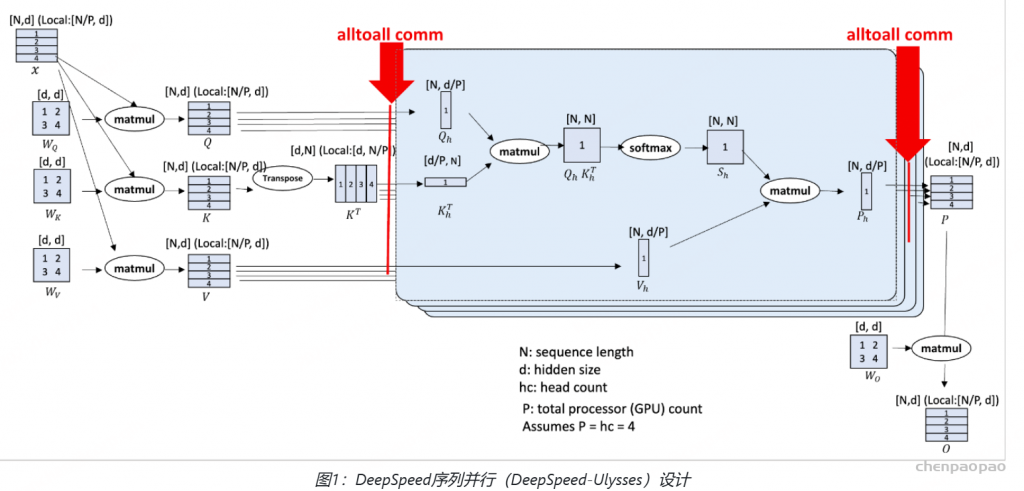
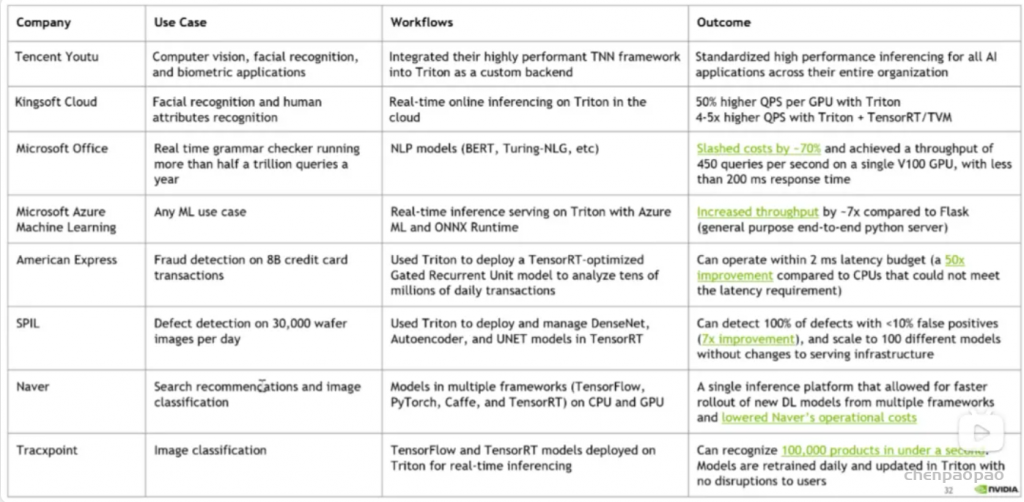
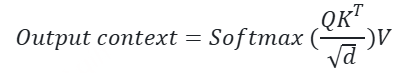深度学习的发展证明了大数据和大模型的价值。无论是在CV还是NLP领域,在大规模的计算资源上训练模型的能力变得日益重要。GPU以比CPU更快的矩阵乘法和加法运算,加速了模型训练。但随着数据量和模型参数的增长,单块GPU很快变得不够用。因此我们必须找到合适的方法,实现数据和模型在多个GPU甚至多个计算节点间的划分和复制,从而实现更短的训练周期和更大的模型参数量。
DDP大致的流程如下:
初始化进程组。 创建分布式并行模型,每个进程都会有相同的模型和参数。 创建数据分发Sampler,使每个进程加载一个mini batch中不同部分的数据。 网络中相邻参数分桶,一般为神经网络模型中需要进行参数更新的每一层网络。 每个进程前向传播并各自计算梯度。 模型某一层的参数得到梯度后会马上进行通讯并进行梯度平均。 各GPU更新模型参数。 今天主要来研究 3创建数据分发和Sampler :主要由三部分组成:torch.utils.data.Dataset【可以自定义】、torch.utils.data.DataLoader、以及torch.utils.data.distributed.DistributedSampler【可以自己定义】。
DistributedSampler 确保每个进程(或 GPU)处理数据集的不同部分。DataLoader 使用 DistributedSampler 生成的数据索引来分批数据,并进行数据加载和预处理。
1、 Dataset :
Dataset 是一个抽象类,用于表示数据集。你需要继承这个类并实现其方法,以定义你自己的数据集。它的主要功能包括:
定义数据访问 :通过实现 __getitem__ 方法,定义如何访问数据集中单个数据项。数据集大小 :通过实现 __len__ 方法,返回数据集中样本的总数。class MyDataset(torch.utils.data.Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data[index]
2、DataLoader:
DataLoader 是一个数据加载器,它负责从 Dataset 中批量加载数据。它提供了对数据的批量处理、随机打乱、并行加载等功能。DataLoader 主要功能包括:
批量加载 :将数据集分成多个批次,并在每次迭代中返回一个批次的数据。并行处理 :使用多个工作线程(num_workers)来并行加载数据,提高数据加载速度。数据打乱 :通过 shuffle 参数来随机打乱数据顺序。自动处理样本 :使用 collate_fn 将单个样本组合成批次。1. 数据加载和预处理
DataLoader 负责从数据集(Dataset)中加载数据,并进行必要的预处理操作。预处理可能包括数据增强、归一化等。它通过多线程或多进程的方式并行加载数据,减少了数据加载时间。
num_workers2. 数据分批
DataLoader 将数据集划分为多个批次(batches),以便于模型进行训练和评估。批次的大小可以通过 batch_size 参数进行设置。
batch_size3. 分布式训练中的数据划分
在 DDP 下,DataLoader 结合 Sampler 来确保数据在各个进程之间的正确分配。Sampler 控制每个进程(或 GPU)获得数据集的哪一部分。
DistributedSamplerDistributedSampler 确保每个进程处理不同的数据子集,从而实现负载均衡和避免数据重复。4. 数据的打乱和顺序
为了提高模型的泛化能力,数据通常在每个 epoch 开始时被打乱。DataLoader 提供了打乱数据的功能,这对于训练过程是非常重要的。
shuffle5. 批次丢弃
在训练过程中,如果最后一个批次的样本数不足以构成完整的批次,可以选择丢弃这个批次,以保证每个批次的大小一致。
drop_lastbatch_size)。6. 与 Sampler 结合使用
DataLoader 可以与不同的 Sampler 结合使用,以支持各种数据加载策略。在 DDP 下,DistributedSampler 是常用的 Sampler,它将数据集划分为多个子集,每个进程处理一个子集。
batch_samplerSampler,可以将其传递给 batch_sampler 参数来控制数据的分批方式。data = [1, 2, 3, 4, 5]
for batch in dataloader:
3、DistributedSampler:
DistributedSampler 用于在分布式训练中对数据进行采样。它的主要作用是确保每个进程(或 GPU)在分布式训练中获得数据的不同子集,从而避免数据重复和确保数据均匀分配。主要功能包括:
分布式数据分配 :根据进程的 rank 和总进程数,计算出每个进程应该处理的数据子集。随机打乱 :支持在每个 epoch 重新打乱数据,以增加训练的随机性。同步 :在多个进程之间协调数据的采样。1. 数据分配
在分布式训练中,数据集被划分成多个子集,每个进程(或 GPU)处理数据集的一部分。Sampler 确保每个进程(或 GPU)得到不同的数据子集,以避免重复和数据丢失。
DistributedSampler :这是 PyTorch 提供的专门用于分布式训练的采样器。它根据当前进程的 rank 和总进程数 num_replicas 来划分数据集。每个进程获得数据集的不同部分,从而实现数据的有效分配和负载均衡。2. 确保数据覆盖
在每个 epoch 中,每个进程需要获取数据集的不同部分,以确保整个数据集被覆盖。Sampler 可以帮助实现这种数据分配策略,避免数据遗漏和冗余。
随机打乱 :DistributedSampler 还支持在每个 epoch 开始时打乱数据集,这对于训练模型具有更好的泛化能力是非常重要的。3. 避免数据重复
如果不使用合适的 Sampler,多个进程可能会处理相同的数据,从而导致数据重复。这不仅浪费计算资源,还可能影响模型的训练效果。
去重 :DistributedSampler 确保每个进程仅处理数据集的一部分,从而避免数据重复。4. 适应批量大小
在分布式训练中,数据的分配和批处理需要适应分布式环境中的批量大小。Sampler 负责将数据分成适合训练的批次,并确保每个进程处理的数据量与其他进程一致。
BatchSampler :BatchSampler 将由 Sampler 生成的索引列表分成批次,以便用于训练。它与 DistributedSampler 结合使用时,可以确保每个进程处理的数据批次符合预期的批量大小。5. 支持多样本处理策略
不同的任务和模型可能需要不同的数据处理策略,如排序、动态采样等。通过自定义 Sampler,可以实现特定的采样策略以满足任务需求。
自定义采样器 :可以实现自定义的 Sampler 类,来满足特定的需求,如按样本长度排序、动态调整批次大小等。sampler = torch.utils.data.distributed.DistributedSampler(dataset, num_replicas=4, rank=0)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=2, sampler=sampler)
动手实现一个采样器:
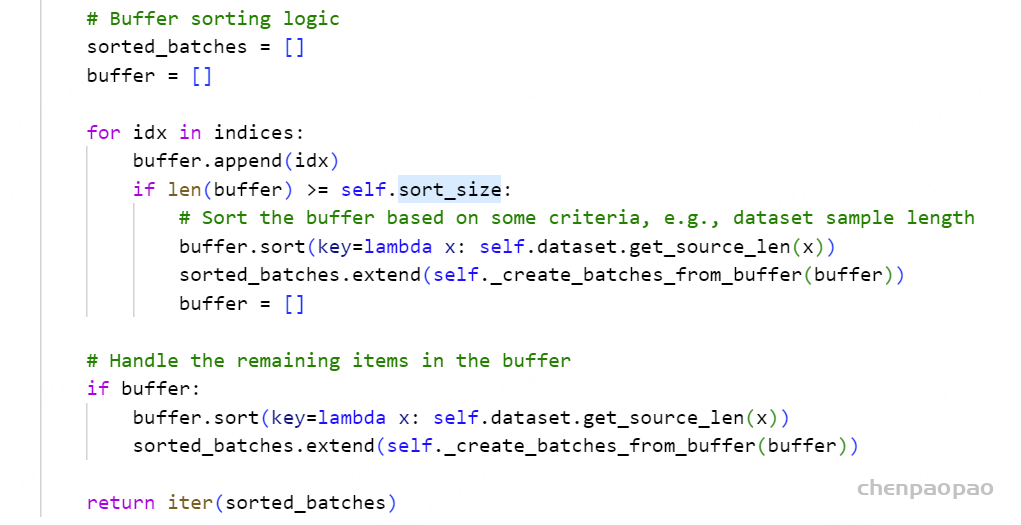
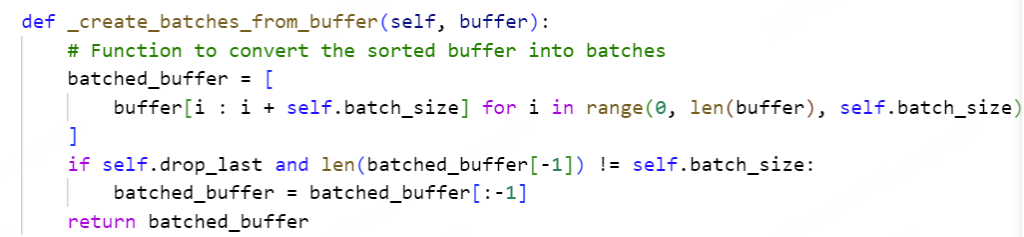
CustomDistributedBufferDynamicBatchSampler 是一个用于分布式训练的自定义数据采样器,它结合了动态批量大小和缓冲区的排序策略。它的目的是通过更复杂的策略来生成批量,以适应各种训练需求。下面是对这个采样器的详细解释:
__iter__ 方法生成数据批次,考虑到动态批量大小和缓冲区的排序:
数据打乱 :如果 shuffle 为 True,数据将被打乱。缓冲区排序 :数据被分成多个缓冲区,每个缓冲区的大小由 sort_size 控制,并按样本长度进行排序。批量生成 :根据 batch_size 和 batch_size_sample_max 生成批量。如果当前缓冲区中的数据无法满足批次大小,则将现有数据作为一个批次。数据重复和分配 :确保每个进程获得相同数量的批次。如果总批次不足以均分,重复一些批次以满足每个进程的需求。
