
自己在浏览 GitHub 过程中,发现的有意思、高质量、容易上手的项目收集起来,这样便于以后查找和学习。

pytorch中与保存和加载模型有关函数有三个:
1.torch.save:将序列化的对象保存到磁盘。此函数使用Python的pickle实用程序进行序列化。使用此功能可以保存各种对象的模型,张量和字典。
2. torch.load:使用pickle的unpickle工具将pickle的对象文件反序列化到内存中。即加载save保存的东西。
3. torch.nn.Module.load_state_dict:使用反序列化的state_dict加载模型的参数字典。注意,这意味着它的传入的参数应该是一个state_dict类型,也就torch.load加载出来的。
# Define model
class TheModelClass(nn.Module):
def __init__(self):
super(TheModelClass, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# Initialize model
model = TheModelClass()
# Initialize optimizer
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# Print model's state_dict
print("Model's state_dict:")
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())
# Print optimizer's state_dict
print("Optimizer's state_dict:")
for var_name in optimizer.state_dict():
print(var_name, "\t", optimizer.state_dict()[var_name]) output:
Model's state_dict:
conv1.weight torch.Size([6, 3, 5, 5])
conv1.bias torch.Size([6])
conv2.weight torch.Size([16, 6, 5, 5])
conv2.bias torch.Size([16])
fc1.weight torch.Size([120, 400])
fc1.bias torch.Size([120])
fc2.weight torch.Size([84, 120])
fc2.bias torch.Size([84])
fc3.weight torch.Size([10, 84])
fc3.bias torch.Size([10])
Optimizer's state_dict:
state {}
param_groups [{'lr': 0.001, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'pa保存模型和加载模型的函数如下:
def save_checkpoint_state(dir,epoch,model,optimizer):
#保存模型
checkpoint = {
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}
if not os.path.isdir(dir):
os.mkdir(dir)
torch.save(checkpoint, os.path.join(dir,'checkpoint-epoch%d.tar'%(epoch)))
def get_checkpoint_state(dir,ckp_name,device,model,optimizer):
# 恢复上次的训练状态
print("Resume from checkpoint...")
checkpoint = torch.load(os.path.join(dir,ckp_name),map_location=device)
model.load_state_dict(checkpoint['model_state_dict'])
epoch=checkpoint['epoch']
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
#scheduler.load_state_dict(checkpoint['scheduler_state_dict'])
print('sucessfully recover from the last state')
return model,epoch,optimizer
如果加入了lr_scheduler,那么lr_scheduler的state_dict也要加进来。
使用时:
# 引用包省略
#保持模型函数
def save_checkpoint_state(epoch, model, optimizer, scheduler, running_loss):
checkpoint = {
"epoch": epoch,
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"scheduler_state_dict": scheduler.state_dict()
}
torch.save(checkpoint, "checkpoint-epoch%d-loss%d.tar" % (epoch, running_loss))
# 加载模型函数
def load_checkpoint_state(path, device, model, optimizer, scheduler):
checkpoint = torch.load(path, map_location=device)
model.load_state_dict(checkpoint["model_state_dict"])
epoch = checkpoint["epoch"]
optimizer.load_state_dict(checkpoint["optimizer_state_dict"])
scheduler.load_state_dict(checkpoint["scheduler_state_dict"])
return model, epoch, optimizer, scheduler
# 是否恢复训练(如果是恢复训练,那么需要设置为true)
resume = False # True
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def train():
trans = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomResizedCrop(512),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomRotation(90),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# get training dataset
leafDiseaseCLS = CustomDataSet(images_path, is_to_ls, trans)
data_loader = DataLoader(leafDiseaseCLS,
batch_size=16,
num_workers=0,
shuffle=True,
pin_memory=False)
# get model
model = EfficientNet.from_pretrained("efficientnet-b3")
# extract the parameter of fully connected layer
fc_features = model._fc.in_features
# modify the number of classes
model._fc = nn.Linear(fc_features, 5)
model.to(device)
# optimizer
optimizer = optim.SGD(model.parameters(),
lr=0.001,
momentum=0.9,
weight_decay=5e-4)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[6, 10], gamma=1/3.)
# loss
#loss_func = nn.CrossEntropyLoss()
loss_func = FocalCosineLoss()
start_epoch = -1
if resume:
model, start_epoch, optimizer,scheduler = load_checkpoint_state("../path/to/checkpoint.tar",
device,
model,
optimizer,
scheduler)
model.train()
epochs = 3
for epoch in range(start_epoch + 1, epochs):
running_loss = 0.0
print("Epoch {}/{}".format(epoch, epochs))
for step, train_data in tqdm(enumerate(data_loader)):
x_train, y_train = train_data
x_train = Variable(x_train.to(device))
y_train = Variable(y_train.to(device))
# forward
prediction = model(x_train)
optimizer.zero_grad()
loss = loss_func(prediction, y_train)
running_loss += loss.item()
# backward
loss.backward()
optimizer.step()
scheduler.step()
# saving model
torch.save(model.state_dict(), str(int(running_loss)) + "_" + str(epoch) + ".pth")
save_checkpoint_state(epoch, model, optimizer, scheduler, running_loss)
print("Loss:{}".format(running_loss))
if __name__ == "__main__":
train()
大多数时候我们需要根据我们的任务调节我们的模型,所以很难保证模型和公开的模型完全一样,但是预训练模型的参数确实有助于提高训练的准确率,为了结合二者的优点,就需要我们加载部分预训练模型。
pretrained_dict = torch.load("model_data/yolo_weights.pth", map_location=device)
model_dict = model.state_dict()
# 将 pretrained_dict 里不属于 model_dict 的键剔除掉
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
#pretrained_dict = {k: v for k, v in pretrained_dict.items() if np.shape(model_dict[k]) == np.shape(v)}
# 更新现有的 model_dict
model_dict.update(pretrained_dict)
# 加载我们真正需要的 state_dict
model.load_state_dict(model_dict)
torch.save(model.state_dict(), PATH)
device = torch.device('cpu')
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH, map_location=device))
torch.save(model.state_dict(), PATH)
device = torch.device("cuda")
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.to(device)
# Make sure to call input = input.to(device) on any input tensors that you feed to the model保存的时候需要将 epoch也保存
代码:实现每隔N个epoch,save模型:
optimizer = torch.optim.SGD(model.parameters(),lr=0.1)
lr_schedule = torch.optim.lr_scheduler.MultiStepLR(optimizer,milestones=[10,20,30,40,50],gamma=0.1)
start_epoch = 9
# print(schedule)
if RESUME:
path_checkpoint = "./model_parameter/test/ckpt_best_50.pth" # 断点路径
checkpoint = torch.load(path_checkpoint) # 加载断点
model.load_state_dict(checkpoint['net']) # 加载模型可学习参数
optimizer.load_state_dict(checkpoint['optimizer']) # 加载优化器参数
start_epoch = checkpoint['epoch'] # 设置开始的epoch
lr_schedule.load_state_dict(checkpoint['lr_schedule'])
for epoch in range(start_epoch+1,80):
optimizer.zero_grad()
optimizer.step()
lr_schedule.step()
if epoch %10 ==0:
print('epoch:',epoch)
print('learning rate:',optimizer.state_dict()['param_groups'][0]['lr'])
checkpoint = {
"net": model.state_dict(),
'optimizer': optimizer.state_dict(),
"epoch": epoch,
'lr_schedule': lr_schedule.state_dict()
}
if not os.path.isdir("./model_parameter/test"):
os.mkdir("./model_parameter/test")
torch.save(checkpoint, './model_parameter/test/ckpt_best_%s.pth' % (str(epoch)))PyTorch时,如果希望通过设置随机数种子,在gpu或cpu上固定每一次的训练结果,则需要在程序执行的开始处添加以下代码:
def setup_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.deterministic = True
# 设置随机数种子
setup_seed(20)
# 预处理数据以及训练模型
# ...
# ...随机数种子seed确定时,不改变程序参数情况下,两次模型的训练结果将始终保持一致。
当我们在训练神经网络时候,学习率作为一个超参数,需要我们指定,如果lr过大,会导致模型不收敛,震荡,而如果lr很小,会导致收敛慢,训练时间长。
一个最普遍的想法,初始时lr设置大一些,随着epoch的增加,lr逐渐下降。
torch.optim.lr_scheduler模块提供了一些根据epoch训练次数来调整学习率(learning rate)的方法
源码:https://pytorch.org/docs/stable/_modules/torch/optim/lr_scheduler.html
torch.optim.lr_scheduler中大部分调整学习率的方法都是根据epoch训练次数,这里介绍常见的几种方法,其他方法以后用到再补充。
要了解每个类的更新策略,可直接查看官网doc中的源码,每类都有个get_lr方法,定义了更新策略
1、torch.optim.lr_scheduler.LambdaLR
>>> # Assuming optimizer has two groups.
>>> lambda1 = lambda epoch: epoch // 30
>>> lambda2 = lambda epoch: 0.95 ** epoch
>>> scheduler = LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()class torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
参数:
list的这样的function,分别计算各个parameter groups的学习率更新用到的λ;更新策略:
new _ l r = λ×initial_lr
其中new_lr是得到的新的学习率,initial_lr是初始的学习率,λ是通过参数lr_lambda和epoch得到的。
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import LambdaLR
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = LambdaLR(optimizer_1, lr_lambda=lambda epoch: 1/(epoch+1))
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.050000
第3个epoch的学习率:0.033333
第4个epoch的学习率:0.025000
第5个epoch的学习率:0.020000
第6个epoch的学习率:0.016667
第7个epoch的学习率:0.014286
第8个epoch的学习率:0.012500
第9个epoch的学习率:0.011111
第10个epoch的学习率:0.010000class torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)

参数:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import StepLR
import itertools
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = StepLR(optimizer_1, step_size=3, gamma=0.1)
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.100000
第3个epoch的学习率:0.100000
第4个epoch的学习率:0.010000
第5个epoch的学习率:0.010000
第6个epoch的学习率:0.010000
第7个epoch的学习率:0.001000
第8个epoch的学习率:0.001000
第9个epoch的学习率:0.001000
第10个epoch的学习率:0.000100class torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
每次遇到milestones中的epoch,做一次更新:

参数:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import MultiStepLR
import itertools
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = MultiStepLR(optimizer_1, milestones=[3, 7], gamma=0.1)
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.100000
第3个epoch的学习率:0.100000
第4个epoch的学习率:0.010000
第5个epoch的学习率:0.010000
第6个epoch的学习率:0.010000
第7个epoch的学习率:0.010000
第8个epoch的学习率:0.001000
第9个epoch的学习率:0.001000
第10个epoch的学习率:0.001000上面的只是一部分,还有很多更新方法,可以在官方源码中查看
https://github.com/zasdfgbnm/TorchSnooper
大家可能遇到这样子的困扰:比如说运行自己编写的 PyTorch 代码的时候,PyTorch 提示你说数据类型不匹配,需要一个 double 的 tensor 但是你给的却是 float;再或者就是需要一个 CUDA tensor, 你给的却是个 CPU tensor。比如下面这种:
RuntimeError: Expected object of scalar type Double but got scalar type Float
这种问题调试起来很麻烦,因为你不知道从哪里开始出问题的。比如你可能在代码的第三行用 torch.zeros 新建了一个 CPU tensor, 然后这个 tensor 进行了若干运算,全是在 CPU 上进行的,一直没有报错,直到第十行需要跟你作为输入传进来的 CUDA tensor 进行运算的时候,才报错。要调试这种错误,有时候就不得不一行行地手写 print 语句,非常麻烦。
再或者,你可能脑子里想象着将一个 tensor 进行什么样子的操作,就会得到什么样子的结果,但是 PyTorch 中途报错说 tensor 的形状不匹配,或者压根没报错但是最终出来的形状不是我们想要的。这个时候,我们往往也不知道是什么地方开始跟我们「预期的发生偏离的」。我们有时候也得需要插入一大堆 print 语句才能找到原因。
TorchSnooper 就是一个设计了用来解决这个问题的工具。TorchSnooper 的安装非常简单,只需要执行标准的 Python 包安装指令就好:
pip install snoop
pip install torchsnooper1、监测函数中的变量:
import torch
import torchsnooper
@torchsnooper.snoop()
def myfunc(mask, x):
y = torch.zeros(6)
y.masked_scatter_(mask, x)
return y
mask = torch.tensor([0, 1, 0, 1, 1, 0], device='cuda')
source = torch.tensor([1.0, 2.0, 3.0], device='cuda')
y = myfunc(mask, source)
Run our script, and we will see:
Starting var:.. mask = tensor<(6,), int64, cuda:0>
Starting var:.. x = tensor<(3,), float32, cuda:0>
21:41:42.941668 call 5 def myfunc(mask, x):
21:41:42.941834 line 6 y = torch.zeros(6)
New var:....... y = tensor<(6,), float32, cpu>
21:41:42.943443 line 7 y.masked_scatter_(mask, x)
21:41:42.944404 exception 7 y.masked_scatter_(mask, x)2、监测for循环中的变量:
with torchsnooper.snoop():
for _ in range(100):
optimizer.zero_grad()
pred = model(x)
squared_diff = (y - pred) ** 2
loss = squared_diff.mean()
print(loss.item())
loss.backward()
optimizer.step()
Part of the trace looks like:
New var:....... x = tensor<(4, 2), float32, cpu>
New var:....... y = tensor<(4,), float32, cpu>
New var:....... model = Model( (layer): Linear(in_features=2, out_features=1, bias=True))
New var:....... optimizer = SGD (Parameter Group 0 dampening: 0 lr: 0....omentum: 0 nesterov: False weight_decay: 0)
