AR for large objects: area > 962
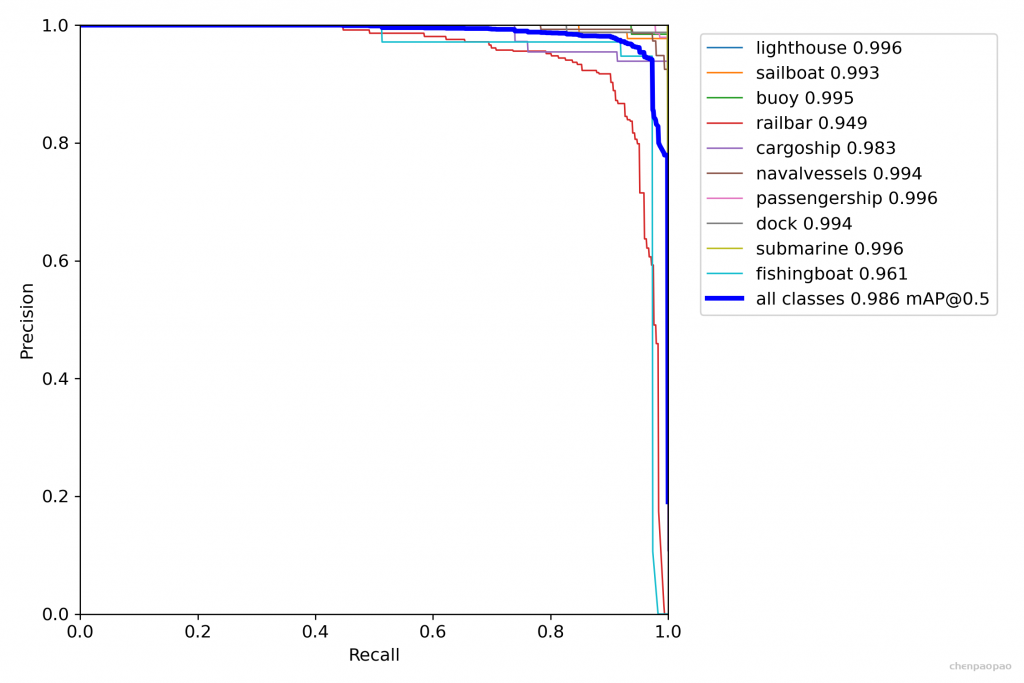
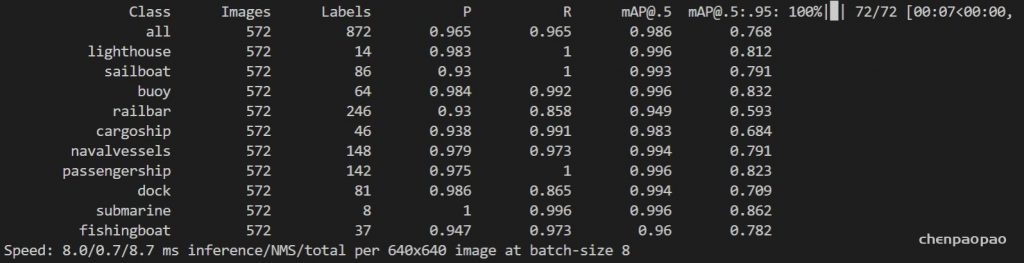
1)除非另有说明,否则AP和AR在多个交汇点(IoU)值上取平均值。具体来说,我们使用10个IoU阈值0.50:0.05:0.95。这是对传统的一个突破,其中AP是在一个单一的0.50的IoU上计算的(这对应于我们的度量APIoU=.50 )。超过均值的IoUs能让探测器更好定位(Averaging over IoUs rewards detectors with better localization.)。
2)AP是所有类别的平均值。传统上,这被称为“平均精确度”(mAP,mean average precision)。我们没有区分AP和mAP(同样是AR和mAR),并假定从上下文中可以清楚地看出差异。

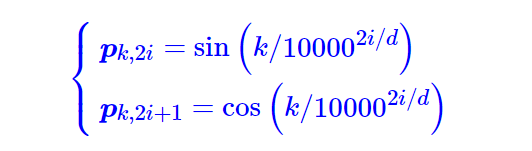









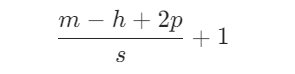
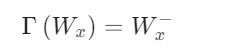





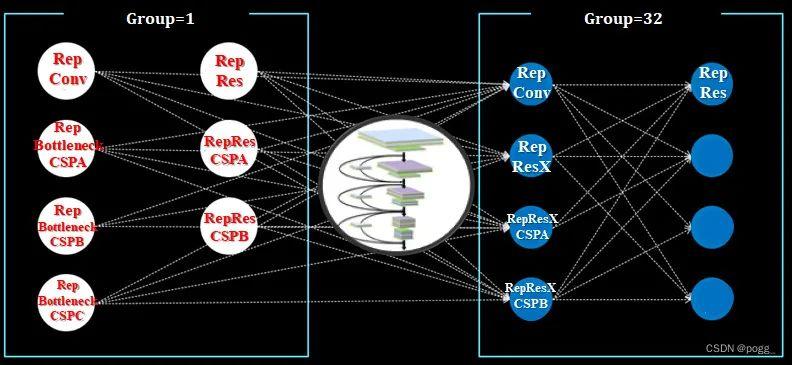
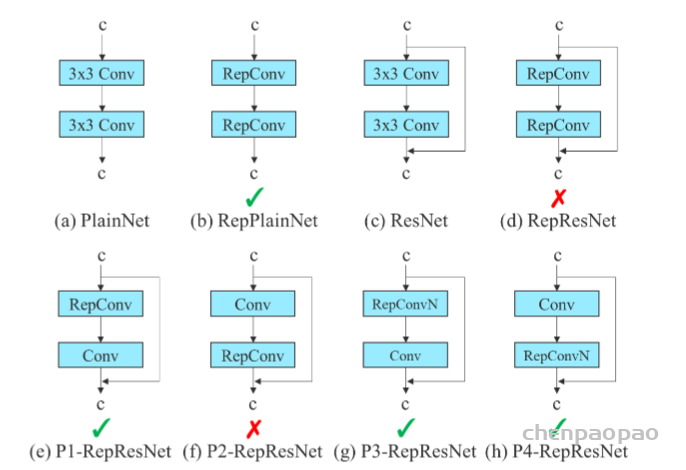




![图3 Rep算子的融合过程[4]](https://p0.meituan.net/travelcube/9f7878c7872787f9b8706b28e5e7c611237315.png)