datasetbatch_sizebatch_typenum_replicasrankrank_splitshuffledrop_lastis_trainingsort_sizestart_step
def __init__(
self,
dataset,
batch_size,
batch_type="token",
num_replicas=None,
rank=None,
rank_split=False,
shuffle=True,
drop_last=False,
is_training: bool = True,
sort_size: int = 1024,
start_step: int = 0,
**kwargs,
):
try:
rank = dist.get_rank()
num_replicas = dist.get_world_size()
except:
rank = 0
num_replicas = 1
self.rank = rank
self.num_replicas = num_replicas
self.dataset = dataset
self.batch_size = batch_size
self.batch_type = batch_type
self.is_training = is_training
self.shuffle = shuffle and is_training
self.drop_last = drop_last
self.total_size = len(self.dataset)
self.num_samples = int(math.ceil(self.total_size / self.num_replicas))
self.epoch = 0
self.sort_size = sort_size * num_replicas
self.max_token_length = kwargs.get("max_token_length", 2048)
self.length_scale_source = kwargs.get("length_scale_source", 1.0)
self.batch_size_sample_max = kwargs.get("batch_size_sample_max", 200)
self.start_step = start_step
self.batch_num = 1
if self.start_step > 0:
logging.info(f"Warning, start_step > 0, dataloader start from step: {self.start_step}")
def __iter__(self):
if self.shuffle:
g = torch.Generator()
g.manual_seed(self.epoch)
random.seed(self.epoch)
indices = torch.randperm(len(self.dataset), generator=g).tolist()
else:
indices = list(range(len(self.dataset)))
# Create sorted buffers and form batches
buffer_batches = []
for i in range(0, len(indices), self.sort_size):
buffer = sorted(
indices[i : i + self.sort_size], key=lambda idx: self.dataset.get_source_len(idx)
)
batch = []
max_len_in_batch = 0
count = 1
for idx in buffer:
original_sample_length = self.dataset.get_source_len(idx)
if original_sample_length > self.max_token_length:
continue
sample_length = 1 if self.batch_type == "example" else original_sample_length
potential_batch_length = max(max_len_in_batch, sample_length) * (len(batch) + 1)
if potential_batch_length <= self.batch_size and count < self.batch_size_sample_max:
batch.append(idx)
max_len_in_batch = max(max_len_in_batch, sample_length)
count += 1
else:
buffer_batches.append(batch)
batch = [idx]
max_len_in_batch = sample_length
count = 1
if batch:
buffer_batches.append(batch)
# Ensure each rank gets the same number of batches, duplicate data if needed
batches_per_rank = math.ceil(len(buffer_batches) / self.num_replicas)
total_batches_needed = batches_per_rank * self.num_replicas
extra_batches = total_batches_needed - len(buffer_batches)
buffer_batches += random.choices(buffer_batches, k=extra_batches)
# Evenly distribute batches from buffer_batches to each rank
rank_batches = [[] for _ in range(self.num_replicas)]
for i, batch in enumerate(buffer_batches):
rank_batches[i % self.num_replicas].append(batch)
# Assign all batches for the current rank directly
final_batches = rank_batches[self.rank][self.start_step :]
self.batch_num = len(final_batches)
logging.info(
f"rank: {self.rank}, dataloader start from step: {self.start_step}, batch_num: {len(rank_batches[self.rank])}, after: {self.batch_num}"
)
return iter(final_batches)
CustomDistributedBufferDynamicBatchSampler 通过以下方式增强了数据采样:
动态批量大小 :根据数据的实际长度动态调整批量大小。缓冲区排序 :使用排序缓冲区策略提高数据处理效率。数据均匀分配 :确保每个进程获得相同数量的批次,避免数据不均衡。 这些特性使得 CustomDistributedBufferDynamicBatchSampler 能够更好地处理大规模数据集,并在分布式训练中提供高效的数据加载和批次生成策略。
数据均匀分配至关重要: 如果分配不均,会导致某个节点的GPU显存爆炸,导致短筒效应,所以需要对数据进行平均分配:
分布式训练的时候 如何定义自己的samper,如何保证不同的节点使用不同的数据训练?