22:27:01.024233 line 21 for _ in range(100):
New var:....... _ = 0
22:27:01.024439 line 22 optimizer.zero_grad()
22:27:01.024574 line 23 pred = model(x)
New var:....... pred = tensor<(4, 1), float32, cpu, grad>
22:27:01.026442 line 24 squared_diff = (y - pred) ** 2
New var:....... squared_diff = tensor<(4, 4), float32, cpu, grad>
22:27:01.027369 line 25 loss = squared_diff.mean()
New var:....... loss = tensor<(), float32, cpu, grad>
22:27:01.027616 line 26 print(loss.item())
22:27:01.027793 line 27 loss.backward()
22:27:01.050189 line 28 optimizer.step()https://captum.ai/tutorials/CIFAR_TorchVision_Captum_Insights
可解释性,即理解人工智能模型为什么做出决定的能力,对于开发人员解释模型为什么做出某个决定是很重要的。它可以使人工智能符合监管法律,以应用于需要解释性的业务。
Captum旨在实现AI模型的最新版本,如集成梯度、深度弯曲和传导等等,它可以帮助研究人员和开发人员解释人工智能在多模态环境中做出的决策,并能帮助研究人员把结果与数据库中现有的模型进行比较。

来源:《Verilog数字系统设计(夏宇闻)》
为什么一定要这样做呢?因为要使综合前仿真和综合后仿真一致的缘故。如果不按照上面两个要点来编写Verilog代码,也有可能综合出正确的逻辑,但前后仿真的结果就会不一致。
为了更好地理解上述要点,我们需要对Verilog 语言中的阻塞赋值和非阻塞赋值的功能和执行时间上的差别有深入的了解。为了解释问题方便下面定义两个缩写字:
RHS – 方程式右手方向的表达式或变量可分别缩写为:RHS表达式或RHS变量。
LHS – 方程式左手方向的表达式或变量可分别缩写为:LHS表达式或LHS变量。
IEEE Verilog标准定义了有些语句有确定的执行时间,有些语句没有确定的执行时间。若有两条或两条以上语句准备在同一时刻执行,但由于语句的排列次序不同(而这种排列次序的不同是IEEE Verilog标准所允许的), 却产生了不同的输出结果。这就是造成Verilog模块冒险和竞争现象的原因。为了避免产生竞争,理解阻塞和非阻塞赋值在执行时间上的差别是至关重要的。
阻塞赋值操作符用等号(即 = )表示。为什么称这种赋值为阻塞赋值呢?这是因为在赋值时先计算等号右手方向(RHS)部分的值,这时赋值语句不允许任何别的Verilog语句的干扰,直到现行的赋值完成时刻,即把RHS赋值给 LHS的时刻,它才允许别的赋值语句的执行。
一般可综合的阻塞赋值操作在RHS不能设定有延迟,(即使是零延迟也不允许)。从理论上讲,它与后面的赋值语句只有概念上的先后,而无实质上的延迟。若在RHS 加上延迟,则在延迟期间会阻止赋值语句的执行, 延迟后才执行赋值,这种赋值语句是不可综合的,在需要综合的模块设计中不可使用这种风格的代码。
阻塞赋值的执行可以认为是只有一个步骤的操作:
计算RHS并更新LHS,此时不能允许有来自任何其他Verilog语句的干扰。所谓阻塞的概念是指在同一个always块中,其后面的赋值语句从概念上(即使不设定延迟)是在前一句赋值语句结束后再开始赋值的。
如果在一个过程块中阻塞赋值的RHS变量正好是另一个过程块中阻塞赋值的LHS变量,这两个过程块又用同一个时钟沿触发,这时阻塞赋值操作会出现问题,即如果阻塞赋值的次序安排不好,就会出现竞争。若这两个阻塞赋值操作用同一个时钟沿触发,则执行的次序是无法确定的。下面的例子可以说明这个问题:
[例1]. 用阻塞赋值的反馈振荡器
module fbosc1 (y1, y2, clk, rst);
output y1, y2;
input clk, rst;
reg y1, y2;
always @(posedge clk or posedge rst)
if (rst) y1 = 0; // reset
else y1 = y2;
always @(posedge clk or posedge rst)
if (rst) y2 = 1; // preset
else y2 = y1;
endmodule按照IEEE Verilog 的标准,上例中两个always块是并行执行的,与前后次序无关。如果前一个always块的复位信号先到0时刻,则y1 和y2都会取1,而如果后一个always块的复位信号先到0时刻,则y1 和y2都会取0。这清楚地说明这个Verilog模块是不稳定的会产生冒险和竞争的情况。
非阻塞赋值操作符用小于等于号 (即 <= )表示。为什么称这种赋值为非阻塞赋值?这是因为在赋值操作时刻开始时计算非阻塞赋值符的RHS表达式,赋值操作时刻结束时更新LHS。在计算非阻塞赋值的RHS表达式和更新LHS期间,其他的Verilog语句,包括其他的Verilog非阻塞赋值语句都能同时计算RHS表达式和更新LHS。非阻塞赋值允许其他的Verilog语句同时进行操作。非阻塞赋值的操作可以看作为两个步骤的过程:
非阻塞赋值操作只能用于对寄存器类型变量进行赋值,因此只能用在”initial”块和”always”块等过程块中。非阻塞赋值不允许用于连续赋值。下面的例子可以说明这个问题:
[例2]. 用非阻塞赋值的反馈振荡器
module fbosc2 (y1, y2, clk, rst);
output y1, y2;
input clk, rst;
reg y1, y2;
always @(posedge clk or posedge rst)
if (rst) y1 <= 0; // reset
else y1 <= y2;
always @(posedge clk or posedge rst)
if (rst) y2 <= 1; // preset
else y2 <= y1;
endmodule同样,按照IEEE Verilog 的标准,上例中两个always块是并行执行的,与前后次序无关。无论哪一个always块的复位信号先到, 两个always块中的非阻塞赋值都在赋值开始时刻计算RHS表达式,,而在结束时刻才更新LHS表达式。所以这两个always块在复位信号到来后,在always块结束时 y1为0而y2为1是确定的。从用户的角度看这两个非阻塞赋值正好是并行执行的。
Verilog模块编程要点:
下面我们还将对阻塞和非阻塞赋值做进一步解释并将举更多的例子来说明这个问题。在此之前,掌握可综合风格的Verilog模块编程的八个原则会有很大的帮助。在编写时牢记这八个要点可以为绝大多数的Verilog用户解决在综合后仿真中出现的90-100% 的冒险竞争问题。
Verilog的新用户在彻底搞明白这两种赋值功能差别之前,一定要牢记这几条要点。照着要点来编写Verilog模块程序,就可省去很多麻烦。

摘自:https://blog.csdn.net/alangaixiaoxiao/article/details/105533746
网上的资源很多,也有很多博主的原理讲解。在这里推荐几个资源:
darknet官网:https://pjreddie.com/darknet/yolo/ linux系统
github上基于VS的工程:https://github.com/AlexeyAB/darknet
github上带有注释的工程:https://github.com/hgpvision/darknet
Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,首先将输入图片resize到448×448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。
YOLO 的核心思想就是利用整张图作为网络的输入,直接在输出层回归 bounding box(边界框) 的位置及其所属的类别。将一幅图像分成 SxS 个网格(grid cell),如果某个 object 的中心落在这个网格中,则这个网格就负责预测这个 object。

每个 bounding box 要预测 (x, y, w, h) 和 confidence 共5个值,每个网格还要预测一个类别信息,记为 C 类。则 SxS个 网格,每个网格要预测 B 个 bounding box, 每个box中都有 C 个 classes对应的概率值。输出就是 S x S x B x(5+C) 的一个 tensor。
注意:class 信息是针对每个网格的,confidence 信息是针对每个 bounding box 的。
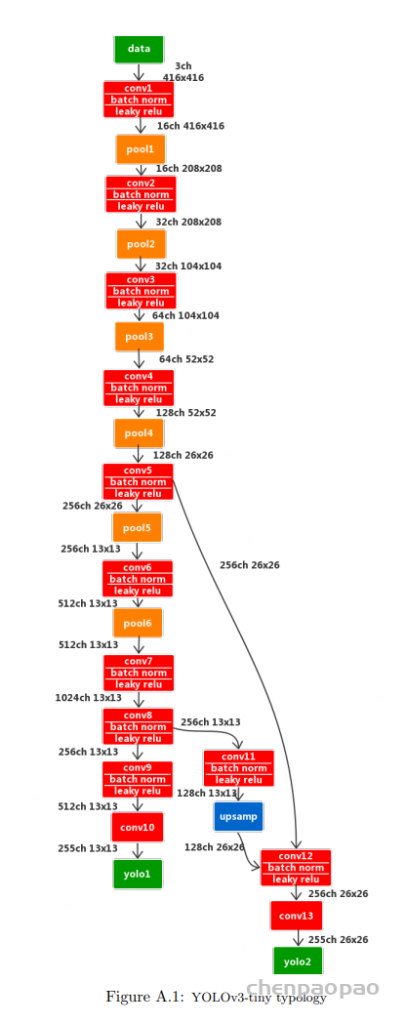
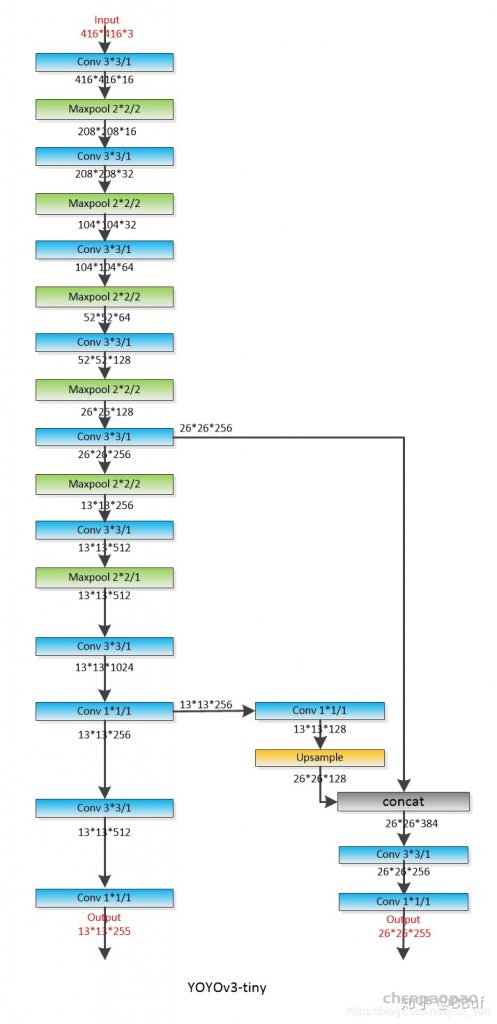
yolov3-tiny中,共有两个输出层(yolo层),分别为13×13和26×26,每个网格可以预测3个bounding box,共有80个分类数。所以最后的yolo层的尺寸为:13x13x255和26x26x255。
yolov3-tiny网络层结构如下:
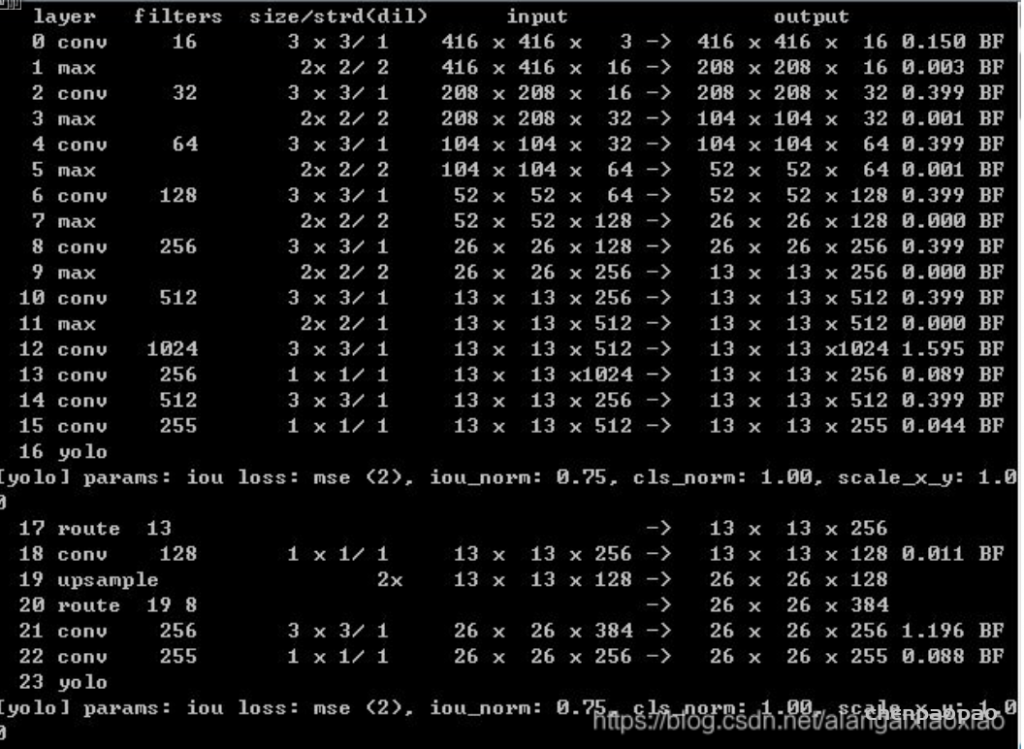
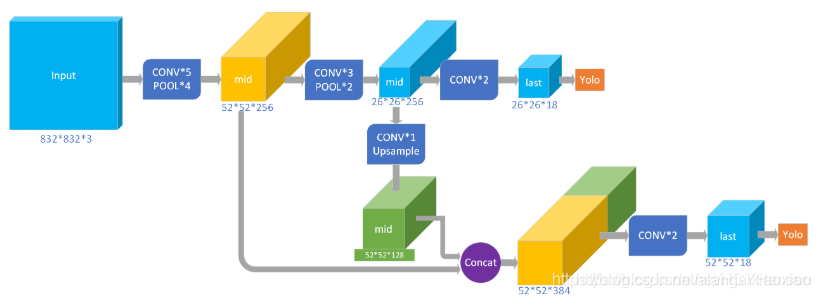
可以看出,yolov3-tiny共有23层网络,其中包含五种不同的网络层:卷积层convolutional(13个),池化层maxpool(6个),路由层route(2个),上采样层upsample(1个),输出层yolo(2个)。Yolov3-tiny中,除了Yolo层之前的那个卷积层,每个卷积层之后都有BN层,且每个卷积层之后都有激活函数LEAKY(yolo层之前是linear)。
yolov3-tiny前向传播主要在detector.c中的test_detector函数中完成:
/** 本函数是检测模型的一个前向推理测试函数.
* @param datacfg 数据集信息文件路径(也即cfg/*.data文件),文件中包含有关数据集的信息,比如cfg/coco.data
* @param cfgfile 网络配置文件路径(也即cfg/*.cfg文件),包含一个网络所有的结构参数,比如cfg/yolo.cfg
* @param weightfile 已经训练好的网络权重文件路径,比如darknet网站上下载的yolo.weights文件
* @param filename 待进行检测的图片路径(单张图片)
* @param thresh 阈值,类别检测概率大于该阈值才认为其检测结果有效
* @param hier_thresh
* @param outfile
* @param fullscreen
* @details 该函数为一个前向推理测试函数,不包括训练过程,因此如果要使用该函数,必须提前训练好网络,并加载训练好的网络参数文件,
* 这些文件可以在作者网站上根据作者的提示下载到。本函数由darknet.c中的主函数调用,严格来说,本文件不应纳入darknet网络结构文件夹中,
* 其只是一个测试文件,或者说是一个example,应该放入到example文件夹中(新版的darknet已经这样做了,可以在github上查看)。
* 本函数的流程为:.
*/
void test_detector(char *datacfg, char *cfgfile, char *weightfile, char *filename, float thresh,
float hier_thresh, int dont_show, int ext_output, int save_labels, char *outfile, int letter_box, int benchmark_layers)
{
// 从指定数据文件datacfg(.data文件)中读入数据信息(测试、训练数据信息)到options中
// options是list类型数据,其中的node包含的void指针具体是kvp数据类型,具有键值和值(类似C++中的Map)
list *options = read_data_cfg(datacfg);
// 获取数据集的名称(包括路径),第二个参数"names"表明要从options中获取所用数据集的名称信息(如names = data/coco.names)
char *name_list = option_find_str(options, "names", "data/names.list");
int names_size = 0;
// 从data/**.names中读取物体名称/标签信息
char **names = get_labels_custom(name_list, &names_size); //get_labels(name_list);
// 加载data/labels/文件夹中所有的字符标签图片
image **alphabet = load_alphabet();
network net = parse_network_cfg_custom(cfgfile, 1, 1); // set batch=1 配置各网络层参数,重要
在parser.c中的parse_network_cfg_custom函数中,根据yolov3-tiny.cfg文件对网络结构进行配置,明确各层网络的类型、输入输出通道数、图像尺寸、卷积核大小等。
//配置各网络层参数
network parse_network_cfg_custom(char *filename, int batch, int time_steps)
{
// 从神经网络结构参数文件中读入所有神经网络层的结构参数,存储到sections中,
// sections的每个node包含一层神经网络的所有结构参数
list *sections = read_cfg(filename);
// 获取sections的第一个节点,可以查看一下cfg/***.cfg文件,其实第一块参数(以[net]开头)不是某层神经网络的参数,
// 而是关于整个网络的一些通用参数,比如学习率,衰减率,输入图像宽高,batch大小等,
// 具体的关于某个网络层的参数是从第二块开始的,如[convolutional],[maxpool]...,
// 这些层并没有编号,只说明了层的属性,但层的参数都是按顺序在文件中排好的,读入时,
// sections链表上的顺序就是文件中的排列顺序。
node *n = sections->front;
if(!n) error("Config file has no sections");
// 创建网络结构并动态分配内存:输入网络层数为sections->size - 1,sections的第一段不是网络层,而是通用网络参数
network net = make_network(sections->size - 1);
// 所用显卡的卡号(gpu_index在cuda.c中用extern关键字声明)
// 在调用parse_network_cfg()之前,使用了cuda_set_device()设置了gpu_index的值号为当前活跃GPU卡号
net.gpu_index = gpu_index;
// size_params结构体元素不含指针变量
size_params params;
if (batch > 0) params.train = 0; // allocates memory for Detection only
else params.train = 1; // allocates memory for Detection & Training
section *s = (section *)n->val;
list *options = s->options;
if(!is_network(s)) error("First section must be [net] or [network]");
parse_net_options(options, &net);
#ifdef GPU
printf("net.optimized_memory = %d \n", net.optimized_memory);
if (net.optimized_memory >= 2 && params.train) {
pre_allocate_pinned_memory((size_t)1024 * 1024 * 1024 * 8); // pre-allocate 8 GB CPU-RAM for pinned memory
}
#endif // GPU
params.h = net.h;
params.w = net.w;
params.c = net.c;
params.inputs = net.inputs;
if (batch > 0) net.batch = batch;
if (time_steps > 0) net.time_steps = time_steps;
if (net.batch < 1) net.batch = 1;
if (net.time_steps < 1) net.time_steps = 1;
if (net.batch < net.time_steps) net.batch = net.time_steps;
params.batch = net.batch;
params.time_steps = net.time_steps;
params.net = net;
printf("mini_batch = %d, batch = %d, time_steps = %d, train = %d \n", net.batch, net.batch * net.subdivisions, net.time_steps, params.train);
int avg_outputs = 0;
float bflops = 0;
size_t workspace_size = 0;
size_t max_inputs = 0;
size_t max_outputs = 0;
n = n->next;
int count = 0;
free_section(s);
// 此处stderr不是错误提示,而是输出结果提示,提示网络结构
fprintf(stderr, " layer filters size/strd(dil) input output\n");
while(n){
params.index = count;
fprintf(stderr, "%4d ", count);
s = (section *)n->val;
options = s->options;
// 定义网络层
layer l = { (LAYER_TYPE)0 };
// 获取网络层的类别
LAYER_TYPE lt = string_to_layer_type(s->type);
//通过读取网络类型,从而配置各网络层的参数
if(lt == CONVOLUTIONAL){//yolov3-tiny 卷积层 13层
l = parse_convolutional(options, params);
}else if(lt == LOCAL){
l = parse_local(options, params);
}else if(lt == ACTIVE){
l = parse_activation(options, params);
}else if(lt == RNN){
l = parse_rnn(options, params);
}else if(lt == GRU){
l = parse_gru(options, params);
}else if(lt == LSTM){
l = parse_lstm(options, params);
}else if (lt == CONV_LSTM) {
l = parse_conv_lstm(options, params);
}else if(lt == CRNN){
l = parse_crnn(options, params);
}else if(lt == CONNECTED){
l = parse_connected(options, params);
}else if(lt == CROP){
l = parse_crop(options, params);
}else if(lt == COST){
l = parse_cost(options, params);
l.keep_delta_gpu = 1;
}else if(lt == REGION){
l = parse_region(options, params);
l.keep_delta_gpu = 1;
}else if (lt == YOLO) {//yolov3-tiny YOLO层 两层
l = parse_yolo(options, params);
l.keep_delta_gpu = 1;
}else if (lt == GAUSSIAN_YOLO) {
l = parse_gaussian_yolo(options, params);
l.keep_delta_gpu = 1;
}else if(lt == DETECTION){
l = parse_detection(options, params);
}else if(lt == SOFTMAX){
l = parse_softmax(options, params);
net.hierarchy = l.softmax_tree;
l.keep_delta_gpu = 1;
}else if(lt == NORMALIZATION){
l = parse_normalization(options, params);
}else if(lt == BATCHNORM){
l = parse_batchnorm(options, params);
}else if(lt == MAXPOOL){//yolov3-tiny 池化层 maxpool 6层
l = parse_maxpool(options, params);
}else if (lt == LOCAL_AVGPOOL) {
l = parse_local_avgpool(options, params);
}else if(lt == REORG){
l = parse_reorg(options, params); }
else if (lt == REORG_OLD) {
l = parse_reorg_old(options, params);
}else if(lt == AVGPOOL){
l = parse_avgpool(options, params);
}else if(lt == ROUTE){//yolov3-tiny 路由层 2层
l = parse_route(options, params);
int k;
for (k = 0; k < l.n; ++k) {
net.layers[l.input_layers[k]].use_bin_output = 0;
net.layers[l.input_layers[k]].keep_delta_gpu = 1;
}
}else if (lt == UPSAMPLE) {//yolov3-tiny 上采样层 1层
l = parse_upsample(options, params, net);
}else if(lt == SHORTCUT){
l = parse_shortcut(options, params, net);
net.layers[count - 1].use_bin_output = 0;
net.layers[l.index].use_bin_output = 0;
net.layers[l.index].keep_delta_gpu = 1;
}else if (lt == SCALE_CHANNELS) {
l = parse_scale_channels(options, params, net);
net.layers[count - 1].use_bin_output = 0;
net.layers[l.index].use_bin_output = 0;
net.layers[l.index].keep_delta_gpu = 1;
}
else if (lt == SAM) {
l = parse_sam(options, params, net);
net.layers[count - 1].use_bin_output = 0;
net.layers[l.index].use_bin_output = 0;
net.layers[l.index].keep_delta_gpu = 1;
}else if(lt == DROPOUT){
l = parse_dropout(options, params);
l.output = net.layers[count-1].output;
l.delta = net.layers[count-1].delta;
.........