根据rank数量将索引分成不同的rank份。 分割数据以确保每个进程获取不同的索引 。
if self.num_replicas is not None and self.rank is not None:
# 每个进程处理的数据索引范围
num_samples = int(np.ceil(len(indices) / self.num_replicas))
start = self.rank * num_samples
end = min(start + num_samples, len(indices))
indices = indices[start:end]1. 定义自定义Sampler
自定义Sampler需要继承torch.utils.data.Sampler并实现__iter__方法,返回数据索引的迭代器。以下是一个简单的示例:
python复制代码import torch
import numpy as np
class CustomSampler(torch.utils.data.Sampler):
def __init__(self, data_source, num_replicas=None, rank=None):
self.data_source = data_source
self.num_replicas = num_replicas
self.rank = rank
def __iter__(self):
# 获取所有样本索引
indices = np.arange(len(self.data_source))
# 分割数据以确保每个进程获取不同的索引
if self.num_replicas is not None and self.rank is not None:
# 每个进程处理的数据索引范围
num_samples = int(np.ceil(len(indices) / self.num_replicas))
start = self.rank * num_samples
end = min(start + num_samples, len(indices))
indices = indices[start:end]
# 打乱数据
np.random.shuffle(indices)
return iter(indices)
def __len__(self):
if self.num_replicas is not None and self.rank is not None:
num_samples = int(np.ceil(len(self.data_source) / self.num_replicas))
return num_samples
return len(self.data_source)
2. 初始化分布式环境
在训练脚本中,初始化分布式环境并创建自定义采样器。
python复制代码import torch
import torch.distributed as dist
dist.init_process_group(backend='nccl') # 或 'gloo'
local_rank = dist.get_rank()
world_size = dist.get_world_size()
# 数据集
from torchvision import datasets, transforms
transform = transforms.Compose([transforms.ToTensor()])
dataset = datasets.CIFAR10(root='./data', train=True, transform=transform, download=True)
# 创建自定义采样器
sampler = CustomSampler(dataset, num_replicas=world_size, rank=local_rank)
# 创建数据加载器
dataloader = torch.utils.data.DataLoader(dataset, batch_size=32, sampler=sampler)
3. 在训练时设置采样器的epoch
如果你的自定义Sampler需要在每个epoch中更改数据顺序,可以在每个epoch开始时调用sampler.set_epoch(epoch)。
python复制代码for epoch in range(num_epochs):
sampler.set_epoch(epoch) # 如果你的自定义Sampler支持这个方法
for batch in dataloader:
# 训练代码
这样,你就可以定义一个适合你需求的自定义Sampler,并在分布式训练中使用它。
DDP分布式训练时候 batchsize设置是指单卡还多卡所有的总batch?
在分布式数据并行(DDP)训练中,batch_size的设置是指每个单卡(即每个GPU)的batch size。总的batch size是每个单卡的batch size乘以GPU的数量。【在samper采样的时候,根据rank数量,将index 分割成 rank份,每一份里面进行batchsize的采样,所以bs指的是单个GPU的bs】
例如,如果你有4个GPU,并且每个GPU的batch size设置为32,那么总的batch size就是32 * 4 = 128。每个GPU在每次训练迭代中处理32个样本,所有4个GPU在每次训练迭代中处理总共128个样本。
如果你使用的是分布式数据并行的训练策略,确保将batch_size设置为每个GPU上希望的大小,而不是总的batch size。
datalaoder中设置的 number_work在DDP训练中如何工作的?
首先明确一点: num_works指的是单个GPU的num_works数据加载进程数量。
**num_workers**参数定义了并行数据加载的进程数量。每个进程独立地从数据集中读取和预处理数据。 **collate_fn**可以自定义如何将数据项组合成batch。 数据加载进程将预处理后的数据批次传递给主进程,主进程将这些批次数据送入模型进行训练。 使用多个数据加载进程可以提高数据预处理的速度,减少GPU在训练时的等待时间,从而加快整体训练过程。
num_workers的作用数据加载 : num_workers决定了用于加载数据的子进程的数量。更多的工作进程可以并行地读取和预处理数据,从而加快数据加载速度,减少GPU的等待时间。性能影响 : 增加num_workers的数量通常可以提高数据加载速度,但也会增加系统的内存使用。合理设置num_workers的值可以在数据加载效率和系统资源使用之间找到平衡。在DDP训练中的考虑
每个进程的num_workers : 每个分布式进程(即每个GPU)都有自己的数据加载子进程。这意味着总的num_workers会是每个GPU上num_workers的值乘以GPU的数量(分布式进程数)。例如,如果有4个GPU,并且每个GPU的num_workers设置为4,那么总的工作进程数将是4 * 4 = 16。 避免数据重叠 : 在分布式训练中,需要确保每个进程处理的数据子集是不同的。使用DistributedSampler可以确保数据在各个进程间均匀分配,从而避免数据重复和丢失。同步和通信开销 : 增加num_workers的数量可能会增加进程间的同步和通信开销,特别是在多GPU的情况下。需要根据具体的硬件配置和数据集大小来调整num_workers。 内存和CPU资源 : 每增加一个工作进程,都会消耗额外的CPU资源和内存。确保你的系统有足够的资源来支持设置的num_workers值。 单个numberwork子进程单独负责一个batch的数据吗,然后多个进程负责加载多个不同batch数据?
在PyTorch中,DataLoader中的子进程(由num_workers参数指定)并不一定是每个进程负责一个完整的batch的数据。实际操作中,多个子进程负责并行地预处理数据并将其送入主进程。下面是详细的解释:
数据加载进程的工作方式
子进程的任务 : 每个数据加载进程从数据集中提取样本,并执行预处理任务。子进程会从数据集中读取单个样本(或多个样本),进行必要的转换和预处理,然后将这些处理后的样本返回给主进程。批次的生成 : DataLoader在主进程中处理批次的生成。主进程负责将从各个子进程中接收到的样本聚合成一个完整的batch。具体来说,当主进程需要一个新的batch时,它会从子进程中获取样本,然后使用collate_fn将这些样本组合成一个batch。数据并行处理 : 如果设置了num_workers > 1,DataLoader会启动多个子进程来并行地加载数据。这些子进程并不独立处理完整的batch,而是并行地从数据集中提取和预处理样本。主进程会从这些子进程中收集样本,并在主进程中将样本组成batch。数据加载示例
假设你设置了num_workers=4,这意味着会有4个子进程并行地处理数据。数据加载的过程大致如下:
子进程读取数据 :每个子进程从数据集中读取样本。 子进程对样本进行预处理(如数据增强、标准化等)。 主进程收集数据 :主进程从子进程中收集处理后的样本。 主进程使用collate_fn将样本组合成一个batch。 生成批次 :为什么numberwork设置大了会增加CPU内存?
设置较大的 num_workers 值会增加 CPU 内存使用的原因有几个方面:
1. 进程数量和内存占用
每个子进程的内存消耗 : 每个数据加载子进程(由 num_workers 定义)都会独立地运行,并加载一部分数据集。每个子进程会使用自己的内存来存储数据和进行预处理操作。内存需求 : 如果 num_workers 设置得很高,系统将会启动多个子进程,这些进程会同时存在并占用内存。每个进程都需要一定的内存来存储数据和运行预处理代码,从而导致总的内存使用增加。2. 数据预处理和缓存
数据缓冲 : DataLoader 使用子进程来并行加载和预处理数据。在预处理过程中,子进程可能会创建和维护缓存,这些缓存可能会消耗额外的内存。数据加载 : 进程在数据加载过程中可能会在内存中保持一定量的数据,以提高数据处理效率。这种内存的占用也会随着 num_workers 的增加而增加。3. 并发处理
并发开销 : 启动大量的子进程进行数据处理会增加系统的并发开销。操作系统需要为每个进程分配内存和管理资源,这会导致系统整体的内存使用增加。进程间通信 : 多个子进程之间可能会有数据交换和同步操作,这些操作也可能增加内存开销。大模型训练中的数据加载和NCCL通信问题
A、训练大模型时候,有两亿的数据,数据索引保存到了jsonl文件中,在torch dataloader 加载数据jsonl文件时候爆内存,如何解决
1. 使用分块加载(Chunk Loading) 【法1】
将数据分块处理,而不是一次性加载所有数据。可以在Dataset类中实现这一点。示例代码如下:
import json
import torch
from torch.utils.data import Dataset, DataLoader
class LargeJSONLDataset(Dataset):
def __init__(self, jsonl_file, chunk_size=1000):
self.jsonl_file = jsonl_file
self.chunk_size = chunk_size
self.data = []
self._load_chunk(0)
def _load_chunk(self, chunk_index):
start_line = chunk_index * self.chunk_size
end_line = start_line + self.chunk_size
self.data = []
with open(self.jsonl_file, 'r') as f:
for i, line in enumerate(f):
if start_line <= i < end_line:
self.data.append(json.loads(line))
if i >= end_line:
break
def __len__(self):
with open(self.jsonl_file, 'r') as f:
return sum(1 for _ in f)
def __getitem__(self, idx):
chunk_index = idx // self.chunk_size
self._load_chunk(chunk_index)
local_idx = idx % self.chunk_size
return self.data[local_idx]
# 创建 Dataset 和 DataLoader
dataset = LargeJSONLDataset('data.jsonl')
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
实现的逻辑:采样器sampler 获取 index = len(self.dataset),然后进行index随机抽样,将抽到的id送给dataloader加载器,dataloader根据这些id,去dataset类里面执行getitem。 dataset 不在需要加载所有的jsonl文件,只需要根据id//self.chunk_size判断数据在第几个chunk,然后对应需要加载目标chunk的数据即可,然后在id% self.chunk_size 得到在该chunk的真实id,读取。这样做缺点是每次都需要重新laod jsonl文件,加载时间变慢。
2. 使用内存映射
内存映射可以帮助将大文件映射到内存中而不是完全加载。jsonl格式通常不支持直接内存映射,但可以使用分块处理与内存映射结合的方法。
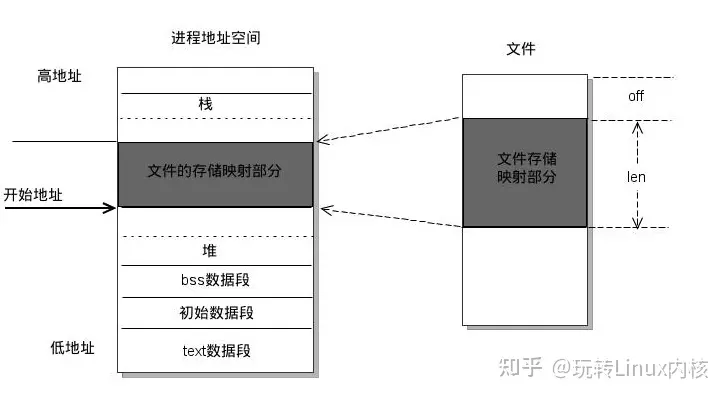
内存映射是一种将磁盘上的文件映射到内存中的方法。通过使用内存映射,我们可以在不将整个文件加载到内存中的情况下访问文件的内容。这对于处理大型数据集非常有用,因为它可以节省内存空间,并且可以快速访问文件的任意部分。
内存映射:将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系 。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用 read、write 等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。
使用内存映射有以下几个优点:
节省内存空间:通过内存映射,我们可以在不将整个文件加载到内存中的情况下访问文件的内容。这对于处理大型数据集非常有用,因为它可以节省大量的内存空间。 快速访问文件的任意部分:由于内存映射将文件映射到内存中,我们可以快速访问文件的任意部分,而不需要读取整个文件。这对于随机访问大型文件非常有用。 支持并发访问:多个进程可以同时访问内存映射文件,而不会发生冲突。这使得内存映射非常适合多进程的数据处理任务。 https://github.com/DACUS1995/pytorch-mmap-dataset
3. 优化数据存储格式
考虑将数据存储为其他格式,如HDF5或Parquet,这些格式支持更高效的分块读写和压缩。例如,可以使用pandas将JSONL文件转换为Parquet格式,然后使用pandas读取它们。
4. 使用数据流处理
使用生成器逐行读取数据,而不是将整个文件加载到内存中:
def data_generator(file_path):
with open(file_path, 'r') as f:
for line in f:
yield json.loads(line)
# 在 DataLoader 中使用生成器
def collate_fn(batch):
# 自定义你的批处理操作
return batch
dataset = data_generator('data.jsonl')
dataloader = DataLoader(dataset, batch_size=32, collate_fn=collate_fn)