在parser.c的load_weights_upto中,根据卷积层的网络配置,开始下载读取各层的权重文件。
//读取权重文件函数
void load_weights_upto(network *net, char *filename, int cutoff)//cutoff = net->n
{
#ifdef GPU
if(net->gpu_index >= 0){
cuda_set_device(net->gpu_index);
}
#endif
fprintf(stderr, "Loading weights from %s...\n", filename);
fflush(stdout);
FILE *fp = fopen(filename, "rb");
if(!fp) file_error(filename);
int major;
int minor;
int revision;
fread(&major, sizeof(int), 1, fp);//读取一个4字节的数据
fread(&minor, sizeof(int), 1, fp);//读取一个4字节的数据
fread(&revision, sizeof(int), 1, fp);//读取一个4字节的数据
printf("the size of int in x64 is %d bytes,attention!!!\n", sizeof(int));//x86 x64: 4
printf("major ,minor,revision of weight is %d, %d ,%d\n", major, minor, revision);//0.2.0
if ((major * 10 + minor) >= 2) {//运行这一部分
printf("\n seen 64");
uint64_t iseen = 0;
fread(&iseen, sizeof(uint64_t), 1, fp);//读取一个8字节的数据
printf("the size of uint64_t is %d\n", sizeof(uint64_t));
*net->seen = iseen;
}
else {
printf("\n seen 32");
uint32_t iseen = 0;
fread(&iseen, sizeof(uint32_t), 1, fp);
*net->seen = iseen;
}
*net->cur_iteration = get_current_batch(*net);
printf(", trained: %.0f K-images (%.0f Kilo-batches_64) \n", (float)(*net->seen / 1000), (float)(*net->seen / 64000));
int transpose = (major > 1000) || (minor > 1000);
int i;
for(i = 0; i < net->n && i < cutoff; ++i){//cutoff = net->n
layer l = net->layers[i];
if (l.dontload) continue;//always 0 跳过之后的循环体,直接运行++i
if(l.type == CONVOLUTIONAL && l.share_layer == NULL){ //只运行这一个分支的代码
load_convolutional_weights(l, fp);
//printf("network layer [%d] is CONVOLUTIONAL \n",i);
}
.......
在读取yolov3-tiny各层权重文件前,先读取4个和训练有关的参数:major,minor, revision和iseen。在前向传播的工程当中,并没有实际的应用。
parser.c中的load_convolutional_weights函数,具体执行对yolov3-tiny权重文件的下载,包括节点参数weight,偏置参数bias和批量归一化参数BN。
void load_convolutional_weights(layer l, FILE *fp)
{
static int flipped_num;
if(l.binary){
//load_convolutional_weights_binary(l, fp);
//return;
}
int num = l.nweights;
//int num = l.n*l.c*l.size*l.size;//l.n 输出的层数 l.c输入的层数
int read_bytes;
read_bytes = fread(l.biases, sizeof(float), l.n, fp);//读取偏置参数 l.n个float数据
if (read_bytes > 0 && read_bytes < l.n) printf("\n Warning: Unexpected end of wights-file! l.biases - l.index = %d \n", l.index);
//fread(l.weights, sizeof(float), num, fp); // as in connected layer
if (l.batch_normalize && (!l.dontloadscales)){
read_bytes = fread(l.scales, sizeof(float), l.n, fp);//读取batch normalize 参数 l.n个float数据
if (read_bytes > 0 && read_bytes < l.n) printf("\n Warning: Unexpected end of wights-file! l.scales - l.index = %d \n", l.index);
read_bytes = fread(l.rolling_mean, sizeof(float), l.n, fp);//读取batch normalize 参数 l.n个float数据
if (read_bytes > 0 && read_bytes < l.n) printf("\n Warning: Unexpected end of wights-file! l.rolling_mean - l.index = %d \n", l.index);
read_bytes = fread(l.rolling_variance, sizeof(float), l.n, fp);//读取batch normalize 参数 l.n个float数据
if (read_bytes > 0 && read_bytes < l.n) printf("\n Warning: Unexpected end of wights-file! l.rolling_variance - l.index = %d \n", l.index);
yolov3-tiny每个卷积层之后,激活函数之前,都要对结果进行Batch Normalization: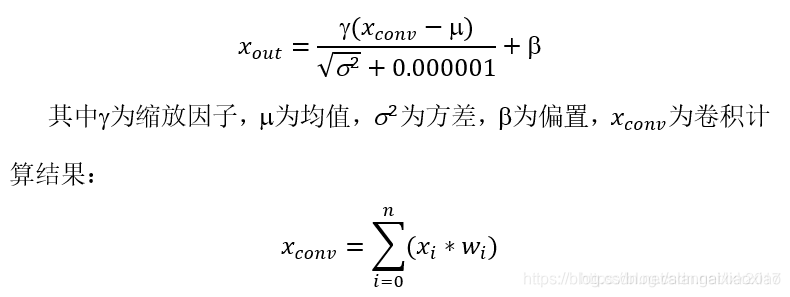
由于BN层和卷积操作都是线性的,将权重文件进行批量归一化,可以代替卷积层之后的BN层:
在network.c的fuse_conv_batchnorm函数中实现权重文件和BN层的合并。
void fuse_conv_batchnorm(network net)
{
int j;
for (j = 0; j < net.n; ++j) {
layer *l = &net.layers[j];
// printf("the %d layer batch_normalize is %d, groups is %d \n", j, l->batch_normalize, l->groups);
if (l->type == CONVOLUTIONAL) { //只运行这一分支 合并卷积层和batch_normal
//printf(" Merges Convolutional-%d and batch_norm \n", j);
if (l->share_layer != NULL) {//l->share_layer always is 0,不运行这个分支
l->batch_normalize = 0;
}
if (l->batch_normalize) {//#15,22层卷积,卷积之后没有batch normalize,其他都要运行这一分支
int f;
for (f = 0; f < l->n; ++f)//该层神经网络 1->n 个输出层权重
{
l->biases[f] = l->biases[f] - (double)l->scales[f] * l->rolling_mean[f] / (sqrt((double)l->rolling_variance[f] + .00001));
const size_t filter_size = l->size*l->size*l->c / l->groups;//kernel_size * kernel_size * c/分组 l->groups存在于卷积层always is 1
int i;
for (i = 0; i < filter_size; ++i) {
int w_index = f*filter_size + i;
l->weights[w_index] = (double)l->weights[w_index] * l->scales[f] / (sqrt((double)l->rolling_variance[f] + .00001));
}
}
free_convolutional_batchnorm(l);//no use
l->batch_normalize = 0;
......
yolov3-tiny输入神经网络的图像尺寸为416×416,对不符合该尺寸的图像,要进行裁剪。在image.c的resize_image函数中完成。这个可以说是整个yolo算法对输入图像唯一进行预处理的地方了。这也是yolo算法在工程应用中极好的地方,没有那么多类似于降噪、滤波之类的预处理,直接送到网络里就完事了。
//im:输入图片 w:416 h:416
//函数作用:将输入图片热size到416x416的尺寸,基本按照缩放/扩大的策略
image resize_image(image im, int w, int h)
{
if (im.w == w && im.h == h) return copy_image(im);
image resized = make_image(w, h, im.c);//416 x 416 x 3空的地址空间
image part = make_image(w, im.h, im.c);//416 x im.h x im.c空的地址空间
int r, c, k;
float w_scale = (float)(im.w - 1) / (w - 1);//宽度缩放因子
float h_scale = (float)(im.h - 1) / (h - 1);//高度缩放因子
for(k = 0; k < im.c; ++k){
for(r = 0; r < im.h; ++r){
for(c = 0; c < w; ++c){//416
float val = 0;
if(c == w-1 || im.w == 1){//c =415 最后一列
val = get_pixel(im, im.w-1, r, k);//取原图片最后一列的像素
} else {
float sx = c*w_scale;
int ix = (int) sx;
float dx = sx - ix;
val = (1 - dx) * get_pixel(im, ix, r, k) + dx * get_pixel(im, ix+1, r, k);
}
set_pixel(part, c, r, k, val);
}
}
}
for(k = 0; k < im.c; ++k){
for(r = 0; r < h; ++r){
float sy = r*h_scale;
int iy = (int) sy;
float dy = sy - iy;
for(c = 0; c < w; ++c){
float val = (1-dy) * get_pixel(part, c, iy, k);
set_pixel(resized, c, r, k, val);
}
if(r == h-1 || im.h == 1) continue;
for(c = 0; c < w; ++c){
float val = dy * get_pixel(part, c, iy+1, k);
add_pixel(resized, c, r, k, val);
}
}
}
free_image(part);
return resized;
}
network.c中的forward_network函数是整个神经网络的核心部分,各层的网络都在函数指针l.forward(l, state)中完成。
void forward_network(network net, network_state state)
{
state.workspace = net.workspace;
int i;
/// 遍历所有层,从第一层到最后一层,逐层进行前向传播(网络总共有net.n层)
for(i = 0; i < net.n; ++i){
state.index = i;/// 置网络当前活跃层为当前层,即第i层
layer l = net.layers[i];/// 获取当前层
if(l.delta && state.train){//不执行此分支的代码
/// 如果当前层的l.delta已经动态分配了内存,则调用fill_cpu()函数,将其所有元素的值初始化为0
scal_cpu(l.outputs * l.batch, 0, l.delta, 1);/// 第一个参数为l.delta的元素个数,第二个参数为初始化值,为0
printf("forward_network scal_cpu of %d layer done!\n ", i);
}
//double time = get_time_point();
l.forward(l, state);//进行卷积运算,激活函数,池化运算/
//if layer_type = convolutional ; l.forward = forward_convolutional_layer;
//if layer_type = maxpool l.forward = forward_maxpool_layer;
//if layer_type = yolo l.forward = forward_yolo_layer;
//if layer_type = ROUTE l.forward = forward_route_layer;其实就是数据的复制和搬移
//if layer_type = upsample l.forward = forward_upsample_layer;;
//printf("%d - Predicted in %lf milli-seconds.\n", i, ((double)get_time_point() - time) / 1000);
/// 完成某一层的推理时,置网络的输入为当前层的输出(这将成为下一层网络的输入),要注意的是,此处是直接更改指针变量net.input本身的值,
/// 也就是此处是通过改变指针net.input所指的地址来改变其中所存内容的值,并不是直接改变其所指的内容而指针所指的地址没变,
/// 所以在退出forward_network()函数后,其对net.input的改变都将失效,net.input将回到进入forward_network()之前时的值。
......
卷积层在convolutional_layer.c中的forward_convolutional_layer函数实现。
void forward_convolutional_layer(convolutional_layer l, network_state state)
{
int out_h = convolutional_out_height(l);//获得本层卷积层输出特征图的高、宽
int out_w = convolutional_out_width(l);
int i, j;
// l.outputs = l.out_h * l.out_w * l.out_c在make各网络层函数中赋值(比如make_convolutional_layer()),
// 对应每张输入图片的所有输出特征图的总元素个数(每张输入图片会得到n也即l.out_c张特征图)
// 初始化输出l.output全为0.0;输入l.outputs*l.batch为输出的总元素个数,其中l.outputs为batch
// 中一个输入对应的输出的所有元素的个数,l.batch为一个batch输入包含的图片张数;0表示初始化所有输出为0;
fill_cpu(l.outputs*l.batch, 0, l.output, 1);//将地址l.output,l.outputs*l.batch个float地址空间的数据初始化0
.......