5. 多进程数据加载
使用torch.utils.data.DataLoader的num_workers参数来并行加载数据:
dataloader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=4)
6. 数据预处理
在数据加载之前进行预处理,将数据处理成更紧凑的格式或者将其划分为多个较小的文件进行分段加载。这样可以减少每次加载的数据量。
7. 使用分块加载 【法2】
方法1 每次读取单个数据,都需要重新读取一边jsonl文件,大大增加了数据加载的时间,为了尽量不影响数据加载时间,我们考虑牺牲一部分随机性来提高速度。
具体方法为:jsonl数据被分成N份,在训练1轮中,数据datalaoder先加载第一份的jsonl数据,然后part1数据加载训练结束后,继续加载part2的jsonl数据…..直到所有的jsonl数据加载完成,训练1轮结束。这样做的好处是每次batch不需要重新读取jsonl,但缺点就是不同part的jsonl之间数据不互通,数据的随机性降低,具体代码实现参考:FunASR
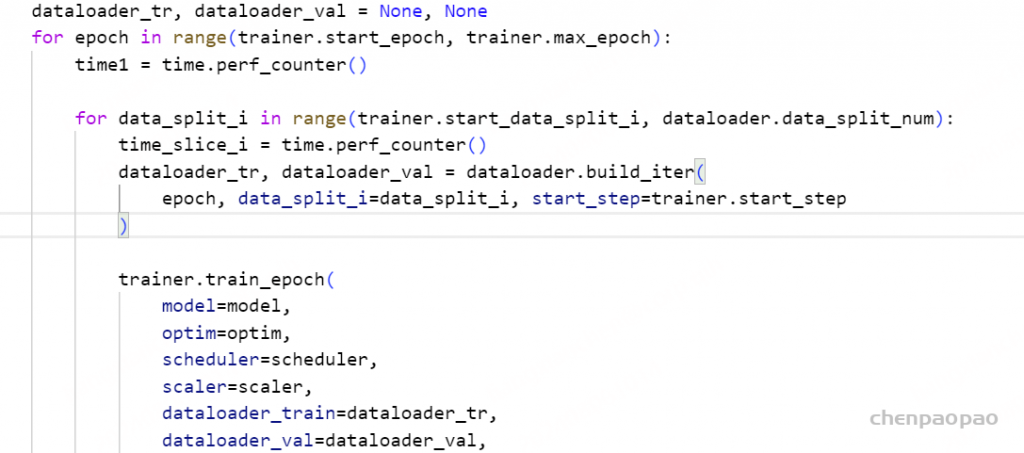
1:在训练1个epoch时候:传递data_split_num【数据分成几份】 data_split_i 【当前第几分】
2、datalaoder的 build_iter代码实现:本质上就是 重新执行 torch.utils.data.Dataset【可以自定义】、torch.utils.data.DataLoader、以及torch.utils.data.distributed.DistributedSampler【可以自己定义】 ,需要向 Dataset 传递 data_split_i 参数;
def build_iter(self, epoch=0, data_split_i=0, start_step=0, **kwargs):
# reload dataset slice
if self.data_split_num > 1:
del self.dataset_tr
self.dataset_tr = self.dataset_class(
self.kwargs.get("train_data_set_list"),
frontend=self.frontend,
tokenizer=self.tokenizer,
is_training=True,
**self.kwargs.get("dataset_conf"),
data_split_i=data_split_i,
)
# dataloader
batch_sampler = self.kwargs["dataset_conf"].get("batch_sampler", "BatchSampler")
batch_sampler_val = None
if batch_sampler is not None:
batch_sampler_class = tables.batch_sampler_classes.get(batch_sampler)
batch_sampler = batch_sampler_class(
self.dataset_tr, start_step=start_step, **self.kwargs.get("dataset_conf")
)
batch_sampler_val = batch_sampler_class(
self.dataset_val, is_training=False, **self.kwargs.get("dataset_conf")
)
batch_sampler["batch_sampler"].set_epoch(epoch)
batch_sampler_val["batch_sampler"].set_epoch(epoch)
dataloader_tr = torch.utils.data.DataLoader(
self.dataset_tr, collate_fn=self.dataset_tr.collator, **batch_sampler
)
dataloader_val = torch.utils.data.DataLoader(
self.dataset_val, collate_fn=self.dataset_val.collator, **batch_sampler_val
)
return dataloader_tr, dataloader_val
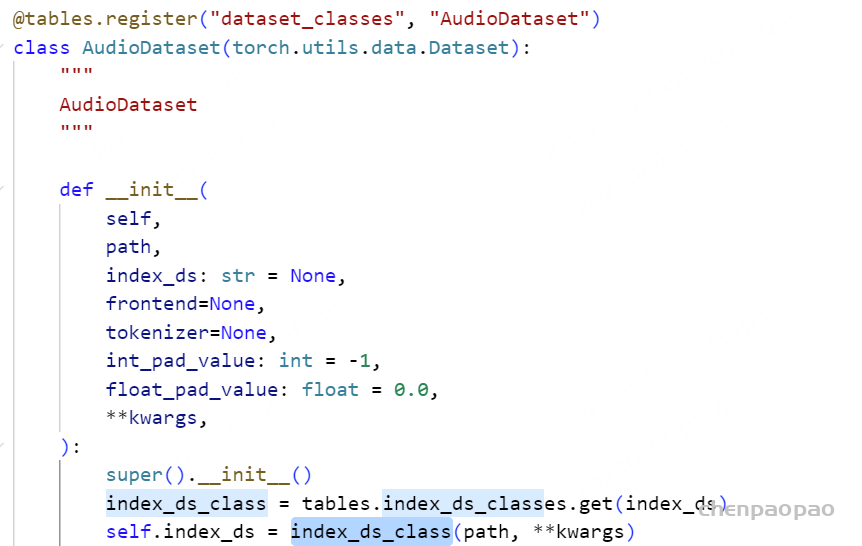
3、 Dataset 的具体实现:
可以看出,AudioDataset里面实际上利用的index_ds来具体读取jsonl文件内容的。
4、index_ds的实现:只返回部分jsonl数据,虽然函数里面加载了整个文件,但函数结束file_list_all解释放掉了,最后只有file_list一直在占用内存。
8、pytorch pin_memory 设置为Fasle【牺牲时间换空间】
在PyTorch中,何时使用pin_memory?【CPU内存不足,建议关闭该功能】 当计算机的内存充足的时候,可以设置pin_memory=True。当系统卡住,或者交换内存使用过多的时候,设置pin_memory=False。
pin_memory就是锁页内存,创建DataLoader时,设置pin_memory=True,则意味着生成的Tensor数据最开始是属于内存中的锁页内存,这样将内存的Tensor转义到GPU的显存就会更快一些。pin_memory=False表示将load进数据放至非锁页内存区,速度会较慢。
当计算机的内存充足的时候,设置pin_memory=True。当系统卡住,或者交换内存使用过多的时候,设置pin_memory=False。
主机中的内存,有两种存在方式: 一是锁页,二是不锁页,
锁页内存存放的内容在任何情况下都不会与主机的虚拟内存进行交换(注:虚拟内存就是硬盘),而不锁页内存在主机内存不足时,数据会存放在虚拟内存中。显卡中的显存全部是锁页内存,当计算机的内存充足的时候,可以设置pin_memory=True。
在使用PyTorch进行数据加载时,pin_memory是一个可选的,它通常用于将数据存储在主机内存(RAM)中的固定内存页(pinned memory)上,以便更高效地将数据传输到GPU内存。
主要作用如下:
提高数据传输效率:当使用GPU进行训练时,通常需要将数据从主机内存传输到GPU内存。使用pin_memory可以将数据存储在固定内存页中,减少数据传输的时间和开销,提高数据传输的效率。 减少数据传输延迟:主机内存和GPU内存之间的数据传输通常涉及内存拷贝操作,而内存拷贝是一项相对较慢的操作。pin_memory可以在数据加载时将数据直接存放在固定内存页中,避免不必要的内存拷贝过程,从而减少数据传输的延迟。 需要注意的是,使用pin_memory会占用额外的主机内存,并且只在使用CUDA设备的情况下才有效果。