作者在进行卷积运算前,将输入特征图进行重新排序:
```c
void im2col_cpu(float* data_im,
int channels, int height, int width,
int ksize, int stride, int pad, float* data_col)
{
int c,h,w;
// 计算该层神经网络的输出图像尺寸(其实没有必要再次计算的,因为在构建卷积层时,make_convolutional_layer()函数
// 已经调用convolutional_out_width(),convolutional_out_height()函数求取了这两个参数,
// 此处直接使用l.out_h,l.out_w即可,函数参数只要传入该层网络指针就可了,没必要弄这么多参数)
int height_col = (height + 2*pad - ksize) / stride + 1;
int width_col = (width + 2*pad - ksize) / stride + 1;
/// 卷积核大小:ksize*ksize是一个卷积核的大小,之所以乘以通道数channels,是因为输入图像有多通道,每个卷积核在做卷积时,
/// 是同时对同一位置处多通道的图像进行卷积运算,这里为了实现这一目的,将三通道上的卷积核并在一起以便进行计算,因此卷积核
/// 实际上并不是二维的,而是三维的,比如对于3通道图像,卷积核尺寸为3*3,该卷积核将同时作用于三通道图像上,这样并起来就得
/// 到含有27个元素的卷积核,且这27个元素都是独立的需要训练的参数。所以在计算训练参数个数时,一定要注意每一个卷积核的实际
/// 训练参数需要乘以输入通道数。
int channels_col = channels * ksize * ksize;//输入通道
// 外循环次数为一个卷积核的尺寸数,循环次数即为最终得到的data_col的总行数
for (c = 0; c < channels_col; ++c) {
//行,列偏置都是对应着本次循环要操作的输出位置的像素而言的,通道偏置,是该位置像素所在的输出通道的绝对位置(通道数)
// 列偏移,卷积核是一个二维矩阵,并按行存储在一维数组中,利用求余运算获取对应在卷积核中的列数,比如对于
// 3*3的卷积核(3通道),当c=0时,显然在第一列,当c=5时,显然在第2列,当c=9时,在第二通道上的卷积核的第一列,
// 当c=26时,在第三列(第三输入通道上)
int w_offset = c % ksize;//0,1,2
// 行偏移,卷积核是一个二维的矩阵,且是按行(卷积核所有行并成一行)存储在一维数组中的,
// 比如对于3*3的卷积核,处理3通道的图像,那么一个卷积核具有27个元素,每9个元素对应一个通道上的卷积核(互为一样),
// 每当c为3的倍数,就意味着卷积核换了一行,h_offset取值为0,1,2,对应3*3卷积核中的第1, 2, 3行
int h_offset = (c / ksize) % ksize;//0,1,2
// 通道偏移,channels_col是多通道的卷积核并在一起的,比如对于3通道,3*3卷积核,每过9个元素就要换一通道数,
// 当c=0~8时,c_im=0;c=9~17时,c_im=1;c=18~26时,c_im=2,操作对象是排序后的像素位置
int c_im = c / ksize / ksize;
// 中循环次数等于该层输出图像行数height_col,说明data_col中的每一行存储了一张特征图,这张特征图又是按行存储在data_col中的某行中
for (h = 0; h < height_col; ++h) {
// 内循环等于该层输出图像列数width_col,说明最终得到的data_col总有channels_col行,height_col*width_col列
for (w = 0; w < width_col; ++w) {
// 由上面可知,对于3*3的卷积核,行偏置h_offset取值为0,1,2,当h_offset=0时,会提取出所有与卷积核第一行元素进行运算的像素,
// 依次类推;加上h*stride是对卷积核进行行移位操作,比如卷积核从图像(0,0)位置开始做卷积,那么最先开始涉及(0,0)~(3,3)
// 之间的像素值,若stride=2,那么卷积核进行一次行移位时,下一行的卷积操作是从元素(2,0)(2为图像行号,0为列号)开始
int im_row = h_offset + h * stride;//yolov3-tiny stride = 1
// 对于3*3的卷积核,w_offset取值也为0,1,2,当w_offset取1时,会提取出所有与卷积核中第2列元素进行运算的像素,
// 实际在做卷积操作时,卷积核对图像逐行扫描做卷积,加上w*stride就是为了做列移位,
// 比如前一次卷积其实像素元素为(0,0),若stride=2,那么下次卷积元素起始像素位置为(0,2)(0为行号,2为列号)
int im_col = w_offset + w * stride;
// col_index为重排后图像中的像素索引,等于c * height_col * width_col + h * width_col +w(还是按行存储,所有通道再并成一行),
// 对应第c通道,h行,w列的元素
int col_index = (c * height_col + h) * width_col + w;//将重排后的图片像素,按照左上->右下的顺序,计算一维索引
//im_col + width*im_row + width*height*channel 重排前的特征图在内存中的位置索引
// im2col_get_pixel函数获取输入图像data_im中第c_im通道,im_row,im_col的像素值并赋值给重排后的图像,
// height和width为输入图像data_im的真实高、宽,pad为四周补0的长度(注意im_row,im_col是补0之后的行列号,
// 不是真实输入图像中的行列号,因此需要减去pad获取真实的行列号)
data_col[col_index] = im2col_get_pixel(data_im, height, width, channels,
im_row, im_col, c_im, pad);
// return data_im[im_col + width*im_row + width*height*channel)];
}
}
}
}
通过gemm进行卷积乘加操作,通过add_bias添加偏置。
//进行卷积的乘加运算,没有bias偏置参数参与运算;
gemm(0, 0, m, n, k, 1, a, k, b, n, 1, c, n);
add_bias(l.output, l.biases, l.batch, l.n, out_h*out_w);//每个输出特征图的元素都加上对应通道的偏置参数
maxpool_layer.c中的forward_maxpool_layer函数完成池化操作。yolov3-tiny保留了池化层,并使用最大值池化,将尺寸为2×2的核中最大值保留下来。
void forward_maxpool_layer_avx(float *src, float *dst, int *indexes, int size, int w, int h, int out_w, int out_h, int c,
int pad, int stride, int batch)
{
const int w_offset = -pad / 2;
const int h_offset = -pad / 2;
int b, k;
for (b = 0; b < batch; ++b) {
// 对于每张输入图片,将得到通道数一样的输出图,以输出图为基准,按输出图通道,行,列依次遍历
// (这对应图像在l.output的存储方式,每张图片按行铺排成一大行,然后图片与图片之间再并成一行)。
// 以输出图为基准进行遍历,最终循环的总次数刚好覆盖池化核在输入图片不同位置进行池化操作。
#pragma omp parallel for
for (k = 0; k < c; ++k) {
int i, j, m, n;
for (i = 0; i < out_h; ++i) {
//for (j = 0; j < out_w; ++j) {
j = 0;
for (; j < out_w; ++j) {
// out_index为输出图中的索引
int out_index = j + out_w*(i + out_h*(k + c*b));//j + out_w * i + out_w * iout_h * k
float max = -FLT_MAX;// FLT_MAX为c语言中float.h定义的对大浮点数,此处初始化最大元素值为最小浮点数
int max_i = -1;// 最大元素值的索引初始化为-1
// 下面两个循环回到了输入图片,计算得到的cur_h以及cur_w都是在当前层所有输入元素的索引,内外循环的目的是找寻输入图像中,
// 以(h_offset + i*l.stride, w_offset + j*l.stride)为左上起点,尺寸为l.size池化区域中的最大元素值max及其在所有输入元素中的索引max_i
for (n = 0; n < size; ++n) {//2
for (m = 0; m < size; ++m) {//2
// cur_h,cur_w是在所有输入图像中第k通道中的cur_h行与cur_w列,index是在所有输入图像元素中的总索引。
// 为什么这里少一层对输入通道数的遍历循环呢?因为对于最大池化层来说输入与输出通道数是一样的,并在上面的通道数循环了!
int cur_h = h_offset + i*stride + n;
int cur_w = w_offset + j*stride + m;
int index = cur_w + w*(cur_h + h*(k + b*c));
// 边界检查:正常情况下,是不会越界的,但是如果有补0操作,就会越界了,这里的处理方式是直接让这些元素值为-FLT_MAX
// (注意虽然称之为补0操作,但实际不是补0),总之,这些补的元素永远不会充当最大元素值。
int valid = (cur_h >= 0 && cur_h < h &&
cur_w >= 0 && cur_w < w);
float val = (valid != 0) ? src[index] : -FLT_MAX;
// 记录这个池化区域中的最大的元素值及其在所有输入元素中的总索引
max_i = (val > max) ? index : max_i;
max = (val > max) ? val : max;
}
}
// 由此得到最大池化层每一个输出元素值及其在所有输入元素中的总索引。
// 为什么需要记录每个输出元素值对应在输入元素中的总索引呢?因为在下面的反向过程中需要用到,在计算当前最大池化层上一层网络的敏感度时,
// 需要该索引明确当前层的每个元素究竟是取上一层输出(也即上前层输入)的哪一个元素的值,具体见下面backward_maxpool_layer()函数的注释。
dst[out_index] = max;
if (indexes) indexes[out_index] = max_i;
}
}
}
}
}
yolov3-tiny中共有两层路由层。第17层路由层(从0层开始),其实直接将第13层网络的输出结果输入。第20层路由层,将第19层和第8层网络结果合并在一起,19层在前,8层在后。在route_layer.c中的forward_route_layer函数中实现。
void forward_route_layer(const route_layer l, network_state state)
{
int i, j;
int offset = 0;
for(i = 0; i < l.n; ++i){//l.n: 卷积层:输出特征图通道数 路由层:有几层网络层输入本层 17层:1(路由第13层) 20:2(路由第19、8层)
int index = l.input_layers[i];//输入本网络层的网络层的索引:如13,19,8
float *input = state.net.layers[index].output;//输入等于 之前网络层索引值得输出(.output)
int input_size = l.input_sizes[i];//输入的网络层的数据量
int part_input_size = input_size / l.groups;//未分组
for(j = 0; j < l.batch; ++j){
//copy_cpu(input_size, input + j*input_size, 1, l.output + offset + j*l.outputs, 1);
//从首地址input处复制input_size 个数据到 l.output中
copy_cpu(part_input_size, input + j*input_size + part_input_size*l.group_id, 1, l.output + offset + j*l.outputs, 1);//l.group_id = 0
//其实就是copy_cpu(part_input_size, input, 1, l.output + offset, 1);
}
//offset += input_size;
offset += part_input_size;
}
}
yolov3-tiny中第19层是上采样层,将18层13x13x128的输入特征图转变为26x26x128的输出特征图。在upsample_layer.c中的forward_upsample_layer函数中完成。
void upsample_cpu(float *in, int w, int h, int c, int batch, int stride, int forward, float scale, float *out)
{
int i, j, k, b;
for (b = 0; b < batch; ++b) {
for (k = 0; k < c; ++k) {
for (j = 0; j < h*stride; ++j) {
for (i = 0; i < w*stride; ++i) {
int in_index = b*w*h*c + k*w*h + (j / stride)*w + i / stride;
int out_index = b*w*h*c*stride*stride + k*w*h*stride*stride + j*w*stride + i;
if (forward) out[out_index] = scale*in[in_index];
else in[in_index] += scale*out[out_index];
}
}
}
}
}
上采样效果:
yolo层完成了对13x13x255和26x26x255输入特诊图的logistic逻辑回归计算。每个box的预测宽度和高度不参与逻辑回归,在yolo_layer.c中的forward_yolo_layer函数中完成。
//两个yolo层 只对数据进行了logistic处理,并没有预测box的位置
//将0-1通道(x,y) 4-84(confidence+class)计算logistic,三个prior(预测框都是这样)
void forward_yolo_layer(const layer l, network_state state)
{
int i, j, b, t, n;
//从state.input复制数据到l.output
memcpy(l.output, state.input, l.outputs*l.batch * sizeof(float));
#ifndef GPU
printf("yolo v3 tiny l.n and l.batch of yolo layer is %d and %d \n ",l.n,l.batch);
for (b = 0; b < l.batch; ++b) {//l.batch = 1
for (n = 0; n < l.n; ++n) {//l.n:3(yolo层)mask 0,1,2 表示每个网络单元预测三个box?
//printf("l.coords is %d in yolov3 tiny yolo layer ,l.scale_x_y is %f \n", l.coords, l.scale_x_y);
// l.coords 坐标:0 l.classes分类数量:80 l.scale_x_y:1
//l.w:输入特征图宽度 l.h输出特征图高度
int index = entry_index(l, b, n*l.w*l.h, 0);//index = n*l.w*l.h*(4 + l.classes + 1)
//起始地址为:l.output + index 个数为:2 * l.w*l.h 计算逻辑回归值,并保存
activate_array(l.output + index, 2 * l.w*l.h, LOGISTIC); // x,y,
//起始地址为:l.output + index 个数为:2 * l.w*l.h 计算方式为:x = x*l.scale_x_y + -0.5*(l.scale_x_y - 1) 简化后:x = x
//yolov3-tiny l.scale_x_y = 1 实际上该函数没有参与任何的运算 scal_add_cpu
scal_add_cpu(2 * l.w*l.h, l.scale_x_y, -0.5*(l.scale_x_y - 1), l.output + index, 1); // scale x,y
//
index = entry_index(l, b, n*l.w*l.h, 4);//index = n*l.w*l.h*(4 + l.classes + 1)+ 4*l.w*l.h
//起始地址为:l.output + index,个数为:(1+80)*l.w*l.h 计算器其逻辑回归值
activate_array(l.output + index, (1 + l.classes)*l.w*l.h, LOGISTIC);
}
}
//w:输入图像宽度640,不一定是416 h:输入图像高度424,不一定是416 thresh:图像置信度阈值0.25 hier:0.5
//map:0 relative:1 num:0 letter:0
//函数作用:统计两个yolo层中 置信度大于阈值的box个数,并对这个box初始化一段地址空间 dets
//根据网络来填充该地址空间dets:
//根据yolo层 计算满足置信度阈值要求的box相对的预测坐标、宽度和高度,并将结果保存在dets[count].bbox结构体中
//每个box有80个类别,有一个置信度,该类别对应的可能性prob:class概率*置信度
///舍弃prob小于阈值0.25的box
//将满足阈值的box个数保存到num中
detection *get_network_boxes(network *net, int w, int h, float thresh, float hier, int *map, int relative, int *num, int letter)
{
//printf("w、h、thresh、hier and letter is %d 、%d 、%f 、%f and %d\n", w, h, thresh, hier, letter);
//函数作用:统计两个yolo层中 置信度大于阈值的box个数,并对这个box初始化一段地址空间 dets
//将满足阈值的box个数保存到num中
detection *dets = make_network_boxes(net, thresh, num);
//根据网络来填充该地址空间dets:
//根据yolo层 计算满足置信度阈值要求的box相对的预测坐标、宽度和高度,并将结果保存在dets[count].bbox结构体中
//每个box有80个类别,有一个置信度,该类别对应的可能性prob:class概率*置信度
///舍弃prob小于阈值0.25的box
fill_network_boxes(net, w, h, thresh, hier, map, relative, dets, letter);
return dets;
}
使用make_network_boxes来创建预测信息的指针变量:
// thresh: 置信度阈值
//num: 0
//函数作用:统计置信度大于阈值的box个数,并对这个box初始化一段地址空间
detection *make_network_boxes(network *net, float thresh, int *num)
{
layer l = net->layers[net->n - 1];//应该是神经网络最后一层 net->n:24 最后一层yolo层
//printf(" net->n of network is %d\n " ,(net->n));
int i;
// -thresh 0.25
//yolo层:yolov3-tiny中共有两层
//三个prior预测框,对每个预测框中,置信度大于thresh 0.25,记为一次,将次数进行累加,并输出
//nboxes:即为要保留的box的个数 两个yolo层中的置信度个数一起累加
int nboxes = num_detections(net, thresh);//-thresh 0.25
if (num) {
printf("nbox = %d \n", num);
*num = nboxes;//不执行该语句
}
//申请内存,个数为nboxes,每个内存大小为:sizeof(detection)
detection* dets = (detection*)xcalloc(nboxes, sizeof(detection));
//遍历每个box,每个dets.prob申请80个float类型的内存:
//dets.uc,申请4个float类型的空间:位置信息
for (i = 0; i < nboxes; ++i) {
dets[i].prob = (float*)xcalloc(l.classes, sizeof(float));
// tx,ty,tw,th uncertainty
dets[i].uc = (float*)xcalloc(4, sizeof(float)); // Gaussian_YOLOv3
if (l.coords > 4) {//不执行这个分支 l.coords:0
dets[i].mask = (float*)xcalloc(l.coords - 4, sizeof(float));
}
}
return dets;
}
使用get_yolo_detections来统计两层yolo层的预测信息:
//w,h:640,424 netw, neth:416,416 thresh:图像置信度阈值0.25 hier:0.5
//map:0 relative:1 letter:0
//根据yolo层 计算满足置信度阈值要求的box相对的预测坐标、宽度和高度,并将结果保存在dets[count].bbox结构体中
//每个box有80个类别,有一个置信度,该类别对应的可能性prob:class概率*置信度
///舍弃prob小于阈值0.25的box
int get_yolo_detections(layer l, int w, int h, int netw, int neth, float thresh, int *map, int relative, detection *dets, int letter)
{
printf("\n l.batch = %d, l.w = %d, l.h = %d, l.n = %d ,netw = %d, neth = %d \n", l.batch, l.w, l.h, l.n, netw, neth);
int i,j,n;
float *predictions = l.output;//yolo层的输出
// This snippet below is not necessary
// Need to comment it in order to batch processing >= 2 images
//if (l.batch == 2) avg_flipped_yolo(l);
int count = 0;
//printf("yolo layer l.mask[0] is %d, l.mask[1] is %d, l.mask[2] is %d\n", l.mask[0], l.mask[1], l.mask[2]);
//printf("yolo layer l.biases[l.mask[0]*2] is %f, l.biases[l.mask[1]*2] is %f, l.biases[l.mask[2]*2] is %f\n", l.biases[l.mask[0] * 2], l.biases[l.mask[1] * 2], l.biases[l.mask[2] * 2]);
//遍历yolo层
for (i = 0; i < l.w*l.h; ++i){//该yolo层输出特征图的宽度、高度:13x13 26x26
int row = i / l.w;
int col = i % l.w;
for(n = 0; n < l.n; ++n){//yolo层,l.n = 3
//obj_index:置信度层索引
int obj_index = entry_index(l, 0, n*l.w*l.h + i, 4);//obj_index = n*l.w*l.h*(4+l.classes+1) + 4*l.w*l.h + i;
float objectness = predictions[obj_index];//获得对应的置信度
//if(objectness <= thresh) continue; // incorrect behavior for Nan values
if (objectness > thresh) {//只有置信度大于阈值才开始执行该分支
//printf("\n objectness = %f, thresh = %f, i = %d, n = %d \n", objectness, thresh, i, n);
//box_index:yolo层每个像素点有三个box,表示每个box的索引值
int box_index = entry_index(l, 0, n*l.w*l.h + i, 0);//box_index = n*l.w*l.h*(4+l.classes+1)+ i;
//l.biases->偏置参数起始地址 l.mask[n]:分别为3,4,5,0,1,2,biases偏置参数偏移量
//根据yolo层 计算满足置信度阈值要求的box相对的预测坐标、宽度和高度,并将结果保存在dets[count].bbox结构体中
dets[count].bbox = get_yolo_box(predictions, l.biases, l.mask[n], box_index, col, row, l.w, l.h, netw, neth, l.w*l.h);
//获取对应的置信度,该置信度经过了logistic
dets[count].objectness = objectness;
//获得分类数:80(int类型)
dets[count].classes = l.classes;
for (j = 0; j < l.classes; ++j) {
//80个类别,每个类别对应的概率,class_index为其所在层的索引
int class_index = entry_index(l, 0, n*l.w*l.h + i, 4 + 1 + j);//class_index = n*l.w*l.h*(4+l.classes+1) + (4+1+j)*l.w*l.h + i;