锁页内存和GPU显存之间的拷贝速度大约是6GB/s
通常我们的主机处理器是支持虚拟内存系统的,也就是使用硬盘空间来代替内存。大多数系统中虚拟内存空间被划分成许多页,它们是寻址的单元,页的大小至少是4096个字节。虚拟寻址能使一个连续的虚拟地址空间映射到物理内存并不连续的一些页。
如果某页的物理内存被标记为换出 状态,它就可以被更换到磁盘上,也就是说被踢出内存了。如果下次需要该页了,则重新加载到内存里。显然如果这一页切换的非常频繁,那么会浪费不少时间。
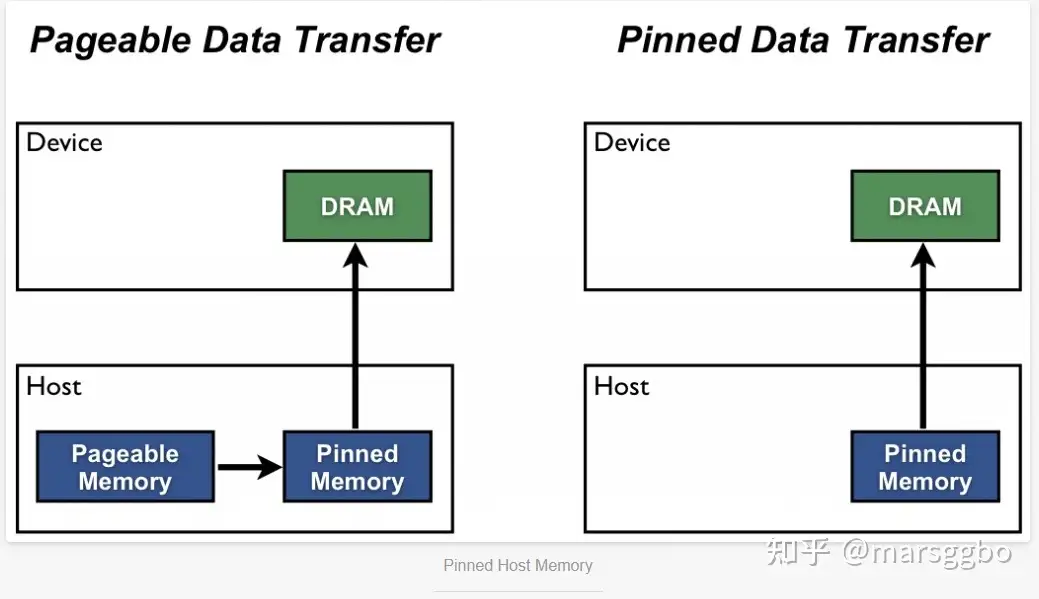
锁页(pinned page)是操作系统常用的操作,就是为了使硬件外设直接访问CPU内存,从而避免过多的复制操作。被锁定的页面会被操作系统标记为不可被换出的 ,所以设备驱动程序给这些外设编程时,可以使用页面的物理地址直接访问内存,CPU也可以访问上述锁页内存,但是此内存是不能移动或换页到磁盘上的。另外,在GPU上分配的内存默认都是锁页内存,这只是因为GPU不支持将内存交换到磁盘上。
Host(例如CPU)的数据分配默认是**pageable(可分页的)**,但是GPU是没法直接读取pageable内存里的数据的,所以需要先创建一个临时的缓冲区(pinned memory),把数据从pageable内存拷贝pinned内存上,然后GPU才能从pinned内存上读取数据,如上图(左)所示。
9、number_works降低参数值
从磁盘加载数据到 host 的page-locked内存. 采用多个 worker 进程并行地数据加载 ,会增加内存占用,因此为了降低内存占用,可以考虑number_work从低到高设置:2、4、8、16,知道训练速度达到最优。
每个进程的num_workers : 每个分布式进程(即每个GPU)都有自己的数据加载子进程。这意味着总的num_workers会是每个GPU上num_workers的值乘以GPU的数量(分布式进程数)。
例如,如果有4个GPU,并且每个GPU的num_workers设置为4,那么总的工作进程数将是4 * 4 = 16。
避免数据重叠 : 在分布式训练中,需要确保每个进程处理的数据子集是不同的。使用DistributedSampler可以确保数据在各个进程间均匀分配,从而避免数据重复和丢失。
同步和通信开销 : 增加num_workers的数量可能会增加进程间的同步和通信开销,特别是在多GPU的情况下。需要根据具体的硬件配置和数据集大小来调整num_workers。
内存和CPU资源 : 每增加一个工作进程,都会消耗额外的CPU资源和内存。确保你的系统有足够的资源来支持设置的num_workers值。
在给Dataloader设置worker数量(num_worker)时,到底设置多少合适?这个worker到底怎么工作的?
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
每次dataloader加载数据时:dataloader一次性创建num_worker个worker,(也可以说dataloader一次性创建num_worker个工作进程,worker也是普通的工作进程),并用batch_sampler将指定第几个batch分配给指定worker,worker将它负责的batch加载进RAM。
然后,dataloader从RAM中找本轮迭代要用的batch,如果找到了,就使用。如果没找到,就要num_worker个worker继续加载batch到内存,直到dataloader在RAM中找到目标batch。一般情况下都是能找到的,因为batch_sampler指定batch时当然优先指定本轮要用的batch。
num_worker设置得大,好处是寻batch速度快,因为下一轮迭代的batch很可能在上一轮/上上一轮…迭代时已经加载好了。坏处是内存开销大,也加重了CPU负担(worker加载数据到RAM的进程是CPU复制的嘛)。num_workers的经验设置值是自己电脑/服务器的CPU核心数,如果CPU很强、RAM也很充足,就可以设置得更大些。
如果num_worker设为0,意味着每一轮迭代时,dataloader不再有自主加载数据到RAM这一步骤(因为没有worker了),而是在RAM中找batch,找不到时再加载相应的batch。缺点当然是速度更慢。
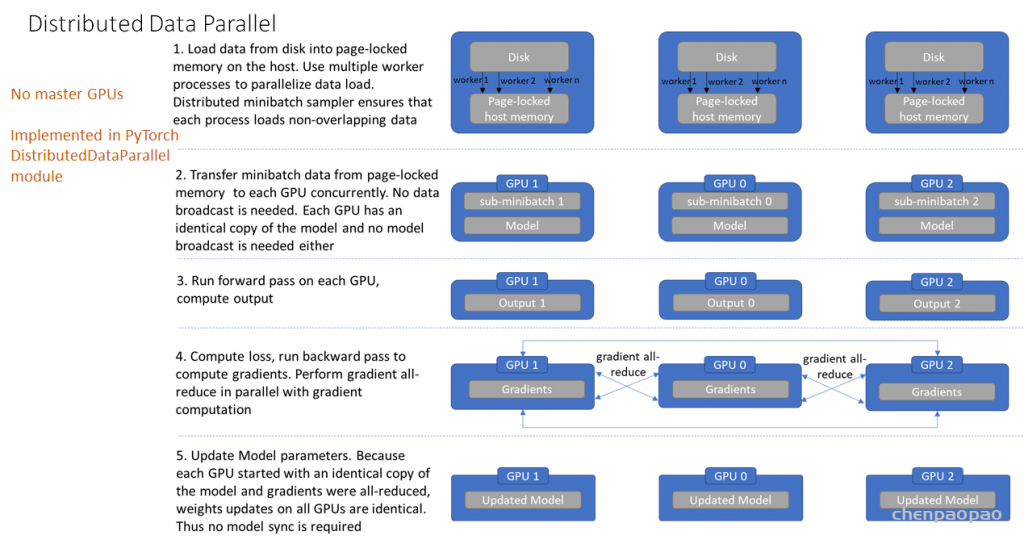
根据硬件配置调整 : 在多核 CPU 环境下,设置较高的 num_workers(如 4 到 16)可以有效利用多核资源,提高数据加载速度。具体的最佳值需要根据系统的 CPU 核心数和内存情况来调整。数据加载瓶颈 : 如果你发现训练时 GPU 经常处于等待数据的状态,这可能是因为数据加载成为了瓶颈。增加 num_workers 可以帮助缓解这一问题。系统负载 : 在某些情况下,设置过高的 num_workers 可能会导致系统负载过高,影响其他任务或整体系统性能。因此需要找到一个平衡点。实验调整 : 实际应用中,最好的做法是从较小的值开始(如 2 或 4),然后逐步增加,观察训练过程中的数据加载速度和系统资源使用情况,从而确定最佳设置。DistributedDataParallel 消除了 DataParallel 中上述不足. 其不再需要主 GPU,每个 GPU 分别进行各自任务. 每个 GPU 上的训练是其独立进程,而在 DataParallel 中是采用多线程(multi-thread) 的.
DistributedDataParallel 的工作过程如,
[1] – 从磁盘加载数据到 host 的page-locked内存. 采用多个 worker 进程并行地数据加载;其中,distributed data sampler 确保了加载的数据在跨进程间是不重叠的.
[2] – 将 mini-batch 数据由 page-locked 内存转移到 GPU. 不需要任何数据广播. 因为每个 GPU 分别有模型副本,因此也不需要模型广播.
[3] – 分别在各 GPU 独立进行前向计算和损失函数计算. 因此,也不需要收集各 GPUs 的输出.
[4] – 后向梯度计算,梯度是跨GPUs all-reduced的. 确保在后向传播结束时,每个 GPU 最终得到相同的平均梯度的副本.
[5] – 更新模型参数. 由于每个 GPU 是由相同的模型副本开始的,且梯度是 all-reduced 的,因此所有 GPUs 上的权重更新是相同的,无需再进行模型同步.