//每个box有80个类别,有一个置信度,该类别对应的可能性prob:class概率*置信度
float prob = objectness*predictions[class_index];
//舍弃prob小于阈值0.25的box
dets[count].prob[j] = (prob > thresh) ? prob : 0;
}
++count;
}
}
}
correct_yolo_boxes(dets, count, w, h, netw, neth, relative, letter);
return count;
}
//dets:box结构体 nboxes:满足阈值的box个数 l.classe:80 thresh=0.45f
//两个box,同一类别进行非极大值抑制,遍历
void do_nms_sort(detection *dets, int total, int classes, float thresh)
{
int i, j, k;
k = total - 1;
for (i = 0; i <= k; ++i) {//box个数
if (dets[i].objectness == 0) {//置信度==0 不执行该分支,理论上没有objectness = 0
printf("there is no objectness == 0 !!! \n");
detection swap = dets[i];
dets[i] = dets[k];
dets[k] = swap;
--k;
--i;
}
}
total = k + 1;
//同一类别进行比较
for (k = 0; k < classes; ++k) {//80个
//box预测的类别
for (i = 0; i < total; ++i) {//box个数
dets[i].sort_class = k;
}
//函数作用:将prob较大的box排列到前面
qsort(dets, total, sizeof(detection), nms_comparator_v3);
for (i = 0; i < total; ++i) {//两个box,同一类别进行非极大值抑制
//printf(" k = %d, \t i = %d \n", k, i);
if (dets[i].prob[k] == 0) continue;
box a = dets[i].bbox;
for (j = i + 1; j < total;++j){
box b = dets[j].bbox;
if( box_iou(a, b) > thresh) dets[j].prob[k] = 0;
}
}
}
}
device = “xcvu3p-ffvc1517-2-e”
参考:
https://thedatabus.io/convolver
https://github.com/sumanth-kalluri/cnn_hardware_acclerator_for_fpga
YOLOv3 的剪枝量化:
https://github.com/coldlarry/YOLOv3-complete-pruning
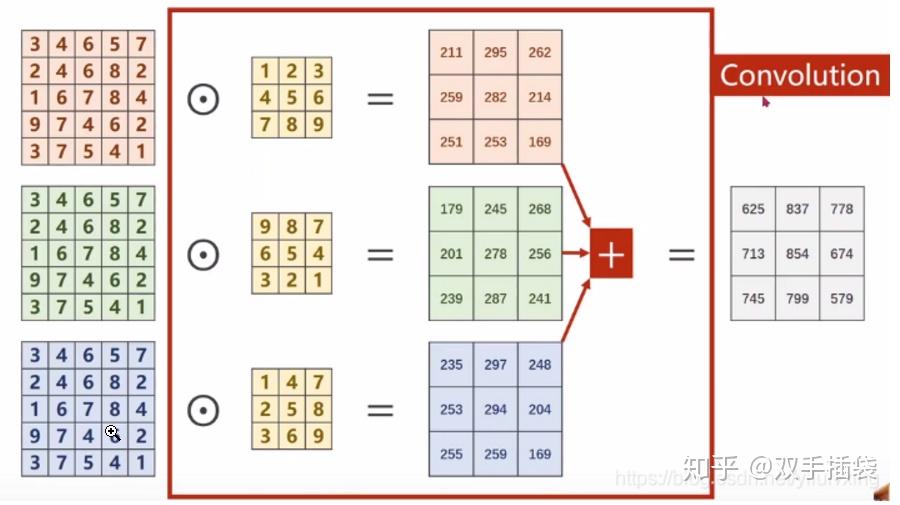
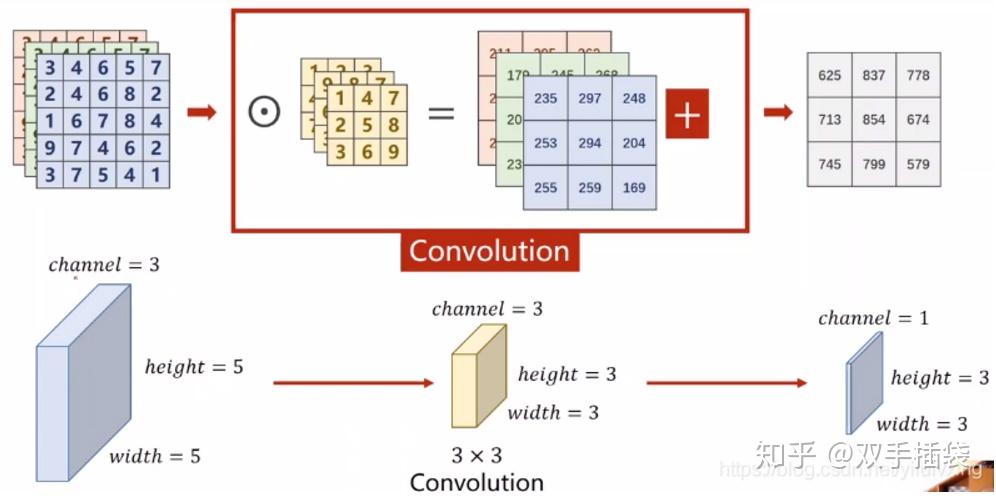
输出为单个通道:上述过程中,每一个卷积核的通道数量,必须要求与输入通道数量一致,因为要对每一个通道的像素值要进行卷积运算,所以每一个卷积核的通道数量必须要与输入通道数量保持一致
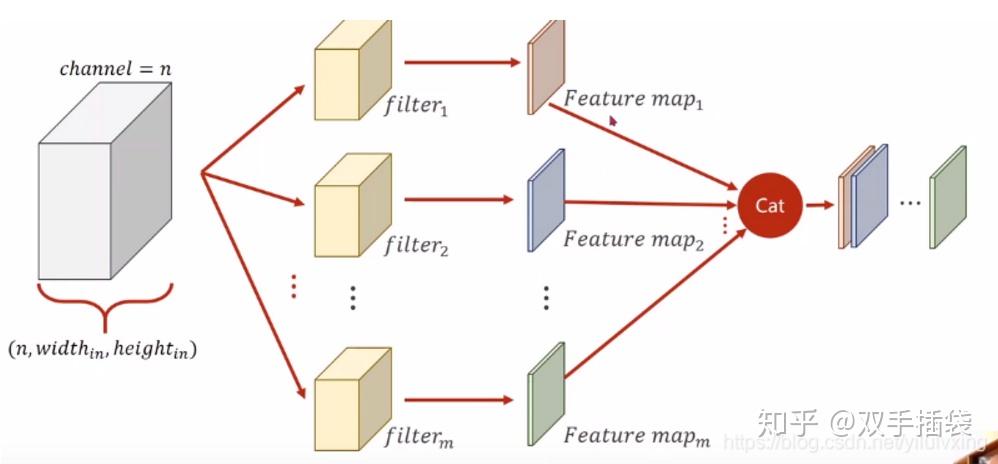
多通道:
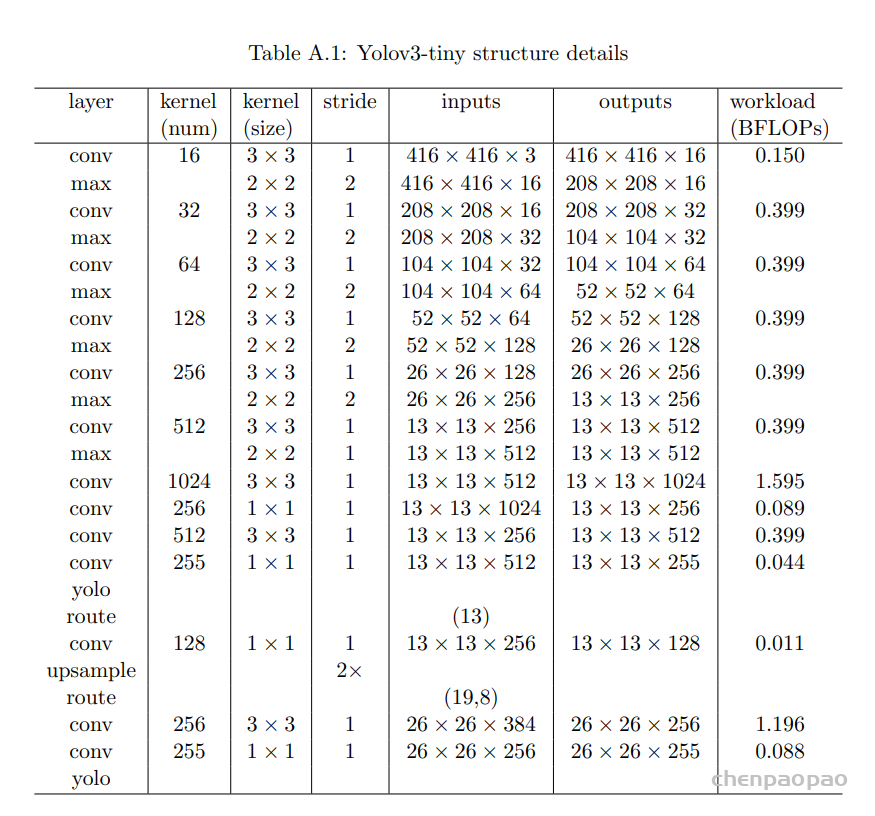
输入 416*416*3 = 519,168 个值
conv0 : input_height=418 原因:这里是做1的填充,所以 最终输入是 416+2 =418
conv_0_param={.kernel_dim=3,
.pad=1,
.input_channel=3,
.input_width=418,
.input_height=418,
.output_channel=16,
.output_width=416,
.output_height=416};16*3个卷积核:一共16*3*9个卷积核参数 +16个bias == 》 432+16 个参数
输出: 416 *416* 16 个值,即2768896个输出
conv1 :
conv_1_param={.kernel_dim=3,
.pad=1,
.input_channel=16,
.input_width=210,
.input_height=210,
.output_channel=32,
.output_width=208,
.output_height=208};一共 32*16个卷积核 4608个卷积核权重参数,36个bias参数
该层输出: 208 *208* 32 = 1384448
conv2 :
conv_2_param={.kernel_dim=3,
.pad=1,
.input_channel=32,
.input_width=106,
.input_height=106,
.output_channel=64,
.output_width=104,
.output_height=104};一共 64 *32个卷积核 18432个卷积核权重参数,64个bias参数
该层输出: 104 *104*64 = 692224
conv3:
conv_3_param={.kernel_dim=3,
.pad=1,
.input_channel=64,
.input_width=54,
.input_height=54,
.output_channel=128,
.output_width=52,
.output_height=52};
一共 128*64个卷积核 73728个卷积核权重参数,128个bias参数
该层输出: 52 *52*128 = 346112
conv4: 256*128*9= 294912 个卷积核权重参数 ,256个偏置, 输出:26*26*256=173056
conv_4_param={.kernel_dim=3,
.pad=1,
.input_channel=128,
.input_width=28,
.input_height=28,
.output_channel=256,
.output_width=26,
.output_height=26};conv5:256*512*9 = 1179648个卷积核权重 512 个bias, 输出:13*13*512=86528
conv6:512*1024*9=4718592个卷积核权重,1024个bias,输出:13*13*1024=173056
conv7:1024*256*1 =262144个卷积层权重,256个bias,输出:13*13*256=43264
conv8:256*512*9 =1179648 个卷积层权重 ,512个bias 输出:13*13*512=86528
上面的卷积层:后面紧跟一个batchnormal层
CONV 9 and 12 have no batch norm layer
conv9 : 最后一层:512*255*1=130560个卷积权重,255个bias, 13*13*255= 43095
conv10: 256*128*1=32768个权重 128个bias 输出13*13*128=21632
conv11: 384*256*3 =305280 个参数 256个bias 输出26*26*256=173056
conv12: 256*255*1=65280个权重 255个bias 输出26*26*255 = 172380
wight= [448,4608,36,18432,64,73728,128,294912,256,1179648,512,4718592,1024,262144,256,1179648 ,512,130560,255,32768,128,305280,256,65280,255]
out: [ 519168,2768896,1384448, 692224,346112,173056,86528,173056,43264,86528,43095,21632,173056,172380]汇总:8269730个wight((八百多万) 输出结果中最大 2768896,最小21632
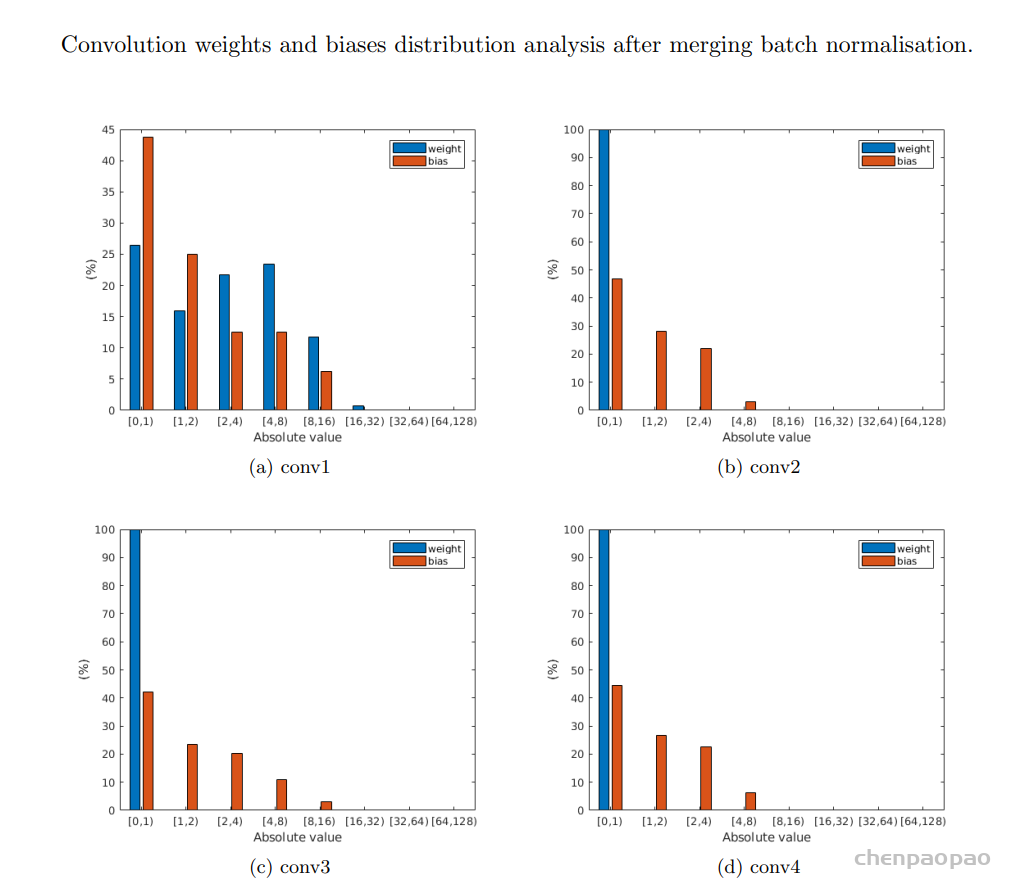
在定点实现中,首先确定整数和小数部分使用了多少位是很重要的。对于线性量化,整数的位宽度与极值以及是否会发生溢出有关。另一方面,分数部分的长度影响量化误差。此外,量化的步长将影响数据的分布。对于不同的网络类型,应在比特宽度和网络精度之间进行彻底的权衡。
在定点实现中,首先确定整数和小数部分使用了多少位是很重要的。对于线性量化,整数的位宽度与极值以及是否会发生溢出有关。另一方面,分数部分的长度影响量化误差。此外,量化的步长将影响数据的分布。对于不同的网络类型,应在比特宽度和网络精度之间进行彻底的权衡。
就总比特而言,2的幂次更可取。为了确定合适的比特宽度,在包含5000幅图像的COCO2014-val5k数据集上进行了实验。下表总结了所有卷积层的数据分布。很明显,所有输入和输出的绝对值都小于128。这意味着在不造成任何溢出的情况下,为有符号整数部分分配8位就足够了。

尝试使用8位表示整数部分,另外8位表示小数。建立了软件定点仿真系统:
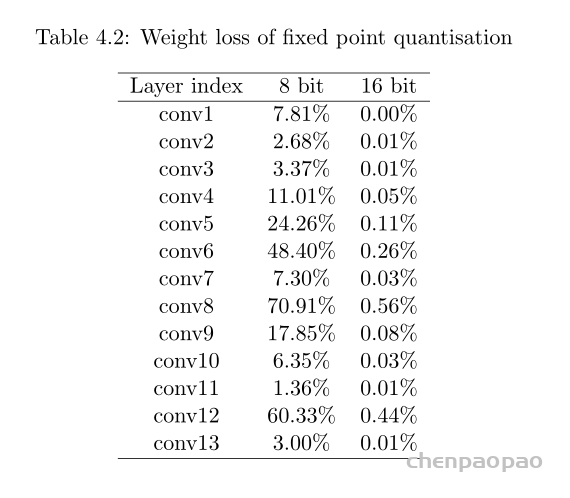
因此选择16bit存储权重以及16bit的数据权重,两者都由16位定点数字表示。对于卷积窗口的结果,采用32位以减少可能的溢出,并提供更高的累积精度。通过实施定点优化,数据宽度从32位压缩到16位,从而实现更高效的DMA传输。此外,使用定点表示为延迟和资源带来了实实在在的好处。
官方 float leaky_activate(float x){return (x>0) ? x : .1*x;}
使用动态定点量化时,激活函数 Leaky ReLU 也要进行相应的量化操作。当位宽 bw 为 16 时,使用与 0xccc 相乘和右移 15 位的定点运算来拟合与 0.1 相乘的操作。量化后的 Leaky ReLU 如下所示:
𝑓′(𝑥) = (𝑥 < 0)? (𝑥 ∗ 0xccc) ≫ 15: 𝑥
OLOv3 tiny中的大多数卷积层在激活前都会进行批量归一化。使用一些数学技术消除批次标准化是安全的。可以很容易地得到以下方程式。
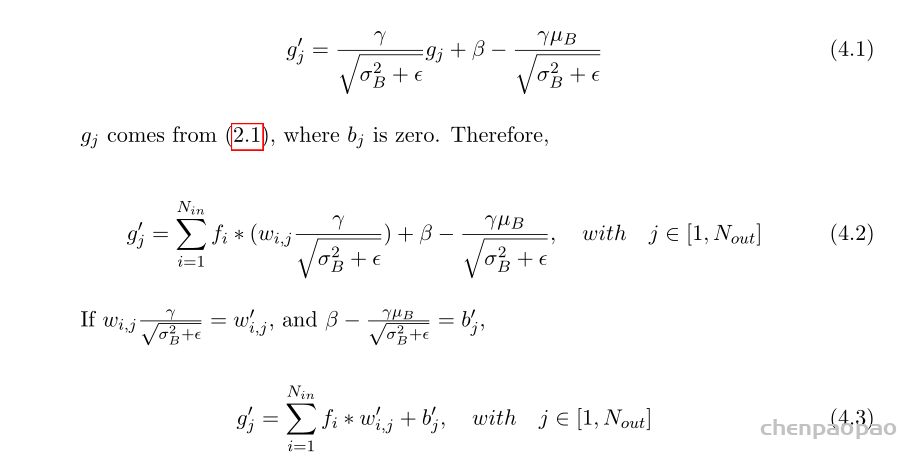
w’0ij和b’j是新的权重和偏差。因为这种转换可以在运行时之前完成,浮点计算过程中的一些可忽略的精度损失外。合并批次归一化也会影响权重的分布。
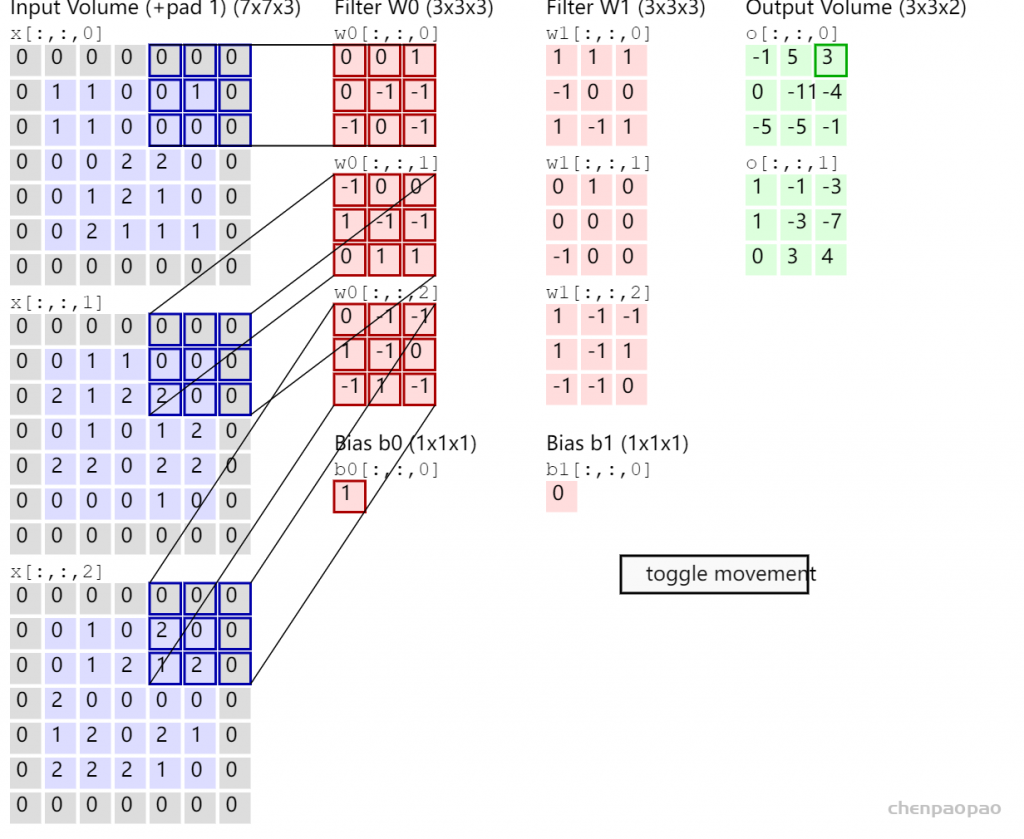
2D 卷积是一种采用权重内核(或窗口或矩阵)并使用这些权重(此矩阵中的值)以某种方式修改输入图像(或特征图或激活图)的操作,pad 默认补0操作
在神经网络中的各种数学线性运算之间引入了激活函数,目的是为整个网络引入非线性。没有它,整个神经网络将简化为单个线性函数,我们都知道这样的函数不足以模拟任何复杂的东西,忘记像图像识别这样的东西。
文献中有多种用于此目的的函数,但最常用(也是第一个)使用的函数是 ReLu(整流线性单元)和 Tanh(双曲正切)函数。
池化本质上是一种“下采样”操作,旨在减少数据在网络中传播时的参数数量和复杂性。此过程涉及在输入上运行“池化窗口”并使用某种算法减小输入的大小。到目前为止,最常见的算法是 Max – Pooling 和 Average – Pooling。
最大池化——在这种方法中,我们只保留落入池化窗口的所有值中的最大值,并丢弃其他值。
平均池化 – 在此方法中,计算池化窗口内所有元素的平均值,并保留该值而不是所有值。
torch.nn.functional.upsample
nearest 采样
yolov3 中的上采样层使用的是2*2上采样:

import torch
from torch import nn
input = torch.arange(1, 5, dtype=torch.float32).view(1, 1, 2, 2)
input
tensor([[[[1., 2.],
[3., 4.]]]])
m = nn.Upsample(scale_factor=2, mode='nearest')
m(input)
返回:
tensor([[[[1., 1., 2., 2.],
[1., 1., 2., 2.],
[3., 3., 4., 4.],
[3., 3., 4., 4.]]]])
首先假设原图是一个像素大小为W*H的图片,缩放后的图片是一个像素大小为w*h的图片,这时候我们是已知原图中每个像素点上的像素值(即灰度值等)的(⚠️像素点对应像素值的坐标都是整数)。这个时候已知缩放后有一个像素点为(x,y),想要得到该像素点的像素值,那么就要根据缩放比例去查看其对应的原图的像素点的像素值,然后将该像素值赋值给该缩放后图片的像素点(x,y)
缩放公式为:
因此这个时候缩放后的图片像素点(x,y)的像素值就对应着原图像素点( W/w * x, H/h *y)的像素值
但是这个时候会出现一个问题就是因为缩放比例的原因,会导致像素点( W/w * x, H/h *y)中的值不是整数,那么就不知道应该对应的是哪个像素点的像素值
这个时候最邻近插值算法使用的方法就是四舍五入法,表示为[.],所以像素值f(x,y) = f( [W/w * x], [H/h *y])
举个例子,如果原图为5*5,缩放后的图为3*3,那么缩放后的图的像素点(1,1)对应的就是原图中([5/3 * 1], [5/3 * 1]) = ([0.6], [0.6]) = (1,1) 像素点对应的像素值
这种方法的好处就是简单,但是坏处就是太过粗暴,会缺失精度,造成缩放后的图像灰度上的不连续,在变化地方可能出现明显锯齿状,如下图所示:(左原图,右缩放后)
在yolo中存在累加操作:conv层 的输出与另外一个conv层输出加和:
yolo在经过多个卷积和上采样之后最终得到的是2个个卷积结果(13*13*255,26*26*255),每一个卷积结果的长和宽分别是(13×13,26×26),深度信息是 [4(box信息)+1(物体判别信息)+80(classNum置信度)] *3(每个点上面计算几个anchor)
对于具有Gh×Gw×Nin输入的YoLO层,它将原始图像划分为 Gh×Gw 网格。通道数n等于(4 +1+C)×B,其中B表示在一个网格中可以检测到多少个对象,C表示对象类别的数量。在YOLOv3 tiny中,B设置为3,COCO数据集中有80个类(c=80).
因此,YLO层的输入具有255的恒定值,这进一步分为3组( 表示在一个网格中可以检测 3种对象)。在每组中,4个通道提供关于边界框的信息,1个通道表示对象分数,其余80个通道表示单个类分数。Yolo层在所有通道上使用Sigmod激活函数,除了表示边界框宽度和高度的通道以外。关键在于指定哪些通道应该通过sigmoid函数,哪些通道应该不被触及。解决方案是提供一个表,其中每个位都表示是否应转换通道。
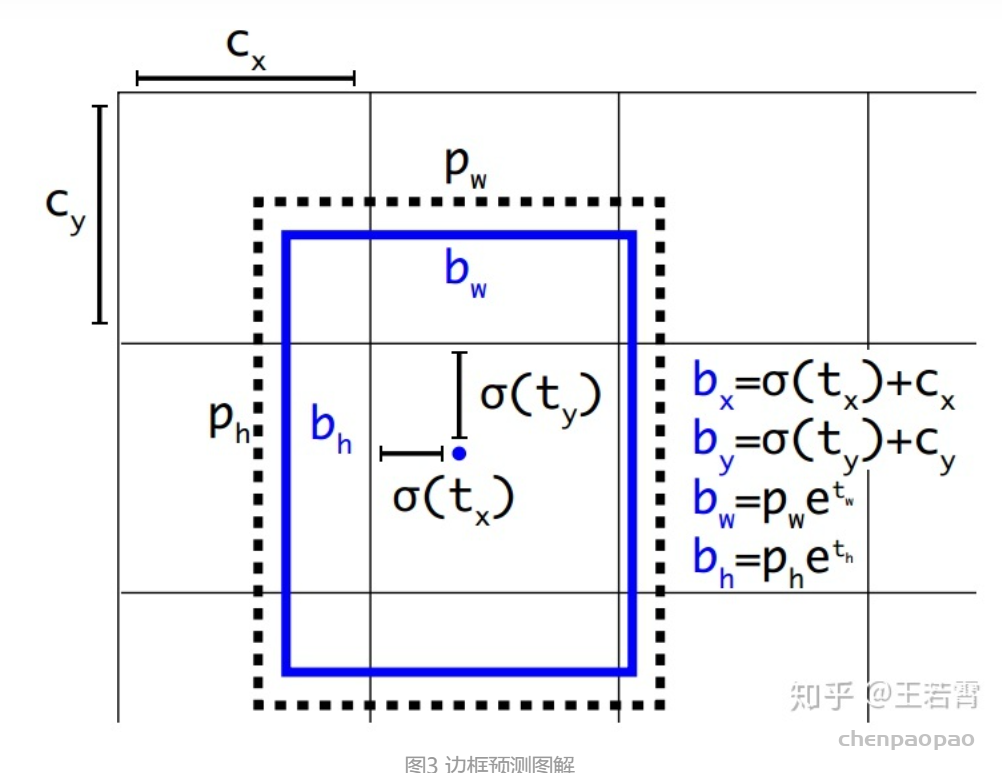
最终得到的边框坐标值是bx,by,bw,bh即边界框bbox相对于feature map的位置和大小,是我们需要的预测输出坐标。但网络实际上的学习目标是tx,ty,tw,th这4个偏移量(offsets),其中tx,ty是预测的坐标偏移值,tw,th是尺度缩放,有了这4个offsets,自然可以根据图2的公式去求得真正需要的bx,by,bw,bh4个坐标。bx,by是预测框中心坐标,bw,bh是预测框的宽高

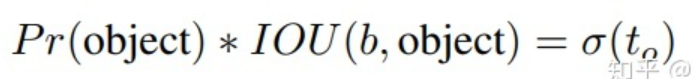
其中 \(C_{x} C_{y}\)是 feature map上anchor box的宽和高, \(t_{y}, t_{w} t_{z} t_{x}\)是 4个通道提供关于边界框的信息

Cx,Cy是feature map中grid cell的左上角坐标,在yolov3中每个grid cell在feature map中的宽和高均为1。如图3的情形时,这个bbox边界框的中心属于第二行第二列的grid cell,它的左上角坐标为(1,1),故Cx=1,Cy=1。Pw、Ph是预设的anchor box映射到feature map中的宽和高,在yolov3.cfg文件中的anchor box原本设定是相对于416*416坐标系下的坐标,代码中是把cfg中读取的坐标除以stride如32映射到feature map坐标系中。
yolov3.cfg文件中的anchor box :
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
问题:anchor box作用的详细描述。
解答:YOLO3为每种FPN预测特征图(13*13,26*26,52*52)设定3种anchor box,总共聚类出9种尺寸的anchor box。在COCO数据集这9个anchor box是:(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90),(156×198),(373×326)。分配上,在最小的13*13特征图上由于其感受野最大故应用最大的anchor box (116×90),(156×198),(373×326),(这几个坐标是针对416*416下的,当然要除以32把尺度缩放到13*13下),适合检测较大的目标。中等的26*26特征图上由于其具有中等感受野故应用中等的anchor box (30×61),(62×45),(59×119),适合检测中等大小的目标。较大的52*52特征图上由于其具有较小的感受野故应用最小的anchor box(10×13),(16×30),(33×23),适合检测较小的目标。同Faster-Rcnn一样,特征图的每个像素(即每个grid)都会有对应的三个anchor box,如13*13特征图的每个grid都有三个anchor box (116×90),(156×198),(373×326)(这几个坐标需除以32缩放尺寸)。
yolo卷积默认补0
主要思想是构建一个高度流水线的流式架构,其中处理模块不必在任何时间点停止。即卷积器的任何部分都不会等待任何其他部分完成其工作并提供结果。每个阶段在每个时钟周期的输入的不同部分上连续执行整个工作的一小部分。这不仅仅是该设计的一个特点,它是一种称为“流水线”的一般原则,广泛用于将大型计算过程分解为更小的步骤,并提高整个电路可以运行的最高频率。
NxN,我们的内核(过滤器/窗口)是维度KxK。显然可以理解,即K < N.s表示窗口在特征图上移动的步幅值。valid_conv和end_conv信号,它们告诉外界这个卷积器模块的输出是否有效。但是为什么卷积器首先会产生无效的结果呢?窗口在输入的特定行上完成移动后,它会继续环绕到下一行,从而创建无效输出。可以避免在环绕期间进行计算,但这需要我们停止流水线,这违反了我们的流式设计原则。因此,我们只是在信号的帮助下丢弃我们认为无效的输出valid conv。具体流程:
下一次从a1开始输入,输出 输出 = w0*a01+ w1*a2 + w2*a3 + w3*a5 + w4*a6 + w5*a7 + w6*a9 + w7*a10 + w8*a11
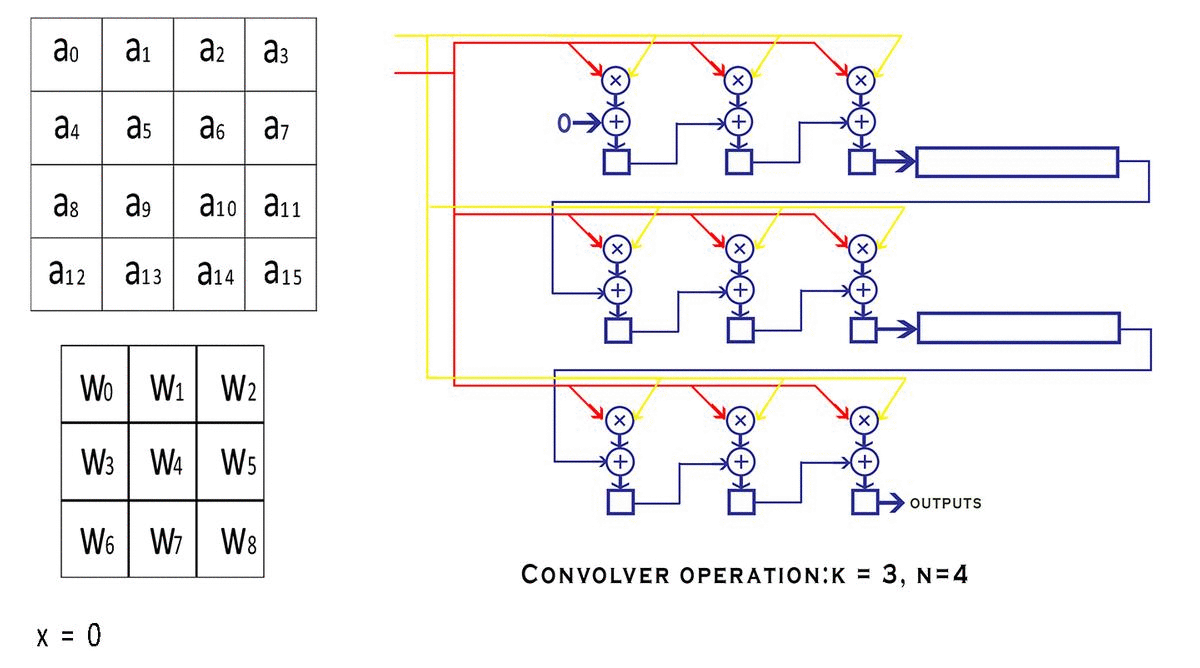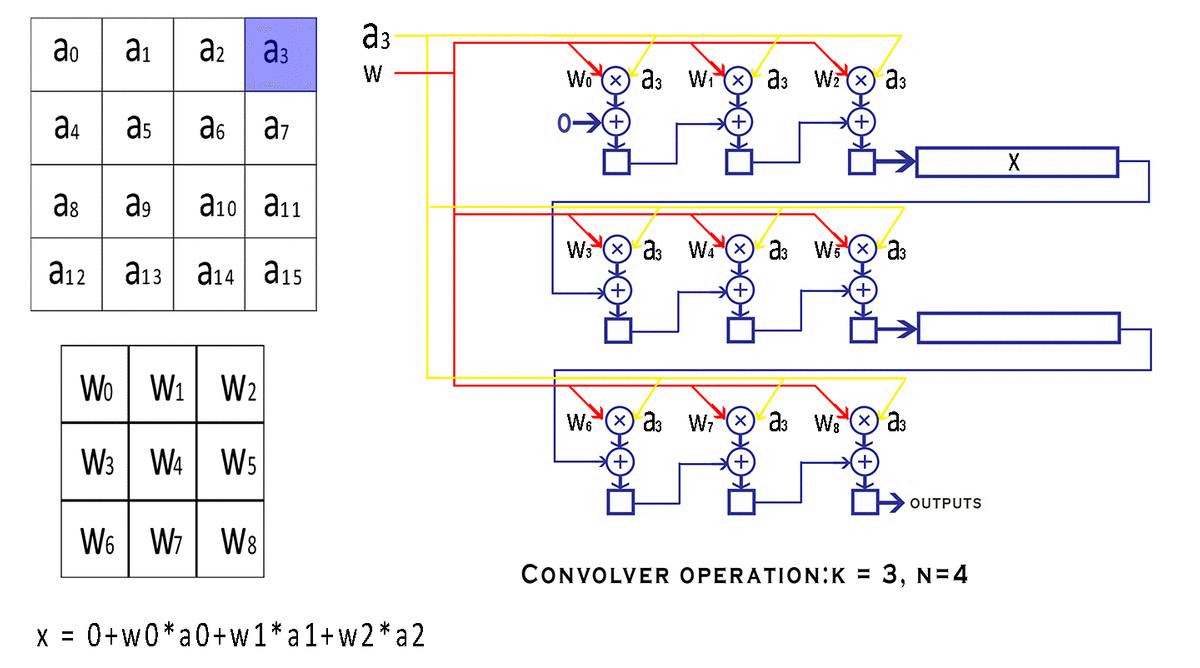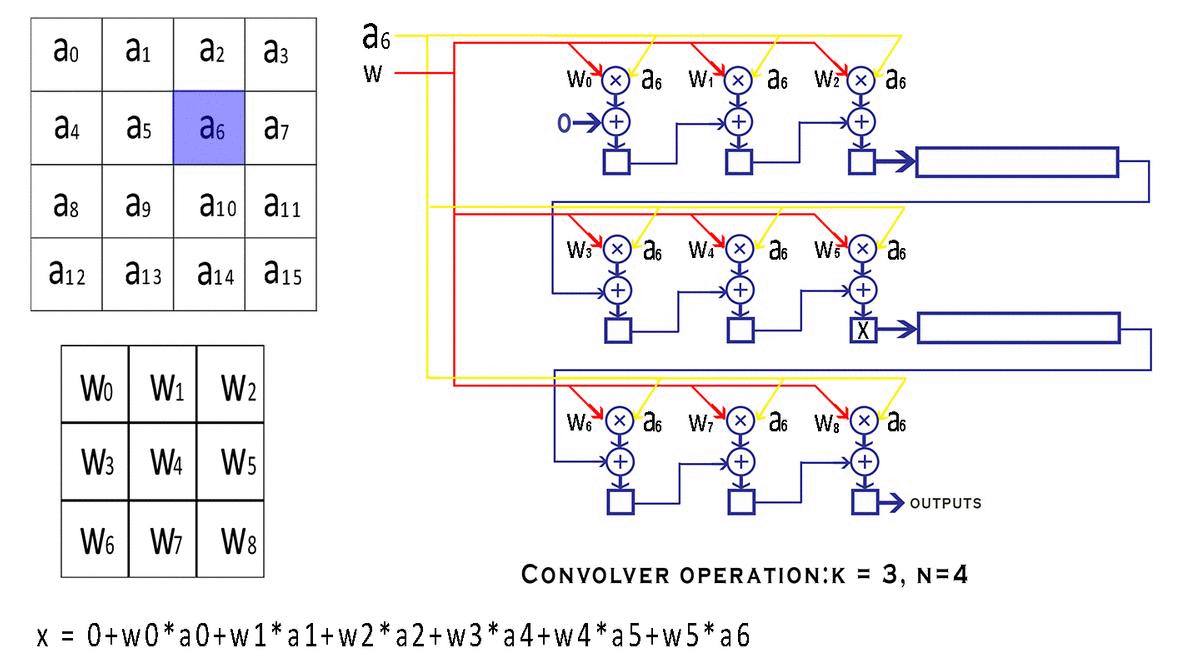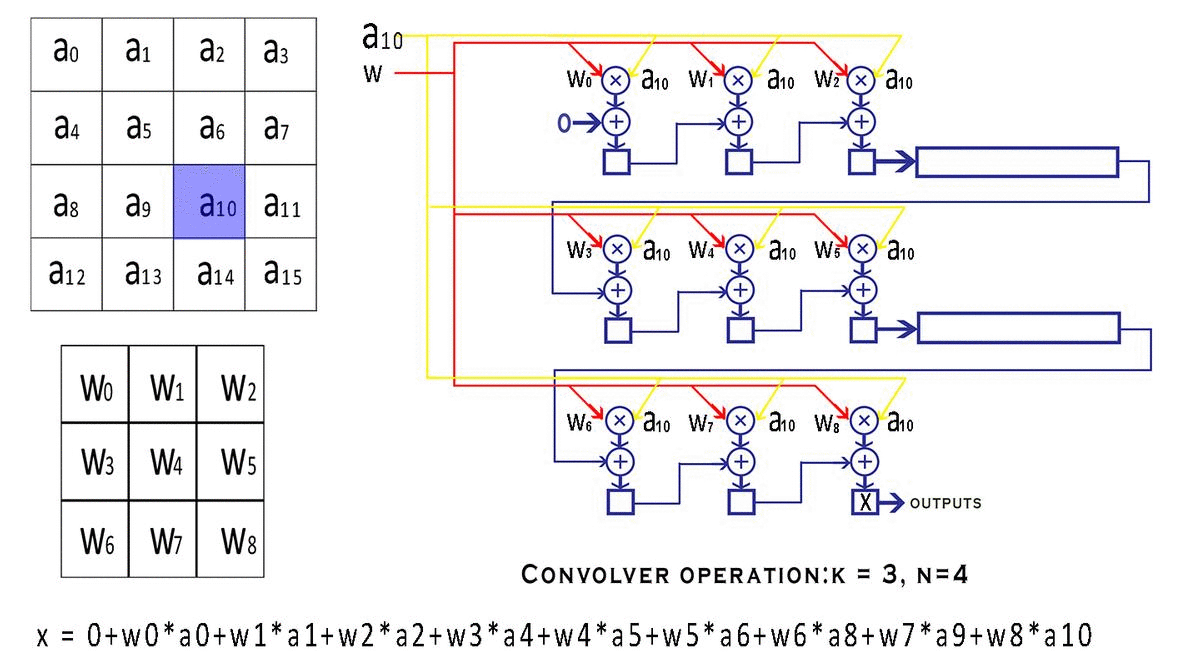
输出 = w0*a0 + w1*a1 + w2*a2 + w3*a4 + w4*a5 + w5*a6 + w6*a8 + w7*a9 + w8*a10
这种架构的优点:
代码:
import numpy as np
from scipy import signal
ksize = 3 #ksize x ksize convolution kernel
im_size = 4 #im_size x im_size input activation map
def strideConv(arr, arr2, s): #the function that performs the 2D convolution
return signal.convolve2d(arr, arr2[::-1, ::-1], mode='valid')[::s, ::s]
kernel = np.arange(0,ksize*ksize,1).reshape((ksize,ksize)) #the kernel is a matrix of increasing numbers
act_map = np.arange(0,im_size*im_size,1).reshape((im_size,im_size)) #the activation map is a matrix of increasin numbers
conv = strideConv(act_map,kernel,1)
print(kernel)
print(act_map)
print(conv) 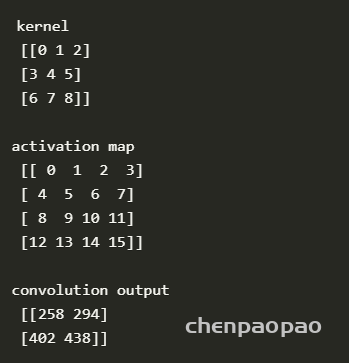
单个加法:
module mac_manual #(
parameter N = 16,
parameter Q = 12
)(
input clk,sclr,ce,
input [N-1:0] a,
input [N-1:0] b,
input [N-1:0] c,
output reg [N-1:0] p
);
always@(posedge clk,posedge sclr)
begin
if(sclr)
begin
p<=0;
end
else if(ce)
begin
p <= (a*b+c); //performs the multiply accumulate operation
end
end
endmodule
卷积中的偏置:
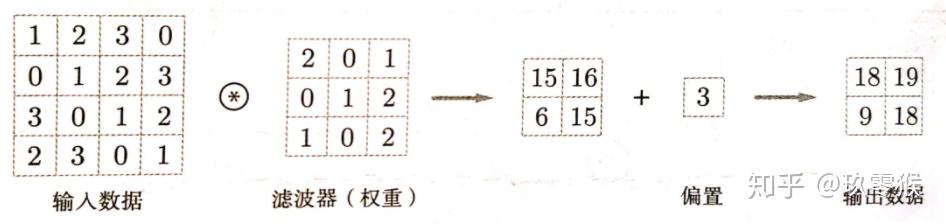
多卷积核的偏置:同一个通道的卷积核共用一个偏置。每个卷积核卷积后的结果+bias
https://cs231n.github.io/assets/conv-demo/index.html
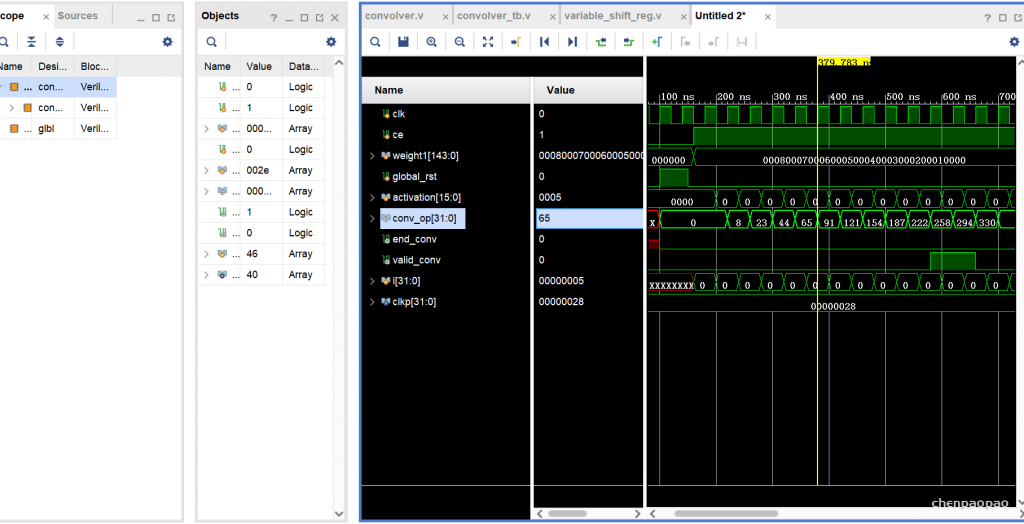
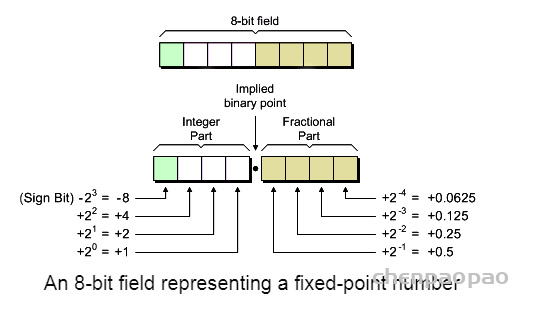
定点数字是小数点位置保持固定的数字,与数字所代表的值无关。与浮点数相比,这使得定点数更易于理解以及在硬件中实现。与浮点运算相比,定点运算使用的资源也少得多。当然,所有这些都需要权衡。浮点运算可以为特定位宽提供比定点运算更高的精度。当我们使用二进制点位于固定位置的数字时,我们会在量化噪声方面受到打击,尽管该数字表示幅度。
Bellman-ford 算法比dijkstra算法更具普遍性,因为它对边没有要求,可以处理负权边与负权回路。缺点是时间复杂度过高,高达O(VE), V为顶点数,E为边数。
特点:支持有环,负权重,但不能存在负权重环。
其主要思想:对所有的边进行n-1轮松弛操作,因为在一个含有n个顶点的图中,任意两点之间的最短路径最多包含n-1边。换句话说,第1轮在对所有的边进行松弛后,得到的是源点最多经过一条边到达其他顶点的最短距离;第2轮在对所有的边进行松弛后,得到的是源点最多经过两条边到达其他顶点的最短距离;第3轮在对所有的边进行松弛后,得到的是源点最多经过一条边到达其他顶点的最短距离……
Bellman-Ford 算法描述:
for (var i = 0; i < n - 1; i++) {
for (var j = 0; j < m; j++) {//对m条边进行循环
var edge = edges[j];
// 松弛操作
if (distance[edge.to] > distance[edge.from] + edge.weight ){
distance[edge.to] = distance[edge.from] + edge.weight;
}
}
}其中, n为顶点的个数,m为边的个数,edges数组储存了所有边,distance数组是源点到所有点的距离估计值,循环结束后就是最小值。
算法过程:首先初始化,对所有的节点V来说,所有的边E进行松弛操作,再然后循环遍历每条边,如果d[v] > d[u] + w(u,v),表示有一个负权重的环路存在。
最后如果没有负权重环路,那么d[v] 是最小路径值。
python 实现:
def bellman_ford(graph, source):
dist = {}
p = {}
max = 10000
for v in graph:
dist[v] = max #赋值为负无穷完成初始化
p[v] = None
dist[source] = 0
for i in range(len( graph ) - 1):
for u in graph:
for v in graph[u]:
if dist[v] > graph[u][v] + dist[u]:
dist[v] = graph[u][v] + dist[u]
p[v] = u #完成松弛操作,p为前驱节点
for u in graph:
for v in graph[u]:
if dist[v] > dist[u] + graph[u][v]:
return None, None #判断是否存在环路
return dist, p
def test():
graph = {
'a': {'b': -1, 'c': 4},
'b': {'c': 2, 'd': 3, 'e': 2},
'c': {},
'd': {'b': 3, 'c': 5},
'e': {'d': -3}
}
dist, p = bellman_ford(graph, 'a')
print(dist)
print(p)
def testfail():
graph = {
'a': {'b': -1, 'c': 4},
'b': {'c': 2, 'd': 3, 'e': 2},
'c': {'d': -5},
'd': {'b': 3},
'e': {'d': -3}
}
dist, p = bellman_ford(graph, 'a')
print(dist)
print(p)
test()
testfail()type [upper:lower] vector_name;
如果声明vector时候指定了vector方向 [8:0] 高到低,那么在使用该vector时,也要从高到低指定:[3:0] [4:1]
向量的字节顺序(或非正式地称为“方向”)是指最低有效位是具有较低的索引(较小的字节序,例如[3:0])还是具有较高的索引(较大的字节序,例如[[ 0:3])。在Verilog中,一旦以特定的字节序声明了向量,就必须始终以相同的方式使用它。例如,声明vec[0:3]时写是非法的。与字节序一致是一种好习惯,因为如果将不同字节序的向量一起分配或使用,则会发生奇怪的错误。
wire [7:0] w; // 8-bit wire reg [4:1] x; // 4-bit reg output reg [0:0] y; // 1-bit reg that is also an output port (this is still a vector) input wire [3:-2] z; // 6-bit wire input (negative ranges are allowed) output [3:0] a; // 4-bit output wire. Type is 'wire' unless specified otherwise. wire [0:7] b; // 8-bit wire where b[0] is the most-significant bit.