以上即完成了一次迭代. 这种设计确保了模型参数的更新是相同的,因此消除了每次开始时的模型同步.
B 、NCCL通信超时问题[PG 1 Rank 9] Timeout at NCCL work: 957, last enqueued NCCL work: 957, last completed NCCL work: 956.
这种报错需要具体情况具体分析
1、尝试增加NCCL 超时时间/设置过NCCL变量
如何设置:
1、查看变量:查看环境变量 NCCL_IB_TIMEOUT 的值
echo $NCCL_IB_TIMEOUT # 如果环境变量已设置,这个命令将显示其值;如果没有设置,则不会有任何输出。
printenv 命令可以显示所有环境变量的值,也可以查看特定的环境变量:
printenv NCCL_IB_TIMEOUT #如果环境变量未设置,该命令不会输出任何内容。也可以使用 env 命令来列出所有环境变量,并查找 NCCL_IB_TIMEOUT:
env | grep NCCL_IB_TIMEOUTNCCL相关环境变量说明 【https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/usage.html】
NCCL_TIMEOUT:设置集合操作超时阈值,单位毫秒;如果常见超时错误,适当增大该值,但不能太大 。NCCL_TIMEOUT 环境变量用于设置 NCCL 集体通信操作的超时时间。通过调整这个值,你可以更好地处理网络延迟和不稳定的问题,确保 NCCL 通信的稳定性和可靠性。如果在集体通信过程中遇到超时问题,可以尝试调整此环境变量以解决问题。设置超时时间 :
NCCL_TIMEOUT 用于定义 NCCL 集体通信操作的超时时间。超时时间是 NCCL 在执行操作时等待响应的最长时间,超出此时间将触发超时错误。解决网络问题 :
在高性能计算和大规模分布式训练中,网络延迟或不稳定可能导致集体通信操作超时。设置合适的 NCCL_TIMEOUT 可以帮助调节容错设置,避免训练过程中因超时错误而中断。 性能调优 :
根据你的集群配置和网络状况,适当调整 NCCL_TIMEOUT 可以帮助优化通信性能和稳定性。 NCCL_ALGO:选择集合通信算法,如Ring, Tree;不同拓扑适合不同算法,测试选更优算法 NCCL_CHUNK_SIZE:定义环形传输缓冲区大小;合理设置可提速,但也会增加内存消耗 NCCL_DEBUG:打开NCCL调试日志;出现问题时打开调试,但会降低速度,不要在生产环境使用 NCCL_DEBUG_FILE设置一个文件地址,变量用于将NCCL的调试日志输出到文件中。有助于调试nccl。 NCCL_P2P_LEVEL:设置点对点通信优化级别;增加该值可减少P2P次数,提高某些操作效率 NCCL_P2P_DISABLE:禁用点对点通信,强制使用集合通信。 在某些情况下,P2P 通信可能会导致性能问题或出现错误。禁用 P2P 通信可以帮助解决这些问题。如果你遇到与 P2P 通信相关的错误或不稳定性,禁用 P2P 可能有助于恢复系统的稳定性。NCCL_PXN_DISABLE:禁用使用非本地 NIC 的节点间通信,使用 NVLink 和一个中间 GPU。建议设置成1。在PyTorch中进行跨节点all-to-all通信时,如果该环境变量是0会出现异常。 NCCL_SOCKET_IFNAME:选择网络接口。 NCCL_SOCKET_NTHREADS 增加它的数量可以提高socker传输的效率,但是会增加CPU的负担 NCCL_NET_GDR_LEVEL:设置GPUDirect RDMA的使用级别。 NCCL_MAX_NRINGS:定义支持的最大NCCL环路数。 NCCL_MIN_NRINGS:定义最小环路数。 NCCL_BUFFSIZE:设置scratch空间大小。 NCCL_BUFFLE_SIZE 缓存数据量,缓存越大一次ring传输的数据就越大自然对带宽的压力最大,但是相应的总延迟次数会少。默认值是4M(4194304),注意设置的时候使用bytes(字节大小) NCCL_NTHREADS:设置NCCL内部使用的线程数。 NCCL_VERSION:显示NCCL版本信息。 NCCL_MAX/MIN_NCHANNELS 最小和最大的rings,rings越多对GPU的显存、带宽的压力都越大,也会影响计算性能 NCCL_CHECKS_DISABLE 在每次集合通信进行前对参数检验校对,这会增加延迟时间,在生产环境中可以设为1.默认是0 NCCL_CHECK_POINTERS 在每次集合通信进行前对CUDA内存 指针进行校验,这会增加延迟时间,在生产环境中可以设为1.默认是0 NCCL_NET_GDR_LEVEL GDR触发的条件,默认是当GPU和NIC挂载一个swith上面时使用GDR NCCL_IGNORE_CPU_AFFINITY 忽略CPU与应用的亲和性使用GPU与nic的亲和性为主 NCCL_IB_DISABLE:禁用InfiniBand传输。 禁用 InfiniBand : 设置 NCCL_IB_DISABLE=1 会禁用 NCCL 在 InfiniBand 设备上的使用。这意味着 NCCL 将不会利用 InfiniBand 网络进行数据传输,而是回退到其他网络接口(例如以太网或其他网络接口)。
调试和兼容性 : 禁用 InfiniBand 可能用于调试目的,或在系统中 InfiniBand 网络出现问题时回退到其他网络接口。如果你遇到与 InfiniBand 相关的错误或兼容性问题,禁用 InfiniBand 可能有助于解决这些问题。
NCCL_IB_HCA 代表IB使用的设备:Mellanox mlx5系列的HCA设备NCCL_IB_HCA=mlx5 会默认轮询所有的设备。NCCL_IB_HCA=mlx5_0:1 指定其中一台设备。 NCCL_IB_TIMEOUT 改变量用于控制InfiniBand Verbs超时。取值范围1-22。超时时间的计算公式为4.096微秒 * 2 ^ timeout,正确的值取决于网络的大小。增加该值可以在非常大的网络上提供帮助,例如 NCCL在调用ibv_poll_cq时出现错误12时。建议在大模型训练任务中设置成最大值22,可以减少不少nccl timeout异常。设置超时时间 : NCCL_IB_TIMEOUT 用于控制 InfiniBand 网络操作的超时时间。通过调整这个值,你可以控制 NCCL 在遇到通信延迟或网络问题时的容忍度。解决网络问题 : 在高性能计算和大规模分布式训练中,网络延迟或不稳定可能导致超时错误。调整 NCCL_IB_TIMEOUT 可以帮助你在遇到网络问题时更好地调节超时设置,避免训练过程被中断。NCCL_IB_RETRY_CNT变量控制 InfiniBand 的重试次数。建议在大模型训练任务中设置成13,尽可能多重试。 NCCL_DEBUG_FILE设置一个文件地址,变量用于将NCCL的调试日志输出到文件中。有助于调试nccl。 NCCL_IB_PCI_RELAXED_ORDERING启用 IB Verbs 传输的Relaxed Ordering。Relaxed Ordering可以极大地提高虚拟化环境下 InfiniBand 网络的性能。设置为 2,如果可用,自动使用Relaxed Ordering。设置为 1,强制使用Relaxed Ordering,如果不可用则失败。设置为 0,禁用使用Relaxed Ordering。默认值为 2。建议值为1 2、增加 dist.init_process_group 超时时间,还要对应修改NCCL变量: export TORCH_NCCL_BLOCKING_WAIT !!