wire [2:0] a, c; // Two vectors
assign a = 3'b101; // a = 101
assign b = a; // b = 1 implicitly-created wire
assign c = b; // c = 001 <-- bug
my_module i1 (d,e); // d and e are implicitly one-bit wide if not declared.
// This could be a bug if the port was intended to be a vector.
Adding `default_nettype none would make the second line of code an error, which makes the bug more visible.assign w = a;
takes the entire 4-bit vector a and assigns it to the entire 8-bit vector w (declarations are taken from above). If the lengths of the right and left sides don't match, it is zero-extended or truncated as appropriate.wire表示直通,即输入有变化,输出马上无条件地反映(如与、非门的简单连接)。
reg表示一定要有触发,输出才会反映输入的状态。
reg相当于存储单元,wire相当于物理连线。reg表示一定要有触发,没有输入的时候可以保持原来的值,但不直接实际的硬件电路对应。
两者的区别是:寄存器型数据保持最后一次的赋值,而线型数据需要持续的驱动。wire使用在连续赋值语句中,而reg使用在过程赋值语句(initial ,always)中。wire若无驱动器连接,其值为z,reg默认初始值为不定值 x 。
在连续赋值语句中,表达式右侧的计算结果可以立即更新表达式的左侧。在理解上,相当于一个逻辑之后直接连了一条线,这个逻辑对应于表达式的右侧,而这条线就对应于wire。在过程赋值语句中,表达式右侧的计算结果在某种条件的触发下放到一个变量当中,而这个变量可以声明成reg类型的。根据触发条件的不同,过程赋值语句可以建模不同的硬件结构:如果这个条件是时钟的上升沿或下降沿,那么这个硬件模型就是一个触发器;如果这个条件是某一信号的高电平或低电平,那么这个硬件模型就是一个锁存器;如果这个条件是赋值语句右侧任意操作数的变化,那么这个硬件模型就是一个组合逻辑。
对组合逻辑输出变量,可以直接用assign。即如果不指定为reg类型,那么就默认为1位wire类型,故无需指定1位wire类型的变量。当然专门指定出wire类型,可能是多位或为使程序易读。wire只能被assign连续赋值,reg只能在initial和always中赋值。
输入端口可以由wire/reg驱动,但输入端口只能是wire;输出端口可以是wire/reg类型,输出端口只能驱动wire;若输出端口在过程块中赋值则为reg型,若在过程块外赋值则为net型(wire/tri)。用关键词inout声明一个双向端口, inout端口不能声明为reg类型,只能是wire类型。
默认信号是wire类型,reg类型要申明。这里所说的默认是指输出信号申明成output时为wire。如果是模块内部信号,必须申明成wire或者reg.
对于always语句而言,赋值要申明成reg,连续赋值assign的时候要用wire。
模块调用时 信号类型确定方法总结如下:
•信号可以分为端口信号和内部信号。出现在端口列表中的信号是端口信号,其它的信号为内部信号。
•对于端口信号,输入端口只能是net类型。输出端口可以是net类型,也可以是register类型。若输出端口在过程块中赋值则为register类型;若在过程块外赋值(包括实例化语句),则为net类型。
•内部信号类型与输出端口相同,可以是net或register类型。判断方法也与输出端口相同。若在过程块中赋值,则为register类型;若在过程块外赋值,则为net类型。
•若信号既需要在过程块中赋值,又需要在过程块外赋值。这种情况是有可能出现的,如决断信号。这时需要一个中间信号转换。
下面所列是常出的错误及相应的错误信息(error message)
•用过程语句给一个net类型的或忘记声明类型的信号赋值。
信息:illegal …… assignment.
•将实例的输出连接到声明为register类型的信号上。
信息:<name> has illegal output port specification.
•将模块的输入信号声明为register类型。
用法:
case(in)
2'b00:out = 0;
2'b01:out = 1;
2'b10:out = 2;
2'b11:out = 3;
endcasecasex: 该语句不考虑高阻值z以及不定值x,即在表达式进行 比较时,不会比较x、z所在位的状态:in = 001 c = xx1 那么 in在case语句中等于c,因为不考虑x位,只需要比较最后一位 1=1
//要实现 如果in的第一个1出现的位置 in == 000 则out = 0 in = 101则out =1 in =111 则out仍是1
case(in)
2'bxx1:out = 3;
2'bx1x:out = 2;
2'b1xx:out = 1;
2'b000:out = 0
endcase
同理 casez 该语句不考虑高阻值z , 即在表达式进行 比较时,不会比较z所在位的状态
思想:动态规划
Floyd-Warshall算法(Floyd-Warshall algorithm)是解决任意两点间的最短路径的一种算法,可以正确处理有向图或负权的最短路径问题,同时也被用于计算有向图的传递闭包。
Floyd-Warshall算法的时间复杂度为O(N^3),空间复杂度为O(N^2)。
Floyd算法是一个经典的动态规划算法。用通俗的语言来描述的话,首先我们的目标是寻找从点i到点j的最短路径。
从动态规划的角度看问题,我们需要为这个目标重新做一个诠释(这个诠释正是动态规划最富创造力的精华所在)
从任意节点i到任意节点j的最短路径不外乎2种可能,1是直接从i到j,2是从i经过若干个节点k到j。所以,我们假设Dis(i,j)为节点u到节点v的最短路径的距离,对于每一个节点k,我们检查Dis(i,k) + Dis(k,j) < Dis(i,j)是否成立,如果成立,证明从i到k再到j的路径比i直接到j的路径短,我们便设置Dis(i,j) = Dis(i,k) + Dis(k,j),这样一来,当我们遍历完所有节点k,Dis(i,j)中记录的便是i到j的最短路径的距离。
a. 从任意一条单边路径开始。所有两点之间的距离是边的权,如果两点之间没有边相连,则权为无穷大。
b. 对于每一对顶点 u 和 v,看看是否存在一个顶点 w 使得从 u 到 w 再到 v 比己知的路径更短。如果是更新它。
方法:两条线,从左上角开始计算一直到右下角 如下所示
先来简单分析下,由于矩阵中对角线上的元素始终为0,因此以k为中间点时,从上一个矩阵到下一个矩阵变化时,矩阵的第k行,第k列和对角线上的元素是不发生改变的(对角线上都是0,因为一个顶点到自己的距离就是0,一直不变;而当k为中间点时,k到其他顶点(第k行)和其他顶点到k(第k列)的距离是不变的)。
因此每一步中我们只需要判断4*4-3*4+2=6个元素是否发生改变即可,也就是要判断既不在第k行第k列又不在对角线上的元素。具体计算步骤如下:以k为中间点(1)“三条线”:划去第k行,第k列,对角线(2)“十字交叉法”:对于任一个不在三条线上的元素x,均可与另外在k行k列上的3个元素构成一个2阶矩阵,x是否发生改变与2阶矩阵中不包含x的那条对角线上2个元素的和有关,若二者之和小于x,则用它们的和替换x,对应的Path矩阵中的与x相对应的位置用k来替代。。
给出矩阵,其中矩阵A是邻接矩阵,而矩阵Path记录u,v两点之间最短路径所必须经过的点(指的是u->….->该点->v)
分别以每一个点作为K点转接v
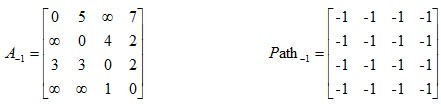



核心代码只有 4 行,实在令人赞叹。 [java]
private void floyd() {
for (int k = 0; k < n; k++) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
a[i][j] = Math.min(a[i][j], a[i][k] + a[k][j]);
}
}
}
// 打印
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
System.out.println(i + " " + j + ":" + a[i][j]);
}
}
}
核心代码只有四行,三行循环,一行更新,的确十分简洁优雅,可是这四行代码为什么就能求出任意两点的最短路径呢?
看代码的特点,很显然特别像是一种动态规划,确实,之前也说过该算法是基于动态规划的。
我们从动态规划的角度考虑,解动态规划题目的重点就是合理的定义状态,划分阶段,我们定义 f[k][i][j] 为经过前k的节点,从i到j所能得到的最短路径,f[k][i][j]可以从f[k-1][i][j]转移过来,即不经过第k个节点,也可以从f[k-1][i][k]+f[k-1][k][j]转移过来,即经过第k个节点。
观察一下这个状态的定义,满足不满足最优子结构和无后效性原则。
图结构中一个显而易见的定理:
最短路径的子路径仍然是最短路径, 这个定理显而易见,比如一条从a到e的最短路a->b->c->d->e 那么 a->b->c 一定是a到c的最短路c->d->e一定是c到e的最短路,反过来,如果说一条最短路必须要经过点k,那么i->k的最短路加上k->j的最短路一定是i->j 经过k的最短路,因此,最优子结构可以保证。
状态f[k][i][j]由f[k-1][i][j],f[k-1][i,k] 以及f[k-1][k][j]转移过来,很容易可以看出,f[k] 的状态完全由f[k-1]转移过来,只要我们把k放倒最外层循环中,就能保证无后效性。
满足以上两个要求,我们即证明了Floyd算法是正确的。
我们最后得出一个状态转移方程:f[k][i][j] = min(f[k-1][i][k],f[k-1][i][k],f[k-1][k][j]) ,可以观察到,这个三维的状态转移方程可以使用滚动数组进行优化。
采用动态规划思想,f[k][i][j] 表示 i 和 j 之间可以通过编号为 1…k 的节点的最短路径。
f[0][i][j] 初值为原图的邻接矩阵。
f[k][i][j]则可以从f[k-1][i][j]转移来,表示 i 到 j 不经过 k 这个节点。
也可以 f[k-1][i][k]+f[k-1][k][j] 从转移过来,表示经过 k 这个点。
意思即 f[k][i][j]=min(f[k-1][i][j], f[k-1][i][k]+f[k-1][k][j])
然后你就会发现 f 最外层一维空间可以省略,因为 f[k] 只与 f[k-1] 有关。
虽然这个算法非常简单,但也需要找点时间理解这个算法,就不会再有这种问题啦。
Floyd算法的本质是DP,而k是DP的阶段,因此要写最外面。
想象一个图,讨论的是要从1点到达3点,是直接走还是经过中间点2,从而确定两点之间的最短路径。
滚动数组是一种动态规划中常见的降维优化的方式,应用广泛(背包dp等),可以极大的减少空间复杂度。
在我们求出的状态转移方程中,我们在更新f[k]层状态的时候,用到f[k-1]层的值,f[k-2] f[k-3]层的值就直接废弃了。
所以我们大可让第一层的大小从n变成2,再进一步,我们在f[k]层更新f[k][i][j]的时候,f[k-1][i][k] 和 f[k-1][k][j] 我们如果能保证,在更新k层另外一组路径m->n的时候,不受前面更新过的f[k][i][j]的影响,就可以把第一维度去掉了。
我们现在去掉第一个维度,写成我们在代码中的那样,就是f[i][j] 依赖 f[i][k] + f[k][j] 我们在更新f[m][n]的时候,用到了f[m][k] + f[k][n] 假设f[i][j]的更新影响到了f[m][k] 或者 f[k][m] 即 {m=i,k=j} 或者 {k=i,n=j} 这时候有两种情况,j和k是同一个点,或者i和k是同一个点,那么 f[i][j] = f[i][j] + f[j][j],或者f[i][j] = f[i][i]+f[i][j] 这时候,我们所谓的“前面更新的点对”还是这两个点本来的路径,也就是说,唯一两种在某一层先更新的点,影响到后更新的点的情况,是完全合理的,所以说,我们即时把第一维去掉,也满足无后效性原则。
因此可以用滚动数组优化。
优化之后的状态转移方程即为:f[i][j] = min(f[i][j],f[i][k]+f[k][j])。
我们上面仅仅是知道了最短路径的长度,实际应用中我们常常是需要知道具体的路径,在Floyd算法中怎么求具体路径呢,很简单,我们只需要记录下来在更新f[i][j]的时候,用到的中间节点是哪个就可以了。
假设我们用path[i][j]记录从i到j松弛的节点k,那么从i到j,肯定是先从i到k,然后再从k到j, 那么我们在找出path[i][k] , path[k][j]即可。
即 i到k的最短路是 i -> path[i][k] -> k -> path[k][j] -> k q` 然后求path[i][k]和path[k][j] ,一直到某两个节点没有中间节点为止,代码如下:
在更新路径的时候: [java]
if(a[i][k]>temp){
a[i][j] = temp;
path[i][j] = k;
}
求路径的时候: [java]
public String getPath(int[][] path, int i, int j) {
if (path[i][j] == -1) {
return " "+i+" "+j;
} else {
int k = path[i][j];
return getPath(path, i, k)+" "+getPath(path, k, j)+" ";
}
}
Floyd算法只能在不存在负权环的情况下使用,因为其并不能判断负权环,上面也说过,如果有负权环,那么最短路将无意义,因为我们可以不断走负权环,这样最短路径值便成为了负无穷。
但是其可以处理带负权边但是无负权环的情况。
以上就是求多源最短路的Floyd算法,基于动态规划,十分优雅。
但是其复杂度确实是不敢恭维,因为要维护一个路径矩阵,因此空间复杂度达到了O(n^2),时间复杂度达到了O(n^3),只有在数据规模很小的时候,才适合使用这个算法,但是在实际的应用中,求单源最短路是最常见的,比如在路由算法中,某个节点仅需要知道从这个节点出发到达其他节点的最短路径,而不需要知道其他点的情况,因此在路由算法中最适合的应该是单源最短路算法,Dijkstra算法。