dist.init_process_group(backend=kwargs.get(“backend”, “nccl”), init_method=”env://”,timeout=timedelta(seconds=7200000)) # 7200s 等待2h
export TORCH_NCCL_BLOCKING_WAIT=1 # 是否堵塞等待某节点错误超时 “0” 不堵塞等待 “1” 堵塞等待
echo $TORCH_NCCL_BLOCKING_WAIT
printenv TORCH_NCCL_BLOCKING_WAIT # 新版本torch
export TORCH_NCCL_ASYNC_ERROR_HANDLING=1 # 是否堵塞等待某节点错误超时 “0” 不堵塞等待 “1” 堵塞等待
echo $TORCH_NCCL_ASYNC_ERROR_HANDLING
printenv TORCH_NCCL_ASYNC_ERROR_HANDLING # 新版本torch
export NCCL_BLOCKING_WAIT=1
echo $NCCL_BLOCKING_WAIT
printenv NCCL_BLOCKING_WAIT #旧版本torch
export NCCL_ASYNC_ERROR_HANDLING=1
echo $NCCL_ASYNC_ERROR_HANDLING
printenv NCCL_ASYNC_ERROR_HANDLING #旧版本torch 在使用 torch.distributed.init_process_group 初始化分布式训练时,timeout 参数用于指定集群中进程之间进行集体通信操作时的超时时间。这个超时时间决定了分布式进程在等待其他进程响应时的最长时间。
torch.distributed.init_process_group(backend=None , init_method=None , timeout=None , world_size=-1 , rank=-1 , store=None , group_name=” , pg_options=None , device_id=None )
说明文档:https://pytorch.org/docs/stable/distributed.html
新版本torch 旧版本torch 超时设置 :
timeout 参数用于设置分布式通信操作的超时时间。超时时间是 timedelta 对象,表示在等待其他进程响应时的最长时间。在你提供的示例中,timeout 被设置为 timedelta(seconds=108000),即 30 小时。这意味着分布式通信操作将在 30 小时内等待其他进程响应。 用途 :
容错性 : 提高容错性,确保在长时间等待期间不会因为网络延迟或通信问题导致进程失败。调试 : 在调试和测试中,设置较长的超时时间可以帮助识别是否因为超时设置过短而导致的通信问题。防止死锁 : 在复杂的分布式训练任务中,长时间的超时时间有助于防止因通信死锁而导致的进程失败。超时处理 :
如果在指定的超时时间内没有收到预期的响应,init_process_group 将会引发超时错误。这通常表示进程之间的通信出现了问题,可能需要检查网络连接、进程配置或其他潜在问题。 TORCH_NCCL_BLOCKING_WAIT 是一个环境变量,用于控制 PyTorch 在使用 NCCL 后端时的通信等待策略。具体来说,它决定了 NCCL 操作是否使用阻塞等待方式来处理通信操作。
TORCH_NCCL_BLOCKING_WAIT 的作用TORCH_NCCL_BLOCKING_WAIT=1启用阻塞等待 : 当设置为 1 时,PyTorch 在执行 NCCL 操作(如 all-reduce 或 broadcast)时,会使用阻塞等待的方式。这意味着 PyTorch 会等待操作完全完成或超时之后才继续执行。这种设置可以帮助确保所有进程在继续之前都完成了通信,有助于解决因异步操作引起的数据同步问题或错误。TORCH_NCCL_BLOCKING_WAIT=0禁用阻塞等待 : 默认情况下(即设置为 0),PyTorch 使用非阻塞等待方式。NCCL 操作在后台异步进行,可能会导致在操作完成之前程序继续执行。这种方式可能会在网络延迟或系统负载较高时引发通信超时或数据不一致的问题。如何设置 TORCH_NCCL_BLOCKING_WAIT
你可以通过以下方式设置 TORCH_NCCL_BLOCKING_WAIT 环境变量:
临时设置 : 在运行程序时,可以在命令行中临时设置环境变量:bash复制代码TORCH_NCCL_BLOCKING_WAIT=1 python your_training_script.py永久设置 : 在终端会话中,可以通过 export 命令永久设置:bash复制代码export TORCH_NCCL_BLOCKING_WAIT=1 这个设置会在当前终端会话中生效,直到会话结束或重新启动。在脚本中设置 : 如果你希望在 Python 脚本内部设置这个变量,可以在脚本的开头添加:python复制代码import os os.environ['TORCH_NCCL_BLOCKING_WAIT'] = '1'使用场景
调试和稳定性 :启用阻塞等待有助于调试和解决 NCCL 操作中的同步问题。它确保所有通信操作完成后才继续执行,有助于提高系统的稳定性。 网络不稳定和负载高 :在网络延迟较高或系统负载较大的环境中,启用阻塞等待可以减少由于异步操作导致的超时和错误。 注意事项
性能影响 :阻塞等待可能会增加通信操作的等待时间,影响整体训练性能,特别是在大规模分布式训练任务中。 超时问题 :如果超时时间设置过短或网络状况较差,启用阻塞等待可能导致更多的超时错误。因此,需要平衡稳定性和性能。 总结
TORCH_NCCL_BLOCKING_WAIT 环境变量控制 PyTorch 使用 NCCL 后端时的通信等待策略。设置为 1 可以启用阻塞等待,有助于提高系统稳定性和调试能力,但可能会影响性能。根据具体的训练任务和环境,可以选择合适的设置来优化训练过程。
相关环境变量解释:
https://pytorch.org/docs/stable/torch_nccl_environment_variables.html
3、增加 num_workers 来加快处理数据【Dataloader阶段导致 NCCL超时】
如果是在数据加载的时间过长,导致NCCL通信超时,考虑增加num_workers来提高数据加载速度。
减少数据加载瓶颈 :
增加 num_workers 可以提高数据加载速度,减少训练过程中因数据加载而导致的等待时间。这可以间接减少由于数据处理缓慢而可能引发的 NCCL 超时问题。 提高训练效率 :
更高效的数据加载可以提高整体训练效率,使训练过程更加顺畅,从而可能减少由于系统负载不均导致的通信超时问题。 4、 DistributedSampler 采样阶段导致 NCCL超时:
如果分布式训练中 NCCL 超时问题发生在采样阶段(特别是在使用 DistributedSampler 或自定义的采样器时),可能表明存在某些潜在的问题,这些问题可能导致训练进程之间的同步或数据传输效率低下。以下是一些可能的原因和解决方法:
可能的原因 :
数据加载和采样速度问题 :如果采样器的性能不佳,可能会导致数据加载速度变慢,从而影响训练过程。虽然这不会直接导致 NCCL 超时,但它会间接影响整体训练性能。 进程同步问题 :在使用 DistributedSampler 时,所有进程需要同步以确保数据的一致性。如果采样器在某些进程中出现延迟或阻塞,可能会导致通信超时。 数据分布不均 :如果数据分布不均,某些进程可能会比其他进程处理更多的数据,从而导致通信延迟和超时问题。 数据预处理复杂:数据预处理太复杂,会导致数据加载过慢,也有可能导致超时 解决方法:
优化采样器和数据加载 :确保自定义采样器或 DistributedSampler 以高效的方式进行数据采样和分配。优化数据加载速度,确保每个进程在采样时不会长时间等待。 使用 num_workers 设置合理的数量,以加快数据加载速度,但要注意 CPU 内存和系统负载。 调整超时时间 :增加 NCCL_TIMEOUT 环境变量值或 dist.init_process_group 中的 timeout 参数,以允许更长的等待时间。 4、基于HugingFace的Trainer多级多卡训练LLM导致NCCL超时
启动命令前增加了OMP_NUM_THREADS=1 MKL_NUM_THREADS=1,避免多线程导致死锁; 去掉了加载数据时的tqdm; 记在数据的DataLoader的drop_last设置为True,pin_memory设置为True,num_workers设置为0; 设置训练批大小为auto/设置小一点 查阅了一些资料 pytorch 多机多卡卡住问题汇总 Script freezes with no output when using DistributedDataParallel PyTorch 训练时中遇到的卡住停住等问题 PyTorch训练时,Dataloader卡死、挂起,跑一个epoch停了,问题解决方案 运行开始训练,卡住半小时,一直不动 关于炼丹,你是否知道这些细节? ultralytics/yolov5#7481 https://www.zhihu.com/question/512132168 https://discuss.pytorch.org/t/nccl-timed-out-when-using-the-torch-distributed-run/153276 https://stackoverflow.com/questions/69693950/error-some-nccl-operations-have-failed-or-timed-out